
【分布式】什么是分布式,分布式和集群的区别又是什么?答案在正文。
1. 什么是分布式 ?
分布式系统一定是由多个节点组成的系统。
其中,节点指的是计算机服务器,而且这些节点一般不是孤立的,而是互通的。
这些连通的节点上部署了我们的节点,并且相互的操作会有协同。
分布式系统对于用户而言,他们面对的就是一个服务器,提供用户需要的服务而已,
而实际上这些服务是通过背后的众多服务器组成的一个分布式系统,因此分布式系统看起来像是一个超级计算机一样。
2. 分布式与集群的区别 ?
- 集群
集群是指在几个服务器上部署相同的应用程序来分担客户端的请求。
它是同一个系统部署在不同的服务器上,比如一个登陆系统部署在不同的服务器上。
好比 多个人一起做同样的事。
集群主要的使用场景是为了分担请求的压力。
但是,当压力进一步增大的时候,可能在需要存储的部分,比如mysql无法面对大量的“写压力”。
因为在mysql做成集群之后,主要的写压力还是在master的机器上,其他slave机器无法分担写压力,这时,就引出了“分布式”。
- 分布式
分布式是指多个系统协同合作完成一个特定任务的系统。
它是不同的系统部署在不同的服务器上,服务器之间相互调用。
好比 多个人一起做不同的事。
分布式是解决中心化管理的问题,把所有的任务叠加到一个节点处理,太慢了。
所以把一个大问题拆分为多个小问题,并分别解决,最终协同合作。
分布式的主要工作是分解任务,把职能拆解。
分布式的主要应用场景是单台机器已经无法满足这种性能的要求,必须要融合多个节点,并且节点之间的相关部分是有交互的。
相当于在写mysql的时候,每个节点存储部分数据(分库分表),这就是分布式存储的由来。
存储一些非结构化数据:静态文件、图片、pdf、小视频 … 这些也是分布式文件系统的由来。
- 用生活中的例子,来说明集群和分布式及其区别:
小饭店原来只有一个厨师,切菜洗菜备料炒菜全干。
后来客人多了,厨房一个厨师忙不过来,又请了个厨师,两个厨师炒一样的菜,这两个厨师的关系是集群。
为了让厨师专心炒菜,把菜做到极致,又请了个配菜师负责切菜,备菜,备料,厨师和配菜师的关系是分布式,
一个配菜师也忙不过来了,又请了个配菜师,两个配菜师关系是集群。 - 最后,再深入理解一下集群和分布式及其区别:
分布式:把一个大业务拆分成多个子业务,每个子业务都是一套独立的系统,子业务之间相互协作最终完成整体的大业务。
集群:把处理同一个业务的系统部署多个节点 。
把一套系统拆分成不同的子系统部署在不同服务器上,这叫分布式。
把多个相同的系统部署在不同的服务器上,这叫集群。部署在不同服务器上的相同系统必然要做“负载均衡”。
集群主要是简单加机器解决问题,对于问题本身不做任何分解。
分布式处理里必然涉及任务分解与答案归并。分布式中的某个子任务节点,可以是一个集群,该集群中的任一节点都作为一个完整的任务出现。
集群和分布式都是由多个节点组成,但集群中各节点间基本不需要通信协调,而分布式中各个节点的通信协调是必不可少的。
3.用一个请求串起来
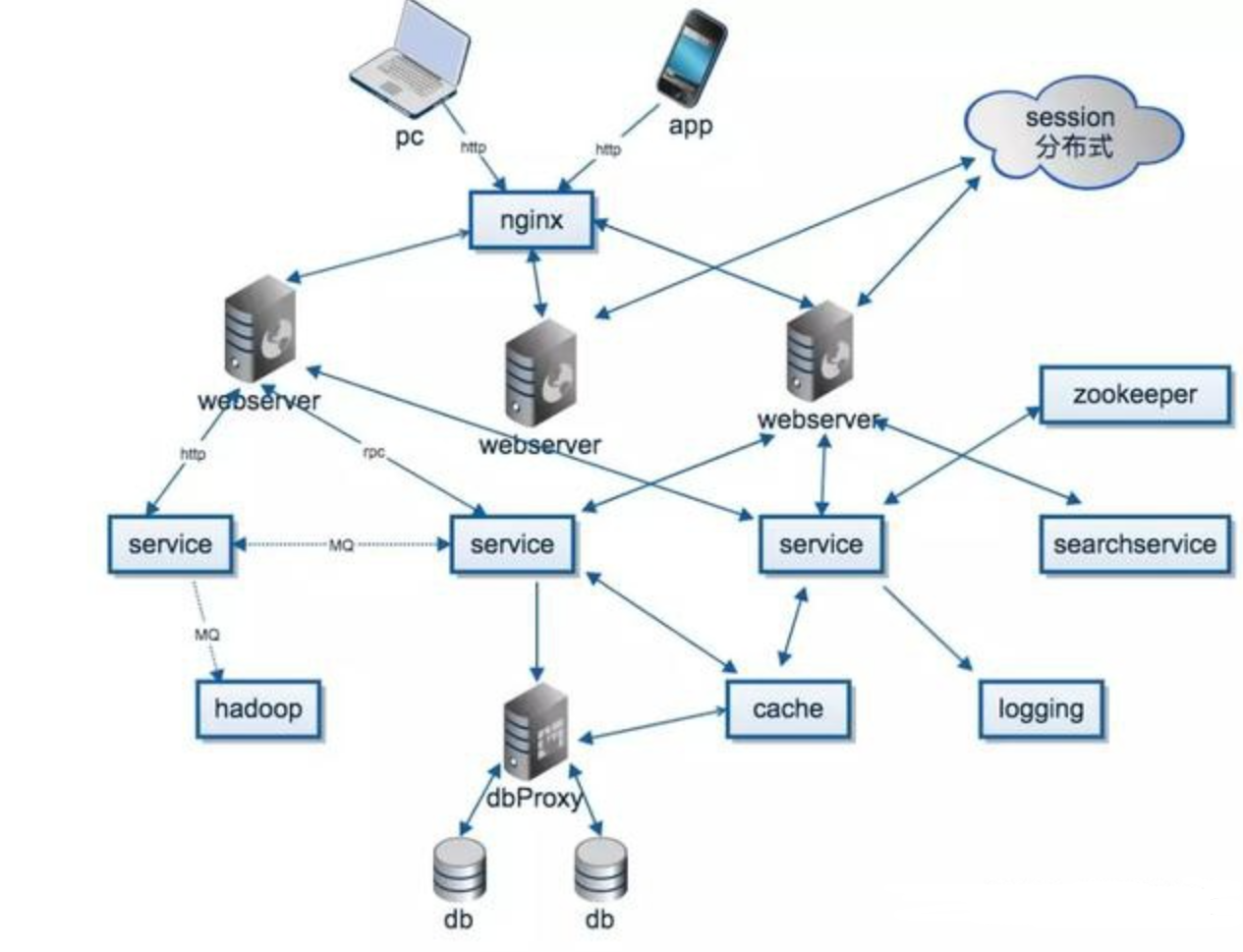
用户使用Web、APP、SDK,通过HTTP、TCP连接到系统。在分布式系统中,为了高并发、高可用,一般都是多个节点提供相同的服务。那么,第一个问题就是具体选择哪个节点来提供服务,这个就是负载均衡(load balance)。
负载均衡的思想很简单,但使用非常广泛,在分布式系统、大型网站的方方面面都有使用,或者说,只要涉及到多个节点提供同质的服务,就需要负载均衡。
通过负载均衡找到一个节点,接下来就是真正处理用户的请求,请求有可能简单,也有可能很复杂。
简单的请求,比如读取数据,那么很可能是有缓存的,即分布式缓存,如果缓存没有命中,那么需要去数据库拉取数据。对于复杂的请求,可能会调用到系统中其他的服务。
承上,假设服务A需要调用服务B的服务,首先两个节点需要通信,网络通信都是建立在TCP/IP协议的基础上。但是,每个应用都手写socket是一件冗杂、低效的事情,因此需要应用层的封装,因此有了HTTP、FTP等各种应用层协议。
当系统愈加复杂,提供大量的http接口也是一件困难的事情。因此,有了更进一步的抽象,那就是RPC(remote produce call),是的远程调用就跟本地过程调用一样方便,屏蔽了网络通信等诸多细节,增加新的接口也更加方便。
一个请求可能包含诸多操作,即在服务A上做一些操作,然后在服务B上做另一些操作。比如简化版的网络购物,在订单服务上发货,在账户服务上扣款。这两个操作需要保证原子性,要么都成功,要么都不操作。这就涉及到分布式事务的问题,分布式事务是从应用层面保证一致性:某种守恒关系。
上面说道一个请求包含多个操作,其实就是涉及到多个服务,分布式系统中有大量的服务,每个服务又是多个节点组成。那么一个服务怎么找到另一个服务(的某个节点呢)?通信是需要地址的,怎么获取这个地址,最简单的办法就是配置文件写死,或者写入到数据库。
但这些方法在节点数据巨大、节点动态增删的时候都不大方便,这个时候就需要服务注册与发现:提供服务的节点向一个协调中心注册自己的地址,使用服务的节点去协调中心拉取地址。
从上可以看见,协调中心提供了中心化的服务:以一组节点提供类似单点的服务,使用非常广泛,比如命令服务、分布式锁。协调中心最出名的就是chubby,zookeeper。
回到用户请求这个点,请求操作会产生一些数据、日志,通常为信息,其他一些系统可能会对这些消息感兴趣。比如个性化推荐、监控等,这里就抽象出了两个概念,消息的生产者与消费者。那么生产者怎么将消息发送给消费者呢,RPC并不是一个很好的选择,因为RPC肯定得指定消息发给谁。
但实际的情况是生产者并不清楚、也不关心谁会消费这个消息,这个时候消息队列就出马了。简单来说,生产者只用往消息队列里面发就行了,队列会将消息按主题(topic)分发给关注这个主题的消费者。消息队列起到了异步处理、应用解耦的作用。
上面提到,用户操作会产生一些数据,这些数据忠实记录了用户的操作习惯、喜好,是各行各业最宝贵的财富。比如各种推荐、广告投放、自动识别。这就催生了分布式计算平台,比如Hadoop,Storm等,用来处理这些海量的数据。
最后,用户的操作完成之后,用户的数据需要持久化,但数据量很大,大到按个节点无法存储。那么这个时候就需要分布式存储:将数据进行划分放在不同的节点上,同时,为了防止数据的丢失,每一份数据会保存多分。
传统的关系型数据库是单点存储,为了在应用层透明的情况下分库分表,会引用额外的代理层。而对于NoSql,一般天然支持分布式。
4.一个简化的架构图
下面用一个不大精确的架构图,尽量还原分布式系统的组成部分(不过只能体现出技术,不好体现出理论)
5.分布式环境的特点
- 分布性:服务部署空间具有多样性
- 并发性:程序运行过程中,并发性操作是很常见的。比如同一个分布式系统中的多个节点,同时访问一个共享资源。数据库、分布式存储
- 无序性:进程之间的消息通信,会出现顺序不一致问题
6.分布式环境下面临的问题
- 网络通信:网络本身的不可靠性,因此会涉及到一些网络通信问题
- 网络分区(脑裂):当网络发生异常导致分布式系统中部分节点之间的网络延时不断增大,最终导致组成分布式架构的所有节点,只有部分节点能够正常通信
- 三态:在分布式架构里面多了个状态:超时,所以有三态: 成功、失败、超时
- 分布式事务:ACID(原子性、一致性、隔离性、持久性)
- 中心化和去中心化:冷备或者热备
7.总结
以上概述对分布式的理解,在分布式架构里面,很多的架构思想采用的是:当集群发生故障的时候,集群中的人群会自动“选举”出一个新的领导。
最典型的是: zookeeper / etcd
相关文章
- hadoop+spark+zookeeper+hive的大数据分布式集群搭建
- 2.ElasticStack分布式数据采集搜索引擎集群搭建配置
- 带你深入了解 MongoDB 分布式集群
- Redis集群的搭建图文教程
- 分布式与集群的概念区别详解程序员
- Akka(11): 分布式运算:集群-均衡负载详解编程语言
- MySQL集群:发挥分布式优势。(mysql分布式集群)
- clusterRedis集群:推动云计算的高性能分布式存储解决方案(redis-)
- MySQL集群与分布式技术:哪一种更适用?(mysql集群还是分布式)
- 分布式Docker部署Redis分布式集群环境(dockerredis)
- “Redis 集群版:高效可靠的分布式数据库解决方案”(redis集群版)
- 使用YML配置Redis节点实现分布式集群(yml redis 节点)
- 搭建单机Redis集群,掌握分布式存储技术(单机下redis集群)
- 效优化分布式Redis集群高效优化连接数(redis集群连接数高)
- Redis集群虚拟地址实现高可用性(redis集群虚地址)
- Redis集群分布式实现的优势(redis集群概述)
- 分布式缓存基于Redis集群的跨域分布式缓存技术研究(redis集群是跨域)
- 批量快速导入Redis集群(redis集群批量导入)
- 分布式Redis集群构建跨多个DBID的灵活存储体系(redis集群多dbid)
- 红色的分布式与集群Redis实现多机分布式存储(redis集群和分布式)
- Redis集群实现集群分布式存储(redis集群名单)
- 性能深入浅出Redis集群写数据性能(redis集群写数据)
- Redis集群实现高效的分布式锁机制(redis集群做分布式锁)
- Redis集群间信息互通的关键指令(redis集群互通命令)
- Redis锁实现分布式集群互斥(redis锁支持集群)
- 红帽子集群双主实例保障安全(redis集群双主实例)