
站在操作系统层面看JVM
站在操作系统层面看JVM
编译型语言内存使用图
在Java出现之前,像C/C++这样的编译型语言写出来的代码经过编译后,得到的是可直接在某平台(Windows或Linux)上执行的机器码,即machine code,machine code其实就是native code,它直接和操作系统交互。
对于内存,主要分三部分:
1)存储可执行代码(冯·诺依曼的存储程序的思想),即编译后的machine code;
2)用来保存代码执行时用到的局部变量,即stack;
3)代码执行时,动态找操作系统申请(最终要归还给操作系统)的heap;
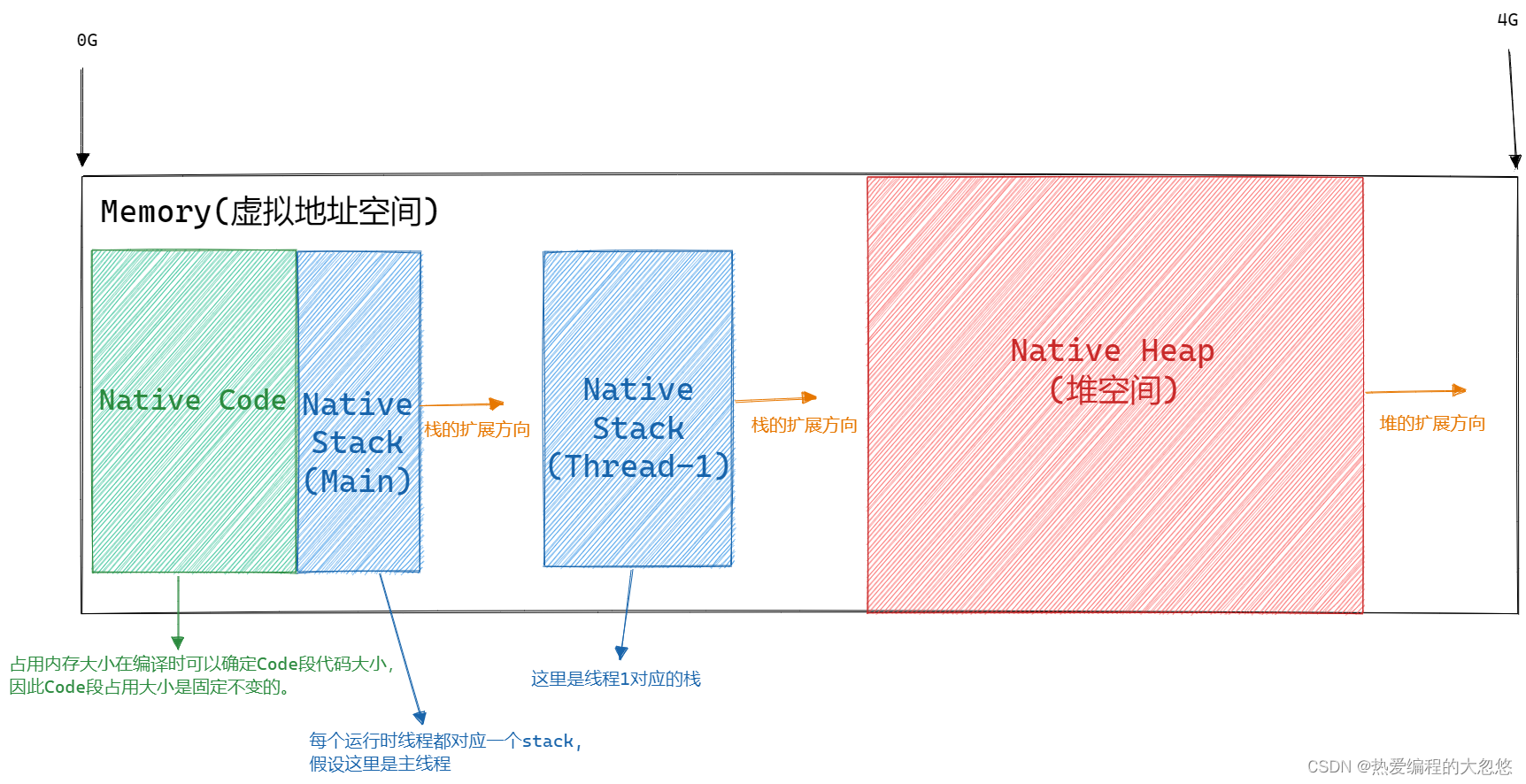
Native Code中存放的是机器指令,因为CPU是通过ip寄存器去Natvie Code段中取指执行的。
这里简化了实际程序的虚拟地址空间使用状态,实际虚拟地址空间中还会留出固定一部分映射到内核空间,为什么这样做,操作系统导论一书给出了答案:

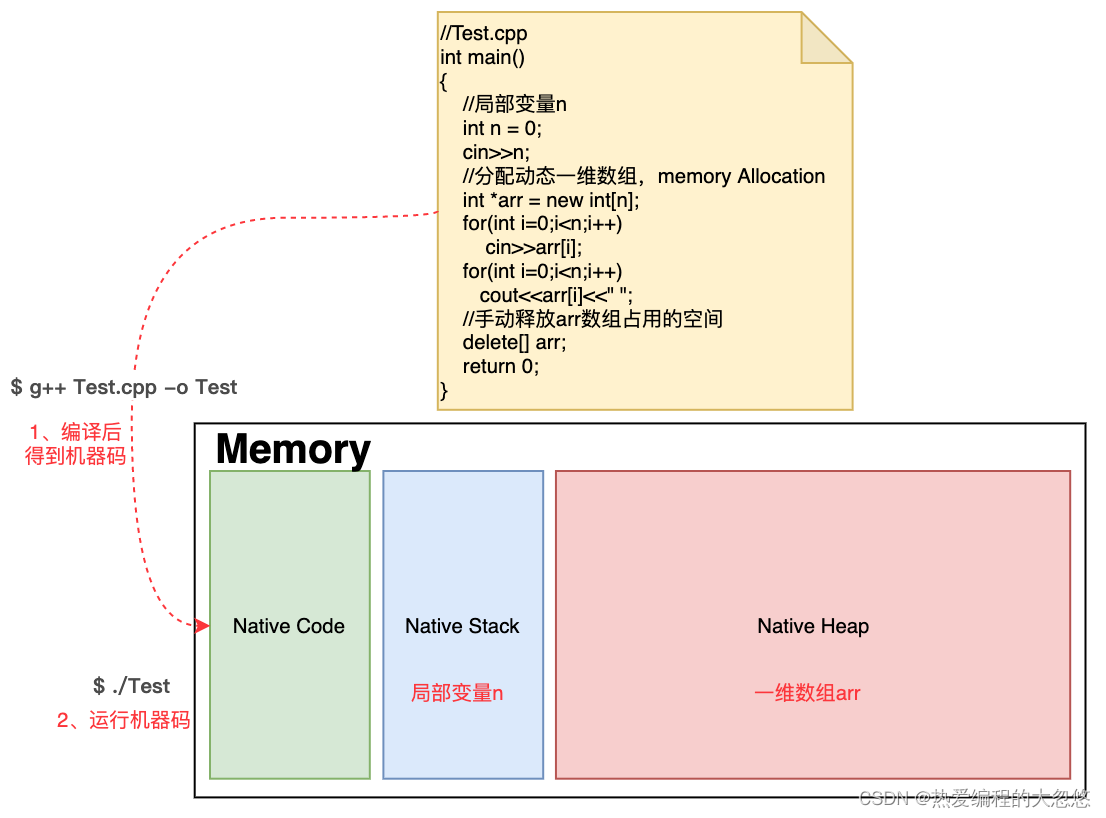
编译型语言写出现的程序,对于Heap的分配和归还都是由程序代码手工维护的。如下图所示,写一段C++代码,GCC编译后就成为了可以在某具体平台上运行的机器码。Native的代码和内存管理主要带来两个问题:
- 一是编译后的代码无法跨平台,毕竟是native的,只能支持被编译平台的操作系统API和指令集。
- 二是堆空间无法自动GC,因为内存管理是手工和操作系统交互,申请与释放的内存的操作交给程序员来做,操作系统并不支持GC。
JAVA呢?
Java是一种解释型语言,解释型语言是相对于编译型语言存在的,它的源代码不是直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行。Java为了解决以上两个问题,它提出了虚拟机的思想,在原来的"Native Heap"里大作文章。
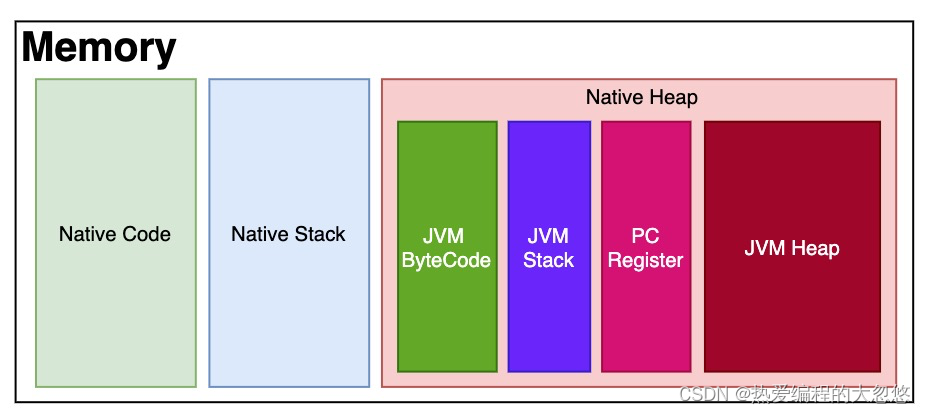
JVM的ByteCode(字节码)在任何平台都是一样的。所以到了某个具体的平台,被特定平台的JVM Runtime解释成本平台的machine code,得到可执行代码,存储到Native Code区,machine code运行起来之后就会用到Native Stack和Native Heap,这种把源代码先翻译成中间代码(即ByteCode)再由解释器解释成机器码供运行的模式,就实现了“Write Once,Run Anywhere”。这就解决了代码无法跨平台的问题。
运行中的JAVA程序本质一个JVM进程,JVM程序负责解释字节码为本平台的机器指令,然后交给CPU执行,所以上面的图可以精细为下图所示:
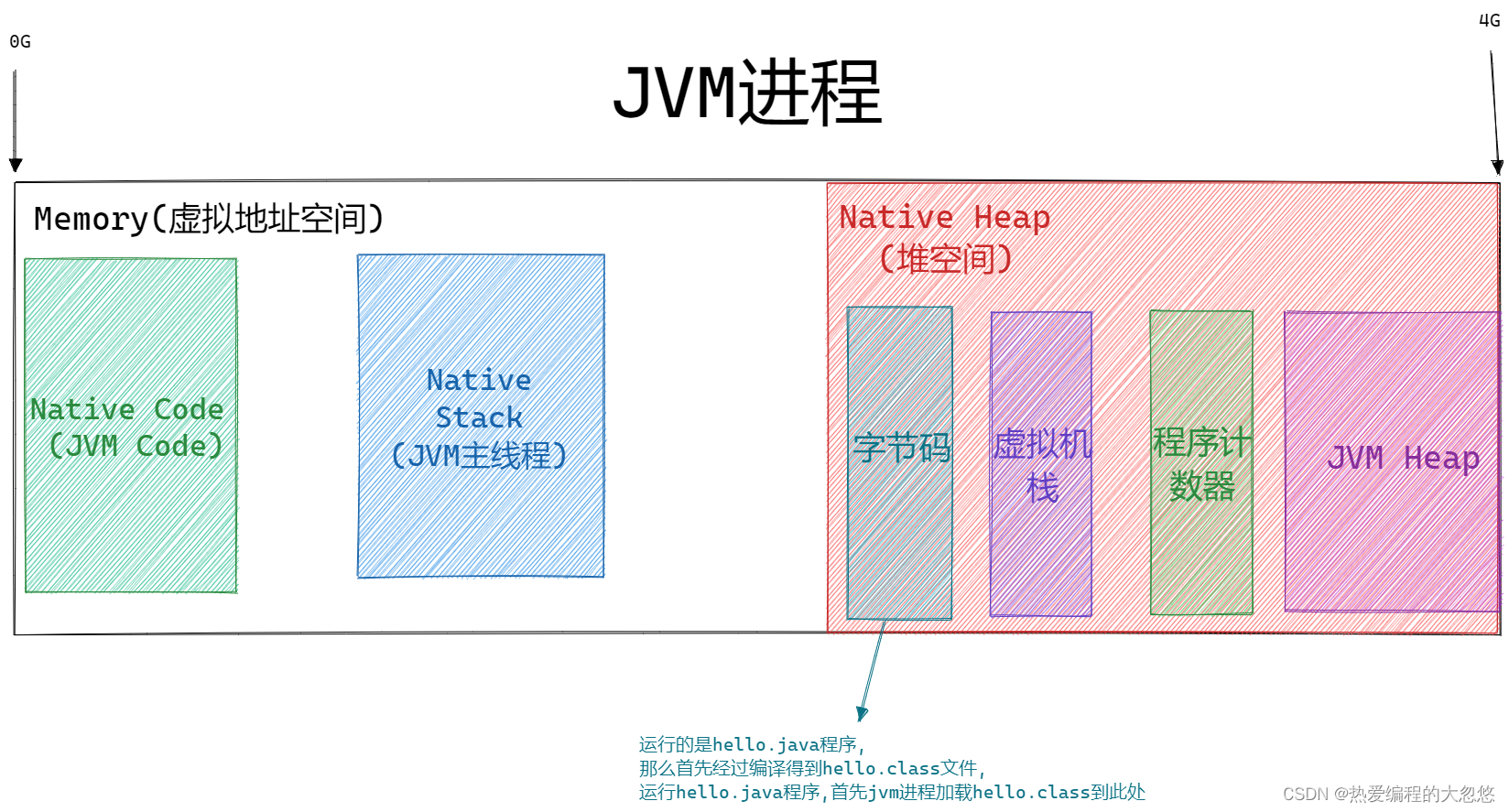
这里实际不只有一个JVM主线程在运行,还有后台垃圾清理线程,其他线程等…
JVM的ByteCode在任何平台都是一样的。所以到了某个具体的平台,被特定平台的JVM Runtime解释成本平台的machine code,得到可执行代码,存储到Native Code区,machine code运行起来之后就会用到Native Stack和Native Heap,这种把源代码先翻译成中间代码(即ByteCode)再由解释器解释成机器码供运行的模式,就实现了“Write Once,Run Anywhere”。这就解决了代码无法跨平台的问题。
如何将Natvie Heap中字节码区域中的字节码解释为本平台机器码然后执行,这个在Jvm Code中已经写好了,具体如何搞的,就是关于解释器那堆东西,不是本文重点。
因为Native Heap中相当一部分内存是供Java应用程序存储对象实例的,完全由JVM管理,就可以对JVM管理的Heap里的数据的引用关系做记录,然后用GC来自动释放内存,这就解决了上面提到的堆空间无法自动GC的问题。
Native Code区域存放JVM程序本身代码,Native Stack是操作系统分配的,不是JVM程序自身可以决定的,堆空间分配也是如此,可以把JVM程序本身看做是一个解释型程序。
堆空间内存如何使用这就是JVM程序可以决定了,JVM程序利用可以掌控的堆空间模拟了一个CPU执行环境,jvm程序提供的解释器和执行引擎等组件充当CPU,堆空间中存放的字节码看做是内存上的机器指令,程序计数器充当ip指针,还有程序执行需要的栈和堆等。
所以一个Java进程启动时,JVM向操作系统要的内存(-Xms与-Xmx),和程序向JVM要的内存是两件不同的事情了。
程序实际是运行在一个由JVM程序模拟的沙盒环境中。
JVM Heap的内部结构与用什么GC算法有关,比如对于传统分代就是由Eden(包括S0与S1)、Tenured和PermGen组成。
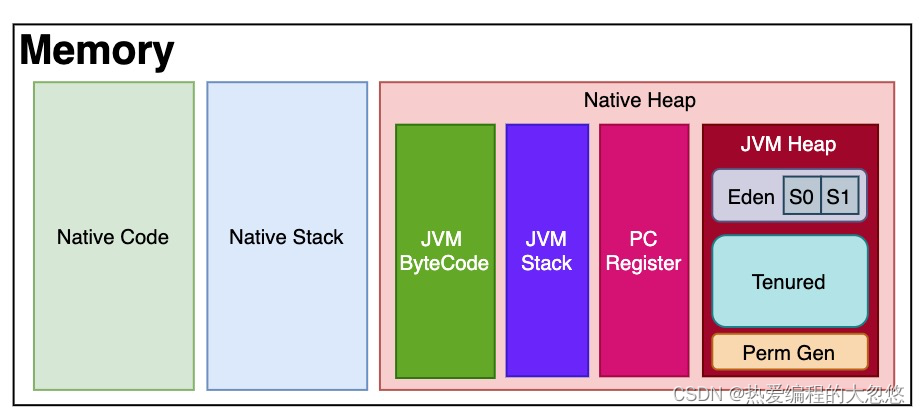
被JVM管理的内存可以总体划分为两部分:Heap Memory和Native Memory。前者我们比较熟悉,其实就是被分成新生代老年代等的JVM heap,是供Java应用程序使用的;
后者也称为C-Heap,是供JVM自身进程使用的。Native Memory没有相应的参数来控制大小,其大小依赖于操作系统进程的最大值(对于32位系统就是3~4G,各种系统的实现并不一样)。

Native Memory里存储了什么呢,主要是
- JNI调用,也就是Native Stack;
- JIT(即使编译器)编译时使用Native Memory,并且JIT的输入(Java字节码)和输出(可执行代码)也都是保存在Native Memory;
- NIO direct buffer。对于IBM JVM和Hotspot,都可以通过-XX:MaxDirectMemorySize来设置nio直接缓冲区的最大值。默认是64M。超过这个时,会按照32M自动增大。
- 用于保存类加载器和类信息的MetaSpace,在Native Memory中的。
本地方法栈就是Native Stack,与Java虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。Navtive方法是Java通过JNI直接调用本地C/C++库,可以认为是Native方法相当于C/C++暴露给Java的一个接口,Java通过调用这个接口从而调用到C/C++方法。
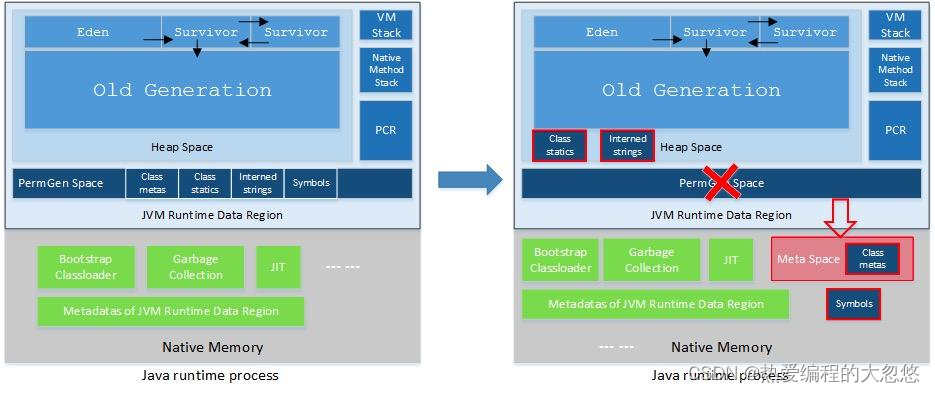
JVM也是在不断发展的,永久代(PermGen区)是对JVM规范中方法区的实现,JDK 7的永久代就在JVM Heap中,与新生代老年代一起构成了JVM Heap。在HotSpot JVM中,永久代(PermGen区)用于存放类和方法的元数据以及常量池,比如Class和Method。
每当一个类初次被加载的时候,它的元数据都会放到永久代(PermGen区)中。永久代(PermGen区)是有大小限制的,因此如果加载的类太多,很有可能导致永久代内存溢出,即java.lang.OutOfMemoryError: PermGen,由于PermGen内存经常会溢出,因此JVM的开发者希望这一块内存可以更灵活地被管理,不要再经常出现这样的OOM。于是JDK 8开始把类的元数据放到本地堆内存(native heap)中,这一块区域就叫Metaspace,中文名叫元空间。之前永久代的类的元数据存储在新的元空间,原永久代的静态变量以及运行时常量池则转移到了JVM Heap中。
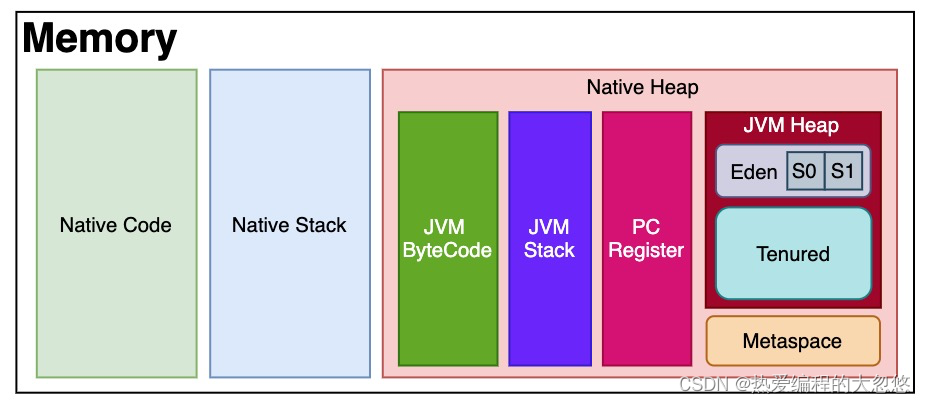
上图精细一下:
Metaspace空间的分配具有和JVM Heap相同的地址空间,使用本地内存有什么好处呢?最直接的表现就是OOM问题将不复存在,本地内存剩余多少理论上Metaspace就可以有多大(容量取决于是32位或是64位操作系统的可用虚拟内存大小),这解决了空间不足的问题。
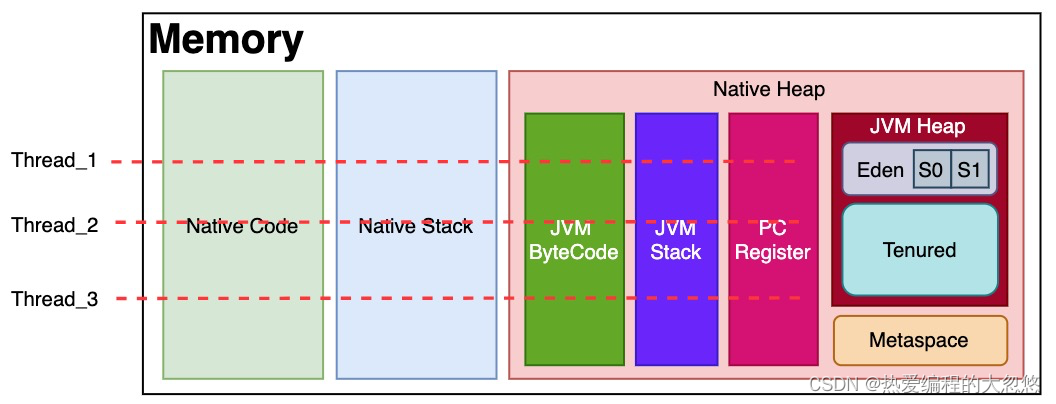
如果从线程执行的角度,大概可以这么理解。每个线程从JVM ByteCode开始执行,记录JVM Stack和PC Register,并被解释成Native Code,在Native Stack真正执行。这些线程共享一个JVM Heap,所以访问共享数据时才需要加锁保证安全。
在G1之前的其他收集器进行收集的范围都是整个新生代或者老年代,而G1打破了原有的分代模型,将堆划分为一个个区域。G1将堆分成许多相同大小的区域单元,每个单元称为Region,Region是一块地址连续的内存空间。每个Region被标记了E、S、O和H,说明每个Region在运行时都充当了一种角色。其中H是以往算法中没有的,它代表Humongous,这表示这些Region存储的是巨型对象(humongous object,H-obj),当新建对象大小超过Region大小一半时,直接在新的一个或多个连续Region中分配,并标记为H。
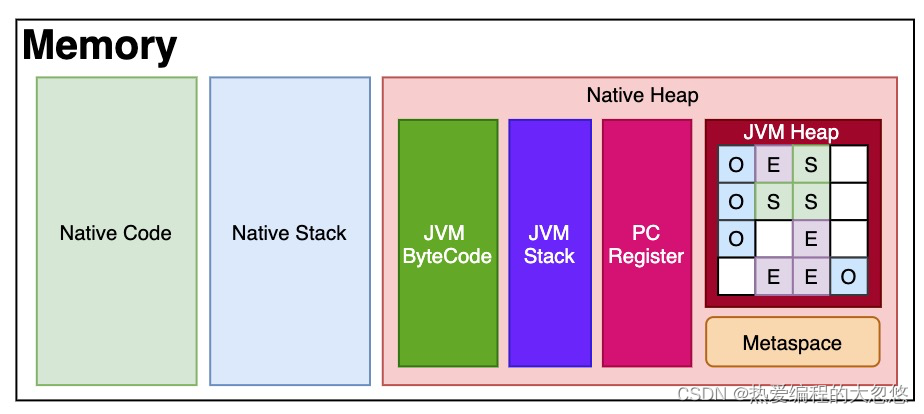
这么划分的目的是在进行收集时不必在全堆范围内进行,这是它最显著的特点。区域划分的好处就是带来了停顿时间可预测的收集模型:用户可以指定收集操作在多长时间内完成。G1垃圾收集算法主要应用在多CPU大内存的服务中,在满足高吞吐量的同时,尽可能地缩短垃圾回收时的暂停时间。
Java Heap和本地内存区别
这里的本地内存就是上图画的直接内存
我先提出一个问题:
Java 的类实例一般在 JVM 堆上分配,而 Java 是通过 JNI 调用 C 代码来实现 Socket 通信的,那么 C 代码在运行过程中需要的内存又是从哪里分配的呢?C 代码能否直接操作 Java 堆?
这个问题的答案如果理解了上面的内容,那么是无需再重复的,但是考虑到部分同学对底层操作系统实现不熟悉,这里再进行一遍解释:
如果你想运行一个 Java 类文件,可以用下面的 Java 命令来执行
java my.class
这个命令中的java其实是一个可执行程序,这个程序会创建 JVM 来加载和运行你的 Java 类。
操作系统会创建一个进程来执行这个java可执行程序,而每个进程都有自己的虚拟地址空间,JVM 用到的内存(包括堆、栈和方法区)就是从进程的虚拟地址空间上分配的。请你注意的是,JVM 内存只是进程空间的一部分,除此之外进程空间内还有代码段、数据段、内存映射区、内核空间等。JVM 的角度看,JVM 内存之外的部分叫作本地内存,C 程序代码在运行过程中用到的内存就是本地内存中分配的。下面我们通过一张图来理解一下。
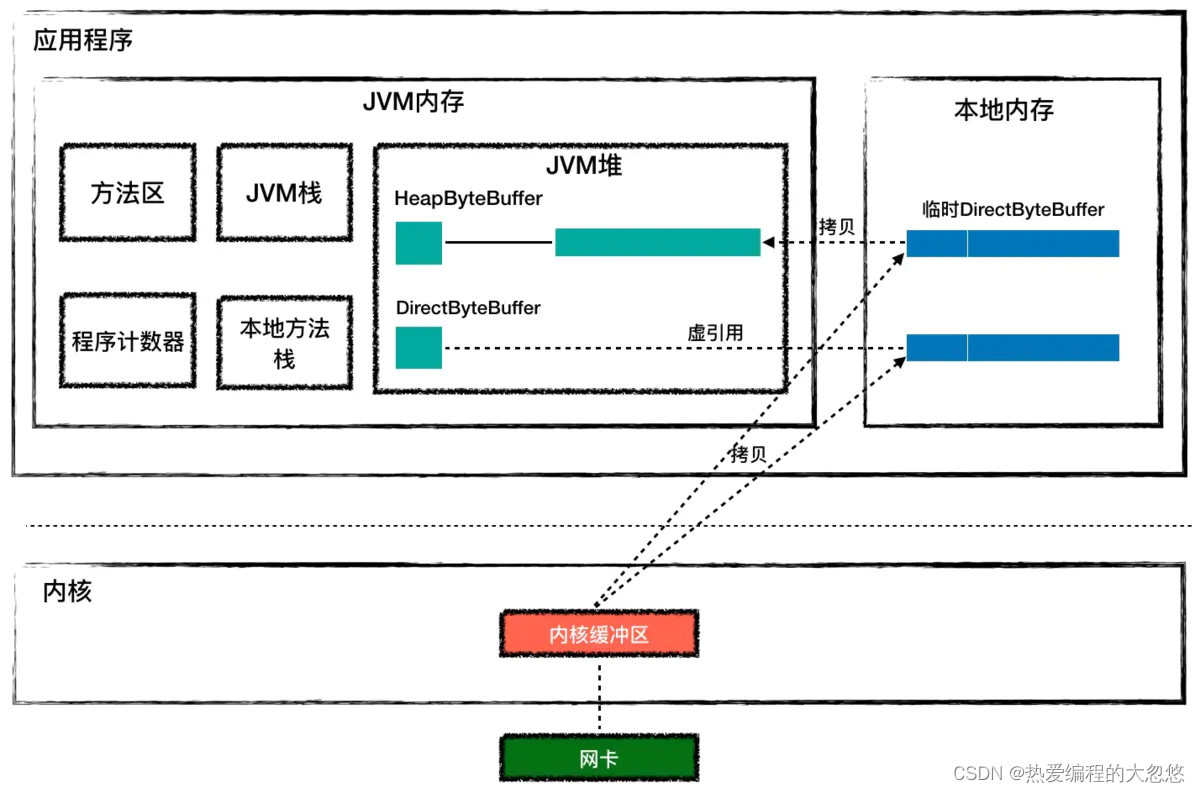
那 HeapByteBuffer 和 DirectByteBuffer 有什么区别呢?HeapByteBuffer 对象本身在 JVM 堆上分配,并且它持有的字节数组byte[]也是在 JVM 堆上分配。
但是如果用HeapByteBuffer来接收网络数据,需要把数据从内核先拷贝到一个临时的本地内存,再从临时本地内存拷贝到 JVM 堆,而不是直接从内核拷贝到 JVM 堆上。这是为什么呢?这是因为数据从内核拷贝到 JVM 堆的过程中,JVM 可能会发生 GC,GC 过程中对象可能会被移动,也就是说 JVM 堆上的字节数组可能会被移动,这样的话 Buffer 地址就失效了。如果这中间经过本地内存中转,从本地内存到 JVM 堆的拷贝过程中 JVM 可以保证不做 GC。
如果使用 HeapByteBuffer,你会发现 JVM 堆和内核之间多了一层中转,而 DirectByteBuffer 用来解决这个问题,DirectByteBuffer 对象本身在 JVM 堆上,但是它持有的字节数组不是从 JVM 堆上分配的,而是从本地内存分配的。
DirectByteBuffer 对象中有个 long 类型字段 address,记录着本地内存的地址,这样在接收数据的时候,直接把这个本地内存地址传递给 C 程序,C 程序会将网络数据从内核拷贝到这个本地内存,JVM 可以直接读取这个本地内存,这种方式比 HeapByteBuffer 少了一次拷贝,因此一般来说它的速度会比 HeapByteBuffer 快好几倍。你可以通过上面的图加深理解。
那为什么HeapByteBuffer的性能比DirectByteBuffer差依然在使用呢?
这是因为本地内存不好管理,发生内存泄漏难以定位,从稳定性考虑,HeapByteBuffer更好。
参考
相关文章
- JVM实用参数(三)打印所有XX参数及值
- linux环境常用命令和java/jvm常用命令
- jvm性能调优---jstat的用法
- Java虚拟机垃圾回收:内存分配与回收策略 方法区垃圾回收 以及 JVM垃圾回收的调优方法
- JVM 发生OOM的四种情况
- JVM调优总结(八)-典型配置举例2
- java 15: jinfo查看jvm配置参数和系统属性
- JVM指令:invokeSpecial/invokeVirtual/invokeStatic/invokeInterface/invokeDynamic方法调用指令
- 【JVM与性能调优】JVM的StackOverflowError介绍
- 为啥要对jvm做优化?
- JVMTM Tool Interface:JVM源码分析之javaagent原理完全解读
- 深入理解JVM一java堆分析
- 【jvm优化超详细】常见的JVM调优场景