
面试题系列:JVM 夺命18问,你能扛到第几问
1.说说 JVM 的内存布局?
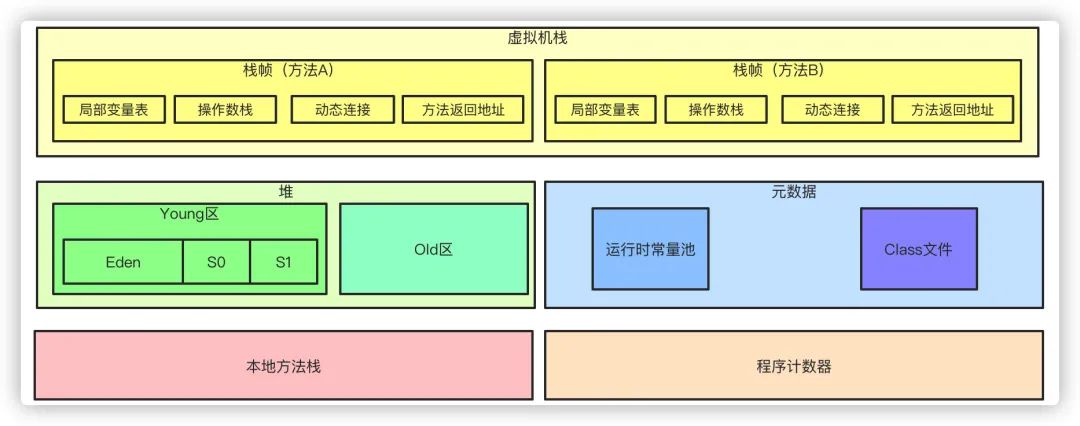
Java虚拟机主要包含几个区域:
1,程序计数器:「程序控制流的指示器,循环,跳转,异常处理,线程的恢复等工作都需要依赖程序计数器去完成」。程序计数器是「线程私有」的,它的「生命周期是和线程保持一致」的。用于记录当前线程下虚拟机正在执行的字节码的指令地址
2,虚拟机栈:是线程内存模型,栈是每个线程私有的内存区域,「生命周期与线程保持一致」。每个方法执行的时候JVM都会在栈创建一个栈帧,一个方法的调用过程就对应着栈的入栈和出栈的过程。每个栈帧的结构又包含局部变量表、操作数栈、动态连接、方法出口返回地址。
2.1,局部变量表用于存储方法参数和局部变量。当第一个方法被调用的时候,他的参数会被传递至从0开始的连续的局部变量表中。
2.2,操作数栈用于一些字节码指令从局部变量表中传递至操作数栈,也用来准备方法调用的参数以及接收方法返回结果。
2.3,动态连接用于将符号引用表示的方法转换为实际方法的直接引用。
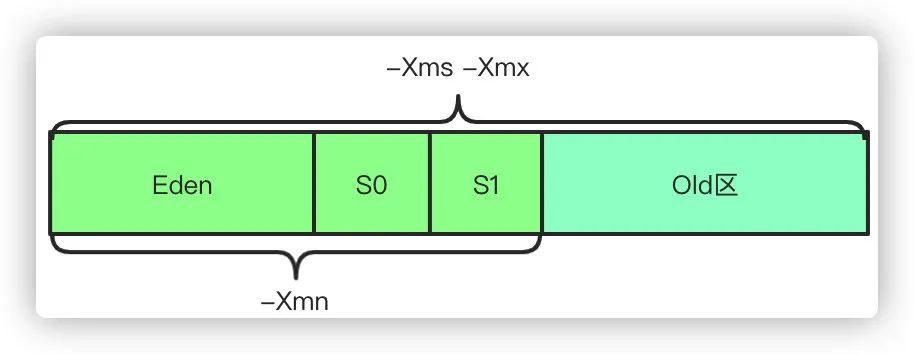
3,堆:堆Java虚拟机中最大的一块内存,是【线程共享】的内存区域,基本上所有的对象实例数组都是在堆上分配空间。堆区细分为Yound区年轻代和Old区老年代,其中年轻代又分为Eden、S0、S1 3个部分,他们默认的比例是8:1:1的大小。
4,元数据(方法区):是所有「线程共享」的区域。在Java1.7之前,包含方法区的概念,常量池就存在于方法区(永久代)中,而方法区本身是一个逻辑上的概念,在1.7之后则是把常量池移到了堆内,1.8之后移出了永久代的概念(方法区的概念仍然保留),实现方式则是现在的元数据。它包含类的元信息和运行时常量池。
4.1,Class文件就是类和接口的定义信息。
4.2,运行时常量池:就是类和接口的常量池运行时的表现形式。
5,本地方法栈:主要用于执行本地native方法的区域。我们知道,java底层用了很多c的代码去实现,而其调用c端的方法上都会有native,代表本地方法服务,而本地方法栈就是为其服务的。
2.知道 new 一个对象的过程吗?
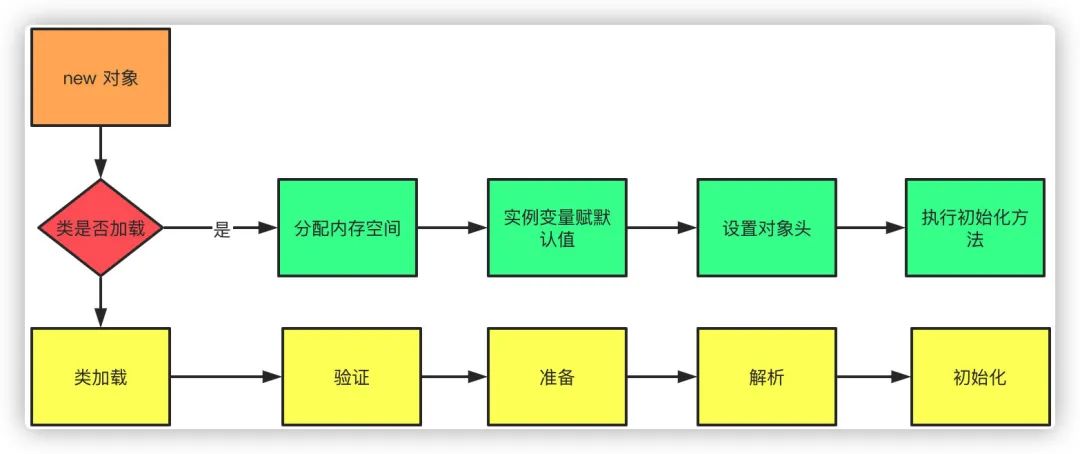
当虚拟机遇见new关键字时候,实现判断当前类是否已经加载,如果类没有加载,首先执行类的加载机制,加载完成后再为对象分配空间、初始化等。
1.类加载校验:首先校验当前类是否被加载,如果没有加载,执行类加载机制
2.加载:就是从字节码加载成二进制流的过程
3.验证:当然加载完成之后,当然需要校验Class文件是否符合虚拟机规范,跟我们接口请求一样,第一件事情当然是先做个参数校验了
4.准备:为静态变量、常量赋默认值
5.解析:把常量池中符号引用(以符号描述引用的目标)替换为直接引用(指向目标的指针或者句柄等)的过程
6.初始化:执行static代码块(cinit)进行初始化,如果存在父类,先对父类进行初始化
Ps:静态代码块是绝对线程安全的,只能隐式被java虚拟机在类加载过程中初始化调用!(此处该有问题static代码块线程安全吗?)
当类加载完成之后,紧接着就是对象分配内存空间和初始化的过程
1.首先为对象分配合适大小的内存空间
2.接着为实例变量赋默认值
3.设置对象的头信息,对象hash码、GC分代年龄、元数据信息等
4.执行构造函数(init)初始化
类的加载机制总结:
Java 虚拟机「把描述类的数据从 Class 文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被 Jvm 可以直接使用的类型」,这个过程就可以成为虚拟机的类加载机制。
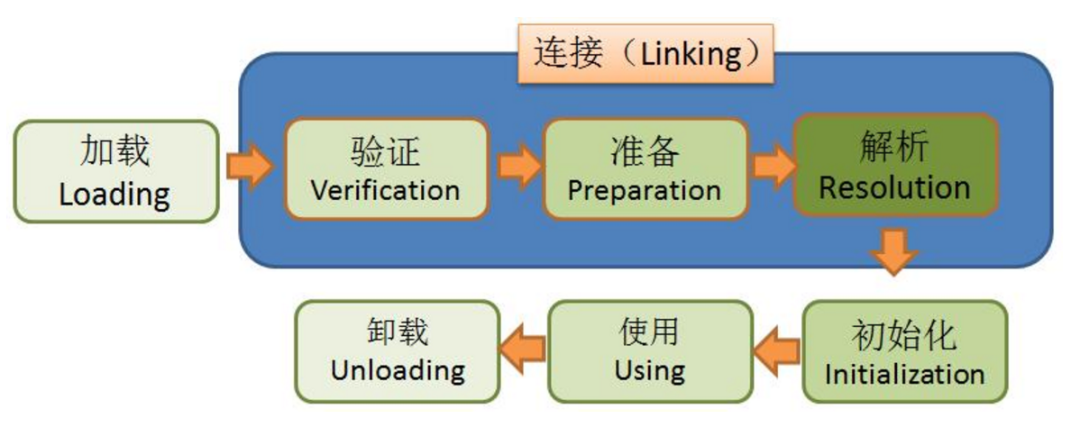
这是一张很经典的图,标明了一个类的生命周期,而很多人一眼看过去就以为明白了类的生命周期,但是这只是其中一种情况。
真实情况是「加载、验证、准备、初始化、卸载这五个阶段的顺序是确定的,是依次有序的」。但是「解析阶段有可能会在初始化之后才会进行」,这是「为了支持 Java 动态绑定」的特性。
「动态绑定」:
「在运行时根据具体对象的类型进行绑定」。提供了一些机制,可在运行期间判断对象的类型,并分别调用适当的方法。也就是说,编译器此时依然不知道对象的类型,但方法调用机制能自己去调查,找到正确的方法主体。
3.说一说对象的内存布局是怎样的?
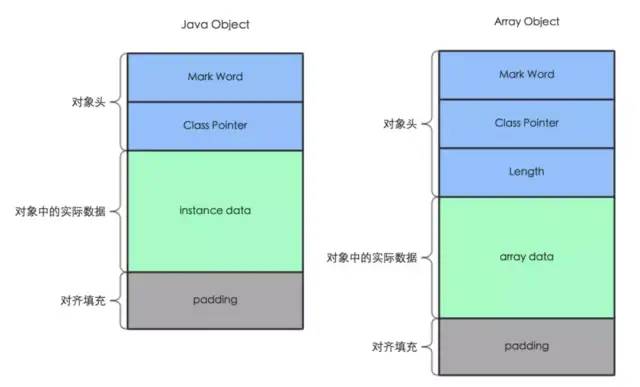
对象内存布局
「1.对象头」: 对象头又分为 「MarkWord」 和 「Class Pointer」 两部分。
「MarkWord」:对象自身运行时所需的数据。具体:对象的hashcode、分代年龄、轻量级锁指针、重量级锁指针、GC标记、偏向锁线程ID、偏向锁时间戳。
「ClassPointer」:存储类型指针,也就是指向类的元数据的指针,通过这个指针才能确定对象是属于哪个类的实例。用来指向对象对应的 Class 对象(其对应的元数据对象)的内存地址。在 32 位系统占 4 字节,在 64 位系统中占 8 字节。
「2.Length」:长度:只在数组对象中存在,用来记录数组的长度,占用 4 字节
「3.Instance data」: 对象实例数据,对象实际数据包括了对象的所有成员变量,其大小由各个成员变量的大小决定。(这里不包括静态成员变量,因为其是在方法区维护的)
「4.Padding」:对齐补充:Java 对象占用空间是 8 字节对齐的,即所有 Java 对象占用 bytes 数必须是 8 的倍数,是因为当我们从磁盘中取一个数据时,不会说我想取一个字节就是一个字节,都是按照一块儿一块儿来取的,这一块大小是 8 个字节,所以为了完整,padding 的作用就是补充字节,「保证对象是 8 字节的整数倍」。
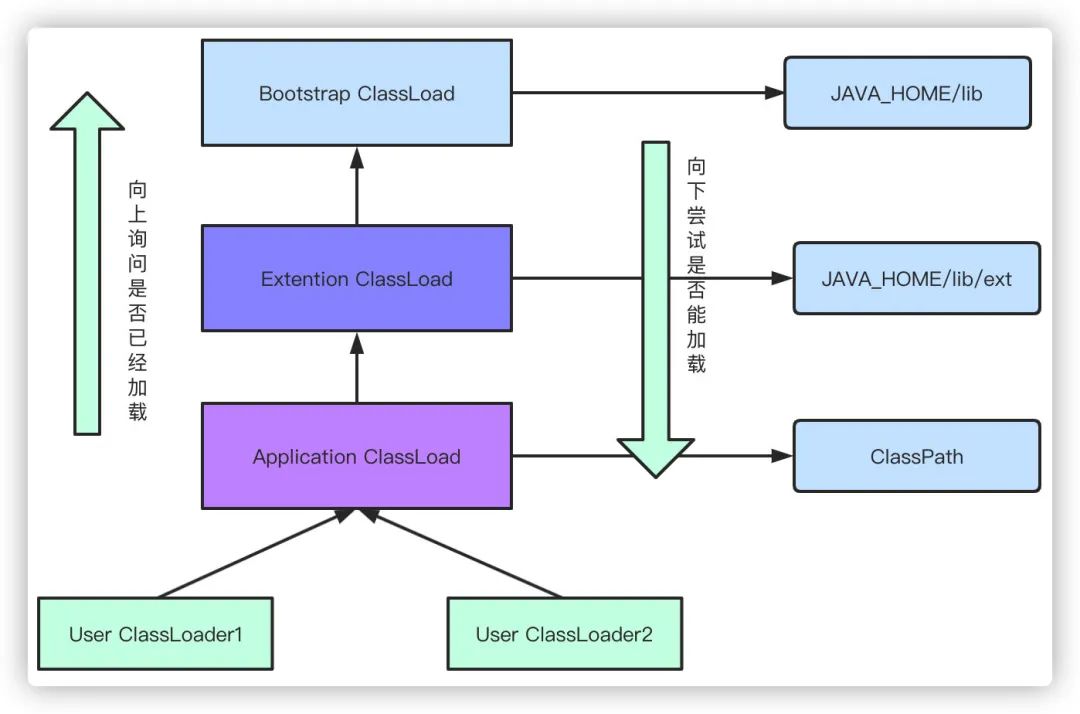
4.知道双亲委派模型吗?
类加载器自顶向下分为:
1.Bootstrap ClassLoader启动类加载器:默认会去加载JAVA_HOME/lib目录下的jar
2.Extention ClassLoader扩展类加载器:默认去加载JAVA_HOME/lib/ext目录下的jar
3.Application ClassLoader应用程序类加载器:比如我们的web应用,会加载web程序中ClassPath下的类
4.User ClassLoader用户自定义类加载器:由用户自己定义
简而言之,就是说一个类加载器收到了类加载的请求,不会自己先加载,而是把它「交给自己的父类去加载,层层迭代」。
「Jvm 中类的唯一性是由类本身和加载这个类的类加载器决定的」
当我们在加载类的时候,首先都会向上询问自己的父加载器是否已经加载,如果没有则依次向上询问,如果没有加载,则从上到下依次尝试是否能加载当前类,直到加载成功。
5.说说有哪些垃圾回收算法?
1,标记-清除,
统一标记出需要回收的对象,标记完成之后统一回收所有被标记的对象,而由于标记的过程需要遍历所有的GC ROOT,清除的过程也要遍历堆中所有的对象,所以标记-清除算法的效率低下,同时也带来了内存碎片的问题。
2,复制算法
为了解决性能的问题,复制算法应运而生,它将内存分为大小相等的两块区域,每次使用其中的一块,当一块内存使用完之后,将还存活的对象拷贝到另外一块内存区域中,然后把当前内存清空,这样性能和内存碎片的问题得以解决。但是同时带来了另外一个问题,可使用的内存空间缩小了一半!
因此,诞生了我们现在的常见的年轻代+老年代的内存结构:Eden+S0+S1组成,因为根据IBM的研究显示,98%的对象都是朝生夕死,所以实际上存活的对象并不是很多,完全不需要用到一半内存浪费,所以默认的比例是8:1:1。
这样,在使用的时候只使用Eden区和S0S1中的一个,每次都把存活的对象拷贝另外一个未使用的Survivor区,同时清空Eden和使用的Survivor,这样下来内存的浪费就只有10%了。
如果最后未使用的Survivor放不下存活的对象,这些对象就进入Old老年代了。
PS:所以有一些初级点的问题会问你为什么要分为Eden区和2个Survior区?有什么作用?就是为了节省内存和解决内存碎片的问题,这些算法都是为了解决问题而产生的,如果理解原因你就不需要死记硬背了
年轻代是用的复制算法进行GC,年轻代分为1个Eden区和2个Survivor区(分别叫from和to)
1,新创建的对象,会被分到Eden区,Eden区满了之后,
2,经历第一次Minor GC之后,如果仍然存活,会被移到From Survivor 区。
3,From Survivor 满了之后,经历Minor GC,如果仍然存活,会被移动到To Survivor 区,对象在Survivor区中每熬过一次Minor GC,年龄就会增加1岁,当它的年龄增加到一定程度时,就会被移动到年老代中。因为年轻代中的对象基本都是朝生夕死的(80%以上),所以在年轻代的垃圾回收算法使用的是复制算法,复制算法的基本思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还活着的对象复制到另外一块上面。复制算法不会产生内存碎片。
3,标记-整理
针对老年代再用复制算法显然不合适,因为进入老年代的对象都存活率比较高了,这时候再频繁的复制对性能影响就比较大,而且也不会再有另外的空间进行兜底。所以针对老年代的特点,通过标记-整理算法,标记出所有的存活对象,让所有存活的对象都向一端移动,然后清理掉边界以外的内存空间。
6.那么什么是 GC ROOT?有哪些 GC ROOT?
上面提到的标记的算法,怎么标记一个对象是否存活?简单的通过引用计数法,给对象设置一个引用计数器,每当有一个地方引用他,就给计数器+1,反之则计数器-1,但是这个简单的算法无法解决循环引用的问题。
Java通过可达性分析算法来达到标记存活对象的目的,定义一系列的GC ROOT为起点,从起点开始向下开始搜索,搜索走过的路径称为引用链,当一个对象到GC ROOT没有任何引用链相连的话,则对象可以判定是可以被回收的。
而可以作为GC ROOT的对象包括:
1.栈中引用的对象
2.静态变量、常量引用的对象
3.本地方法栈native方法引用的对象
4,所有「被 Synchronized 持有的对象」。
7.垃圾回收器了解吗?年轻代和老年代都有哪些垃圾回收器?
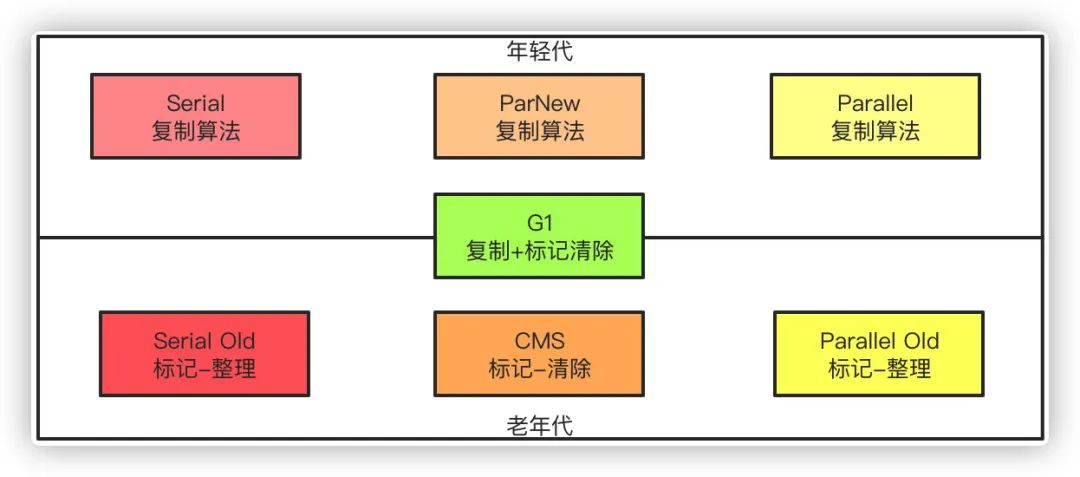
年轻代的垃圾收集器包含有Serial、ParNew、Parallell,
老年代则包括Serial Old老年代版本、CMS、Parallel Old老年代版本和JDK11中的船新的G1收集器。
Serial:单线程版本收集器,进行垃圾回收的时候会STW(Stop The World),也就是进行垃圾回收的时候其他的工作线程都必须暂停
ParNew:Serial的多线程版本,用于和CMS配合使用
Parallel Scavenge:可以并行收集的多线程垃圾收集器
Serial Old:Serial的老年代版本,也是单线程
Parallel Old:Parallel Scavenge的老年代版本
CMS(Concurrent Mark Sweep):CMS收集器是以获取最短停顿时间为目标的收集器,相对于其他的收集器STW的时间更短暂,可以并行收集是他的特点,同时他基于标记-清除算法,整个GC的过程分为4步。
1.初始标记:标记GC ROOT能关联到的对象,需要STW(Stop The World)
2.并发标记:从GCRoots的直接关联对象开始遍历整个对象图的过程,不需要STW
3.重新标记:为了修正并发标记期间,因用户程序继续运作而导致标记产生改变的标记,需要STW
4.并发清除:清理删除掉标记阶段判断的已经死亡的对象,不需要STW
从整个过程来看,并发标记和并发清除的耗时最长,但是不需要停止用户线程,而初始标记和重新标记的耗时较短,但是需要停止用户线程,总体而言,整个过程造成的停顿时间较短,大部分时候是可以和用户线程一起工作的。
G1(Garbage First):G1收集器是JDK9的默认垃圾收集器,而且不再区分年轻代和老年代进行回收。
8.什么是 STW ?
Java 中「「Stop-The-World机制简称 STW」」 ,是在执行垃圾收集算法时,Java 应用程序的其他所有线程都被挂起(除了垃圾收集帮助器之外)。「Java 中一种全局暂停现象,全局停顿」,所有 Java 代码停止,native 代码可以执行,但不能与 JVM 交互。
9.为什么需要 STW?
在 java 应用程序中「引用关系」是不断发生「「变化」」的,那么就会有会有很多种情况来导致「垃圾标识」出错。想想一下如果 Object a 目前是个垃圾,GC 把它标记为垃圾,但是在清除前又有其他对象指向了 Object a,那么此刻 Object a 又不是垃圾了,那么如果没有 STW 就要去无限维护这种关系来去采集正确的信息。再举个例子,到了秋天,道路上洒满了金色的落叶,环卫工人在打扫街道,却永远也无法打扫干净,因为总会有不断的落叶。
10.java 有哪四种引用类型?
-
「1.强引用」
"Object o = new Object()" 就是一种强引用关系,这也是我们在代码中最常用的一种引用关系。无论任何情况下,只要强引用关系还存在,垃圾回收器就不会回收掉被引用的对象。
-
「2.软引用」
当内存空间不足时,就会回收软引用对象。
// 软引用 SoftReference<String> softRef = new SoftReference<String>(str);软引用用来描述那些有用但是没必要的对象。
-
「3.弱引用」
弱引用要比软引用更弱一点,它「只能够存活到下次垃圾回收之前」。也就是说,垃圾回收器开始工作,会回收掉所有只被弱引用关联的对象。
WeakReference<String> weakRef = new WeakReference<String>(str);在 「ThreadLocal」 中就使用了弱引用来防止内存泄漏。
-
「4.虚引用」
虚引用是最弱的一种引用关系,它的唯一作用是用来作为一种通知。如零拷贝(Zero Copy),开辟了堆外内存,虚引用在这里使用,会将这部分信息存储到一个队列中,以便于后续对堆外内存的回收管理。
11.G1 的原理了解吗?
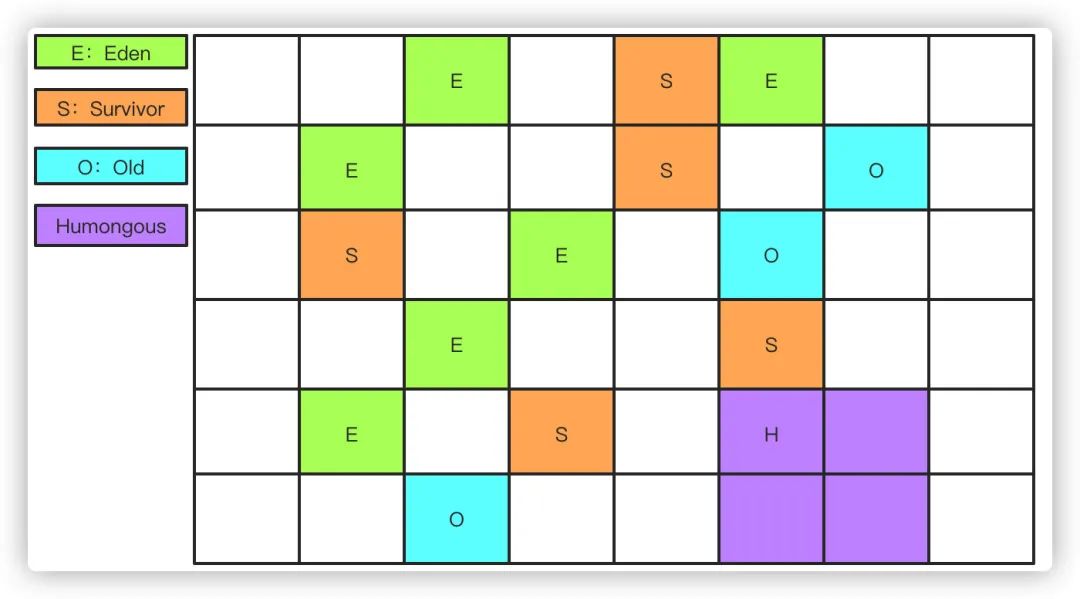
G1作为JDK9之后的服务端默认收集器,且不再区分年轻代和老年代进行垃圾回收,他把内存划分为多个Region,每个Region的大小可以通过-XX:G1HeapRegionSize设置,大小为1~32M,
对于大对象的存储则衍生出Humongous的概念,超过Region大小一半的对象会被认为是大对象,而超过整个Region大小的对象被认为是超级大对象,将会被存储在连续的N个Humongous Region中,G1在进行回收的时候会在后台维护一个优先级列表,每次根据用户设定允许的收集停顿时间优先回收收益最大的Region。
G1的回收过程分为以下四个步骤:
1.初始标记:标记GC ROOT能关联到的对象,需要STW(Stop The World)
2.并发标记:从GCRoots的直接关联对象开始遍历整个对象图的过程,扫描完成后还会重新处理并发标记过程中产生变动的对象
3.最终标记:短暂暂停用户线程,再处理一次,需要STW
4.筛选回收:更新Region的统计数据,对每个Region的回收价值和成本排序,根据用户设置的停顿时间制定回收计划。再把需要回收的Region中存活对象复制到空的Region,同时清理旧的Region。需要STW
总的来说除了并发标记之外,其他几个过程也还是需要短暂的STW,G1的目标是在停顿和延迟可控的情况下尽可能提高吞吐量。
12.什么时候会触发 YGC 和 FGC?对象什么时候会进入老年代?
12.1.YGC和FGC是什么
YGC :对新生代堆进行gc(Yong GC)。频率比较高,因为大部分对象的存活寿命较短,在新生代里被回收。性能耗费较小。
FGC :全堆范围的gc(Full GC)。默认堆空间使用到达80%(可调整)的时候会触发fgc。以我们生产环境为例,一般比较少会触发fgc,有时10天或一周左右会有一次。
12.2.什么时候执行YGC和FGC
1,当一个新的对象来申请内存空间的时候,如果Eden区无法满足内存分配需求,即Edn空间不足,则触发YGC,
2,使用中的Survivor区和Eden区存活对象送到未使用的Survivor区,如果YGC之后还是没有足够空间,则直接进入老年代分配,如果老年代也无法分配空间,总之:old空间不足,perm空间不足,调用方法System.gc() ,ygc时的悲观策略, dump live的内存信息时(jmap –dump:live),都会触发FGC,
3,FGC之后还是放不下则报出OOM异常。
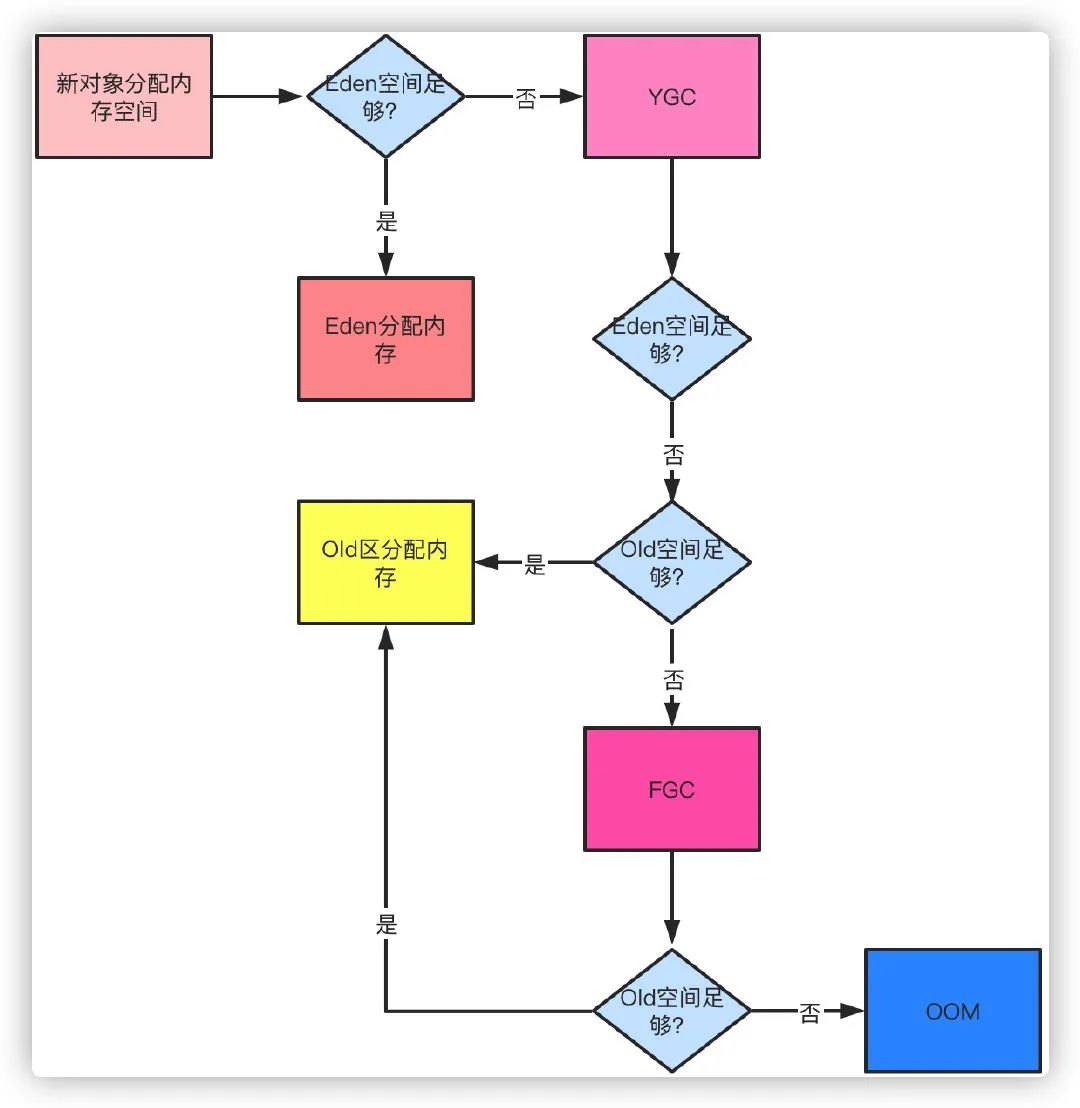
YGC之后,存活的对象将会被复制到未使用的Survivor区,如果S区放不下,则直接晋升至老年代。而对于那些一直在Survivor区来回复制的对象,通过-XX:MaxTenuringThreshold配置交换阈值,默认15次,如果超过次数同样进入老年代。
此外,还有一种动态年龄的判断机制,不需要等到MaxTenuringThreshold就能晋升老年代。如果在Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代。
13.频繁 FullGC 怎么排查?
这种问题最好的办法就是结合有具体的例子举例分析,如果没有就说一般的分析步骤。发生FGC有可能是内存分配不合理,比如Eden区太小,导致对象频繁进入老年代,这时候通过启动参数配置就能看出来,另外有可能就是存在内存泄露,可以通过以下的步骤进行排查:
1.jstat -gcutil或者查看gc.log日志,查看内存回收情况
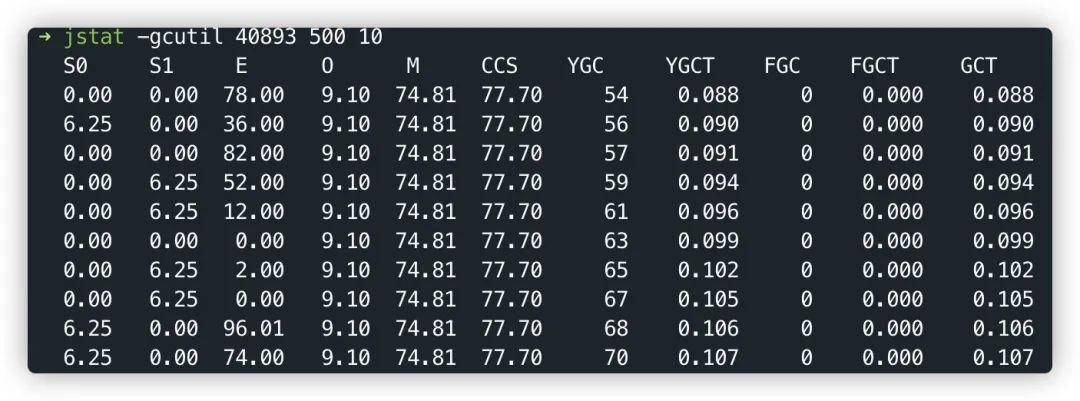
S0 S1 分别代表两个Survivor区占比
E代表Eden区占比,图中可以看到使用78%
O代表老年代,M代表元空间,YGC发生54次,YGCT代表YGC累计耗时,GCT代表GC累计耗时。
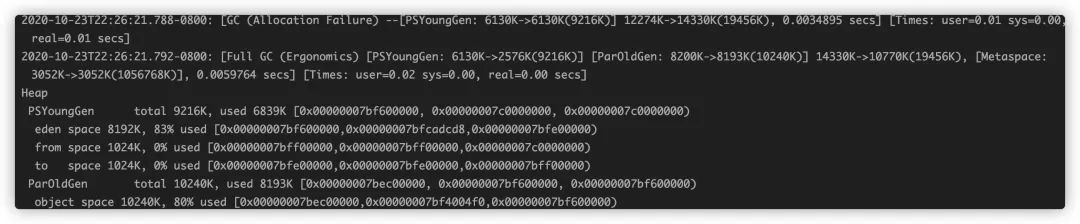
[GC [FGC 开头代表垃圾回收的类型
PSYoungGen: 6130K->6130K(9216K)] 12274K->14330K(19456K), 0.0034895 secs代表YGC前后内存使用情况
Times: user=0.02 sys=0.00, real=0.00 secs,user表示用户态消耗的CPU时间,sys表示内核态消耗的CPU时间,real表示各种墙时钟的等待时间
这两张图只是举例并没有关联关系,比如你从图里面看能到是否进行FGC,FGC的时间花费多长,GC后老年代,年轻代内存是否有减少,得到一些初步的情况来做出判断。
2.dump出内存文件在具体分析,比如通过jmap命令jmap -dump:format=b,file=dumpfile pid,导出之后再通过Eclipse Memory Analyzer等工具进行分析,定位到代码,修复
CPU飙高,同时FGC怎么办?办法比较类似
1.找到当前进程的pid,top -p pid -H 查看资源占用,找到线程
2.printf “%x\n” pid,把线程pid转为16进制,比如0x32d
3.jstack pid|grep -A 10 0x32d查看线程的堆栈日志,还找不到问题继续
4.dump出内存文件用MAT等工具进行分析,定位到代码,修复
14.JVM 调优有什么经验吗?
要明白一点,所有的调优的目的都是为了用更小的硬件成本达到更高的吞吐,JVM的调优也是一样,通过对垃圾收集器和内存分配的调优达到性能的最佳。
简单的参数含义
首先,需要知道几个主要的参数含义。
1.-Xms设置初始堆的大小,-Xmx设置最大堆的大小
2.-XX:NewSize年轻代大小,-XX:MaxNewSize年轻代最大值,-Xmn则是相当于同时配置-XX:NewSize和-XX:MaxNewSize为一样的值
3.-XX:NewRatio设置年轻代和年老代的比值,默认值为2,如果为3,表示年轻代与老年代比值为1:3,
4.-XX:SurvivorRatio年轻代和两个Survivor的比值,默认8,代表比值为8:1:1
5.-XX:PretenureSizeThreshold 当创建的对象超过指定大小时,直接把对象分配在老年代。
6.-XX:MaxTenuringThreshold设定对象在Survivor复制的最大年龄阈值,超过阈值转移到老年代
7.-XX:MaxDirectMemorySize当Direct ByteBuffer分配的堆外内存到达指定大小后,即触发Full GC
调优
1.为了打印日志方便排查问题最好开启GC日志,开启GC日志对性能影响微乎其微,但是能帮助我们快速排查定位问题。-XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:gc.log
2.一般设置-Xms=-Xmx,这样可以获得固定大小的堆内存,减少GC的次数和耗时,可以使得堆相对稳定
3.-XX:+HeapDumpOnOutOfMemoryError让JVM在发生内存溢出的时候自动生成内存快照,方便排查问题
4.-Xmn设置新生代的大小,太小会增加YGC,太大会减小老年代大小,一般设置为整个堆的1/4到1/3
5.设置-XX:+DisableExplicitGC禁止系统System.gc(),防止手动误触发FGC造成问题
15.如何排查 OOM 的问题?
1.增加两个参数 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof,当 OOM 发生时自动 dump 堆内存信息到指定目录;
2.同时 jstat 查看监控 JVM 的内存和 GC 情况,先观察问题大概出在什么区域;
3.使用工具载入到 dump 文件,分析大对象的占用情况。
16.什么情况下会发生栈内存溢出?
Java 栈内存溢出可能抛出两种异常,两种异常虽然都发生在栈内存,但是两者导致内存溢出的根本原因是不一样的:
1.「如果线程请求分配的栈容量超过 Java 虚拟机栈允许的最大容量的时候」,Java 虚拟机将抛出一个 StackOverFlowError 异常。
2.如果 Java 虚拟机栈可以动态拓展,并且扩展的动作已经尝试过,但是目前「无法申请到足够的内存去完成拓展,或者在建立新线程的时候没有足够的内存去创建对应的虚拟机栈」,那 Java 虚拟机将会抛出一个 OutOfMemoryError 异常。
17,jvm其他区域发生内存溢出的原因以及解决办法
1. Java 堆空间
发生频率:5颗星
造成原因
无法在 Java 堆中分配对象
吞吐量增加
应用程序无意中保存了对象引用,对象无法被 GC 回收
应用程序过度使用 finalizer。finalizer 对象不能被 GC 立刻回收。finalizer 由结束队列服务的守护线程调用,有时 finalizer 线程的处理能力无法跟上结束队列的增长
解决方案
使用 -Xmx 增加堆大小
修复应用程序中的内存泄漏
2. GC 开销超过限制
发生频率:5颗星
造成原因
Java 进程98%的时间在进行垃圾回收,恢复了不到2%的堆空间,最后连续5个(编译时常量)垃圾回收一直如此。
解决方案
使用 -Xmx 增加堆大小
使用 -XX:-UseGCOverheadLimit 取消 GC 开销限制
修复应用程序中的内存泄漏
3. 请求的数组大小超过虚拟机限制
发生频率:2颗星
造成原因
应用程序试图分配一个超过堆大小的数组
解决方案
使用 -Xmx 增加堆大小
修复应用程序中分配巨大数组的 bug
4. Perm gen 空间
发生频率:3颗星
造成原因
Perm gen 空间包含:
类的名字、字段、方法
与类相关的对象数组和类型数组
JIT 编译器优化
当 Perm gen 空间用尽时,将抛出异常。
解决方案
使用 -XX: MaxPermSize 增加 Permgen 大小
不重启应用部署应用程序可能会导致此问题。重启 JVM 解决
5. Metaspace
发生频率:3颗星
造成原因
从 Java 8 开始 Perm gen 改成了 Metaspace,在本机内存中分配 class 元数据(称为 metaspace)。如果 metaspace 耗尽,则抛出异常
解决方案
通过命令行设置 -XX: MaxMetaSpaceSize 增加 metaspace 大小
取消 -XX: maxmetsspacedize
减小 Java 堆大小,为 MetaSpace 提供更多的可用空间
为服务器分配更多的内存
可能是应用程序 bug,修复 bug
6. 无法新建本机线程
发生频率:5颗星
造成原因
内存不足,无法创建新线程。由于线程在本机内存中创建,报告这个错误表明本机内存空间不足
解决方案
为机器分配更多的内存
减少 Java 堆空间
修复应用程序中的线程泄漏。
增加操作系统级别的限制
ulimit -a
用户进程数增大 (-u) 1800
使用 -Xss 减小线程堆栈大小
18,内存溢出和内存泄漏分别是什么?产生的原因是什么?
- 内存溢出(Out Of Memory) :系统已经不能再分配出你所需要的空间,比如你需要100M的空间,系统只剩90M了,这就叫内存溢出。即申请内存时,JVM没有足够的内存空间。通俗说法就是去蹲坑发现坑位满了。
- 内存泄露 (Memory Leak):强引用所指向的对象不会被回收,可能导致内存泄漏,虚拟机宁愿抛出OOM也不会去回收他指向的对象。即申请了内存,但是没有释放,导致内存空间浪费。通俗说法就是有人占着茅坑不拉屎。
18.1、内存溢出
在JVM的几个内存区域中,除了程序计数器外,其他几个运行时区域都有发生内存溢出(OOM)异常的可能。
18.1.1Java堆溢出
Java堆内存的OutOfMemoryError异常是实际应用中最常见的内存溢出异常情况。出现Java堆内存溢出时,异常堆栈信息“java.lang.OutOfMemoryError”会跟随进一步提示“Java heap space”。 Java堆文件快照文件dump到了java_pid18728.hprof文件。
要解决这个内存区域的异常,常规的处理方法是首先通过内存映像分析工具(如JProfiler、Eclipse Memory Analyzer等)对Dump出来的堆转储快照进行分析。
18.1.2、虚拟机栈和本地方法栈溢出
- 如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出
StackOverflowError异常。(栈容量过小,栈帧太大)- 如果虚拟机的栈内存允许动态扩展,当扩展栈容量无法申请到足够的内存时,将抛出
OutOfMemoryError异常。(创建线程导致内存溢出异常 )18.1.3、方法区和运行时常量池溢出
java.lang.OutOfMemoryError: PermGen space18.1.4、本机直接内存溢出
直接内存(Direct Memory)的容量大小可通过-XX:MaxDirectMemorySize参数来指定,如果不去指定,则默认与Java堆最大值(由-Xmx指定)一致。
由直接内存导致的内存溢出,一个明显的特征是在Heap Dump文件中不会看见明显的异常情况。
18.2、内存泄漏
内存回收,简单说就是应该被垃圾回收的对象没有被垃圾回收。
原因如下:
1,静态集合类引起内存泄漏
静态集合的生命周期和 JVM 一致,所以静态集合引用的对象不能被释放2,数据连接、IO、Socket等连接
创建的连接不再使用时,需要调用 close 方法关闭连接,只有连接被关闭后,GC 才会回收对应的对象(Connection,Statement,ResultSet,Session)。忘记关闭这些资源会导致持续占有内存,无法被 GC 回收3,单例模式
单例对象在初始化后会以静态变量的方式在 JVM 的整个生命周期中存在。如果单例对象持有外部的引用,那么这个外部对象将不能被 GC 回收,导致内存泄漏
4,变量不合理的作用域:
一个变量的定义作用域大于其使用范围,很可能存在内存泄漏;或不再使用对象没有及时将对象设置为 null,很可能导致内存泄漏的发生。
5,引用了外部类的非静态内部类
非静态内部类(或匿名类)的初始化总是需要依赖外部类的实例。默认情况下,每个非静态内部类都包含对其包含类的隐式引用,若在程序中使用这个内部类对象,那么即使在包含类对象超出范围之后,也不会被回收(内部类对象隐式地持有外部类对象的引用,使其成不能被回收)。6,Hash 值发生改变
对象Hash值改变,使用HashMap、HashSet等容器中时候,由于对象修改之后的Hah值和存储进容器时的Hash值不同,会导致无法从容器中单独删除当前对象,造成内存泄露。7,ThreadLocal 造成的内存泄漏
ThreadLocal 可以实现变量的线程隔离,但若使用不当,就可能会引入内存泄漏问题
______________________________________________________
学习链接:YGC和FGC是什么 - 简书
学习链接:面试题系列:JVM 夺命连环10问
学习链接:JVM 夺命连环 20 问?拿捏了~
学习链接:内存泄漏和内存溢出有啥区别? - 知乎
相关文章
- 高级面试题–SpringBoot启动流程解析「建议收藏」
- sql优化的几种方法面试题_mysql存储过程面试题
- ajax面试题及答案_javase面试题
- java面试题 --- Spring②
- Hbase面试题(持续更新)「建议收藏」
- Hbase面试题(面经)整理
- PHP经典算法面试题列表
- Qt面试题整理
- hashmap的实现原理面试_jvm面试题总结及答案
- 常用lunix命令面试题_五个常见的linux命令
- 我的react面试题整理2(附答案)
- 字节前端高频手写面试题(持续更新中)1
- Linux基础知识:面试准备(linux基础面试题)
- Linux下的JVM监控工具使用指南(jvm监控工具linux)
- Efficiently Monitor JVM Memory on Linux with These Simple Tips(linux监控jvm内存)
- 如何在Linux上查看JVM运行信息(Linux查看jvm)
- mssql 面试指南:完全掌握全部知识(mssql 面试题)
- Linux JVM GC管理追求极致性能(linux jvm gc)
- 如何在Linux下修改JVM参数配置(linux修改jvm参数)
- 目Oracle应聘者的面试考试之路(oracle 公司面试题)
- Oracle的JVM实现高性能成就突破(jvm属于oracle)
- 方案面对 Redis 面试题,找出最佳到岸方案(redis面试题及到岸)
- Redis集群扩容面试题怎么回答(redis集群扩容面试题)
- Redis运维面试必备的知识与技能(redis 运维面试题)
- Oracle JVM安装指南(oracle jvm安装)
- 在Oracle JVM环境下进行下载的指南(oracle jvm下载)