
【Spark NLP】第 14 章:搜索引擎
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在第 13 章中,我们讨论了如何组织从文本中提取的知识,以便人类和专家系统可以利用它。然而,大多数人并不通过图表与数据交互——尤其是文本数据。人们通常希望搜索和检索文本。在第 6 章中,我们介绍了信息检索的基本概念。我们学习了如何处理文本以及如何计算 TF.IDF。在本章中,我们将构建一个实际的搜索应用程序。
我们需要考虑的第一件事是我们要解决什么问题。与其设计一个特定的用例,不如尝试构建一个其他人可以用来解决特定任务的应用程序。我们想要构建一个用户可以用来创建自定义搜索的工具。
我们将需要我们的应用程序做一些不同的事情:
- 处理文本数据
- 索引处理后的文本
- 查询索引
- 标记搜索结果以衡量和改善搜索体验
我们在第12章和第13章中使用了虚构的场景。让我们看看我们是否可以制作一个对我们真正有用的工具。我们是这里的用户。这个练习很有用,因为您需要构建供自己使用的工具并不少见。
问题陈述和约束
-
我们试图解决的问题是什么?
我们希望能够构建自定义搜索引擎,我们可以随着时间的推移进行改进。我们希望它尽可能地可重用。因此,我们将希望在我们的应用程序中构建一些抽象。
-
有哪些限制条件?
我们将从具有标题和文本的文档开始。或者,它们还可以包含其他属性,例如类别、作者和关键字。我们希望能够改进我们的搜索结果,而无需重新索引所有数据。此外,我们需要能够标记文档查询对以改进我们的搜索引擎。
-
我们如何解决约束问题?
我们需要考虑多个部分。首先,我们将使用 Spark NLP 处理文本,并直接使用 Spark 将其索引到 Elasticsearch。我们将构建一个特殊的查询,该查询将利用我们文档的字段。我们将记录查询和每个查询的选择。
计划项目
我们将把它分解成块,就像我们之前的项目一样。该项目将依赖于组织多种开源技术。
- 构建处理和索引脚本(Spark NLP、Elasticsearch)
- 自定义查询功能
- 标注文档-查询对 (doccano)
对于前三个步骤,我们将使用简单英语维基百科数据集。这是一个很好的数据集,因为它不会像英语维基百科那样在个人机器上使用太大。为此使用 wiki 的好处是我们不需要特殊知识来评估搜索结果。
设计解决方案
在任何实际场景中,前两部分的代码都需要定制。我们能做的就是分离出专门的代码。这将使我们能够在未来更轻松地重新利用这些工具。
我们将构建一个索引脚本。首先,这将解析和准备索引数据。这些是需要针对不同数据源重新实现的专门步骤。该脚本将索引数据。这是一段更通用的代码。然后,我们将构建一个查询函数,允许用户在他们的查询中使用索引文档的不同字段。最后,我们将查看标签搜索结果。其输出可用于改进索引脚本或潜在地实现基于机器学习的排名器。
实施解决方案
在开始实施之前,请按照安装 Elasticsearch的相应说明进行操作。你也可以考虑使用Elasticsearch Docker。
一旦 Elasticsearch 运行,我们就可以开始加载和处理文本。
import json
import re
import pandas as pd
import requests
import sparknlp
from pyspark.ml import Pipeline
from pyspark.sql import SparkSession, Row
from pyspark.sql.functions import lit, col
import sparknlp
from sparknlp import DocumentAssembler, Finisher
from sparknlp.annotator import *packages = [
'JohnSnowLabs:spark-nlp:2.2.2',
'com.databricks:spark-xml_2.11:0.6.0',
'org.elasticsearch:elasticsearch-spark-20_2.11:7.4.2'
]
spark = SparkSession.builder \
.master("local[*]") \
.appName("Indexing") \
.config("spark.driver.memory", "12g") \
.config("spark.jars.packages", ','.join(packages)) \
.getOrCreate()加载和解析数据需要专门针对不同的数据集。我们应该确保输出至少包含一个文本字段和一个标题字段。您可以包括可用于扩充搜索的其他字段。例如,您可以将类别添加到数据中。这允许分面搜索,这是另一种表示您正在根据具有某些属性或方面的结果过滤结果的方式。
# 加载数据 - 这需要专门化
df = spark.read\
.format('xml')\
.option("rootTag", "mediawiki")\
.option("rowTag", "page")\
.load("simplewiki-20191020-pages-articles-multistream.xml.bz2")\
.repartition(200)\
.persist()# 选择数据 - 这需要专门化
df = df.filter('redirect IS NULL').selectExpr(
'revision.text._VALUE AS text',
'title'
).filter('text IS NOT NULL')
# 你必须输出一个 DataFrame,它有一个文本字段和一个
# 标题字段现在我们有了数据,让我们使用 Spark NLP 来处理它。这类似于我们之前处理数据的方式。
assembler = DocumentAssembler()\
.setInputCol('text')\
.setOutputCol('document')
tokenizer = Tokenizer()\
.setInputCols(['document'])\
.setOutputCol('tokens')
lemmatizer = LemmatizerModel.pretrained()\
.setInputCols(['tokens'])\
.setOutputCol('lemmas')
normalizer = Normalizer()\
.setCleanupPatterns([
'[^a-zA-Z.-]+',
'^[^a-zA-Z]+',
'[^a-zA-Z]+$',
])\
.setInputCols(['lemmas'])\
.setOutputCol('normalized')\
.setLowercase(True)
finisher = Finisher()\
.setInputCols(['normalized'])\
.setOutputCols(['normalized'])
nlp_pipeline = Pipeline().setStages([
assembler, tokenizer,
lemmatizer, normalizer, finisher
]).fit(df)processed = nlp_pipeline.transform(df)现在,让我们选择我们感兴趣的字段。我们将对文本、标题和规范化数据进行索引。我们想要存储实际文本,以便我们可以将其显示给用户。然而,情况可能并非总是如此。在联合搜索中,您正在组合存储在不同索引中的数据,也许还有其他类型的数据存储,并一次搜索所有数据。在联合搜索中,您不想复制您将提供的数据。根据您在数据存储中组合搜索的方式,您可能需要复制一些经过处理的数据形式。在这种情况下,一切都将在 Elasticsearch 中。我们将搜索标题文本和规范化文本。将这些字段视为有助于处理两个不同的指标。如果查询与标题匹配,则很可能是相关文档,但有许多与文档相关但与标题不匹配的查询。搜索规范化的文本会提高召回率,但我们仍然希望标题匹配对排名产生更大的影响。
processed = processed.selectExpr(
'text',
'title',
'array_join(normalized, " ") AS normalized'
)现在我们可以按DataFrame原样索引。我们将数据直接传递给 Elasticsearch。创建 Elasticsearch 索引时有很多选项,因此您应该查看Elasticsearch 的 API。
processed.write.format('org.elasticsearch.spark.sql')\
.save('simpleenglish')我们可以使用以下 cURL 命令检查可用的索引。
!curl "http://localhost:9200/_cat/indices?v"health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open simpleenglish jVeJPRyATKKzPPEnuUp3ZQ 1 1 220858 0 1.6gb 1.6gb看起来一切都在那里。我们现在可以使用 REST API 查询索引。为了查询我们的索引,我们需要选择要查询的字段。注意我们列出的字段。猜测字段的初始权重。当我们了解用户如何查询数据时,我们可以调整权重。
headers = {
'Content-Type': 'application/json',
}
params = (
('pretty', ''),
)
data = {
"_source": ['title'],
"query": {
"multi_match": {
"query": "data",
"fields": ["normalized^1", "title^10"]
},
}
}
response = requests.post(
'http://localhost:9200/simpleenglish/_search',
headers=headers, params=params, data=json.dumps(data))
response.json(){'took': 32,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 9774, 'relation': 'eq'},
'max_score': 54.93799,
'hits': [{'_index': 'simpleenglish',
'_type': '_doc',
'_id': '13iVYG4BfVJ3yetiTdZJ',
'_score': 54.93799,
'_source': {'title': 'Data'}},
{'_index': 'simpleenglish',
'_type': '_doc',
'_id': '13iUYG4BfVJ3yeti720D',
'_score': 45.704754,
'_source': {'title': 'Repository (data)'}},
...
{'_index': 'simpleenglish',
'_type': '_doc',
'_id': 'eHmWYG4BfVJ3yetiIs2m',
'_score': 45.704754,
'_source': {'title': 'Data collection'}}]}}现在,让我们构建我们的查询函数。该fields参数应为字段名称和提升的元组列表。提升本质上是应用于从不同字段的索引返回的分数的权重。
def query_index(query, fields=None, size=10):
data = spark.createDataFrame([(text,)], ('text',))
row = nlp_pipeline.transform(data).first()
query = row['normalized'][0]
if fields is None:
fields = [('normalized', 1), ('title', 10)]
headers = {
'Content-Type': 'application/json',
}
params = (
('pretty', ''), ('size', size)
)
data = {
"_source": ['title'],
"query": {
"multi_match": {
"query": query,
"fields": ['{}^{}'.format(f, b) for f, b in fields]
},
}
}
response = requests.post(
'http://localhost:9200/simpleenglish/_search',
headers=headers, params=params,
data=json.dumps(data)).json()
return [(r['_source']['title'], r['_score'])
for r in response['hits']['hits']]现在让我们构建我们的集合,我们将对其进行标记。让我们查询“语言”的索引。
language_query_results = query_index('Language', size=13)
language_query_results[('Language', 72.923416),
('Baure language', 60.667435),
('Luwian language', 60.667435),
('Faroese language', 60.667435),
('Aramaic language', 60.667435),
('Gun language', 60.667435),
('Beary language', 60.667435),
('Tigrinya language', 60.667435),
('Estonian language', 60.667435),
('Korean language', 60.667435),
('Kashmiri language', 60.667435),
('Okinawan language', 60.667435),
('Rohingya language', 60.667435)]返回有关实际语言的文章是查询“语言”的一个非常合理的结果。
我们需要确保导出标签所需的信息,即标题和文本。如果您的数据包含您认为与判断相关的额外字段,则应修改导出的字段以包含它们。我们将创建用于标签的文档。这些文档将包含查询、标题、分数和文本。
language_query_df = spark.createDataFrame(
language_query_results, ['title', 'score'])
docs = df.join(language_query_df, ['title'])
docs = docs.collect()
docs = [r.asDict() for r in docs]
with open('lang_query_results.json', 'w') as out:
for doc in docs:
text = 'Query: Language\n'
text += '=' * 50 + '\n'
text += 'Title: {}'.format(doc['title']) + '\n'
text += '=' * 50 + '\n'
text += 'Score: {}'.format(doc['score']) + '\n'
text += '=' * 50 + '\n'
text += doc['text']
line = json.dumps({'text': text})
out.write(line + '\n')现在我们已经创建了需要标记的数据,让我们开始使用doccano。Doccano 是一个用于帮助 NLP 标记的工具。它允许文档分类标记(用于情感分析等任务)、片段标记(用于 NER 等任务)和序列到序列标记(用于机器翻译等任务)。您可以在本地设置此服务或在 docker 中启动它。让我们看看在 docker 中启动它。
首先,我们将拉取图像。
docker pull chakkiworks/doccano接下来,我们将运行一个容器。
docker run -d --rm --name doccano \
-e "ADMIN_USERNAME=admin" \
-e "ADMIN_EMAIL=admin@example.com" \
-e "ADMIN_PASSWORD=password" \
-p 8000:8000 chakkiworks/doccano如果您打算使用 doccano 给其他人贴上标签,您应该考虑更改管理员凭据。
启动容器后,转到(或者如果您修改了参数localhost:8000,则选择您选择的任何端口)。-p您应该会看到图 14-1中的页面。
图 14-1。Doccano登陆页面
单击登录名并使用docker run命令中的凭据。然后单击“创建项目”。这里,在图 14-2中,项目字段被填写。
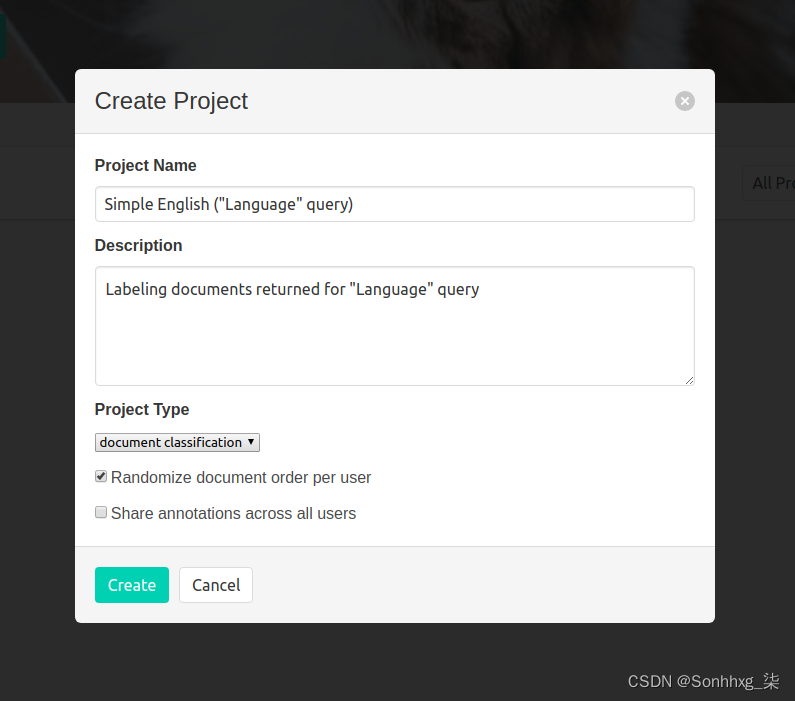
图 14-2。在 doccano 中创建项目
接下来,单击“选择文件”,然后导航到lang_query_results.json之前创建的位置。这会将用于标记的文档添加到项目中。
在此之后,单击“标签”,然后单击“新标签”。我添加了三个,“相关”、“部分相关”和“不相关”。在基础数据中,这些标签将按照您创建它们的顺序来表示。例如,如果您创建了“相关”、“部分相关”和“不相关”,它们的表示将分别为 1、2、3。
我认为为标记任务编写指南是一个好主意,即使你是做标记的人。这将帮助您考虑如何标记数据。在你去的时候弄清楚它可能会导致不一致。
图 14-3是我为这个示例任务创建的指南示例。

图 14-3。Doccano指南
现在我们准备开始标记。单击“注释数据”,然后开始标记。图 14-4是标注页面的截图。

图 14-4。Doccano标签
完成后,您可以单击“编辑数据”,这将带您返回项目页面。从这里,您可以通过单击“导出数据”来导出数据。您可以导出为 JSON 行或 CSV。但是,我们不会使用这些数据,因为标记足够多的查询-文档对来提高排名需要一些时间。
测试和测量解决方案
现在我们已经创建了一个索引并查看了如何使用 doccano 进行标记,我们可以讨论如何衡量我们的解决方案。这是与大多数应用程序不同的场景,因为该工具将用于为我们组织和检索文档——我们是客户。
以模型为中心的指标
在衡量一个指数时,有许多可能的指标。首先,我们想要最好的排名。衡量排名的一种方法是通过召回和精度,这类似于二元分类问题。问题是如果我们返回一百个文档,召回率和精度不会告诉我们它们的顺序。为此,我们需要排名指标。最流行的指标之一是归一化贴现累积增益 (NDCG)。为了解释这一点,我们需要构建它。首先,让我们定义gain。在这种情况下,增益是文本中的信息。我们使用文档的相关性作为增益。累积增益是直到所选截止值的增益总和。到目前为止,排名没有任何意义,所以我们越往下看,就越会打折扣。我们将需要使用排名来减少增益。我们使用排名的对数,以便折扣将列表中较早的项目比列表中较晚的项目更强烈地分开。最后一部分是标准化。如果指标介于 0 和 1 之间,则报告指标要容易得多。因此,我们需要确定理想的折现累积增益。如果你不能直接计算它,你可以假设所有高于临界值的文档都是相关的。现在让我们看看实际的指标。
现在,我们可以量化我们的索引的工作情况。即使您正在为自己构建工具,量化数据驱动应用程序的质量也很重要。人类是真理的最终来源,但我们也善变和喜怒无常。使用指标有助于使我们的评估可靠。
审查
当您自己工作时,复习会更加困难。如果您有人愿意帮助您审查工作,他们可以提供重要的外部视角。你想珍惜你志愿者的时间,所以你应该准备一个演示。更深入的审查是一个更繁重的要求,因此您不能依赖能够从志愿者那里获得代码审查。
那么我们如何在没有帮助的情况下检查质量呢?我们必须在测试和文档方面投入更多精力。这就产生了另一个问题——追求质量的努力会导致你失去动力。这意味着您应该利用这些项目来设定合理的目标和里程碑。
结论
信息检索是一个丰富的研究领域。本章可以作为您深入研究该领域的起点。本章强调的另一件重要事情是为自己构建的项目的价值。在数据科学中,通常很难找到学习新技术的专业机会。为您自己的目的构建一个项目可能是扩展您的技能集合的绝佳机会。
在第 15 章中,我们将学习如何构建一个与用户交互工作的模型。
相关文章
- Windows10搭建Spark+Python开发环境
- Apache CarbonData 2.0 开发实用系列之一:与Spark SQL集成使用
- Spark在shell中调试
- 大数据基础之Spark(9)spark部署方式yarn/mesos
- 大叔经验分享(14)spark on yarn提交任务到集群后spark-submit进程一直等待
- Spark会把数据都载入到内存么?
- Spark修炼之道(高级篇)——Spark源码阅读:第七节 resourceOffers方法与launchTasks方法解析
- Spark On K8S 在有赞的实践与经验
- spark on k8s配置日志存储路径:spark-defaults.conf
- spark wordcount完整工程代码(含pom.xml)
- 【网址收藏】Spark History Server配置及使用
- Spark Locality Sensitive Hashing (LSH)局部哈希敏感
- 执行Spark运行在yarn上的命令报错 spark-shell --master yarn-client
- 两步实现spark集群
- spark单机版计算测试
- 解决spark中遇到的数据倾斜问题
- Spark实战(四)spark+python快速入门实战小例子(PySpark)
- cdh5.14.2安装spark 2.3.0parcel包