
DDPM代码详细解读(2):Unet结构、正向和逆向过程、IS和FID测试、EMA优化
一、EMA优化
关于EMA看:【炼丹技巧】指数移动平均(EMA)【在一定程度上提高最终模型在测试数据上的表现(例如accuracy、FID、泛化能力…)】
使用指数移动平均对模型参数进行优化,提高测试指标增加模型鲁棒性。代码如下:
def ema(source, target, decay):
source_dict = source.state_dict()
target_dict = target.state_dict()
for key in source_dict.keys():
target_dict[key].data.copy_(target_dict[key].data * decay + source_dict[key].data * (1 - decay))
在训练的过程中,每一个step对net_model和ema_model(即sample model)做ema:
ema(net_model, ema_model, FLAGS.ema_decay)
二、训练目标和采样目标
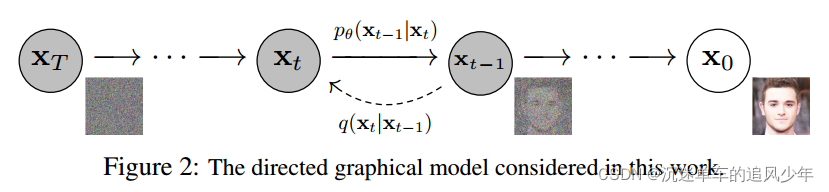
1)正向过程
正向过程即p过程,逆向过程即q过程、采样过程。
正向过程不涉及参数分布的计算和预测,可以理解为一个单纯add noise的过程。
训练和采样的训练目标如下:

上一篇文章详细解释了
x
t
x_t
xt 和
ϵ
θ
\boldsymbol{\epsilon}_{\theta}
ϵθ 是怎么计算的,正向过程就非常容易理解了:
class GaussianDiffusionTrainer(nn.Module):
def __init__(self, model, beta_1, beta_T, T):
super().__init__()
self.model = model
self.T = T
self.register_buffer('betas', torch.linspace(beta_1, beta_T, T).double())
alphas = 1. - self.betas
alphas_bar = torch.cumprod(alphas, dim=0)
# calculations for diffusion q(x_t | x_{t-1}) and others
self.register_buffer('sqrt_alphas_bar', torch.sqrt(alphas_bar))
self.register_buffer('sqrt_one_minus_alphas_bar', torch.sqrt(1. - alphas_bar))
def forward(self, x_0):
"""
Algorithm 1. Training
"""
t = torch.randint(self.T, size=(x_0.shape[0], ), device=x_0.device)
noise = torch.randn_like(x_0)
x_t = (
extract(self.sqrt_alphas_bar, t, x_0.shape) * x_0 +
extract(self.sqrt_one_minus_alphas_bar, t, x_0.shape) * noise)
loss = F.mse_loss(self.model(x_t, t), noise, reduction='none')
return loss
2)逆向过程
x t x_t xt 的分布符合高斯分布,这是通过均值和方差进行计算的:
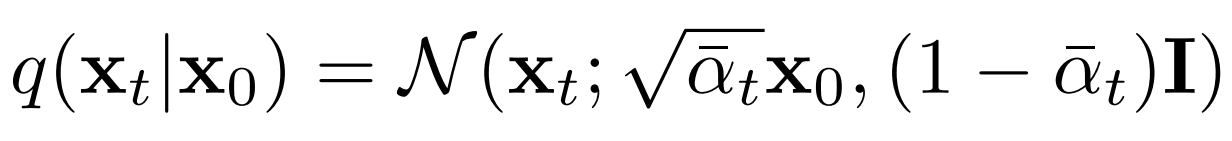
计算
σ
t
Z
\sigma_{t} \mathbf{Z}
σtZ使用:
torch.exp(0.5 * log_var) * noise
而其他的参数我们都已经计算过了,所以重点是计算第一项的均值:

我们输入
x
t
x_t
xt,得到
x
t
−
1
x_{t-1}
xt−1,最终的代码如下:
class GaussianDiffusionSampler(nn.Module):
def __init__(self, model, beta_1, beta_T, T, img_size=32,
mean_type='eps', var_type='fixedlarge'):
assert mean_type in ['xprev' 'xstart', 'epsilon']
assert var_type in ['fixedlarge', 'fixedsmall']
super().__init__()
self.model = model
self.T = T
self.img_size = img_size
self.mean_type = mean_type
self.var_type = var_type
# 得到betas
self.register_buffer('betas', torch.linspace(beta_1, beta_T, T).double())
alphas = 1. - self.betas
alphas_bar = torch.cumprod(alphas, dim=0)
alphas_bar_prev = F.pad(alphas_bar, [1, 0], value=1)[:T]
# 计算根号(连乘α) 和 根号(1-连乘α)
# calculations for diffusion q(x_t | x_{t-1}) and others
self.register_buffer('sqrt_recip_alphas_bar', torch.sqrt(1. / alphas_bar))
self.register_buffer('sqrt_recipm1_alphas_bar', torch.sqrt(1. / alphas_bar - 1))
# calculations for posterior q(x_{t-1} | x_t, x_0)
self.register_buffer('posterior_var', self.betas * (1. - alphas_bar_prev) / (1. - alphas_bar))
# below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
self.register_buffer('posterior_log_var_clipped', torch.log(torch.cat([self.posterior_var[1:2], self.posterior_var[1:]])))
self.register_buffer('posterior_mean_coef1', torch.sqrt(alphas_bar_prev) * self.betas / (1. - alphas_bar))
self.register_buffer('posterior_mean_coef2', torch.sqrt(alphas) * (1. - alphas_bar_prev) / (1. - alphas_bar))
def q_mean_variance(self, x_0, x_t, t):
"""
Compute the mean and variance of the diffusion posterior
q(x_{t-1} | x_t, x_0)
"""
assert x_0.shape == x_t.shape
posterior_mean = (
extract(self.posterior_mean_coef1, t, x_t.shape) * x_0 +
extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
)
posterior_log_var_clipped = extract(self.posterior_log_var_clipped, t, x_t.shape)
return posterior_mean, posterior_log_var_clipped
def predict_xstart_from_eps(self, x_t, t, eps):
assert x_t.shape == eps.shape
return (
extract(self.sqrt_recip_alphas_bar, t, x_t.shape) * x_t -
extract(self.sqrt_recipm1_alphas_bar, t, x_t.shape) * eps
)
def predict_xstart_from_xprev(self, x_t, t, xprev):
assert x_t.shape == xprev.shape
# (xprev - coef2*x_t) / coef1
return (
extract(1. / self.posterior_mean_coef1, t, x_t.shape) * xprev -
extract(self.posterior_mean_coef2 / self.posterior_mean_coef1, t, x_t.shape) * x_t
)
def p_mean_variance(self, x_t, t):
# below: only log_variance is used in the KL computations
model_log_var = {
# for fixedlarge, we set the initial (log-)variance like so to get a better decoder log likelihood
'fixedlarge': torch.log(torch.cat([self.posterior_var[1:2], self.betas[1:]])),
'fixedsmall': self.posterior_log_var_clipped,
}[self.var_type]
model_log_var = extract(model_log_var, t, x_t.shape)
# Mean parameterization
if self.mean_type == 'xprev': # the model predicts x_{t-1}
x_prev = self.model(x_t, t)
x_0 = self.predict_xstart_from_xprev(x_t, t, xprev=x_prev)
model_mean = x_prev
elif self.mean_type == 'xstart': # the model predicts x_0
x_0 = self.model(x_t, t)
model_mean, _ = self.q_mean_variance(x_0, x_t, t)
elif self.mean_type == 'epsilon': # the model predicts epsilon
eps = self.model(x_t, t)
x_0 = self.predict_xstart_from_eps(x_t, t, eps=eps)
model_mean, _ = self.q_mean_variance(x_0, x_t, t)
else:
raise NotImplementedError(self.mean_type)
x_0 = torch.clip(x_0, -1., 1.)
return model_mean, model_log_var
def forward(self, x_T):
"""
Algorithm 2. Sampling
"""
x_t = x_T
for time_step in reversed(range(self.T)):
t = x_t.new_ones([x_T.shape[0], ], dtype=torch.long) * time_step
mean, log_var = self.p_mean_variance(x_t=x_t, t=t)
# no noise when t == 0
if time_step > 0:
noise = torch.randn_like(x_t)
else:
noise = 0
x_t = mean + torch.exp(0.5 * log_var) * noise
x_0 = x_t
# 因为我们预测的是概率分布,所以最终将所有的值缩放到[-1,1]这个区间中。
return torch.clip(x_0, -1, 1)
三、Unet网络结构【model.py】
import math
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as F
class Swish(nn.Module):
def forward(self, x):
return x * torch.sigmoid(x)
class TimeEmbedding(nn.Module):
def __init__(self, T, d_model, dim):
assert d_model % 2 == 0
super().__init__()
emb = torch.arange(0, d_model, step=2) / d_model * math.log(10000)
emb = torch.exp(-emb)
pos = torch.arange(T).float()
emb = pos[:, None] * emb[None, :]
assert list(emb.shape) == [T, d_model // 2]
emb = torch.stack([torch.sin(emb), torch.cos(emb)], dim=-1)
assert list(emb.shape) == [T, d_model // 2, 2]
emb = emb.view(T, d_model)
self.timembedding = nn.Sequential(
nn.Embedding.from_pretrained(emb),
nn.Linear(d_model, dim),
Swish(),
nn.Linear(dim, dim),
)
self.initialize()
def initialize(self):
for module in self.modules():
if isinstance(module, nn.Linear):
init.xavier_uniform_(module.weight)
init.zeros_(module.bias)
def forward(self, t):
emb = self.timembedding(t)
return emb
class DownSample(nn.Module):
def __init__(self, in_ch):
super().__init__()
self.main = nn.Conv2d(in_ch, in_ch, 3, stride=2, padding=1)
self.initialize()
def initialize(self):
init.xavier_uniform_(self.main.weight)
init.zeros_(self.main.bias)
def forward(self, x, temb):
x = self.main(x)
return x
class UpSample(nn.Module):
def __init__(self, in_ch):
super().__init__()
self.main = nn.Conv2d(in_ch, in_ch, 3, stride=1, padding=1)
self.initialize()
def initialize(self):
init.xavier_uniform_(self.main.weight)
init.zeros_(self.main.bias)
def forward(self, x, temb):
_, _, H, W = x.shape
x = F.interpolate(
x, scale_factor=2, mode='nearest')
x = self.main(x)
return x
class AttnBlock(nn.Module):
def __init__(self, in_ch):
super().__init__()
self.group_norm = nn.GroupNorm(32, in_ch)
self.proj_q = nn.Conv2d(in_ch, in_ch, 1, stride=1, padding=0)
self.proj_k = nn.Conv2d(in_ch, in_ch, 1, stride=1, padding=0)
self.proj_v = nn.Conv2d(in_ch, in_ch, 1, stride=1, padding=0)
self.proj = nn.Conv2d(in_ch, in_ch, 1, stride=1, padding=0)
self.initialize()
def initialize(self):
for module in [self.proj_q, self.proj_k, self.proj_v, self.proj]:
init.xavier_uniform_(module.weight)
init.zeros_(module.bias)
init.xavier_uniform_(self.proj.weight, gain=1e-5)
def forward(self, x):
B, C, H, W = x.shape
h = self.group_norm(x)
q = self.proj_q(h)
k = self.proj_k(h)
v = self.proj_v(h)
q = q.permute(0, 2, 3, 1).view(B, H * W, C)
k = k.view(B, C, H * W)
w = torch.bmm(q, k) * (int(C) ** (-0.5))
assert list(w.shape) == [B, H * W, H * W]
w = F.softmax(w, dim=-1)
v = v.permute(0, 2, 3, 1).view(B, H * W, C)
h = torch.bmm(w, v)
assert list(h.shape) == [B, H * W, C]
h = h.view(B, H, W, C).permute(0, 3, 1, 2)
h = self.proj(h)
return x + h
class ResBlock(nn.Module):
def __init__(self, in_ch, out_ch, tdim, dropout, attn=False):
super().__init__()
self.block1 = nn.Sequential(
nn.GroupNorm(32, in_ch),
Swish(),
nn.Conv2d(in_ch, out_ch, 3, stride=1, padding=1),
)
self.temb_proj = nn.Sequential(
Swish(),
nn.Linear(tdim, out_ch),
)
self.block2 = nn.Sequential(
nn.GroupNorm(32, out_ch),
Swish(),
nn.Dropout(dropout),
nn.Conv2d(out_ch, out_ch, 3, stride=1, padding=1),
)
if in_ch != out_ch:
self.shortcut = nn.Conv2d(in_ch, out_ch, 1, stride=1, padding=0)
else:
self.shortcut = nn.Identity()
if attn:
self.attn = AttnBlock(out_ch)
else:
self.attn = nn.Identity()
self.initialize()
def initialize(self):
for module in self.modules():
if isinstance(module, (nn.Conv2d, nn.Linear)):
init.xavier_uniform_(module.weight)
init.zeros_(module.bias)
init.xavier_uniform_(self.block2[-1].weight, gain=1e-5)
def forward(self, x, temb):
h = self.block1(x)
h += self.temb_proj(temb)[:, :, None, None]
h = self.block2(h)
h = h + self.shortcut(x)
h = self.attn(h)
return h
class UNet(nn.Module):
def __init__(self, T, ch, ch_mult, attn, num_res_blocks, dropout):
super().__init__()
assert all([i < len(ch_mult) for i in attn]), 'attn index out of bound'
tdim = ch * 4
self.time_embedding = TimeEmbedding(T, ch, tdim)
self.head = nn.Conv2d(3, ch, kernel_size=3, stride=1, padding=1)
self.downblocks = nn.ModuleList()
chs = [ch] # record output channel when dowmsample for upsample
now_ch = ch
for i, mult in enumerate(ch_mult):
out_ch = ch * mult
for _ in range(num_res_blocks):
self.downblocks.append(ResBlock(
in_ch=now_ch, out_ch=out_ch, tdim=tdim,
dropout=dropout, attn=(i in attn)))
now_ch = out_ch
chs.append(now_ch)
if i != len(ch_mult) - 1:
self.downblocks.append(DownSample(now_ch))
chs.append(now_ch)
self.middleblocks = nn.ModuleList([
ResBlock(now_ch, now_ch, tdim, dropout, attn=True),
ResBlock(now_ch, now_ch, tdim, dropout, attn=False),
])
self.upblocks = nn.ModuleList()
for i, mult in reversed(list(enumerate(ch_mult))):
out_ch = ch * mult
for _ in range(num_res_blocks + 1):
self.upblocks.append(ResBlock(
in_ch=chs.pop() + now_ch, out_ch=out_ch, tdim=tdim,
dropout=dropout, attn=(i in attn)))
now_ch = out_ch
if i != 0:
self.upblocks.append(UpSample(now_ch))
assert len(chs) == 0
self.tail = nn.Sequential(
nn.GroupNorm(32, now_ch),
Swish(),
nn.Conv2d(now_ch, 3, 3, stride=1, padding=1)
)
self.initialize()
def initialize(self):
init.xavier_uniform_(self.head.weight)
init.zeros_(self.head.bias)
init.xavier_uniform_(self.tail[-1].weight, gain=1e-5)
init.zeros_(self.tail[-1].bias)
def forward(self, x, t):
# Timestep embedding
temb = self.time_embedding(t)
# Downsampling
h = self.head(x)
hs = [h]
for layer in self.downblocks:
h = layer(h, temb)
hs.append(h)
# Middle
for layer in self.middleblocks:
h = layer(h, temb)
# Upsampling
for layer in self.upblocks:
if isinstance(layer, ResBlock):
h = torch.cat([h, hs.pop()], dim=1)
h = layer(h, temb)
h = self.tail(h)
assert len(hs) == 0
return h
if __name__ == '__main__':
batch_size = 8
model = UNet(
T=1000, ch=128, ch_mult=[1, 2, 2, 2], attn=[1],
num_res_blocks=2, dropout=0.1)
x = torch.randn(batch_size, 3, 32, 32)
t = torch.randint(1000, (batch_size, ))
y = model(x, t)
相关文章
- java实现人脸识别源码【含测试效果图】——前期准备工作及访问提示
- Mybatis+MySQL动态分页查询数据经典案例(含代码以及测试)
- apache ab压力测试
- 性能测试术语
- [Contract] 测试 Solidity 合约代码的两种方式 与 优缺点
- ZZNUOJ_C语言1086:ASCII码排序(多实例测试)(完整代码)
- ZZNUOJ_C语言1087:获取出生日期(多实例测试)(完整代码)
- 2022年3月14日蓝桥杯基础算法能力测试
- Web性能测试中的几个关键指标
- 60集Python入门视频PPT整理 | Python代码的测试、调试与探查
- PostgreSQL的学习心得和知识总结(三十四)|PostgreSQL数据库中的代码覆盖工具(gcov、lcov)的使用及代码覆盖率测试(coverage)
- 2022广东网络安全省赛—代码渗透测试wp
- 胶囊模型的代码在Windows下的测试,99.76%正确率
- 软件测试技术之跨平台的移动端UI自动化测试(下)
- 接口测试脚本如何编写?其实很简单 一分钟教会你
- 学会代码不是测试的终点而是测试开发的起点
- 何使用Selenium开启Web自动化测试
- VectorCAST/C++在汽车电子C++代码测试的应用
- 支持DevOps和功能安全/信息安全的静态代码分析器 Klocwork——Klocwork的主要功能特性:基于SAST(静态应⽤程序安全测试)查找安全漏洞;支持DevOps;⽀持⾏业标准要求的编码规范
- 如何保证汽车信息安全?还得从代码静态测试说起
- Appium自动化测试基础 — 获取元素文本内容
- 2023Web自动化测试之高级用法(建议收藏)
- 阿里P6测试总监分享,这份《接口自动化测试》总结,让我入门了...
- 字节5年经验之谈,迷茫的手工测试如何进阶自动化测试呢?
- 工龄10年的测试员从大厂“裸辞”后...
- 一名新手测试经理3个月试用期转正总结【人情世故】
- Pytest----如何执行未安装的本地包中的测试脚本
- twisted系列教程十五–测试twisted代码
- RobotFrameWork - 03 - 创建新的项目工程与测试套件(suite)
- 基于JAVA实现的WEB端UI自动化 - WebDriver高级篇 - grid [跨浏览器远程测试-可分布式]