
GAN在短视频中的AI特效实践(PPT演示)
目录
导读
近年来,以GAN为代表的生成式技术在学术界取得蓬勃发展。在工业界,基于生成式技术的真实感效果也引领了一批爆款特效和应用。快手Y-tech在国内率先将GAN落地于短视频特效制作,并积累了丰富的实践经验,为快手各类人脸爆款特效提供有力技术支持。本文主要介绍快手在高精度人脸属性编辑方面的实践,包括性别、年龄、头发、表情等的生成。
01背景介绍
人脸特效是辅助短视频内容生产的重要组成部分,生动好玩的特效有利于促进短视频内容的消费。传统的人脸特效主要依赖于人脸二维和三维的语义理解,并结合图形图像处理、优秀的产品设计达到吸引用户的目的,但该特效制作存在真实感缺失的局限。
近些年,生成式技术如VAE、GAN、AutoRegressive Model、Normalizing Flow Model等在学术界取得了蓬勃发展。在这其中,GAN是杰出的代表,GAN通过生成器和判别器的相互博弈,使得生成器生成的数据分布接近真实数据分布。自2014年GAN提出以来,GAN生成效果逐渐逼真和高清,广泛应用于图像翻译、图像修复和增强、图像和视频合成等领域。
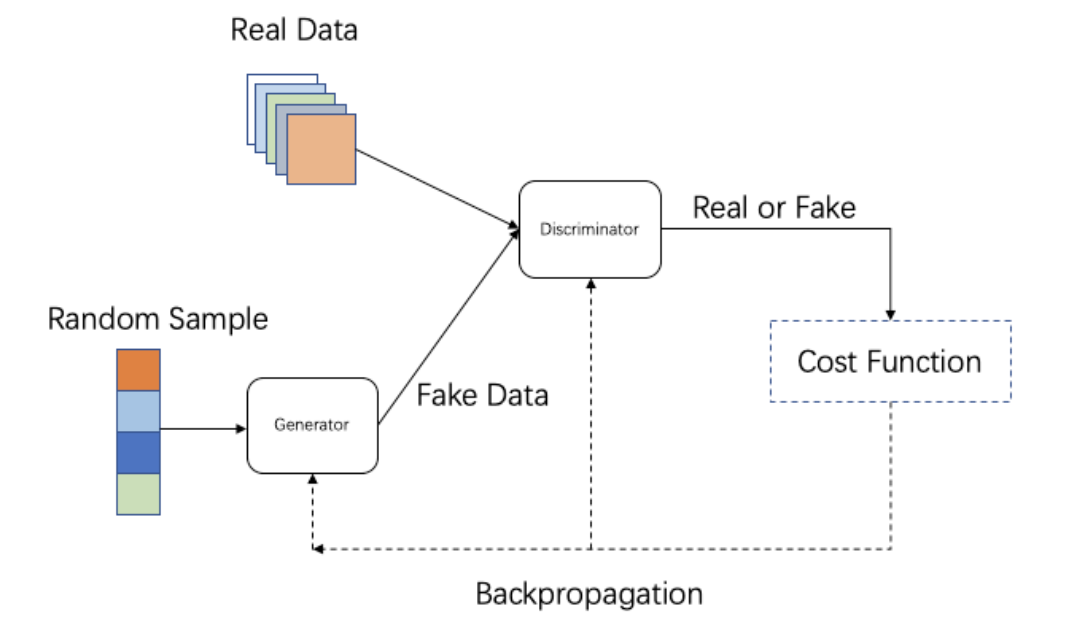
GAN技术对于特效生产具有重要意义:(为什么选择GAN?)
- 第一,GAN生成效果真实感强、清晰度高,可以做到传统特效无法实现的效果。
- 第二, GAN是端到端的效果输出,可节约特效制作成本。
- 第三,GAN可进一步实现自动化的图片和视频生产,降低短视频生产的门槛。
在工业界,GAN技术造就一批爆款特效和应用,海外如FaceAPP的变老、Snapchat的变性别,在国内,快手是最早将GAN落地于短视频特效制作的公司,本文从高精度人脸属性编辑方面介绍GAN在快手的实践工作,如性别、年龄、头发、表情等的生成和变化。
02业务应用
目前,生成式技术在高精度人脸属性方面,主要应用于快手、一甜相机等App的特效模块。
第一,快手魔表。在快手手机端魔表拍摄功能上,自2019年8月陆续推出多款魔表,如变小孩、我的一生、变性别、大笑嘟嘴等表情, 给大家带来新奇体验。
1.变小孩

2.我的一生:

3.变性别:

第二,一甜相机的服务端头发自然生长。发型对于人的美感及形象是至关重要的。与脸型和五官适配的发型可以修饰面部的缺陷,提高一个人的气质与魅力。但是,人们往往没办法很快的改变自己的发型,比如自己本身是短发,想看看变成长发是否能为自己的形象气质加分,那就需要等待数月来让头发长长。传统特效采用假发贴片效果很假,侧脸角度容易露怯,利用生成式技术可实现高精度的真实感头发生成。






03问题分析
在落地实践中, 需要解决如下几个关键问题。
第一,GAN训练不稳定,容易出现斑点、伪影、局部区域扭曲等问题。在落地过程中,快手将GAN模型分为两个阶段,分别为造数据模型和pixel2pixel模型。GAN训练不稳定会导致造数据阶段生成的配对数据失败率高,无法造出大量合格数据提供给后续的pixel2pixel模型,影响了项目的整体进度。
第二,不同落地终端和场景对效果要求不一。(下面从算力进行分析)
(1)服务端。服务端算力足,可采用离线处理方式,时延要求不高。但服务端上传用户图片清晰度和分辨率不一、光照角度等复杂性高。故服务端方案需要做到高清、鲁棒性好。
(2)手机端。从算力角度看,手机端算力不一,算法需跨越几百块手机到上万块手机性能,需解决低延迟和算力低的矛盾。从拍摄场景看,大部分是近距离、正常光照、小角度自拍。故需设计不同机型的细分方案,保证效果的良好体验。
第三,用户体验决定算法目标和优先级。特效最终服务于用户,拍摄体验决定算法优化方案的目标和优先级,比如头发生长需要考虑头发蓬松度和长度,变老需要考虑真实感和美观度的统一。
CVPR 2020GAN论文梳理汇总
1 【时尚编辑】Fashion Editing with Adversarial Parsing Learning
从草图free-form sketches和颜色笔触sparse color strokes来控制编辑图像。
2 【虚拟穿衣】Image Based Virtual Try-on Network from Unpaired Data


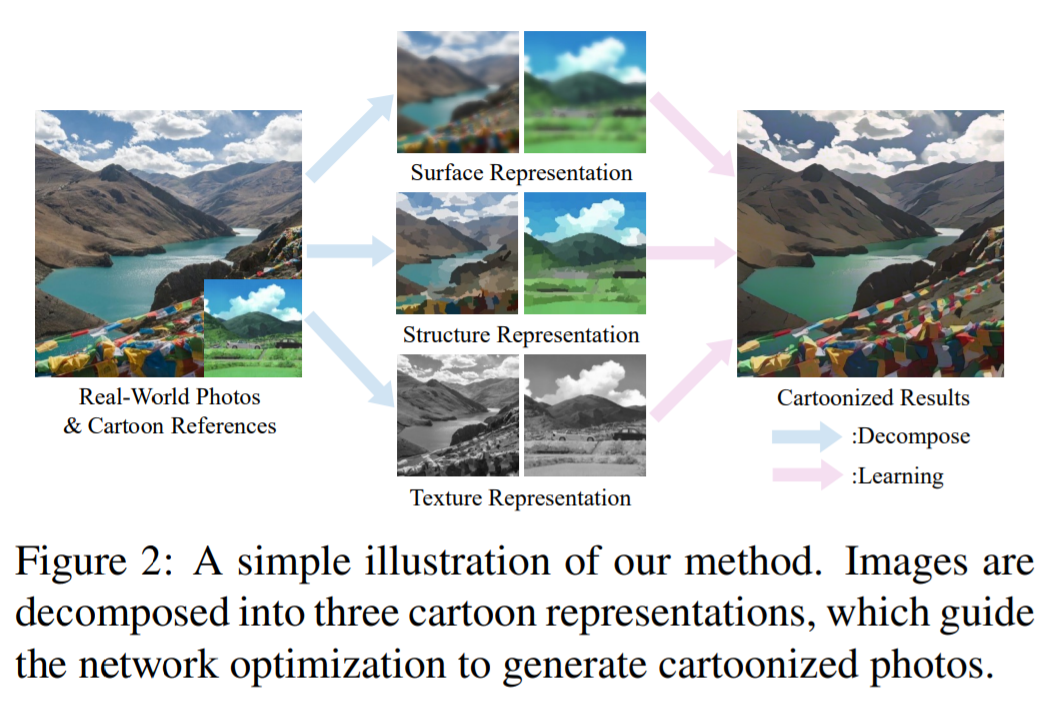
3 【图像卡通化】Learning to Cartoonize Using White-box Cartoon Representations
4 【肖像动画化】PuppeteerGAN: Arbitrary Portrait Animation with Semantic-aware Appearance Transformation

5 【草图上色、注意力机制】Reference-Based Sketch Image Colorization using Augmented-Self Reference and Dense Semantic Correspondence

6 【图像多样性】Diverse Image Generation via Self-Conditioned GANs
介绍了一种简单而有效的无监督方法来生成逼真而多样的图像。通过训练无需人工类别标签的类条件GAN模型(自动生成的标签为条件,根据在判别器特征空间聚类自动得出)。

7 【注意力机制、超分】Learning Texture Transformer Network for Image Super-Resolution

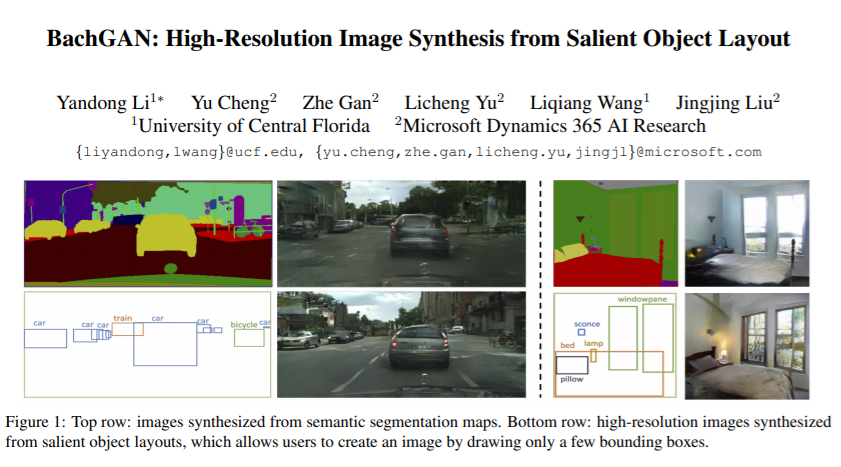
8 【基于物体布局生成】BachGAN: High-Resolution Image Synthesis from Salient Object Layout
9 【解耦表征】MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation
提出MixNMatch,一个可以在极小监督情况下完成对图像中的背景、物体姿势、形状和纹理等进行分开(解耦)的条件生成模型,分解后可以通过混合它们以生成新的图像。方法基于2019年的FineGAN(一个无条件的生成模型)框架进行改进,以适用于条件式的图像转换任务。所用的监督信息仅仅是bounding box,而无需其他监督信息。

10 【图像分离、去雨/反射/阴影等】Deep Adversarial Decomposition: A Unified Framework for Separating Superimposed Images

11【文档阴影去除】BEDSR-Net: A Deep Shadow Removal Network from a Single Document Image

相关文章
- vivo AI 计算平台的 ACK 混合云实践
- 百度AI开放平台,文字识别接口
- 少儿编程:AI人工智能时代、每个孩子都应该学习编程的8个理由
- L1-064 估值一亿的AI核心代码 (20 分)—团体程序设计天梯赛
- AI开发者大会之AI学习与进阶实践:2020年7月3日《如何转型搞AI?》、《基于AI行业价值的AI学习与进阶路径》、《自动机器学习与前沿AI开源项目》、《使用TensorFlow实现经典模型》
- AI公开课:19.05.16漆远-蚂蚁金服集团CF《金融智能的深度与温度》课堂笔记以及个人感悟—191017再次更新
- BigData:根据最新2018人工智能行业创新企业Top100名单,绘制AI地区热点图,一目了然,看清哪个是AI最热门城市,以及VC最AI的热门领域
- AI开发实践丨客流分析之未佩戴口罩识别
- 中秋节,用华为云AI制作一轮超大的月亮吧!
- 【华为云技术分享】HBase与AI/用户画像/推荐系统的结合:CloudTable标签索引特性介绍
- 【人工智能 Open AI】怎样实现身体和心灵的完美和谐?
- 【人工智能 AI 写书】第一章 架构概述 -《卓越架构师修炼之道》
- 跟随Deepmind使用AI玩《星际争霸2》
- AI入门(重实践)书籍推荐