
【Pytorch with fastai】第 8 章 :协同过滤深入探讨
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
要解决的一个常见问题是拥有大量用户并且 许多产品,并且您想推荐哪些产品最有可能对哪些用户有用。存在许多变体:例如,推荐电影(例如在 Netflix 上)、确定在主页上为用户突出显示的内容、决定在社交媒体提要中显示哪些故事,等等。这个问题的通用解决方案,称为协同过滤,其工作原理是:查看当前用户使用过或喜欢过哪些产品,找到使用过或喜欢过类似产品的其他用户,然后推荐这些用户使用过或喜欢过的其他产品.
例如,在 Netflix 上,您可能看过很多 1970 年代制作的充满科幻色彩的电影。Netflix 可能不知道你看过的电影的这些特殊属性,但它能够看到看过你看过的同一部电影的其他人也倾向于看其他科幻电影,充满动作,并且是70 年代制造。换句话说,要使用这种方法,除了喜欢看电影的人之外,我们不需要知道任何关于电影的信息。
这种方法可以解决一类更普遍的问题,不一定涉及用户和产品。 事实上,对于协同过滤,我们更常提到的是物品,而不是产品。项目可以是人们点击的链接、为患者选择的诊断等等。
关键的基本思想是潜在因素。在里面 以 Netflix 为例,我们首先假设您喜欢动作丰富的老式科幻电影。但是你从来没有告诉 Netflix 你喜欢这些类型的电影。Netflix 从来不需要在其电影表中添加列来说明哪些电影属于这些类型。尽管如此,仍必须有一些关于科幻、动作和电影时代的基本概念,并且这些概念必须至少与某些人的电影观看决定相关。
在本章中,我们将研究这个电影推荐问题。我们将从获取一些适合协同过滤模型的数据开始。
初步了解数据
我们无法访问 Netflix 的整个电影观看历史数据集,但我们可以使用一个很棒的数据集,称为 电影镜头。该数据集包含数千万个电影排名(电影 ID、用户 ID 和数字评分的组合),尽管我们仅在示例中使用其中 100,000 个中的一个子集。如果您有兴趣,尝试在完整的 2500 万推荐数据集上复制这种方法将是一个很好的学习项目,您可以从他们的网站上获得这些数据集。
数据集可通过常用的 fastai 函数获得:
from fastai.collab import *
from fastai.tabular.all import *
path = untar_data(URLs.ML_100k)根据自述文件,主表位于文件u.data中。它是制表符分隔的,列分别是用户、电影、评级和时间戳。由于这些名称未编码,因此我们需要在使用 Pandas 读取文件时指明它们。下面是打开此表并查看的方法:
ratings = pd.read_csv(path/'u.data', delimiter='\t', header=None,
names=['user','movie','rating','timestamp'])
ratings.head()| user | movie | rating | timestamp | |
|---|---|---|---|---|
| 0 | 196 | 242 | 3 | 881250949 |
| 1 | 186 | 302 | 3 | 891717742 |
| 2 | 22 | 377 | 1 | 878887116 |
| 3 | 244 | 51 | 2 | 880606923 |
| 4 | 166 | 346 | 1 | 886397596 |
尽管这包含了我们需要的所有信息,但它并不是特别 人们查看这些数据的有用方法。图 8-1显示了交叉制表到人性化表格中的相同数据。
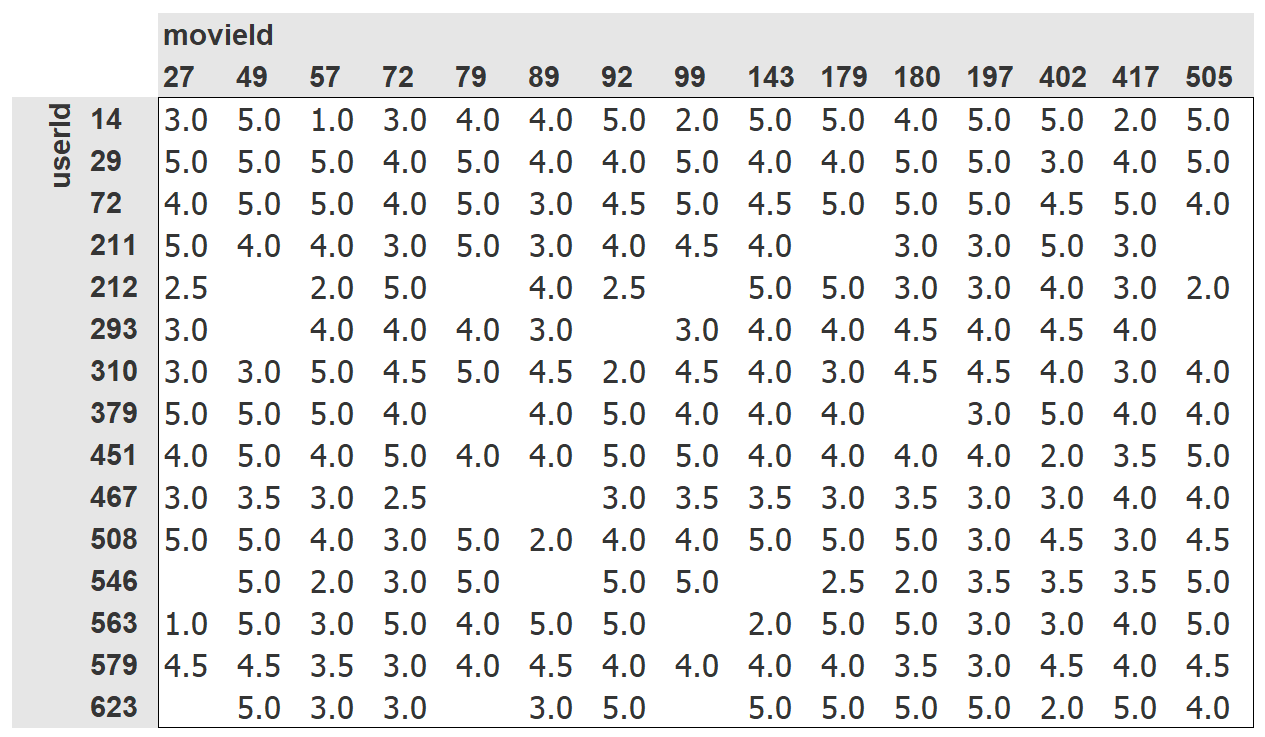
图 8-1。电影和用户的交叉表
对于这个交叉表示例,我们只选择了一些最流行的电影和观看电影最多的用户。此表中的空单元格是我们希望我们的模型学习填充的内容。这些是用户尚未评论电影的地方,大概是因为他们还没有看过电影。对于每个用户,我们想弄清楚他们最有可能喜欢哪些电影。
如果我们知道每个用户在多大程度上喜欢一部电影可能属于的每个重要类别,例如流派、年龄、喜欢的导演和演员等等,并且我们知道关于每部电影的相同信息,那么一个简单的方法填写此表就是将每部电影的此信息相乘并使用组合。例如,假设这些因素介于 –1 和 +1 之间,正数表示匹配度较高,负数表示匹配度较弱,类别是科幻小说、动作片和老电影,那么我们可以表示电影《天行者崛起》如下:
rise_skywalker = np.array([0.98,0.9,-0.9])例如,在这里,我们将“非常科幻”评分为 0.98,“非常动作”评分为 0.9,“ 非常不古老”评分为 –0.9。我们可以代表一个喜欢现代科幻动作片的用户,如下所示:
user1 = np.array([0.9,0.8,-0.6])我们现在可以计算此组合之间的匹配:
(user1*rise_skywalker).sum()2.1420000000000003
当我们将两个向量相乘并将结果相加时,这是 称为点积。它在机器学习中被大量使用,并构成了矩阵乘法的基础。我们将在 第 17 章更多地关注矩阵乘法和点积。
将两个向量的元素相乘,然后将结果相加的数学运算。
另一方面,我们可以将电影《卡萨布兰卡》表示如下:
casablanca = np.array([-0.99,-0.3,0.8])此组合之间的匹配如下所示:
(user1*casablanca).sum()-1.611
由于我们不知道潜在因素是什么,也不知道如何为每个用户和电影对它们进行评分,因此我们应该学习它们。
学习潜在因素
令人惊讶的是,指定 a 的结构之间几乎没有区别 模型,就像我们在上一节中所做的那样,并学习一个模型,因为我们可以只使用我们的通用梯度下降方法。
这种方法的第一步是随机初始化一些参数。这些参数将是每个用户和电影的一组潜在因素。我们将不得不决定使用多少。我们将很快讨论如何选择它,但为了便于说明,我们现在使用 5。因为每个用户都有一组这些因素,每部电影都有一组这些因素,我们可以在交叉表中的用户和电影旁边显示这些随机初始化值,然后我们可以填写点积中间的每一个组合。例如,图 8-2显示了它在 Microsoft Excel 中的样子,以左上角的单元格公式为例。
这种方法的第 2 步是计算我们的预测。正如我们所讨论的,我们可以通过简单地对每个用户计算每部电影的点积来做到这一点。例如,如果第一个潜在用户因素表示用户对动作片的喜爱程度,而第一个潜在电影因素表示电影是否有很多动作,如果用户喜欢动作,那么它们的乘积将特别高电影并且电影中有很多动作,或者用户不喜欢动作片而电影中没有任何动作。另一方面,如果我们有不匹配(用户喜欢动作片但电影不是动作片,或者用户不喜欢动作片而它是一部),产品将非常低。
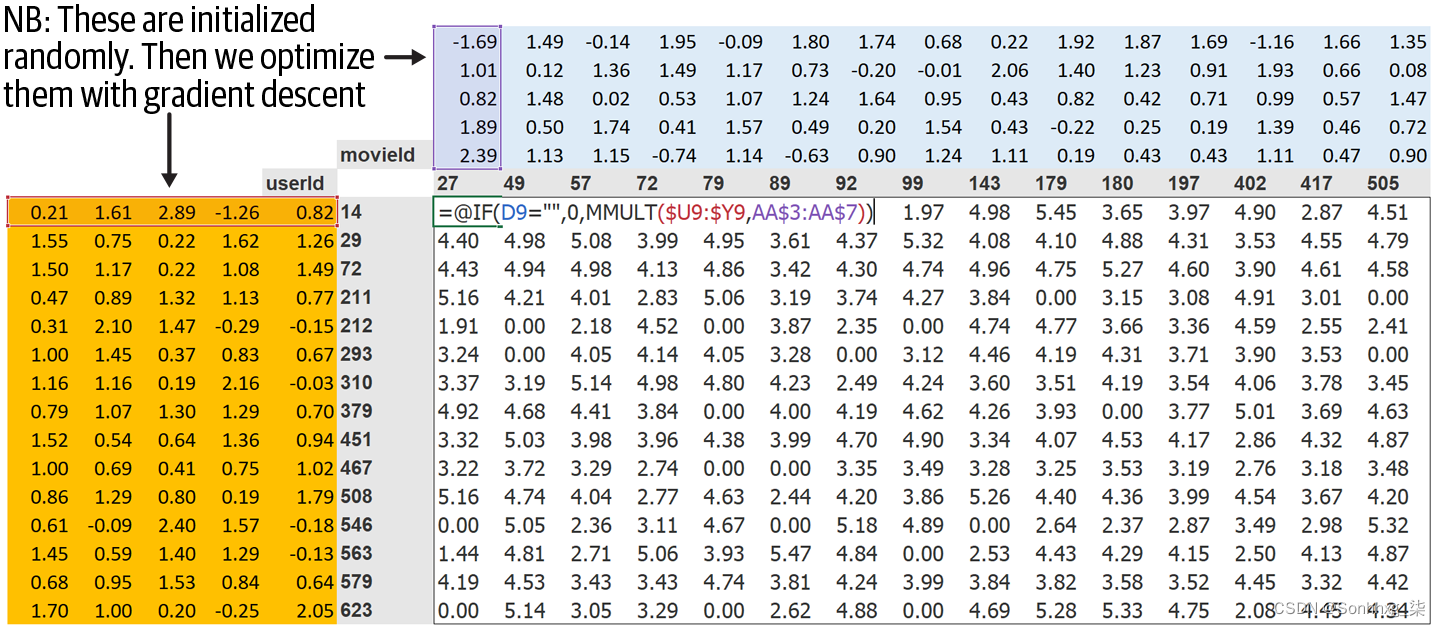
图 8-2。交叉表的潜在因素
第三步是计算我们的损失。我们可以使用我们想要的任何损失函数;现在让我们选择均方误差,因为这是表示预测准确性的一种合理方式。
这就是我们所需要的。有了这个,我们可以使用随机梯度下降优化我们的参数(潜在因素),例如最小化损失。在每一步,随机梯度下降优化器将使用点积计算每部电影与每个用户之间的匹配,并将其与每个用户对每部电影的实际评分进行比较。然后它将计算该值的导数,并通过将其乘以学习率来步进权重。这样做很多次之后,损失会越来越好,推荐也会越来越好。
要使用通常的Learner.fit功能,我们需要将数据放入 aDataLoaders中,所以现在让我们专注于此。
创建数据加载器
在显示数据时,我们宁愿看到电影标题而不是他们的 ID。 该表u.item包含ID与标题的对应关系:
movies = pd.read_csv(path/'u.item', delimiter='|', encoding='latin-1',
usecols=(0,1), names=('movie','title'), header=None)
movies.head()| movie | title | |
|---|---|---|
| 0 | 1 | Toy Story (1995) |
| 1 | 2 | GoldenEye (1995) |
| 2 | 3 | Four Rooms (1995) |
| 3 | 4 | Get Shorty (1995) |
| 4 | 5 | Copycat (1995) |
我们可以将其与我们的ratings表合并以按标题获取用户评分:
ratings = ratings.merge(movies)
ratings.head()| user | movie | rating | timestamp | tiltle | |
|---|---|---|---|---|---|
| 0 | 196 | 242 | 3 | 881250949 | Kolya(1996) |
| 1 | 63 | 242 | 3 | 875747190 | Kolya (1996) |
| 2 | 226 | 242 | 5 | 883888671 | Kolya(1996) |
| 3 | 154 | 242 | 3 | 879138235 | Kolya (1996) |
| 4 | 306 | 242 | 5 | 876503793 | Kolya (1996) |
然后我们可以从这个表构建一个DataLoaders对象。默认情况下,第一列用于用户,第二列用于项目(这里是我们的电影),第三列用于评级。在我们的例子中,我们需要更改 的值item_name以使用标题而不是 ID:
dls = CollabDataLoaders.from_df(ratings, item_name='title', bs=64)
dls.show_batch()| user | title | rating | |
|---|---|---|---|
| 0 | 207 | Four Weddings and a Funeral (1994) | 3 |
| 1 | 565 | Remains of the Day, The (1993) | 5 |
| 2 | 506 | Kids (1995) | 1 |
| 3 | 845 | Chasing Amy (1997) | 3 |
| 4 | 798 | Being Human (1993) | 2 |
| 5 | 500 | Down by Law (1986) | 4 |
| 6 | 409 | Much Ado About Nothing (1993) | 3 |
| 7 | 721 | Braveheart (1995) | 5 |
| 8 | 316 | Psycho (1960) | 2 |
| 9 | 883 | Judgment Night (1993) | 5 |
为了在 PyTorch 中表示协同过滤,我们 不能直接使用交叉表表示,特别是如果我们希望它适合我们的深度学习框架。我们可以将我们的电影和用户潜在因子表表示为简单的矩阵:
n_users = len(dls.classes['user'])
n_movies = len(dls.classes['title'])
n_factors = 5
user_factors = torch.randn(n_users, n_factors)
movie_factors = torch.randn(n_movies, n_factors)要计算特定电影和用户组合的结果,我们必须在电影隐因子矩阵中查找电影的索引,以及在用户隐因子矩阵中查找用户的索引;然后我们可以在两个潜在因子向量之间进行点积。但是在索引中查找并不是我们的深度学习模型知道该怎么做的操作。他们知道如何做矩阵乘积和激活 函数。
幸运的是,事实证明我们可以将索引中的查找表示为矩阵 产品。诀窍是用单热编码向量替换我们的索引。下面是一个示例,说明如果我们将一个向量乘以表示索引 3 的单热编码向量会发生什么:
one_hot_3 = one_hot(3, n_users).float()
user_factors.t() @ one_hot_3tensor([-0.4586, -0.9915, -0.4052, -0.3621, -0.5908])
它为我们提供了与矩阵中索引为 3 的向量相同的向量:
user_factors[3]tensor([-0.4586, -0.9915, -0.4052, -0.3621, -0.5908])
如果我们一次对几个索引执行此操作,我们将得到一个单热编码向量矩阵,并且该操作将是矩阵乘法!这将是使用这种架构构建模型的完全可接受的方式,除了它会使用比必要的更多的内存和时间。我们知道没有真正的基础 存储 one-hot-encoded 向量或搜索它以查找数字 1 的出现的原因——我们应该能够直接使用整数索引到数组中。因此,包括 PyTorch 在内的大多数深度学习库都包含一个特殊的层来执行此操作;它使用整数对向量进行索引,但其导数的计算方式与使用单热编码向量进行矩阵乘法时的结果相同。这称为嵌入。
与one-hot-encoded矩阵相乘,使用可以通过简单直接索引来实现的计算捷径。对于一个非常简单的概念,这是一个非常奇特的词。将单热编码矩阵乘以(或者,使用计算快捷方式,直接索引)的东西称为嵌入矩阵。
在计算机视觉中,我们有一种非常简单的方法可以通过像素的 RGB 值来获取像素的所有信息:彩色图像中的每个像素由三个数字表示。这三个数字为我们提供了红色、绿色和蓝色,这足以让我们的模型随后运行。
对于手头的问题,我们没有同样简单的方法来描述用户或电影的特征。可能与类型有关:如果给定用户喜欢爱情片,他们可能会给爱情片更高的分数。其他因素可能是电影是更注重动作还是更注重对话,或者是否出现了用户可能特别喜欢的特定演员。
我们如何确定数字来表征这些?答案是,我们没有。我们会让我们的模型学习它们。通过分析用户和电影之间的现有关系,我们的模型可以自己找出看起来重要或不重要的特征。
这就是嵌入。我们将为我们的每个用户和我们的每部电影分配一个特定长度的随机向量(这里, n_factors=5),我们将制作这些可学习的参数。这意味着在每一步,当我们通过将预测与目标进行比较来计算损失时,我们将计算损失相对于那些嵌入向量的梯度,并使用 SGD(或其他优化器)的规则更新它们。
一开始,这些数字没有任何意义,因为我们是随机选择它们的,但是在训练结束时,它们将具有任何意义。通过学习关于用户和电影之间关系的现有数据,在没有任何其他信息的情况下,我们将看到它们仍然获得了一些重要的特征,并且可以将大片与独立电影、动作片与浪漫片等区分开来。
我们现在可以从头开始创建我们的整个模型。
从零开始的协同过滤
在我们用 PyTorch 编写模型之前,我们首先需要学习 面向对象编程和 Python 的基础知识。如果您以前没有做过任何面向对象的编程,我们将在这里给您一个快速介绍,但我们建议您在继续之前先查找教程并进行一些练习。
面向对象编程的关键思想是类。我们已经 在本书中使用类,例如DataLoader、String和 Learner。Python 也让我们很容易创建新的类。这是一个简单类的示例:
class Example:
def __init__(self, a): self.a = a
def say(self,x): return f'Hello {self.a}, {x}.'其中最重要的部分是称为__init__ (发音为dunder init)的特殊方法。在 Python 中,任何方法都包含在 double 中 像这样的下划线被认为是特殊的。它表示一些额外的行为与此方法名称相关联。在 的情况下 __init__,这是创建新对象时 Python 将调用的方法。因此,您可以在这里设置任何需要在对象创建时初始化的状态。用户构造类的实例时包含的任何参数都将 __init__作为参数传递给方法。请注意,在类中定义的任何方法的第一个参数都是self,因此您可以使用它来设置和获取您需要的任何属性:
ex = Example('Sylvain')
ex.say('nice to meet you')'Hello Sylvain, nice to meet you.'
另请注意,创建新的 PyTorch 模块需要继承自 Module. 继承是一个重要的面向对象概念,我们在这里不做详细讨论——简而言之,它意味着我们可以向现有类添加额外的行为。PyTorch 已经提供了一个 Module类,它提供了一些我们想要构建的基础。因此,我们将这个超类的名称添加到我们正在定义的类的名称之后,如以下示例所示。
创建一个新的 PyTorch 模块你需要知道的最后一件事是 当您的模块被调用时,PyTorch 将调用您的类中名为 的方法,并将调用forward中包含的任何参数传递给该方法。这是定义我们的点积模型的类:
class DotProduct(Module):
def __init__(self, n_users, n_movies, n_factors):
self.user_factors = Embedding(n_users, n_factors)
self.movie_factors = Embedding(n_movies, n_factors)
def forward(self, x):
users = self.user_factors(x[:,0])
movies = self.movie_factors(x[:,1])
return (users * movies).sum(dim=1)如果您以前没有见过面向对象编程,别担心;你不需要在本书中经常使用它。我们只是在这里提到这种方法,因为大多数在线教程和文档将使用面向对象的语法。
请注意,模型的输入是形状为 的张量batch_size x 2,其中第一列 ( x[:, 0]) 包含用户 ID,第二列 ( x[:, 1]) 包含电影 ID。如前所述,我们使用嵌入层来表示我们的用户和电影潜在因素矩阵:
x,y = dls.one_batch()
x.shapetorch.Size([64, 2])
现在我们已经定义了架构并创建了参数 矩阵,我们需要创建一个Learner来优化我们的模型。过去,我们使用特殊功能,例如cnn_learner,它为我们针对特定应用程序设置了一切。由于我们在这里从头开始做事,我们将使用普通Learner类:
model = DotProduct(n_users, n_movies, 50)
learn = Learner(dls, model, loss_func=MSELossFlat())learn.fit_one_cycle(5, 5e-3)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 1.326261 | 1.295701 | 00:12 |
| 1 | 1.091352 | 1.091475 | 00:11 |
| 2 | 0.961574 | 0.977690 | 00:11 |
| 3 | 0.829995 | 0.893122 | 00:11 |
| 4 | 0.781661 | 0.876511 | 00:12 |
为了使这个模型更好一点,我们可以做的第一件事是强制这些预测值在 0 到 5 之间。为此,我们只需要使用 sigmoid_range,如第 6 章所述。我们发现的一件事 根据经验,范围最好超过 5,所以我们使用(0, 5.5):
class DotProduct(Module):
def __init__(self, n_users, n_movies, n_factors, y_range=(0,5.5)):
self.user_factors = Embedding(n_users, n_factors)
self.movie_factors = Embedding(n_movies, n_factors)
self.y_range = y_range
def forward(self, x):
users = self.user_factors(x[:,0])
movies = self.movie_factors(x[:,1])
return sigmoid_range((users * movies).sum(dim=1), *self.y_range)model = DotProduct(n_users, n_movies, 50)
learn = Learner(dls, model, loss_func=MSELossFlat())
learn.fit_one_cycle(5, 5e-3)| epoch | train_loss | 有效损失 | 时间 |
|---|---|---|---|
| 0 | 0.976380 | 1.001455 | 00:12 |
| 1 | 0.875964 | 0.919960 | 00:12 |
| 2 | 0.685377 | 0.870664 | 00:12 |
| 3 | 0.483701 | 0.874071 | 00:12 |
| 4 | 0.385249 | 0.878055 | 00:12 |
这是一个合理的开始,但我们可以做得更好。一个明显缺失的部分是,一些用户在他们的推荐中比其他人更积极或更消极,而一些电影只是比其他人更好或更差。但是在我们的点积表示中,我们没有任何方法来编码这些东西。如果你只能说一部电影很科幻,很动作,很不老,那么你真的没有办法说大多数人是否喜欢它。
那是因为此时我们只有权重;我们没有偏见。如果我们可以为每个用户添加一个号码 我们的分数,以及每部电影的同上,将很好地处理这个缺失的部分。所以首先,让我们调整我们的模型架构:
class DotProductBias(Module):
def __init__(self, n_users, n_movies, n_factors, y_range=(0,5.5)):
self.user_factors = Embedding(n_users, n_factors)
self.user_bias = Embedding(n_users, 1)
self.movie_factors = Embedding(n_movies, n_factors)
self.movie_bias = Embedding(n_movies, 1)
self.y_range = y_range
def forward(self, x):
users = self.user_factors(x[:,0])
movies = self.movie_factors(x[:,1])
res = (users * movies).sum(dim=1, keepdim=True)
res += self.user_bias(x[:,0]) + self.movie_bias(x[:,1])
return sigmoid_range(res, *self.y_range)让我们尝试训练它,看看它是如何进行的:
model = DotProductBias(n_users, n_movies, 50)
learn = Learner(dls, model, loss_func=MSELossFlat())
learn.fit_one_cycle(5, 5e-3)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.929161 | 0.936303 | 00:13 |
| 1 | 0.820444 | 0.861306 | 00:13 |
| 2 | 0.621612 | 0.865306 | 00:14 |
| 3 | 0.404648 | 0.886448 | 00:13 |
| 4 | 0.292948 | 0.892580 | 00:13 |
它没有变得更好,而是变得更糟(至少在 训练)。这是为什么?如果我们仔细观察这两个训练,我们可以看到验证损失在中间停止改善并开始变得更糟。正如我们所见,这是过度拟合的明显迹象。在这种情况下,没有办法使用数据扩充,所以我们将不得不使用另一种正则化技术。一种有用的方法是权重衰减。
重量衰减
权重衰减或L2 正则化包括将所有权重的平方和添加到您的损失函数中。为什么要这样做?因为当 我们计算梯度,它会增加对它们的贡献,这将鼓励权重尽可能小。
为什么它会防止过度拟合?这个想法是系数越大,损失函数中的峡谷就越尖锐。如果我们以抛物线为例,y = a * (x**2)越大a,抛物线越窄:
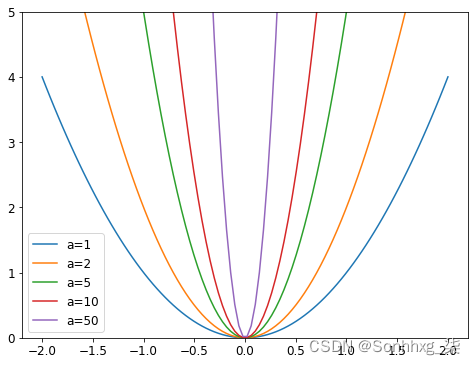
所以,让我们的模型学习高参数可能会导致它用一个过于复杂的函数来拟合训练集中的所有数据点,这个函数的变化非常剧烈,这将导致过拟合。
限制我们的权重增长太多会阻碍模型的训练,但它会产生一个更好泛化的状态。简要地回到理论,权重衰减(或只是 wd)是一个参数,它控制我们添加到损失中的平方和(假设parameters是所有参数的张量):
loss_with_wd = loss + wd * (parameters**2).sum()但在实践中,计算这么大的总和并将其添加到损失中将是非常低效的(并且可能在数值上不稳定)。如果你还记得一点高中数学知识,你可能还记得关于 的导数p**2是p,2*p所以将这个大和加到我们的损失中与这样做完全相同:
parameters.grad += wd * 2 * parameters 在实践中,由于wd是我们选择的参数,我们可以将其设置为两倍大,因此我们甚至不需要*2这个等式中的 。要在 fastai 中使用权重衰减,请将wd您的调用传递给 fitor fit_one_cycle(它可以同时传递给两者):
model = DotProductBias(n_users, n_movies, 50)
learn = Learner(dls, model, loss_func=MSELossFlat())
learn.fit_one_cycle(5, 5e-3, wd=0.1)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.972090 | 0.962366 | 00:13 |
| 1 | 0.875591 | 0.885106 | 00:13 |
| 2 | 0.723798 | 0.839880 | 00:13 |
| 3 | 0.586002 | 0.823225 | 00:13 |
| 4 | 0.490980 | 0.823060 | 00:13 |
创建我们自己的嵌入模块
到目前为止,我们已经使用Embedding了而没有考虑它是如何使用的 真的有效。DotProductBias 让我们在不使用此类的情况下重新创建。我们需要为每个嵌入设置一个随机初始化的权重矩阵。然而,我们必须小心。回想一下 第 4 章,优化器要求它们能够 从模块的 parameters方法中获取模块的所有参数。但是,这不会完全自动发生。如果我们只是将张量作为属性添加到 aModule中,它不会包含在 中parameters:
class T(Module):
def __init__(self): self.a = torch.ones(3)
L(T().parameters())(#0) []
为了Module表明我们想将张量视为参数,我们有 把它包装在nn.Parameter课堂上。此类不添加任何功能(除了自动调用 requires_grad_我们)。它仅用作“标记”以显示要包含的内容parameters:
class T(Module):
def __init__(self): self.a = nn.Parameter(torch.ones(3))
L(T().parameters())(#1) [Parameter containing: tensor([1., 1., 1.], requires_grad=True)]
所有 PyTorch 模块都使用nn.Parameter任何可训练参数,这就是为什么我们直到现在才需要显式使用这个包装器:
class T(Module):
def __init__(self): self.a = nn.Linear(1, 3, bias=False)
t = T()
L(t.parameters())(#1) [Parameter containing:
tensor([[-0.9595],
[-0.8490],
[ 0.8159]], requires_grad=True)]
type(t.a.weight)torch.nn.parameter.Parameter
我们可以创建一个张量作为参数,并进行随机初始化,如下所示:
def create_params(size):
return nn.Parameter(torch.zeros(*size).normal_(0, 0.01))让我们用它来DotProductBias再次创建,但没有 Embedding:
class DotProductBias(Module):
def __init__(self, n_users, n_movies, n_factors, y_range=(0,5.5)):
self.user_factors = create_params([n_users, n_factors])
self.user_bias = create_params([n_users])
self.movie_factors = create_params([n_movies, n_factors])
self.movie_bias = create_params([n_movies])
self.y_range = y_range
def forward(self, x):
users = self.user_factors[x[:,0]]
movies = self.movie_factors[x[:,1]]
res = (users*movies).sum(dim=1)
res += self.user_bias[x[:,0]] + self.movie_bias[x[:,1]]
return sigmoid_range(res, *self.y_range)然后让我们再次训练它以检查我们得到的结果与上一节中看到的结果相同:
model = DotProductBias(n_users, n_movies, 50)
learn = Learner(dls, model, loss_func=MSELossFlat())
learn.fit_one_cycle(5, 5e-3, wd=0.1)| epoch | train_loss | vaild_loss | time |
|---|---|---|---|
| 0 | 0.962146 | 0.936952 | 00:14 |
| 1 | 0.858084 | 0.884951 | 00:14 |
| 2 | 0.740883 | 0.838549 | 00:14 |
| 3 | 0.592497 | 0.823599 | 00:14 |
| 4 | 0.473570 | 0.824263 | 00:14 |
现在,让我们看看我们的模型学到了什么。
解释嵌入和偏差
我们的模型已经很有用了,因为它可以为我们提供电影 为我们的用户提供的建议——但看看它发现了哪些参数也很有趣。最容易解释的是偏见。以下是偏置向量中值最低的电影:
movie_bias = learn.model.movie_bias.squeeze()
idxs = movie_bias.argsort()[:5]
[dls.classes['title'][i] for i in idxs]['Children of the Corn: The Gathering (1996)', 'Lawnmower Man 2: Beyond Cyberspace (1996)', 'Beautician and the Beast, The (1997)', 'Crow: City of Angels, The (1996)', 'Home Alone 3 (1997)']
想想这意味着什么。它的意思是,对于这些电影中的每一部电影,即使用户与其潜在因素非常匹配(正如我们稍后会看到的那样,它往往代表动作水平、电影年龄等) ),他们仍然普遍不喜欢它。我们本可以简单地直接根据电影的平均评分对电影进行排序,但观察习得的偏见会告诉我们一些更有趣的事情。它不仅告诉我们一部电影是否属于人们不喜欢看的电影,而且告诉我们人们往往不喜欢看它,即使它是他们本来会喜欢的电影!出于同样的原因,以下是偏见最高的电影:
idxs = movie_bias.argsort(descending=True)[:5]
[dls.classes['title'][i] for i in idxs]['L.A. Confidential (1997)', 'Titanic (1997)', 'Silence of the Lambs, The (1991)', 'Shawshank Redemption, The (1994)', 'Star Wars (1977)']
因此,例如,即使您通常不喜欢侦探电影,您也可能会喜欢洛杉矶机密!
直接解释嵌入矩阵并不是那么容易。人类需要考虑的因素太多了。但是有一种技术可以从这样的矩阵中提取出最重要的潜在方向 ,称为主成分分析(PCA)。我们不会在本书中详细介绍这一点,因为了解成为深度学习实践者并不是特别重要,但如果您有兴趣,我们建议您查看 fast.ai 课程计算线性代数编码员。 图 8-3显示了我们的电影基于两个最强大的 PCA 组件的样子。
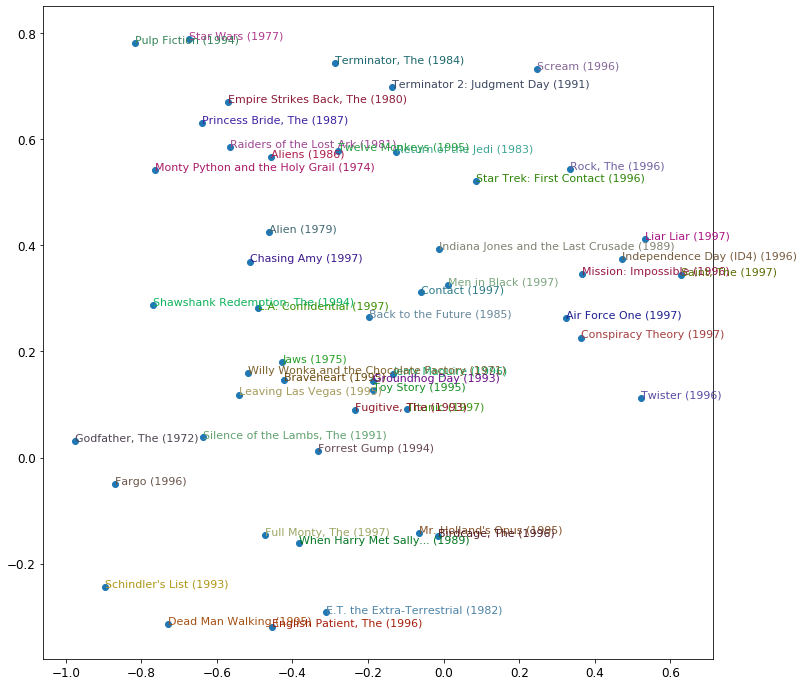
图 8-3。基于两个最强 PCA 组件的电影表示
我们在这里可以看到,该模型似乎发现了 经典电影与流行文化电影的概念,或者可能是这里所代表的广受好评。
无论我训练了多少模型,我都对这些随机初始化的数字束感到感动和惊讶,这些数字是用如此简单的机制训练的,如何设法自行发现关于我的数据的事情。这几乎像是在作弊,我可以创建代码来做有用的事情,而无需实际告诉它如何做这些事情!
我们从头开始定义我们的模型来教你里面有什么,但你可以直接使用 fastai 库来构建它。接下来我们将看看如何做到这一点。
使用 fastai.collab
我们可以使用 fastai 之前显示的确切结构来创建和训练协同过滤模型collab_learner:
learn = collab_learner(dls, n_factors=50, y_range=(0, 5.5))learn.fit_one_cycle(5, 5e-3, wd=0.1)| epoch | train_loss | vaild_loss | time |
|---|---|---|---|
| 0 | 0.931751 | 0.953806 | 00:13 |
| 1 | 0.851826 | 0.878119 | 00:13 |
| 2 | 0.715254 | 0.834711 | 00:13 |
| 3 | 0.583173 | 0.821470 | 00:13 |
| 4 | 0.496625 | 0.821688 | 00:13 |
learn.modelEmbeddingDotBias( (u_weight): Embedding(944, 50) (i_weight): Embedding(1635, 50) (u_bias): Embedding(944, 1) (i_bias): Embedding(1635, 1) )
我们可以使用这些来复制我们在上一节中所做的任何分析——例如:
movie_bias = learn.model.i_bias.weight.squeeze()
idxs = movie_bias.argsort(descending=True)[:5]
[dls.classes['title'][i] for i in idxs]['Titanic (1997)', "Schindler's List (1993)", 'Shawshank Redemption, The (1994)', 'L.A. Confidential (1997)', 'Silence of the Lambs, The (1991)']
Another interesting thing we can do with these learned embeddings is to look at distance.
Embedding Distance
On a two-dimensional map, we can calculate the distance between two coordinates by using the formula of Pythagoras: x2+y2 (assuming that x and y are the distances between the coordinates on each axis). For a 50-dimensional embedding, we can do exactly the same thing, except that we add up the squares of all 50 of the coordinate distances.
如果有两部电影几乎相同,那么它们的嵌入向量也必须几乎相同,因为喜欢它们的用户几乎完全相同。这里有一个更普遍的想法:电影相似度可以定义为喜欢这些电影的用户的相似度。这直接意味着两部电影的嵌入向量之间的距离可以定义这种相似性。我们可以用它来找到与《沉默的羔羊》最相似的电影:
movie_factors = learn.model.i_weight.weight
idx = dls.classes['title'].o2i['Silence of the Lambs, The (1991)']
distances = nn.CosineSimilarity(dim=1)(movie_factors, movie_factors[idx][None])
idx = distances.argsort(descending=True)[1]
dls.classes['title'][idx]'Dial M for Murder (1954)'
现在我们已经成功训练了一个模型,让我们看看如何处理用户没有数据的情况。我们如何向新用户推荐?
引导协同过滤模型
在实践中使用协同过滤模型的最大挑战是引导问题。最极端的版本 这个问题是没有用户,因此没有历史可以学习。您向您的第一个用户推荐什么产品?
但即使您是一家拥有悠久用户交易历史的老牌公司,您仍然会有一个问题:当新用户注册时,您会怎么做?事实上,当您将新产品添加到您的产品组合时,您会怎么做?这个问题没有神奇的解决方案,实际上我们建议的解决方案只是 使用常识的变体. 您可以为新用户分配其他用户的所有嵌入向量的均值,但这有一个问题,即潜在因素的特定组合可能根本不常见(例如,科幻因素的平均值可能是高,而行动因素的平均值可能较低,但找到喜欢科幻小说但不采取行动的人并不常见)。选择一个特定的用户来代表平均品味可能会更好。
更好的方法是使用基于用户元数据的表格模型来构建您的初始嵌入向量。当用户注册时,想一想您可以提出哪些问题来帮助您了解他们的喜好。然后你可以创建一个模型,其中因变量是用户的嵌入向量,自变量是你向他们提出的问题的结果,以及他们的注册元数据。我们将在下一节中看到如何创建这些类型的表格模型。(你可能已经注意到,当你注册 Pandora 和 Netflix 等服务时,他们往往会问你几个关于你喜欢什么类型的电影或音乐的问题;这就是他们提出你最初的协同过滤建议的方式。)
需要注意的一件事是,少数非常热心的用户可能最终会有效地设置推荐 为您的整个用户群。这是一个非常普遍的问题,例如,在电影推荐系统中。看动漫的人往往会看很多,而不会看其他的,并且会花很多时间将他们的评分放在网站上。结果,动漫在许多 有史以来最好的电影列表中往往被大量代表。在这种特殊情况下,很明显存在表示偏差问题,但如果偏差发生在潜在因素中,则可能根本不明显。
这样的问题可能会改变您的用户群的整体构成,并且 你的系统的行为。由于正反馈循环,这一点尤其正确。如果你的一小部分用户倾向于设定你的推荐系统的方向,他们自然会最终吸引更多像他们一样的人加入你的系统。当然,这会放大原始表示偏差。这种类型的偏差是一种以指数方式放大的自然趋势。您可能已经看到公司高管对他们的在线平台如何迅速恶化表示惊讶,以至于他们表达的价值观与创始人的价值观不一致的例子。在存在这些类型的反馈循环的情况下,很容易看出这种分歧是如何迅速发生的,并且以一种隐藏的方式发生,直到为时已晚。
在这样一个自我强化的系统中,我们可能应该期望这些类型的反馈循环成为常态,而不是例外。因此,您应该假设您会看到它们,为此做好计划,并预先确定您将如何处理这些问题。尝试考虑在您的系统中可能表示反馈循环的所有方式,以及您如何能够在您的数据中识别它们。最后,这又回到了我们最初关于在推出任何类型的机器学习系统时如何避免灾难的建议。这一切都是为了确保有人参与其中;有仔细的监控,以及循序渐进和深思熟虑的推出。
我们的点积模型运行良好,它是许多成功的现实世界推荐系统的基础。这种方法 协同过滤被称为概率矩阵分解 (PMF)。另一种通常在给定相同数据的情况下同样有效的方法是深度学习。
协同过滤的深度学习
要将我们的架构转变为深度学习模型,第一步是 获取嵌入查找的结果并将这些激活连接在一起。这给了我们一个矩阵,然后我们可以用通常的方式通过线性层和非线性层。
由于我们将连接嵌入,而不是采用它们的点积,因此两个嵌入矩阵可以具有不同的大小(不同数量的潜在因子)。fastai 有一个函数get_emb_sz,可以根据 fast.ai 发现在实践中效果很好的启发式方法返回数据嵌入矩阵的推荐大小:
embs = get_emb_sz(dls)
embs[(944, 74), (1635, 101)]
让我们实现这个类:
class CollabNN(Module):
def __init__(self, user_sz, item_sz, y_range=(0,5.5), n_act=100):
self.user_factors = Embedding(*user_sz)
self.item_factors = Embedding(*item_sz)
self.layers = nn.Sequential(
nn.Linear(user_sz[1]+item_sz[1], n_act),
nn.ReLU(),
nn.Linear(n_act, 1))
self.y_range = y_range
def forward(self, x):
embs = self.user_factors(x[:,0]),self.item_factors(x[:,1])
x = self.layers(torch.cat(embs, dim=1))
return sigmoid_range(x, *self.y_range)并用它来创建模型:
model = CollabNN(*embs)CollabNNEmbedding以与本章前面的类相同的方式创建我们的层,除了我们现在使用embs尺寸。 self.layers与我们在 第 4 章中为 MNIST 创建的微型神经网络相同。然后,在 中forward,我们应用嵌入,连接结果,并将其传递给微型神经网络。最后,我们sigmoid_range像在以前的模型中一样应用。
让我们看看它是否训练:
learn = Learner(dls, model, loss_func=MSELossFlat())
learn.fit_one_cycle(5, 5e-3, wd=0.01)| epoch | train_loss | vaild_loss | time |
|---|---|---|---|
| 0 | 0.940104 | 0.959786 | 00:15 |
| 1 | 0.893943 | 0.905222 | 00:14 |
| 2 | 0.865591 | 0.875238 | 00:14 |
| 3 | 0.800177 | 0.867468 | 00:14 |
| 4 | 0.760255 | 0.867455 | 00:14 |
fastai.collab如果您将use_nn=True 呼叫传递给collab_learner(包括呼叫您), fastai 会提供此模型get_emb_sz,它可以让您轻松创建更多层。例如,这里我们创建两个隐藏层,大小分别为 100 和 50:
learn = collab_learner(dls, use_nn=True, y_range=(0, 5.5), layers=[100,50])
learn.fit_one_cycle(5, 5e-3, wd=0.1)| epoch | train_loss | vaild_loss | time |
|---|---|---|---|
| 0 | 1.002747 | 0.972392 | 00:16 |
| 1 | 0.926903 | 0.922348 | 00:16 |
| 2 | 0.877160 | 0.893401 | 00:16 |
| 3 | 0.838334 | 0.865040 | 00:16 |
| 4 | 0.781666 | 0.864936 | 00:16 |
learn.model是类型的对象EmbeddingNN。我们来看看fastai的这个类的代码:
@delegates(TabularModel)
class EmbeddingNN(TabularModel):
def __init__(self, emb_szs, layers, **kwargs):
super().__init__(emb_szs, layers=layers, n_cont=0, out_sz=1, **kwargs)哇,那不是很多代码!此类继承自 TabularModel,这是它从中获取所有功能的地方。在 __init__中,它调用相同的方法TabularModel,传递 n_cont=0和out_sz=1;除此之外,它只传递它收到的任何参数。
KWARGS 和 DELEGATES
EmbeddingNN包括**kwargs作为参数__init__。在 Python**kwargs在参数列表中的意思是“将任何其他关键字参数放入名为 的字典中” kwargs。在**kwargs参数列表中意味着“将kwargs字典中的所有键/值对作为命名参数插入此处。” 这种方法在许多流行的库中使用,例如matplotlib,其中 mainplot函数仅具有签名plot(*args, **kwargs)。该 plot文档说“这些kwargs是Line2D属性”,然后列出了这些属性。
我们正在使用**kwargsinEmbeddingNN来避免将所有参数写入TabularModel第二次,并使它们保持同步。然而,这使得我们的 API 很难使用,因为现在 Jupyter Notebook 不知道有哪些参数可用。因此,诸如参数名称的 Tab 完成和签名的弹出列表之类的东西将不起作用。
fastai 通过提供一个特殊的@delegates装饰器来解决这个问题, 它会自动更改类或函数(EmbeddingNN在本例中)的签名,以将其所有关键字参数插入到签名中。
虽然结果EmbeddingNN比点积方法差一点(它显示了为域精心构建架构的力量),但它确实让我们做了一些非常重要的事情:我们现在可以直接合并其他用户和电影信息,日期和时间信息,或任何其他可能与推荐相关的信息。这正是TabularModel它的作用。事实上,我们现在已经看到它EmbeddingNN只是一个 TabularModel,n_cont=0和out_sz=1。所以,我们最好花点时间了解一下TabularModel,以及如何使用它来获得好的结果!我们将在下一章中这样做。
结论
对于我们的第一个非计算机视觉应用程序,我们研究了推荐系统,并了解梯度下降如何从评级历史中学习项目的内在因素或偏见。然后,这些可以为我们提供有关数据的信息。
我们还在 PyTorch 中构建了我们的第一个模型。我们将在本书的下一节中做更多这方面的工作,但首先,让我们结束对深度学习的其他一般应用的深入研究,继续使用表格数据。
相关文章
- 深度学习四大框架之争(Tensorflow、Pytorch、Keras和Paddle)
- pytorch中的卷积操作详解
- pytorch – ohem 代码实现
- 独家 | 兼顾速度和存储效率的PyTorch性能优化(2022)
- PyTorch正式加入Linux基金会,Linux基金会多了一把「瑞士军刀」?
- pytorch交叉熵损失函数计算_pytorch loss不下降
- pytorch MSELoss参数详解「建议收藏」
- Pytorch cuda上的tensor转numpy[通俗易懂]
- pytorch tensor转int_numpy和pytorch
- pyTorch入门(三)——GoogleNet和ResNet训练
- PyTorch的Dataset 和TorchData API的比较
- 语句掌握Oracle中用WITH语句的利用技巧(oracle的with)
- Oracle 中的 WITH 语句使用技巧(oracle with用法)
- 语句Oracle中简洁的With语句(oracle 中with)
- 语句使用Oracle两个WITH语句实现数据查询(oracle两个with)