
【Neo4j】第 2 章:Cypher 查询语言
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
Cypher 是用于与 Neo4j 交互的语言。最初由 Neo4j 为 Neo4j 创建,它已作为 openCypher 开源,现在被其他图形数据库引擎使用,例如RedisGraph. 它也是图形查询语言( GQL ) 协会的一部分,其目标是构建一种通用的图形数据库查询语言——就像 SQL 用于关系数据库一样。无论如何,了解如何查询图形数据库是一个很好的起点,因为它的视觉方面:节点和关系可以通过查看查询来快速识别。
在本章中,我们将回顾 Cypher 的基础知识,这将在本书中使用:CRUD 方法、批量导入各种格式的数据,以及从图中准确提取我们需要的数据的模式匹配。这是介绍Awesome Procedures On Cypher ( APOC )插件的好地方,它是 Cypher 的扩展,引入了强大的数据导入方法等。我们还将了解更高级的工具,例如 Cypher 查询计划器。它将帮助我们了解查询的不同步骤以及我们如何调整它以加快执行速度。最后,我们将使用社交(类似 Facebook)图表来讨论 Neo4j 和 Cypher 的性能。
本章将涵盖以下主题:
- 创建节点和关系
- 更新和删除节点和关系
- 使用聚合函数
- 从 CSV 或 JSON 导入数据
- 测量性能并调整查询以提高速度
技术要求
本章所需的技术和安装如下:
- Neo4j 3.5
- Neo4j 桌面 1.2
- APOC插件安装说明可在此处获得:https : //neo4j.com/docs/labs/apoc/current/introduction/。
我们建议直接通过 Neo4j Desktop 安装,最简单的方法(版本 ≥ 3.5.0.3)。 - Neo4j Python 驱动程序(可选):pip install neo4j
- 本章使用的数据文件可在https://github.com/PacktPublishing/Hands-On-Graph-Analytics-with-Neo4j/tree/master/ch2 获得。
创建节点和关系
与 Gremlin ( Apache TinkerPop ) 或 AQL (ArangoDB) 等图形数据库的其他查询语言不同,Cypher 的构建具有类似于 SQL 的语法,以简化开发人员的过渡和数据科学家习惯了结构化查询语言。
使用 Neo4j Desktop 管理数据库
假设您已经有使用 Neo4j Desktop 的经验。这是管理 Neo4j 图表、已安装插件和应用程序的最简单工具。我建议为本书创建一个新项目,我们将在其中创建几个数据库。在以下屏幕截图中,我创建了一个名为Hands-On-Graph-Analytics-with-Neo4j的项目,其中包含两个数据库:Test graph和USA: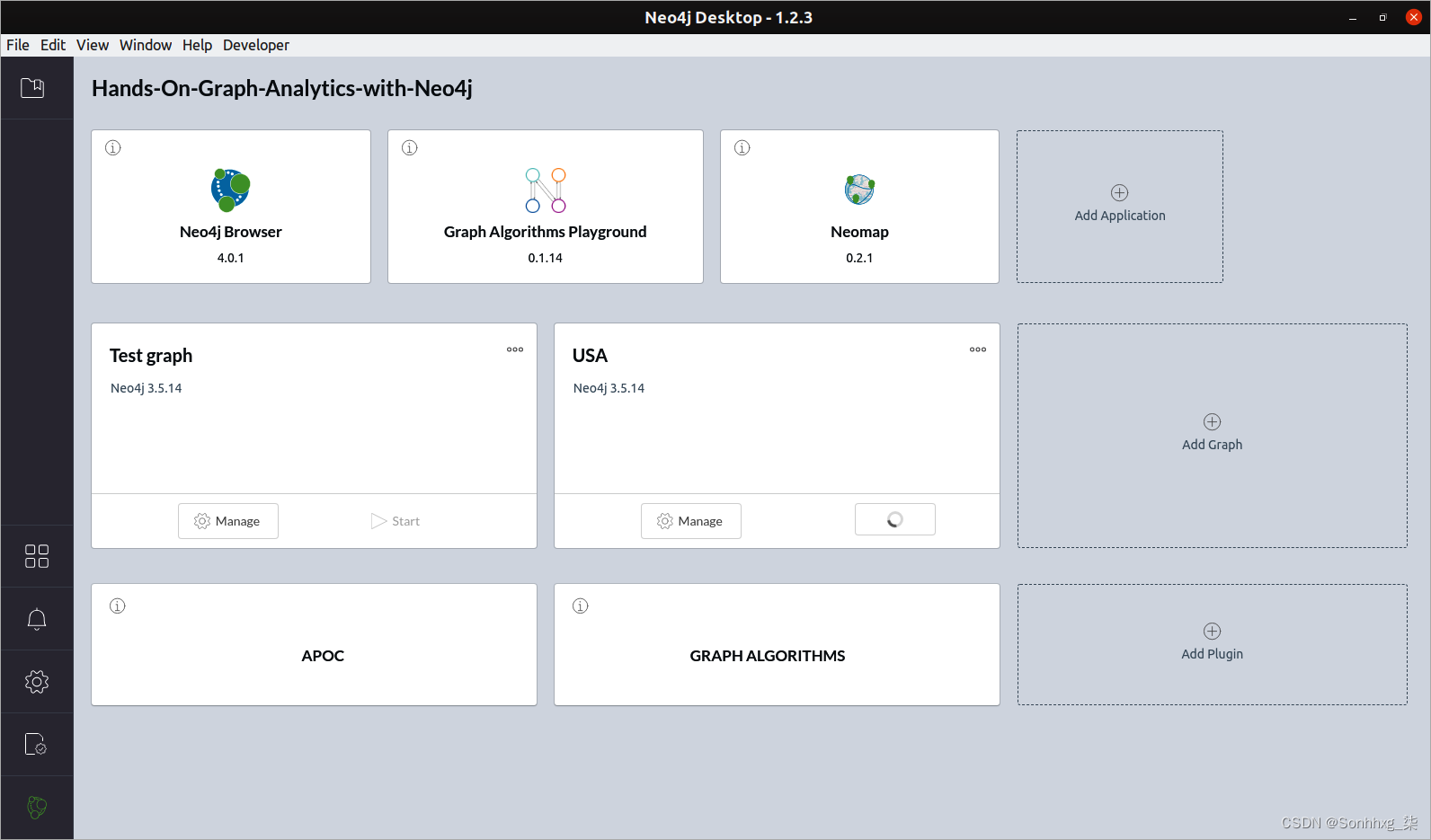
在本书中,我们将使用 Neo4j 浏览器,它是默认安装在 Neo4j Desktop 中的应用程序。在此应用程序中,您可以编写和执行 Cypher 查询,还可以以不同格式可视化结果:可视化图形、JSON 或表格数据。
创建节点
创建节点的最简单指令如下:
CREATE ()它创建一个没有标签或关系的节点。
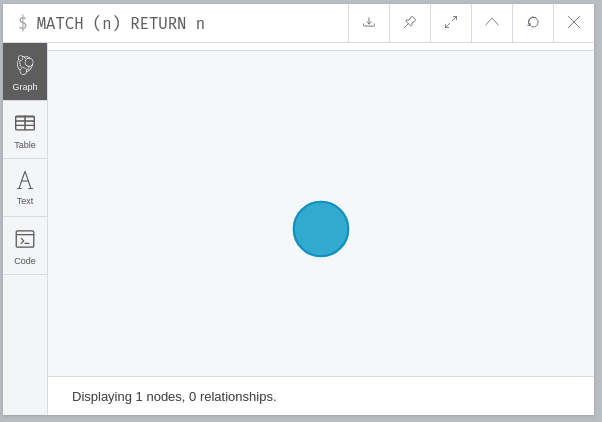
我们可以在此语句之后使用一个简单的MATCH查询来检查数据库的内容,该查询将返回图形的所有节点:
MATCH (n)
RETURN n在这里,我们正在选择节点(因为使用()),并且我们还为这些节点提供了名称、别名:n。由于这个别名,我们可以在查询的后面部分引用这些节点,这里只在RETURN语句中。
此查询的结果如下所示:
好,很好。但是对于大多数用例来说,没有标签或属性的单个节点是不够的。如果我们想在创建节点时为其分配标签,请使用以下语法:
CREATE (:Label)那已经更好了!现在,让我们在创建节点时创建属性:
CREATE (:Label {property1: "value", property2: 13})我们将在后面的部分中看到如何修改现有节点:添加或删除标签,以及添加、更新或删除属性。
选择节点
我们已经讨论过这里的简单查询,它选择数据库中的所有节点:
MATCH (n)
RETURN nMATCH (n)
RETURN n
LIMIT 10
让我们尝试在我们想要选择(过滤)的数据和RETURN语句中我们需要的属性更具体一些。
Filtering
通常,我们不想选择数据库的所有节点,而只选择符合某些条件的节点。例如,我们可能只想检索具有给定标签的节点。在这种情况下,我们会使用这个:
MATCH (n:Label)
RETURN n或者,如果您只想选择具有给定属性的节点,请使用以下命令:
MATCH (n {id: 1})
RETURN n该WHERE语句对于过滤节点也很有用。{}与符号相比,它实际上允许进行更复杂的比较。例如,我们可以使用不等式比较(大于>、小于<、大于或等于>=、或小于或等于<=语句),还可以使用布尔运算,如ANDand OR:
MATCH (n:Label)
WHERE n.property > 1 AND n.otherProperty <= 0.8
RETURN n返回属性
到目前为止,我们已经返回了整个节点,以及与之关联的所有属性。如果对于您的应用程序,您只对匹配节点的某些属性感兴趣,则可以通过使用以下查询指定要返回的属性来减小结果集的大小:
MATCH (n)
RETURN n.property1, n.property2使用这种语法,我们无法再访问 Neo4j 浏览器中的图形输出,因为它无法访问节点对象,但我们有一个更简单的表输出。
创建关系
为了创建关系,我们必须告诉 Neo4j 它的开始和结束节点,这意味着在创建关系时节点需要已经在数据库中。有两种可能的解决方案:
- 一次性创建节点和它们之间的关系:
CREATE (n:Label {id: 1})
CREATE (m:Label {id: 2})
CREATE (n)-[:RELATED_TO]->(m)- 创建节点(如果它们不存在):
CREATE (:Label {id: 3})
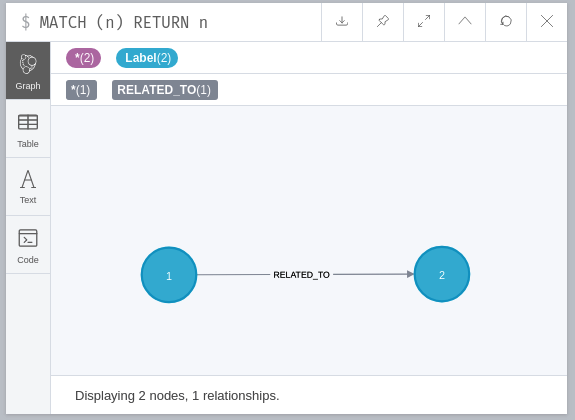
CREATE (:Label {id: 4})然后建立关系。在这种情况下,由于关系是在另一个查询(另一个命名空间)中创建的,我们需要首先MATCH关注感兴趣的节点:
MATCH (a {id: 3})
MATCH (b {id: 4})
CREATE (a)-[:RELATED_TO]->(b)如果我们在第一次查询后检查图表的内容,结果如下:
提醒:虽然在创建节点时指定节点标签不是强制性的,但关系必须具有类型。以下查询无效:CREATE (n)-[]->(m)并导致以下查询Neo.ClientError.Statement.SyntaxError:
Exactly one relationship type must be specified for CREATE. Did you forget to prefix your relationship type with a : (line 3, column 11 (offset: 60))?选择关系
我们想编写如下查询,类似于我们为节点编写的查询,但使用方括号,[]而不是方括号,():
MATCH [r]
RETURN r但是这个查询会导致错误。不能以与节点相同的方式检索关系。如果您想以简单的方式查看关系属性,可以使用以下任一语法:
// no filtering
MATCH ()-[r]-()
RETURN r
// filtering on relationship type
MATCH ()-[r:REL_TYPE]-()
RETURN r
// filtering on relationship property and returning a subset of its properties
MATCH ()-[r]-()
WHERE r.property > 10
RETURN r.property我们将在稍后的模式匹配和数据检索部分详细了解它是如何工作的。
MERGE 关键字
Cypher 文档MERGE很好地描述了该命令的行为:
让我们看一个例子:
MERGE (n:Label {id: 1})
ON CREATE SET n.timestamp_created = timestamp()
ON MATCH SET n.timestamp_last_update = timestamp()在这里,我们试图访问一个具有Label和 单个属性的节点id,其值为1。如果图中已经存在这样的节点,则使用该节点执行后续操作。在这种情况下,该语句等效于 a MATCH。但是,如果带有标签的节点Label不id=1存在,那么它将被创建,因此与CREATE语句并行。
另外两个可选语句也很重要:
- ON CREATE SET当且仅当在数据库中未找到该节点并且必须执行创建过程时才会执行。
- ON MATCH SET仅当节点已存在于图中时才会执行。
在此示例中,我使用这两个语句来记住节点的创建时间和上次在此类查询中出现的时间。
您现在可以创建节点和关系,为它们分配标签和属性。下一节将专门介绍可以对这些对象执行的其他类型的 CRUD 操作:更新和删除。
更新和删除节点和关系
创建对象不足以使数据库发挥作用。它还需要能够执行以下操作:
- 使用新信息更新现有对象
- 删除不再相关的对象
- 从数据库中读取数据
本节介绍前两个要点,而最后一个要点将在下一节中介绍。
更新对象
Cypher没有UPDATE关键字。要更新对象、节点或关系,我们将SET只使用语句。
更新现有属性或创建新属性
如果您想更新现有属性或添加新属性,很简单,如下所示:
MATCH (n {id: 1})
SET n.name = "Node 1"
RETURN n该RETURN语句不是强制性的,但它是一种检查查询是否正常的方法,例如,检查Table结果单元格的选项卡:
{
"name": "Node 1",
"id": 1
}更新节点的所有属性
如果我们想更新节点的所有属性,有一个实用的捷径:
MATCH (n {id: 1})
SET n = {id: 1, name: "My name", age: 30, address: "Earth, Universe"}
RETURN n这导致以下结果:
{
"name": "My name",
"address": "Earth, Universe",
"id": 1,
"age": 30
}例如,在某些情况下,重复现有属性以确保不删除 可能会很痛苦id。在这种情况下,+=语法是要走的路:
MATCH (n {id: 1})
SET n += {gender: "F", name: "Another name"}
RETURN n这再次按预期工作,添加gender属性并更新name字段的值:
{
"name": "Another name",
"address": "Earth, Universe",
"id": 1,
"gender": "F",
"age": 30
}更新节点标签
除了添加、更新和删除属性之外,我们还可以对节点标签执行相同操作。如果您需要为现有节点添加标签,可以使用以下语法:
MATCH (n {id: 1})
SET n:AnotherLabel
RETURN labels(n)在这里,RETURN声明只是为了确保一切顺利。结果如下:
["Label", "AnotherLabel"]相反,如果你错误地给一个节点设置了一个标签,你可以REMOVE:
MATCH (n {id: 1})
REMOVE n:AnotherLabel
RETURN labels(n)我们又回到了节点id:1有一个名为 的标签的情况Label。
删除节点属性
NULL我们在前一章中简要讨论了价值观。在 Neo4j 中,NULL值不会保存在属性列表中。没有属性意味着它是空的。因此,删除属性就像将其设置为一个NULL值一样简单:
MATCH (n {id: 1})
SET n.age = NULL
RETURN n结果如下:
{
"name": "Another name",
"address": "Earth, Universe",
"id": 1,
"gender": "F"
}另一种解决方案是使用REMOVE关键字:
MATCH (n {id: 1})
REMOVE n.address
RETURN n结果如下:
{
"gender": "F",
"name": "Another name",
"id": 1
}如果要从节点中删除所有属性,则必须为其分配一个空映射,如下所示:
MATCH (n {id: 2})
SET n = {}
RETURN n删除对象
要删除一个对象,我们将使用以下DELETE语句:
- 对于关系:
MATCH ()-[r:REL_TYPE {id: 1}]-()
DELETE r- 对于一个节点:
MATCH (n {id: 1})
DELETE n如果您尝试删除仍涉及关系的节点,您将收到Neo.ClientError.Schema.ConstraintValidationFailed错误消息,并显示以下消息:
Cannot delete node<41>, because it still has relationships. To delete this node, you must first delete its relationships.我们需要先删除关系,再删除节点,这样:
MATCH (n {id:1})-[r:REL_TYPE]-()
DELETE r, n但是在这里,Cypher 再次为此提供了一个实用的快捷方式DETACH DELETE——它将执行前面的操作:
MATCH (n {id: 1})
DETACH DELETE n您现在拥有所有工具,可以从 Neo4j 创建、更新、删除和读取简单模式。在下一节中,我们将重点介绍模式匹配技术,以最有效的方式从 Neo4j 中读取数据。
模式匹配和数据检索
图数据库的全部力量,尤其是 Neo4j,在于它们能够以超快的方式跟踪关系,从一个节点转到另一个节点。在本节中,我们将解释如何通过模式匹配从 Neo4j 中读取数据,从而充分利用图结构。
模式匹配
让我们进行以下查询:
MATCH ()-[r]-()
RETURN r当我们编写这些类型的查询时,我们实际上是在使用图形数据库执行所谓的模式匹配。以下架构解释了这个概念:
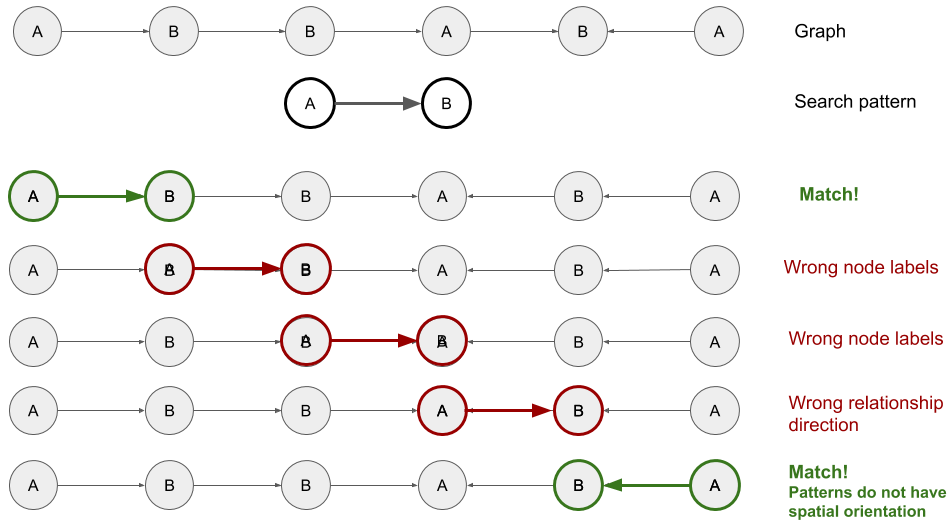
在这种情况下,我们有一个由带有标签A或B的节点组成的有向图。我们正在寻找序列A -> B。模式匹配包括沿图移动模板并查看哪些节点和关系对与其一致。在第一次迭代中,节点标签和关系方向都与搜索模式匹配。但是在第二次和第三次迭代中,节点标签不是预期的,这些模式被拒绝了。在第四次迭代中,标签是正确的,但是关系方向相反,这使得匹配再次失败。最后,在最后一次迭代中,即使没有以正确的顺序绘制,模式也会得到尊重:我们有一个节点A与一个到节点B的出站关系。
测试数据
让我们首先创建一些测试数据进行试验。我们将使用美国各州作为游乐场。我们图中的一个节点将是一个状态,它的两个字母代码、名称和四舍五入的人口作为属性。当这些州通过 type 的关系共享共同边界时,它们是连接的SHARE_BORDER_WITH: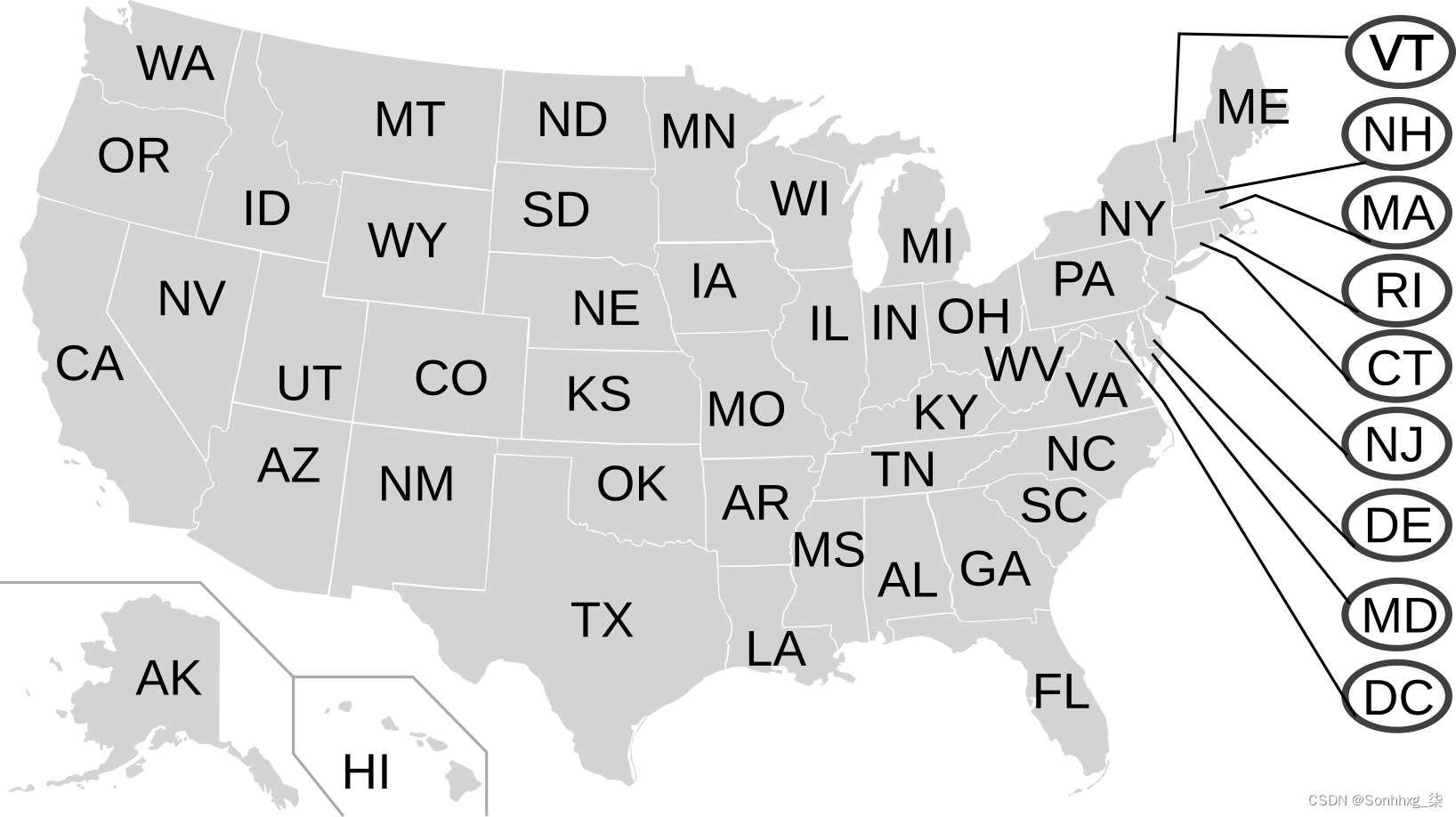
{kind=link}
这是我们的样本数据,从前面的图像创建,仅使用距离佛罗里达州(FL)最多两度的州:
CREATE (FL:State {code: "FL", name: "Florida", population: 21500000})
CREATE (AL:State {code: "AL", name: "Alabama", population: 4900000})
CREATE (GA:State {code: "GA", name: "Georgia", population: 10600000})
CREATE (MS:State {code: "MS", name: "Mississippi", population: 3000000})
CREATE (TN:State {code: "TN", name: "Tennessee", population: 6800000})
CREATE (NC:State {code: "NC", name: "North Carolina", population: 10500000})
CREATE (SC:State {code: "SC", name: "South Carolina", population: 5100000})
CREATE (FL)-[:SHARE_BORDER_WITH]->(AL)
CREATE (FL)-[:SHARE_BORDER_WITH]->(GA)
CREATE (AL)-[:SHARE_BORDER_WITH]->(MS)
CREATE (AL)-[:SHARE_BORDER_WITH]->(TN)
CREATE (GA)-[:SHARE_BORDER_WITH]->(AL)
CREATE (GA)-[:SHARE_BORDER_WITH]->(NC)
CREATE (GA)-[:SHARE_BORDER_WITH]->(SC)
CREATE (SC)-[:SHARE_BORDER_WITH]->(NC)
CREATE (TN)-[:SHARE_BORDER_WITH]->(MS)
CREATE (NC)-[:SHARE_BORDER_WITH]->(TN)我们现在将使用这些数据来理解图遍历。
图遍历
图遍历包括通过沿给定方向的边(关系)从一个节点到其邻居。
方向
虽然在创建关系时必须有方向,但可以通过考虑或不考虑这种方向来执行模式匹配。a两个节点和之间的关系b可以是三种(相对于a):
OUTBOUND: (a) -[r]->(b)
INBOUND: (a)<-[r]- (b)
BOTH: (a) -[r]- (b)我们的美国州图是无向的,所以我们将只使用BOTH关系语法。例如,让我们找到佛罗里达州的直接邻居并返回他们的名字:
MATCH (:State {code: "FL"})-[:SHARE_BORDER_WITH]-(n)
RETURN n.name这导致以下结果:
╒═════════╕
│"n.name" │
╞═════════╡
│"Georgia"│
├─────────┤
│"Alabama"│
└─────────┘还可以查看州人口,并按此值对结果进行排序,不是吗?
MATCH (:State {code: "FL"})-[:SHARE_BORDER_WITH]-(n)
RETURN n.name as state_name, n.population as state_population
ORDER BY n.population DESC这是相应的结果:
╒════════════╤══════════════════╕
│"state_name"│"state_population"│
╞════════════╪══════════════════╡
│"Georgia" │10600000 │
├────────────┼──────────────────┤
│"Alabama" │4900000 │
└────────────┴──────────────────┘在这个查询中,我们只对佛罗里达州的直接邻居感兴趣,这意味着距离起始节点只有一跳。但是使用 Cypher,我们可以遍历更多的关系。
The number of hops
例如,如果我们还想要佛罗里达州邻居的邻居,我们可以使用这个:
MATCH (:State {code: "FL"})-[:SHARE_BORDER_WITH]-(neighbor)-[:SHARE_BORDER_WITH]-(neighbor_of_neighbor)
RETURN neighbor_of_neighbor这将返回六个节点。如果您仔细检查结果,您可能会惊讶地发现它包含例如佛罗里达州的直接邻居阿拉巴马州。没错,但阿拉巴马州也是田纳西州的邻居,田纳西州是佛罗里达州的邻居,所以阿拉巴马州也是佛罗里达州的邻居。如果我们只想要不是佛罗里达州直接邻居的邻居的邻居,我们必须明确排除它们:
MATCH (FL:State {code: "FL"})-[:SHARE_BORDER_WITH]-(neighbor)-[:SHARE_BORDER_WITH]-(neighbor_of_neighbor)
WHERE NOT (FL)-[:SHARE_BORDER_WITH]-(neighbor_of_neighbor)
RETURN neighbor_of_neighbor这一次,查询只返回四个结果:南卡罗来纳州、北卡罗来纳州、田纳西州和密西西比州。
可变长度模式
当关系是相同类型时,如我们的示例,或者,如果我们不关心关系类型,我们可以使用以下快捷方式:
MATCH (:State {code: "FL"})-[:SHARE_BORDER_WITH*2]-(neighbor_of_neighbor)
RETURN neighbor_of_neighbor这将返回与我们在上一节中使用此查询相同的六个结果:
(FL:State {code: "FL"})-[:SHARE_BORDER_WITH]-(neighbor)-[:SHARE_BORDER_WITH]-(neighbor_of_neighbor)您可以使用以下语法为跃点数指定下限值和上限值:
[:SHARE_BORDER_WITH*<lower_value>..<upper_value>]例如,[:SHARE_BORDER_WITH*2..3]将返回具有两个或三个分离度的邻居。
*甚至可以使用符号来使用任何路径长度,如下所示:
[:SHARE_BORDER_WITH*]无论关系的数量如何,这都会匹配路径。但是,不建议使用此语法,因为它会导致性能大幅下降。
可选匹配
一些州与美国的另一个州没有任何边界。让我们将阿拉斯加添加到我们的测试图中:
CREATE (CA:State {code: "AK", name: "Alaska", population: 700000 })在阿拉斯加的情况下,我们之前编写的获取邻居的查询实际上将返回零结果:
MATCH (n:State {code: "AK"})-[:SHARE_BORDER_WITH]-(m)
RETURN n, m事实上,没有任何模式与序列匹配("AK")-SHARE_BORDER_WITH-()。
在某些情况下,我们可能希望在结果中看到阿拉斯加。例如,知道阿拉斯加有零个邻居本身就是信息。在这种情况下,我们将使用OPTIONAL MATCH模式匹配:
MATCH (n:State {code: "AK"})
OPTIONAL MATCH (n)-[:SHARE_BORDER_WITH]-(m)
RETURN n.name, m.name此查询返回以下结果:
╒════════╤════════╕
│"n.name"│"m.name"│
╞════════╪════════╡
│"Alaska"│null │
└────────┴────────┘邻居名称m.name是NULL因为没有找到邻居,但阿拉斯加是结果的一部分。
我们现在对 Cypher 执行模式匹配的方式有了更好的了解。下一节将展示如何执行聚合,例如countor sum,以及处理对象列表。
使用聚合函数
为我们数据库中的实体计算一些聚合数量通常非常有用,例如社交图中的朋友数量或电子商务网站的订单总价。我们将在这里发现如何使用 Cypher 进行这些计算。
计数、求和和平均
与 SQL 类似,您可以使用 Cypher 计算聚合。与 SQL 的主要区别在于不需要使用GROUP BY语句;所有不在聚合函数中的字段都将用于创建组:
MATCH (FL:State {code: "FL"})-[:SHARE_BORDER_WITH]-(n)
RETURN FL.name as state_name, COUNT(n.code) as number_of_neighbors正如预期的那样,结果如下:
╒════════════╤═════════════════════╕
│"state_name"│"number_of_neighbors"│
╞════════════╪═════════════════════╡
│"Florida" │2 │
└────────────┴─────────────────────┘可以使用以下聚合函数:
- AVG(expr): 可用于数值和持续时间
- COUNT(expr): 非空的行数expr
- MAX(expr)expr:超过组的最大值
- MIN(expr)expr:组的最小值
- percentileCont(expr, p):组内的p(百分比)expr,插值
- percentileDisc(expr, p):超过组的p(百分比)expr
- stDev(expr)expr:超过组的标准差
- stDevP(expr)expr:整个组的总体标准差
- SUM(expr): 可用于数值和持续时间
- COLLECT(expr): 看下一节
例如,我们可以计算一个州人口与居住在其相邻州的所有人口之和之间的比率,如下所示:
MATCH (s:State)-[:SHARE_BORDER_WITH]-(n)
WITH s.name as state, toFloat(SUM(n.population)) as neighbor_population, s.population as pop
RETURN state, pop, neighbor_population, pop / neighbor_population as f
ORDER BY f desc创建对象列表
有时将多行聚合到一个对象列表中很有用。在这种情况下,我们将使用以下内容:
COLLECT例如,如果我们想创建一个包含与科罗拉多州接壤的州代码的列表:
MATCH (:State {code: "FL"})-[:SHARE_BORDER_WITH]-(n)
RETURN COLLECT(n.code)这将返回以下结果:
["GA","AL"]取消嵌套对象
取消嵌套包括将对象列表转换为行,每行包含列表中的一项。它与 完全相反COLLECT,它将对象组合成一个列表。
使用 Cypher,我们将使用以下语句:
UNWIND例如,以下两个查询是等价的:
MATCH (:State {code: "FL"})-[:SHARE_BORDER_WITH]-(n)
WITH COLLECT(n.code) as codes
UNWIND codes as c
RETURN c
// is equivalent to, since COLLECT and UNWIND cancel each other:
MATCH (CO:State {code: "FL"})-[:SHARE_BORDER_WITH]-(n)
RETURN n.cod这将返回我们众所周知的两个状态代码。
该UNWIND操作对于数据导入很有用,因为某些文件的格式可以将多条信息聚合在一行中。根据数据格式,在将数据导入 Neo4j 时,此功能很有用,我们将在下一节中看到。
从 CSV 或 JSON 导入数据
即使您以 Neo4j 作为核心数据库开始您的业务,您也很可能必须将一些静态数据导入到您的图表中。我们还需要在本书中执行这种操作。在本节中,我们详细介绍了使用不同工具和不同输入数据格式批量馈送 Neo4j 的几种方法。
从 Cypher 导入数据
Cypher 本身包含用于从本地或远程文件以 CSV 格式导入数据的实用程序。
文件位置
无论是导入 CSV、JSON 还是其他文件格式,此文件都可以位于以下位置:
- 在线并可通过公共 URL 访问:'http://example.com/data.csv'
- 在您的本地磁盘上:'files:///data.csv'
本地文件:导入文件夹
在后一种情况下,使用默认的 Neo4j 配置,文件必须在/imports文件夹中。使用 Neo4j Desktop 查找此文件夹非常简单:
- 单击您感兴趣的图表上的管理按钮。
- 识别新窗口顶部的打开文件夹按钮。
- 单击此按钮旁边的箭头并选择Import。
这将在您的图形导入文件夹中打开您的文件浏览器。
如果您更喜欢命令行,而不是单击Open Folder,您可以使用Open Terminal按钮。在我的本地 Ubuntu 安装中,它会打开一个会话,其工作目录如下:
~/.config/Neo4j Desktop/Application/neo4jDatabases/database-c83f9dc8-f2fe-4e5a-8243-2e9ee29e67aa/installation-3.5.14
您系统上的路径会有所不同,因为您将拥有不同的数据库 ID,并且可能具有不同的 Neo4j 版本。
这个目录结构如下:
$ tree -L 1
.
├── bin
├── certificates
├── conf
├── data
├── import
├── lib
├── LICENSES.txt
├── LICENSE.txt
├── logs
├── metrics
├── NOTICE.txt
├── plugins
├── README.txt
├── run
└── UPGRADE.txt
10 directories, 5 files以下是有关此目录内容的一些注释:
- data:实际上包含您的数据,尤其是data/databases/graph.db/您可以从一台计算机复制到另一台计算机以检索图形数据的文件夹。
- bin: 包含一些有用的可执行文件,例如我们将在下一节讨论的导入工具。
- import:将您要导入的文件放到您的图表中。
- plugins: 如果你已经安装了 APOC 插件,你应该会apoc-<version>.jar在那个文件夹中看到。所有插件都会在这里下载,如果我们要添加 Neo4j Desktop 官方不支持的插件,复制jar这个目录下的文件就够了。
更改默认配置以从另一个目录导入文件
可以通过更改配置文件中的dbms.directories.import参数来配置默认的导入文件夹conf/neo4j.conf:
# This setting constrains all `LOAD CSV` import files to be under the `import` directory. Remove or comment it out to
# allow files to be loaded from anywhere in the filesystem; this introduces possible security problems. See the
# `LOAD CSV` section of the manual for details.
dbms.directories.import=importCSV 文件
CSV 文件是使用LOAD CSVCypher 语句导入的。根据您是否可以/想要使用标头,语法略有不同。
没有标题的 CSV 文件
如果您的文件不包含列标题,或者您更愿意忽略它们,则可以按索引引用列:
LOAD CSV FROM 'path/to/file.csv' AS row
CREATE (:Node {name: row[1]带标题的 CSV 文件
但是,在大多数情况下,您将拥有一个包含命名列的 CSV 文件。在这种情况下,使用列标题而不是数字作为参考要方便得多。通过在查询中指定WITH HEADERS选项, Cypher 可以做到这一点:LOAD CSV
LOAD CSV WITH HEADERS FROM '<path/to/file.csv>' AS row
CREATE (:Node {name: row.name})让我们用一个例子来练习。usa_state_neighbors_edges.csv CSV 文件具有以下结构:
code;neighbor_code
NE;SD
NE;WY
NM;TX
...这可以解释如下:
- code是两个字母的州标识符(例如,科罗拉多州的 CO)。
- neighbor_code是与当前状态共享边界的状态的两个字母标识符。
我们的目标是创建一个图,其中每个状态都是一个节点,如果两个状态共享一个共同的边界,我们将创建它们之间的关系。
那么,让我们开始吧:
- 此 CSV 文件中的字段用分号分隔;,因此我们必须使用该FIELDTERMINATOR选项(默认为逗号,,)。
- 第一列包含一个州代码;我们需要创建关联节点。
- 最后一列还包含一个状态代码,所以我们必须检查这个状态是否已经存在,如果不存在则创建它。
- 最后,我们可以创建两个状态之间的关系,任意选择从第一个状态定向到第二个状态:
LOAD CSV WITH HEADERS FROM "file:///usa_state_neighbors_edges.csv" AS row FIELDTERMINATOR ';'
MERGE (n:State {code: row.code})
MERGE (m:State {code: row.neighbor_code})
MERGE (n)-[:SHARE_BORDER_WITH]->(m)这导致此处显示的图表是美国的代表: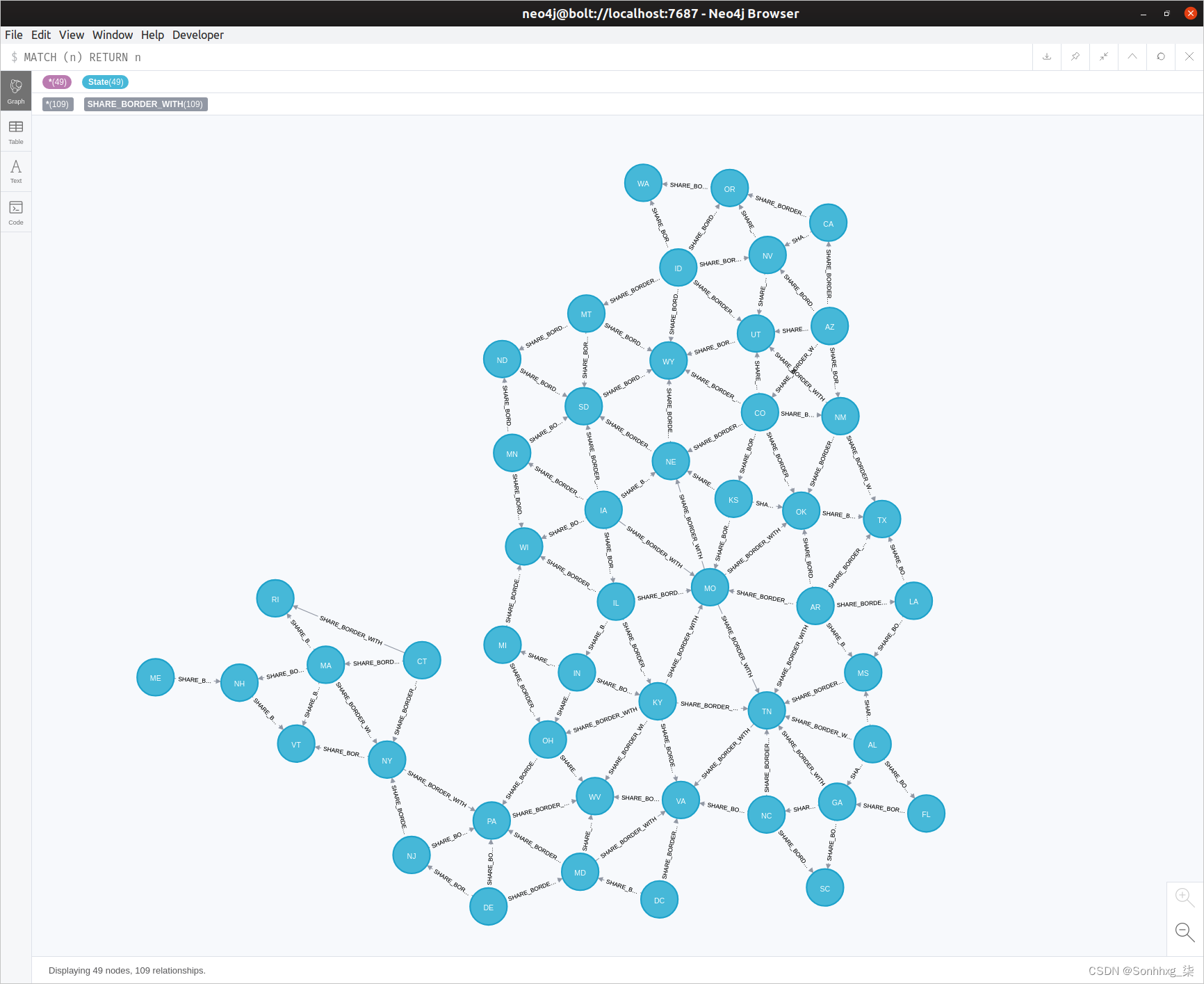
有趣的是,纽约州的特殊作用将图表完全分为两部分:纽约州一侧的州永远不会与纽约州另一侧的州相连。第 6 章,节点重要性,将描述能够检测此类节点的算法。
我们当前的图结构至少有一个问题:它不包含没有共同边界的州,例如阿拉斯加和夏威夷。为了解决这个问题,我们将使用另一个格式不同但也包含没有共享边界的状态的数据文件:
code;neighbors
CA;OR,NV,AZ
NH;VT,MA,ME
OR;WA,CA,ID,NV
...
AK;""
...如您所见,我们现在每个州都有一行,其中包含其邻居列表。如果该州没有任何邻居,则它存在于文件中,但该neighbors列包含空值。
导入这个文件的查询可以这样写:
LOAD CSV WITH HEADERS FROM "file:///usa_state_neighbors_all.csv" AS row FIELDTERMINATOR ';'
WITH row.code as state, split(row.neighbors, ',') as neighbors
MERGE (a:State {code: state})
WITH a, neighbors
UNWIND neighbors as neighbor
WITH a, neighbor
WHERE neighbor <> ""
MERGE (b:State {code: neighbor})
CREATE (a)-[:SHARE_BORDER_WITH]->(b)一些注释可以更好地理解这个查询:
- 我们使用该split()函数从以逗号分隔的状态代码列表创建列表。
- 操作员为相邻代码列表中的每个元素UNWIND创建一行。
- 我们需要从查询的其余部分中过滤掉没有邻居的状态,因为 Cypher 在合并节点时不能使用NULL值作为标识符。但是,由于该WHERE子句发生在第一个 之后MERGE,仍然会创建没有邻居的状态。
如果您在使用时看到错误或意外结果LOAD CSV,您可以通过返回中间结果进行调试。例如,这可以像这样实现:
LOAD CSV WITH HEADERS FROM "file:///usa_state_neighbors_all.csv" AS row FIELDTERMINATOR ';'
WITH row LIMIT 10
RETURN row使用LIMIT函数不是强制性的,但如果您使用非常大的文件,则可以提高性能。
Eager operations
如果您仔细观察,Neo4j Desktop 会在查询文本编辑器旁边显示一个小的警告标志。如果您单击此警告,它将显示有关它的解释。在我们的例子中,它是这样说的:
The execution plan for this query contains the Eager operator, which forces all dependent data to be materialized in main memory before proceeding这与数据导入没有直接关系,但这往往是我们第一次面对这个警告信息,所以让我们试着理解它。
Neo4j 文档Eager在这句话中定义了操作符:
换句话说,查询的每条语句在移动到另一行之前针对文件的每一行执行。这通常不是问题,因为一条 Cypher 语句会处理一百个左右的节点,但是在导入大型数据文件时,开销是显而易见的,甚至可能导致OutOfMemory错误。然后需要考虑到这一点。
在数据导入的情况下,使用Eager操作符是因为我们使用的是MERGE语句,这迫使 Cypher 检查整个数据文件是否存在节点和关系。
为了克服这个问题,有几种解决方案是可能的,具体取决于输入数据:
- 如果我们确定数据文件不包含重复项,我们可以将MERGE操作替换为CREATE.
- 但大多数时候,我们需要将import语句拆分为两个或多个部分。
加载美国各州的解决方案是使用三个连续查询:
// 首先创建起始状态节点,如果它不存在
LOAD CSV WITH HEADERS FROM "file:///usa_state_neighbors_edges.csv" AS row FIELDTERMINATOR ';'
MERGE (:State {code: row.code})
// 如果不存在则创建结束状态节点
LOAD CSV WITH HEADERS FROM "file:///usa_state_neighbors_edges.csv" AS row FIELDTERMINATOR ';
MERGE (:State {code: row.neighbor_code})
// 然后创建关系
LOAD CSV WITH HEADERS FROM "file:///usa_state_neighbors_edges.csv" AS row FIELDTERMINATOR ';'
MATCH (n:State {code: row.code})
MATCH (m:State {code: row.neighbor_code})
MERGE (n)-[:SHARE_BORDER_WITH]->(m)前两个查询创建State节点。如果一个状态代码在文件中出现多次,该MERGE操作将注意创建两个具有相同代码的不同节点。
完成此操作后,我们再次读取同一文件以创建邻域关系:我们从State使用操作从图中读取节点开始MATCH,然后在它们之间创建唯一关系。在这里,我们再次使用MERGE操作而不是CREATE防止在相同的两个节点之间出现两次相同的关系。
我们不得不将前两个语句拆分为两个单独的查询,因为它们作用于同一个节点标签。但是,像下面这样的语句将不依赖于Eager运算符:
LOAD CSV WITH HEADERS FROM "file:///data.csv" AS row
MERGE (:User {id: row.user_id})
MERGE (:Product {id: row.product_id})事实上,由于两个MERGE节点涉及两个不同的节点标签,Cypher 不必执行第一行的所有操作以确保与第二行没有冲突;操作是独立的。
在导入的 APOC 实用程序部分,我们将研究美国数据集的另一种表示形式,我们将能够在不编写三个不同查询的情况下导入它。
在此之前,我们先来看看内置的 Neo4j 导入工具。
从命令行导入数据
Neo4j 还提供了一个命令行导入工具。可执行文件位于$NEO4J_HOME/bin/import. 它需要几个 CSV 文件:
- 具有以下格式的节点的一个或多个 CSV 文件:
id:ID,:LABEL,code,name,population_estimate_2019:int
1,State,CA,California,40000000
2,State,OR,Oregon,4000000
3,State,AZ,Arizona,7000000- 节点必须具有唯一标识符。此标识符必须用:ID关键字标识。
- 所有字段都被解析为字符串,除非在头中使用:type语法指定类型。
- 一个或多个 CSV 文件,用于具有以下格式的关系:
:START_ID,:END_ID,:TYPE,year:int
1,2,SHARE_BORDER_WITH,2019
1,3,SHARE_BORDER_WITH,2019创建数据文件并将其放置在import文件夹中后,您可以运行以下命令:
bin/neo4j-admin import --nodes=import/states.csv --relationships=import/rel.csv如果您有非常大的文件,导入工具会更加方便,因为它可以管理压缩文件(.tar、.gz或.zip),还可以理解单独文件中的标头定义,从而更容易打开和更新。
有关导入工具的完整文档可以在https://neo4j.com/docs/operations-manual/current/tutorial/import-tool/ 找到。
用于进口的 APOC 实用程序
APOC 库是一个 Neo4j 扩展,其中包含几个工具来简化使用此数据库的工作:
- 数据导入和导出:从 CSV 和 JSON 以及 HTML 或 Web API 等不同格式导入和导出
- 数据结构:高级数据操作,包括类型转换函数、映射和集合管理
- 高级图形查询功能:增强模式匹配的工具,包括更多条件
- 图形投影:具有虚拟节点和/或关系
图算法的第一个实现是在该库中完成的,即使它们现在已被弃用,取而代之的是我们将在本书第 2 部分中发现的专用插件。
在执行本章其余部分的代码时,您可能会收到如下错误消息:
There is no procedure with the name apoc.load.jsonParams registered for this database instance如果是这样,您必须将以下行添加到您的neo4j.conf设置中(Neo4j Desktop 中“图形管理”区域中的“设置”选项卡):
dbms.security.procedures.whitelist= apoc.load.*CSV 文件
APOC 库包含导入 CSV 文件的过程。语法如下:
CALL apoc.load.csv('')
YIELD name, age
CREATE (:None {name: name, age: age})作为练习,尝试使用此过程导入美国州数据。
JSON 文件
更重要的是,APOC 还包含一个从 JSON 导入数据的过程,这在 vanilla Cypher 中是不可能的。查询的结构如下:
CALL apoc.load.json('http://...') AS value
UNWIND value.items AS item
CREATE (:Node {name: item.name}例如,我们将使用 GitHub API 从 GitHub 导入一些数据:https ://developer.github.com/v3/ 。
我们可以通过以下请求获取组织 Neo4j 拥有的存储库列表:
curl -u "<your_github_username>" https://api.github.com/orgs/neo4j/repos这是您可以获得的给定存储库的数据示例(带有选定的字段):
{
"id": 34007506,
"node_id": "MDEwOlJlcG9zaXRvcnkzNDAwNzUwNg==",
"name": "neo4j-java-driver",
"full_name": "neo4j/neo4j-java-driver",
"private": false,
"owner": {
"login": "neo4j",
"id": 201120,
"node_id": "MDEyOk9yZ2FuaXphdGlvbjIwMTEyMA==",
"html_url": "https://github.com/neo4j",
"followers_url": "https://api.github.com/users/neo4j/followers",
"following_url": "https://api.github.com/users/neo4j/following{/other_user}",
"repos_url": "https://api.github.com/users/neo4j/repos",
"type": "Organization"
},
"html_url": "https://github.com/neo4j/neo4j-java-driver",
"description": "Neo4j Bolt driver for Java",
"contributors_url": "https://api.github.com/repos/neo4j/neo4j-java-driver/contributors",
"subscribers_url": "https://api.github.com/repos/neo4j/neo4j-java-driver/subscribers",
"commits_url": "https://api.github.com/repos/neo4j/neo4j-java-driver/commits{/sha}",
"issues_url": "https://api.github.com/repos/neo4j/neo4j-java-driver/issues{/number}",
"created_at": "2015-04-15T17:08:15Z",
"updated_at": "2020-01-02T10:20:45Z",
"homepage": "",
"size": 8700,
"stargazers_count": 199,
"language": "Java",
"license": {
"key": "apache-2.0",
"name": "Apache License 2.0",
"spdx_id": "Apache-2.0",
"node_id": "MDc6TGljZW5zZTI="
},
"default_branch": "4.0"
}我们将使用 APOC 将这些数据导入到新图表中。为此,我们必须通过在 Neo4j 配置文件 ( neo4j.conf) 中添加以下行来启用 APOC 文件导入:
apoc.import.file.enabled=true 现在让我们阅读这些数据。您可以通过以下方式查看该apoc.load.json过程的结果:
CALL apoc.load.json("neo4j_repos_github.json") YIELD value AS item
RETURN item
LIMIT 1此查询生成与前面的示例 JSON 类似的结果。要访问每个 JSON 文件中的字段,我们可以使用item.<field>符号。因此,这里是如何为每个存储库和所有者创建一个节点,以及所有者和存储库之间的关系:
CALL apoc.load.json("neo4j_repos_github.json") YIELD value AS item
CREATE (r:Repository {name: item.name,created_at: item.created_at, contributors_url: item.contributors_url} )
MERGE (u:User {login: item.owner.login})
CREATE (u)-[:OWNS]->(r)检查图表的内容,我们可以看到这种模式: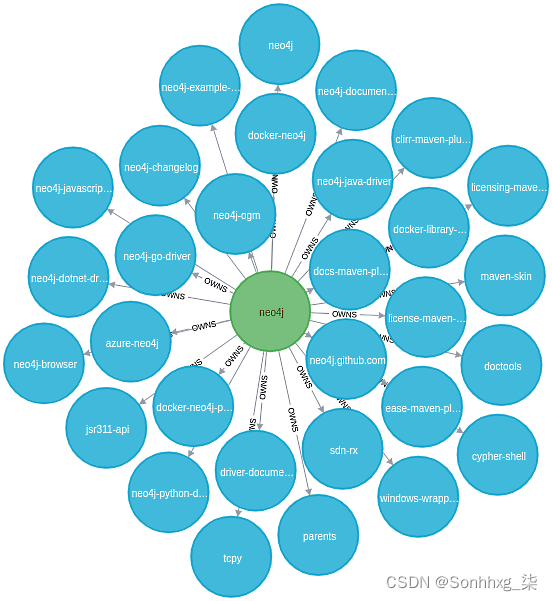
我们可以这样做将所有贡献者导入 Neo4j 存储库:
CALL apoc.load.json("neo4j_neo4j_contributors_github.json")
YIELD value AS item
MATCH (r:Repository {name: "neo4j"})
MERGE (u:User {login: item.login})
CREATE (u)-[:CONTRIBUTED_TO]->(r)从 Web API 导入数据
您可能已经注意到 GitHub 返回的 JSON 包含一个 URL,用于扩展我们对存储库或用户的了解。例如,在neo4j_neo4j_contributors_github.json文件中,有一个关注者 URL。让我们看看如何使用 APOC 为图形提供这个 API 调用的结果。
设置参数
我们可以使用以下语法在 Neo4j 浏览器中设置参数:
:params {"repo_name": "neo4j"}然后可以在以后的查询中使用以下$repo_name符号引用这些参数:
MATCH (r:Repository {name: $repo_name}) RETURN r当参数在查询中的多个位置使用时,这可能非常有用。
在下一节中,我们将直接从 Cypher 向 GitHub API 执行 HTTP 请求。您需要一个 GitHub 令牌来进行身份验证并保存为参数:
:params {"token": "<your_token>"}调用 GitHub Web API
我们可以使用apoc.load.jsonParams从 Web API 加载 JSON 文件,在此过程的第二个参数中设置 HTTP 请求标头:
CALL apoc.load.json("neo4j_neo4j_contributors_github.json") YIELD value AS item
MATCH (u:User {login: item.login})
CALL apoc.load.jsonParams(item.followers_url, {Authorization: 'Token ' + $token}, null) YIELD value AS contrib
MERGE (f:User {login: contrib.login})
CREATE (f)-[:FOLLOWS]->(u)执行导入时,我得到以下结果:
Added 439 labels, created 439 nodes, set 439 properties, created 601 relationships, completed after 12652 ms.当您运行它时,这可能会有所不同,因为给定用户的关注者会随着时间的推移而发展。这是生成的图表,其中用户以绿色显示,存储库以蓝色显示: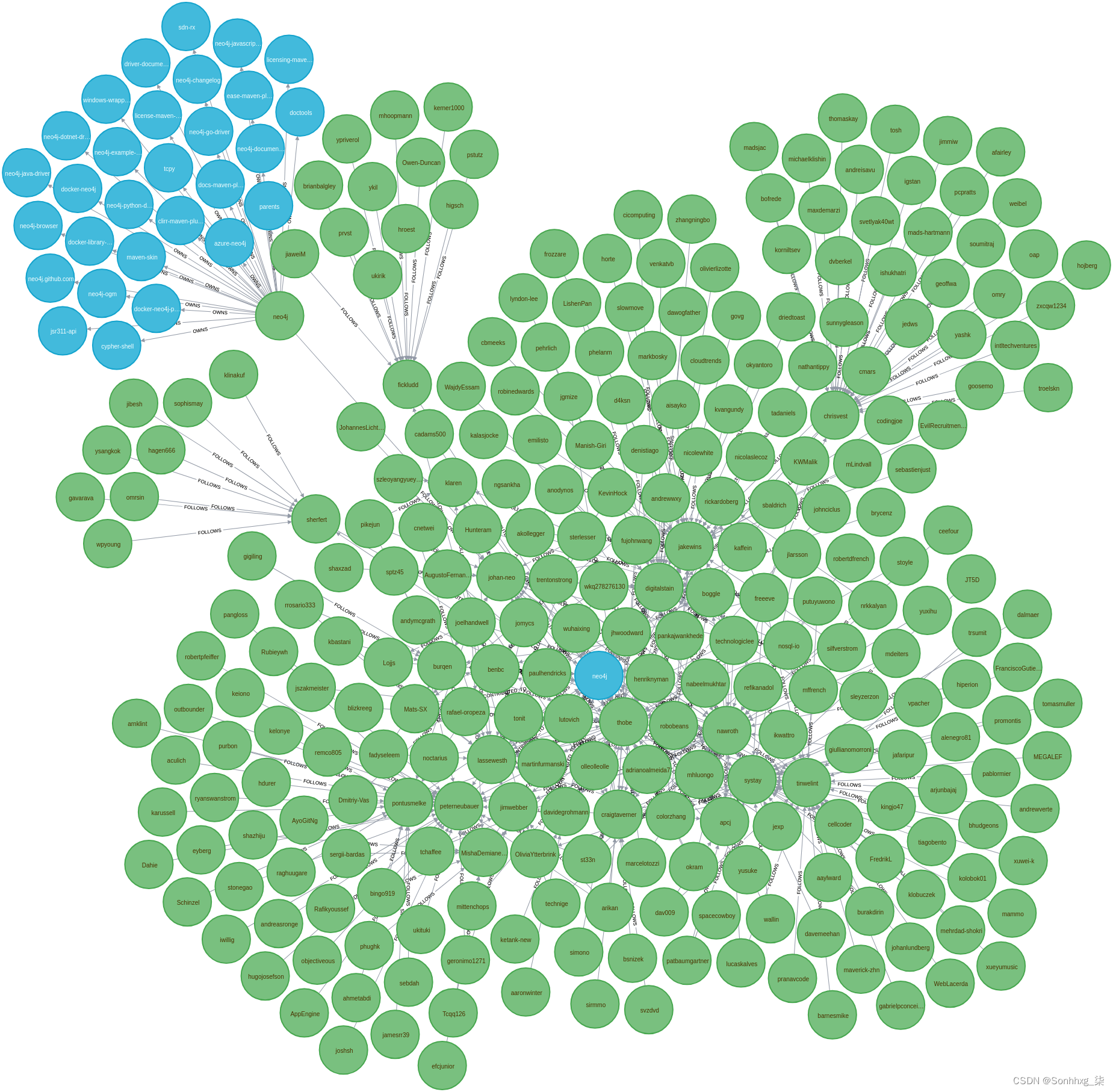
您可以使用任何提供的 URL 来丰富您的图表,具体取决于您要执行的分析类型:您可以添加提交、贡献者、问题等。
导入方法总结
选择正确的工具来导入数据主要取决于其格式。以下是一些总体建议:
- 如果您只有 JSON 文件,那么apoc.load.json这是您唯一的选择。
- 如果您使用的是 CSV 文件,则:
- 如果您的数据很大,请从命令行使用导入工具。
- 如果您的数据是中小型数据,您可以使用 APOC 或 Cypher LOAD CSV,.
这将关闭我们关于数据导入的部分,在那里我们学习了如何使用现有数据(来自 CSV、JSON,甚至通过直接调用 Web API)来为 Neo4j 图形提供数据。我们将在本书中使用这些工具来获得有意义的数据来运行算法。
在继续使用这些算法之前,需要最后一步。事实上,与 SQL 一样,通常有几个 Cypher 查询产生相同的结果,但并非所有查询都具有相同的效率。下一节将向您展示如何衡量效率并处理一些良好实践以避免主要警告。
测量性能并调整查询以提高速度
为了衡量 Cypher 查询性能,我们将不得不查看 Cypher 查询计划器,它详细说明了幕后执行的操作。在本节中,我们将介绍如何访问 Cypher 执行计划的概念。在以一个众所周知的例子结束之前,我们还将处理一些好的做法,以避免在性能方面出现最差的操作。
密码查询计划器
与使用 SQL 一样,您可以检查 Cypher 查询计划器以了解幕后发生的事情以及如何改进您的查询。有两种选择:
- EXPLAIN:如果您不希望运行查询,EXPLAIN则不会对您的图表进行任何更改。
- PROFILE:这将实际运行查询并更改您的图表,同时测量性能。
在本章的其余部分,我们将使用 Facebook 在 2012 年发布的数据集,用于由 Kaggle 主办的招聘竞赛。数据集可以在这里下载:https://www.kaggle.com/c/FacebookRecruiting/data。我只使用了训练样本,其中包含匿名人员之间的联系列表。它包含1,867,425 个节点和 9,437,519 条边。
我们已经讨论了可以在查询计划器中识别的操作之一:Eager操作,我们需要尽可能避免,因为它们确实会损害性能。让我们看看更多的运算符以及如何调整我们的查询以提高性能。
选择具有给定节点id并获取 Cypher 查询解释的简单查询可以编写如下:
PROFILE
MATCH (p { id: 1000})
RETURN p执行此查询时,结果单元格中会出现一个名为Plan的新选项卡,如以下屏幕截图所示:

查询配置文件显示了运算符的使用,该运算符在图形的节点上AllNodesScan执行搜索。ALL在这种特定情况下,这不会产生太大影响,因为我们只有一个节点标签Person. 但是,如果您的图表恰好有许多不同的标签,则对所有节点执行扫描可能会非常缓慢。因此,强烈建议在我们的查询中明确设置节点标签和感兴趣的关系类型:
PROFILE
MATCH (p:Person { id: 1000})
RETURN p在这种情况下,Cypher 使用NodeByLabelScan如下截图所示的操作:

在性能方面,在我的笔记本电脑上执行此查询大约需要 650 毫秒,在这两种情况下。在某些情况下,由于 Neo4j 索引,性能可以进一步提高。
Neo4j 索引
Neo4j 索引用于轻松找到模式匹配查询的起始节点。我们来看看创建索引对执行计划和执行时间的影响:
CREATE INDEX ON :Person(id)让我们再次运行我们的查询:
PROFILE
MATCH (p:Person { id: 1000})
RETURN p通过操作可以看到查询现在正在使用我们的索引NodeIndexSeek,这将执行时间减少到了1毫秒:
也可以使用以下语句删除索引:
DROP INDEX ON :Person(id)Neo4j 索引系统还支持组合索引和全文索引。检查https://neo4j.com/docs/cypher-manual/current/schema/index/了解更多信息。
返回加载 CSV
Eager记住我们在本章前面讨论过操作符。我们正在使用以下LOAD CSV声明进口美国各州:
LOAD CSV WITH HEADERS FROM "file:///usa_state_neighbors_edges.csv" AS row FIELDTERMINATOR ';'
MERGE (n:State {code: row.code})
MERGE (m:State {code: row.neighbor_code})
MERGE (n)-[:SHARE_BORDER_WITH]->(m)为了更好地理解它并确定此警告消息的根本原因,我们向 Neo4j 询问EXPLAIN它。然后我们会得到一个复杂的图表,就像这里显示的那样:
我为您强调了三个要素:
- 紫色部分对应于第一个MERGE陈述。
- 绿色部分包含与第二条MERGE语句相同的操作。
- 读取框是Eager操作。
从该图中,您可以看到Eager操作是在步骤 1(第一个MERGE)和步骤 2(第二个MERGE)之间执行的。这是您的查询需要拆分的地方,以避免使用此运算符。
您现在了解了更多关于如何理解 Cypher 在执行查询时执行的操作以及如何识别和修复瓶颈的信息。是时候根据时间实际衡量查询性能了。为此,我们将在社交网络中使用著名的朋友的例子。
朋友的例子
在谈到性能时,朋友之友的例子是支持 Neo4j 的最著名的论据。由于众所周知 Neo4j 在遍历关系方面的性能令人难以置信,与其他数据库引擎相反,我们预计此查询的响应时间会非常低。
Neo4j 浏览器在结果单元格中显示查询执行时间:
它也可以以编程方式测量。例如,使用 Neo4j 包中的 Neo4j Python 驱动程序,我们可以通过以下方式测量总执行时间和流式传输时间:
from neo4j import GraphDatabase
URL = "bolt://localhost:7687"
USER = "neo4j"
PWD = "neo4j"
driver = GraphDatabase.driver(URL, auth=(USER, PWD)
query = "MATCH (a:Person {id: 203749})-[:IS_FRIEND_WITH]-(b:Person) RETURN count(b.id)"
with driver.session() as session:
with session.begin_transaction() as tx:
result = tx.run(query)
summary = result.summary()
avail = summary.result_available_after # ms
cons = summary.result_consumed_after # ms
total_time = avail + cons使用该代码,我们能够测量不同起始节点、不同程度和不同深度(一级朋友、二级...直到四级)的总执行时间。
下图显示了结果。如您所见,对于所有深度 1 查询,在提供结果之前的时间量低于 1 毫秒,与节点的一级邻居数无关:
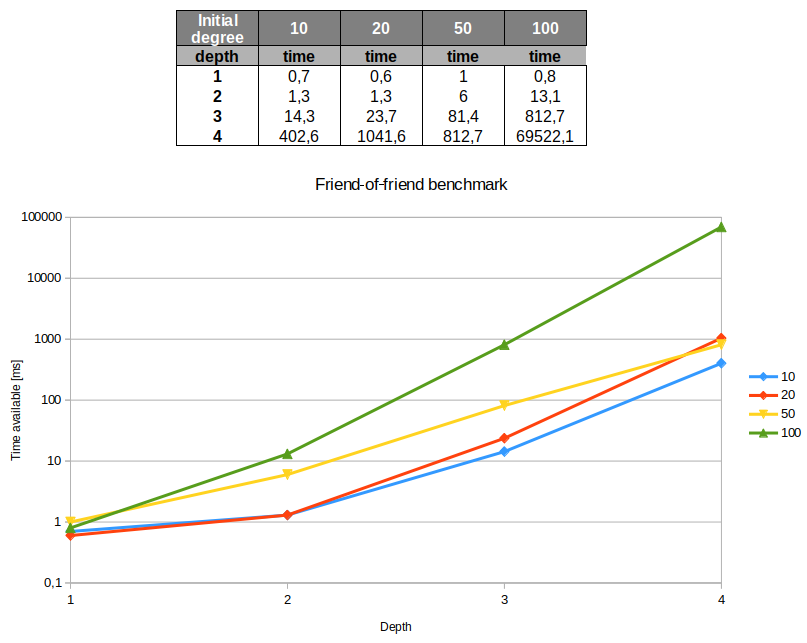
正如预期的那样,Neo4j 获取结果所需的时间随着查询的深度而增加。但是,您可以看到,只有当有很多朋友时,初始节点的朋友数量之间的时间差才变得非常重要。从深度 4 有 100 个好友的节点开始,匹配节点的数量接近 450,000,大约在 1 分钟内识别。
关于这些配置的更多信息将在第 12 章,Neo4j at Scale中给出。
概括
在本章中,您学习了如何导航到 Neo4j 图表。您现在可以使用 Cypher 执行 CRUD 操作,创建、更新和删除节点、关系及其属性。
但是 Neo4j 的全部功能在于关系遍历(从一个节点到其邻居的速度非常快)和您现在可以使用 Cypher 执行的模式匹配。
您还发现了如何使用 Cypher 查询计划器来衡量您的查询性能。这可以帮助您避免一些陷阱,例如Eager加载数据时的操作。它还有助于理解 Cypher 的内部结构并调整您的查询以在速度方面获得更好的性能。
我们知道手头有所有工具可以开始真正使用 Neo4j 并研究一些现实生活中的例子。在下一章中,我们将学习知识图谱。对于许多组织来说,这是图世界的第一个入口点。使用该数据结构,我们将能够为您的客户实施高性能推荐引擎和基于图形的搜索。
问题
- 美国州:
- 找到 Colorado 的一级邻居(代码CO):
- 这些邻居的代码是什么?
- 你能数出有多少使用聚合函数吗?
- 哪些州的邻居数量最多?最低的?考虑ORDER BY条款。
- 找到 Colorado 的一级邻居(代码CO):
- GitHub图增强:
- 从neo4j_repos_github.json,您可以在提供时将项目语言保存为新节点吗?您可以使用新的Language节点标签。
- 如果提供了许可证,您还可以使用新节点保存许可证吗?使用Licence节点标签并将 GitHub 中提供的所有信息保存为属性。
(提示:许可证以以下格式提供):
"license": {
"key": "other",
"name": "Other",
"spdx_id": "NOASSERTION",
"url": null,
"node_id": "MDc6TGljZW5zZTA="
},- 使用 GitHub API,您可以保存用户位置吗?
提示:获取用户信息的 URL 是https://api.github.com/users/<login>。 - 该位置通常包含城市和国家/地区名称,以空格或逗号分隔。你能写一个查询来只保存这对的第一个元素,假设是城市吗?
提示:检查 APOC 文本工具。 - 使用 GitHub API,您可以检索每个 Neo4j 贡献者拥有的存储库吗?
提示:获取给定用户的存储库的 URL 是https://api.github.com/users/<login>/repos。 - Neo4j 贡献者中哪个位置最具代表性?
进一步阅读
- Neo4j 创建的 Cypher 备忘单信息量很大:https ://neo4j.com/docs/cypher-refcard/current/ 。
- 我建议您查看 APOC 插件文档以了解 APOC 的功能并决定是否值得将其包含在您的项目中:https ://neo4j.com/docs/labs/apoc/current/ 。
- 有关数据建模和 Neo4j 性能的更多信息,请参阅 Neo4j High Performance, S. Raj, Packt Publishing。
相关文章
- Neo4j CQL基本使用
- ML之GB:基于MovieLens电影评分数据集利用基于图的推荐算法(Neo4j图数据库+Cypher查询语言)实现对用户进行Top5电影推荐案例
- Neo4j之Cypher:Cypher查询语言的简介、语法、使用案例之详细攻略
- Python编程:py2neo操作neo4j图数据库
- Neo4j简单的样例
- 【Neo4j构建知识图谱】图上的数据科学1:算法项目合集方法梳理【飞机航线作为案例】
- 【Neo4j构建知识图谱】官方服务图谱大型数据集下载与可视化方法【数据集包括:食谱数据、足球、权力的游戏、美国宇航局、英国公司注册、财产所有权、政治捐款】
- 【Neo4j构建知识图谱】cypher操作import导入本地 CSV电影人数据集
- 【Neo4j构建知识图谱】Python调用cypher语言(3):构造关系网(MATCH,CREATE)用法
- 【Neo4j构建知识图谱】Python调用cypher语言(2):批量创建多节点多关系多领域
- NLP模型笔记2022-30:neo4j+py2neo构建数学有向矩阵知识图谱
- NLP模型笔记2022-26:neo4j+py2neo知识图谱构建【中国各城市名与城市经纬度】(代码已开源)
- 图数据库HugeGraph——这个无非是利用cassandra+ES作为后端来做的图数据库,支持分布式而已,要说性能,肯定是没有原生的neo4j强的
- Neo4j图数据库简介和底层原理
- Neo4j数据库入门教程
- 【Neo4j】第 9 章:预测关系
- 【Neo4j】第 5 章:空间数据
- 【Neo4j】第 3 章:使用 Pure Cypher 为您的业务赋能
- 【Neo4j】第 1 章:图数据库
- 【Docker系列】7.Docker-compose 安装neo4j