
【项目】如何通过总的用户数据计算单台kafka所需磁盘容量?
一、背景
项目中需要用到Kafka来承接车机上来的接口数据,然后再转存到数据库,客户反馈,需要对生产环境中的Kafka的存储容量进行评估。以下是具体的算法内容
二、Kafka的Topic信息与Kafka架构信息
(1)Kafka的Topic信息
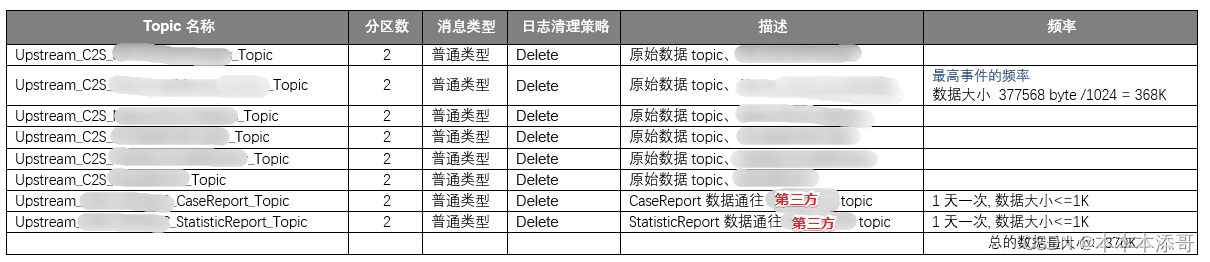
(2)Kafka的架构信息
Kafka架构为集群架构,购买的是阿里云的云Kafka
三台kafka的 连接地址:
K1.alikafka.aliyuncs.com:9092,
K2.alikafka.aliyuncs.com:9092,
K3alikafka.aliyuncs.com:9092
Kafka的副本数量,默认保存三份 (生产需要三个副本,沙箱1个即可)
Kafka保存的天数为 默认的7天
三、开始计算
Step1、计算用户活跃数
假设总的用户数据是60W,
根据经验,用户活跃数为用户总数的15%,即 9W
Step2、评估峰值的业务数据
只要计算出最高业务数据的总频率 ,那么其他业务数据就不用算
那如何评估出峰值的业务数据呢?有两个方案
方案1: 结合日常生活的经验得出
因为这个业务与日常生活场景还是相差比较远的,因此采用方案2
方案2:结合目前有的测试数据进行估值计算
算法如下
查看最高事件的频率是哪个?
select count(*) from 表1
select count(*) from 表2
...
select count(*) from 表N
得出表N是具有最多的数据量的表,那么它就是峰值的业务数据。
Step3、计算产生这么多业务数据需要多少天
select * from 表N order by create_time asc
计算开始时间:2022-10-28
计算结束时间:2023-1-4
总共历经 2 个月 = 31*2 = 62天
Step4、计算一台车机数据总数
select distinct(vin) from 表N
计算出来,这么多数据是由43台车机产生的
43 台车机数据总数 :1258246 条
1 台车机数据总数 :29261 条
实际车机阈值是多少?因为存在业务数据的不确定性,因此无法正确评估
Step5、查看一条数据的大小
一条数据的大小: 800byte (取JSON数据,拿txt查看的大小)
Step6、计算每天一台车机产生的数据大小
62天1 台车机产生的数据大小:29261 条数据 * 800byte = 23409228 byte
每天1 台车机产生的数据大小:23409228 / 62天 = 377568 byte
每天1 台车机产生的数据大小(byte换算成K):377568 byte /1024 = 368K
Step7、计算活跃车机的数据量大小
一台车机总的数据量大小 :370K(四舍五入)
9W活跃车机的数据量大小:370K * 9W = 33300000K = 32519M
Step8、结合Kafka架构计算
32519M * 3个副本数量 = 97558 M
97558 M * 保存多少天 (默认的7天) = 682910 M
Step9、计算一台Kafka机器所需的磁盘容量
预估需要的磁盘容量:666.904296875 (四舍五入700G)
硬盘的容量提集群(三个机器)一共700G
一台机器250G左右就够了
相关文章
- 图解Kafka中的数据采集和统计机制 | 文末送30本书任你选[通俗易懂]
- Flume和Kafka的区别与联系「建议收藏」
- 大数据必知必会之Kafka
- Kafka入门实战教程(9):深入了解Offset
- 如何在 Rocky Linux 上安装 Apache Kafka?
- KAFKA删除topic步骤[通俗易懂]
- Kafka教程_图解kafka
- kafka多线程消费[通俗易懂]
- Kafka 杂谈
- 面试系列-kafka基础组件及其关系
- kafka和rabbitmq对比
- 万字干货:Kafka 高可靠高性能原理探究
- Kafka实战-Kafka到Storm详解大数据
- Kafka实战-实时日志统计流程详解大数据
- 的数据同步从MySQL到Kafka:实现实时数据同步(mysql到kafka)
- Oracle 数据流轻松集成 Kafka 服务:提高数据传输效率(oracle到kafka)
- Kafka与Oracle融合实现数据交互(kafka与oracle)