
【python 2】python 进阶
文章目录
一、函数
def 函数名():
函数体
调用:函数名() —>找到函数,并执行函数体的内容
写了函数名() 就是调用,调用的过程是,系统先顺着名字找到地址,找到地址就找到了内容,之后执行内容。
1、函数的参数
定义:
def 函数名(参数):
函数体
调用:
求随机数的函数,产生的个数不确定:
定义的时候定义的参数:形参(占位)
调用的时候需要的参数:实参(具体的参数)
import random
def generate_random(number):
for i in range(number):
ran = random.randint()
print(ran)
print(generate_random)
输出:>>>
<function generate_random at 0x00000238957C8AE8>
generate_random(3)
输出:>>>
7
6
5
练习 1:封装一个用户登陆函数
'''
定义一个登陆函数,参数是 uername, password
函数体:
判断参数传过来的 username、password 是否正确,如果正确则登陆成功,否则登陆失败
'''
# 函数的定义
def login(username, password):
uname = 'admin123'
pword = '112233'
for i in range(3):
if username == uname:
print('登陆成功!')
break
else:
print('用户名或密码不匹配,登陆失败!')
username = input('请输入用户名:')
password = input('请输入密码:')
else:
print('超过三次错误,用户锁定!')
# 函数的调用
username = input('请输入用户名:')
password = input('请输入密码:')
login(username, password)
>>>
请输入用户名: admin123
请输入密码: 112233
登陆成功!
练习 2:封装一个求最大值的函数
# 定义
def max(iterable):
max = iterable[0]
for i in iterable:
if i > max:
max = i
print('最大值是:', max)
# 调用
list1 = [3,6,3,2,7]
max(list1)
>>>
最大值是: 7
# 定义
def min(iterable):
min = iterable[0]
for i in iterable:
if i < min:
min = i
print('最小值是:',min)
# 调用
list1 = [3,6,3,2,7]
min(list1)
>>>
最小值是: 2
判断是不是 list、tuple等类型:isinstance()
# isinstance(名称,类型)
print(isinstance(list1,list))
>>>
True
练习3:模拟 enumerate
s = [1,3,5,7,9]
for i in s:
print(i)
print('-----------------')
for index,value in enumerate(s):
print(index,value)
print('-----------------')
list1 = []
index = 0
for i in s:
t1 = (index,i)
list1.append(t1)
index+=1
print(list1)
print('-----------------')
for index,value in list1:
print(index,value)
>>>
1
3
5
7
9
-----------------
0 1
1 3
2 5
3 7
4 9
-----------------
[(0, 1), (1, 3), (2, 5), (3, 7), (4, 9)]
-----------------
0 1
1 3
2 5
3 7
4 9
# 定义
def enumerate(value):
list1 = []
index = 0
for i in value:
t1 = (index,i)
list1.append(t1)
index += 1
for index,value in list1:
print(index,value)
#调用:
value = [1,3,5,7,9]
enumerate(value)
>>>
0 1
1 3
2 5
3 7
4 9
列表是可变的,字符串是不可变的,
# 列表可变
list1 = [1,2,3,4]
list2 = list1
list1.remove(3)
print(list2)
>>>
[1, 2, 4]
# 字符串不可变
s1 = 'abc'
s2 = s1
s1 = 'abcd'
print(s2)
>>>
abc
可变参数的定义方式:
# 定义
def add(*args):
print(args)
# 调用
add()
add(1,)
add(1,2)
>>>
() # 空元组
(1,)
(1, 2)
可变参数必须放在不可变参数的后面
def add(name, *args):
print(name, args)
add('aa',1,2,3)
>>>
aa (1, 2, 3)
默认值:
def add(a, b=10):
result = a+b
print(result)
add(3)
add(4,7) # b=7,会覆盖掉默认的b=10
>>>
13
11
# 想给c赋值,不想给b赋值,通过关键字赋值
def add1(a,b=10,c=4):
result = a+b+c
print(result)
add1(2,c=10)
>>>
22
打印每位同学的姓名和年龄:
students={'001':('王俊凯', 20),'002':('易烊千玺',19), '003':('王源',19)}
def print_boy(person):
if isinstance(person, dict):
for name, age in person.values():
print('{}的年龄是: {}'.format(name,age))
print_boy(students)
>>>
王俊凯的年龄是: 20
易烊千玺的年龄是: 19
王源的年龄是: 19
关键字参数:
# **kwargs:关键字参数,必须按 a=10,c=9 这样来赋值
# 得到字典形式的结果
def func(**kwargs):
print(kwargs)
func(a=1,b=2,c=3)
>>>
{'a': 1, 'b': 2, 'c': 3}
能用字典传入吗?
给函数赋值的时候,传递实参的时候,用到 ** 的时候,把这个字典拆包,拆成关键字的形式。拆成 001=python, 003=java…,
dict = {'001':'python','002':'java','003':'c++','004':'go'}
def func1(**kwargs):
print(kwargs)
# 调用
func1(**dict)
>>>
{'001': 'python', '002': 'java', '003': 'c++', '004': 'go'}
使用的时候:
调用的时候用 **dicts:拆包, 穿实参的时候加 **,系统会先拆成关键字的形式(001=python,002=java…)
定义的时候用 **kwargs:装包,把拆完的又给装成字典
def bb(a, b, *c, **d):
print(a,b,c,d)
bb(1,2)
bb(1,2,3,4)
bb(1,2,x=10,y=20)
bb(1,2,3,x=100)
>>>
1 2 () {}
1 2 (3, 4) {}
1 2 () {'x': 10, 'y': 20}
1 2 (3,) {'x': 100}
函数返回值:将函数运算的结果,利用return的形式返回来,return result。
# 把函数的输出结果扔出来
def add(a,b):
result1 = a+b
return result1
result = add(1,2)
print(result)
>>>
3
练习 1:加入购物车
'''
加入购物车
判断用户是否登录,如果登录,则成功加入购物车,如果没有登陆,则提示登陆之后再添加
'''
islogin = False # 用于判断用户是否登录的变量,默认是没有登陆的
def add_shoppingcart(goodsName):
global islogin
if islogin:
if goodsName:
print('成功加入购物车!')
else:
print('登陆成功,没有选中任何商品!')
else:
answer = input('用户没有登陆,是否登陆?(y/n)')
if answer == 'y':
username = input('请输入用户名:')
password = input('请输入密码:')
islogin = login(username, password)
else:
print('很遗憾,不能添加任何商品!')
def login(username, password):
if username == '李佳琪' and password == '123456':
return True
else:
print('用户名或密码有误,请重新输入:')
return False
# 调用函数,添加到购物车
username = input('请输入用户名:')
password = input('请输入密码:')
islogin = login(username, password)
add_shoppingcart('阿玛尼唇釉')
>>>
请输入用户名: 离
请输入密码: ww
用户名或密码有误,请重新输入:
用户没有登陆,是否登陆?(y/n) y
请输入用户名: 李佳琪
请输入密码: 123456
验证码验证:
def generate_checkcode(n):
s = '0123456789qwertyuiopasdfghjklzxcvbnmQWERTYUIOPASDFGHJKLZXCVBNM'
code = ''
for i in range(n):
ran = random.randint(0,len(s)-1)
code += s[ran]
return code
def login():
username = input('输入用户名:')
password = input('请输入密码:')
code = generate_checkcode(5)
print('验证码是:',code)
code1 = input('请输入验证码!')
# 验证
if code.lower() == code1.lower():
if username == 'lijiaqi' and password == '123456':
print('用户登陆成功!')
else:
print('用户名或密码有误!')
else:
print('验证码输入错误')
login()
>>>
输入用户名: lijiaqi
请输入密码: 123456
验证码是: Wavvv
请输入验证码! Wavvv
用户登陆成功!
2、全局变量和局部变量
局部变量:函数内部声明的变量,只能在函数体内改变
全局变量:声明在函数外侧的,所有函数都可以访问,在函数体中不能修改,如果要改,要在函数的开头加 global name,只有修改的时候,才需要加。
什么情况加 global:全局变量是不可变的(字符串、float等)但要修改的时候,需要加 global。如果全局变量是可变的,比如 list、修改的时候是不用加 global 的。
3、内部函数
在函数里边又声明一个函数,这个内部函数就是在大函数里边的。
特点:
- 内部函数可以访问这个函数中声明的变量
- 内部函数可以修改外部函数的可变类型的变量,比如list
- 内部函数不能修改外部函数的不可变变量,要修改得加 nonlocal。
- 内部函数不能修改全局变量,要修改得在内部函数里边加 global.
修改全局变量: global a
修改局部变量: nonlocal b
def func3():
p = 100
list1 = [3,1,2,4]
# 声明内部函数
def inner_func():
for index in range(len(list1)):
list1[index] +=5
print(list1)
inner_func()
func3()
>>>
[8, 6, 7, 9]
def func3():
p = 100
list1 = [3,1,2,4]
# 声明内部函数
def inner_func():
for index,value in enumerate(list1):
list1[index] = value + 5
print(list1)
inner_func()
func3()
>>>
[8, 6, 7, 9]
a = 100
print(globals())
def func():
b = 90
def inner_func():
global a
nonlocal b
c = 88
# 尝试修改
c += 12
b += 10
a += 10
print(a, b, c)
inner_func()
print(locals())
func()
>>>
110 100 100
{'inner_func': <function func.<locals>.inner_func at 0x00000238961E37B8>, 'b': 100}
locals() 函数:是一个内置函数,可以查看当前函数中声明内容有哪些
locals() 输出的形式: key:values
globals() 函数:查看全局变量有哪些,以字典的形式输出。
4、闭包
闭包是在函数中提出的概念,也就是在外部函数的外部访问内部函数。
闭包的格式:在函数里边定义了一个内部函数,把内部函数通过 return 给扔出来了,就叫闭包。
闭包的条件:
- 必须要有内部函数
- 内部函数必须引用外部函数的变量
- 外部函数是有返回值的,返回的值是内部函数名
格式:
def 外部函数():
...
def 内部函数():
...
return 内部函数名
def func():
a = 100
def inner_func():
b = 90
print(a,b)
return inner_func
# 调用,相当于把 inner_func 给了a,a就是内部函数了,然后调用该内部函数,就给 a 加括号就好啦
a = func()
a()
>>>
100 90
def func(a,b):
c = 10
def inner_func():
s = a+b+c
print('相加之和的结果是:', s)
return inner_func
ifunc = func(6,9)
ifunc()
ifunc = func(5,6)
ifunc()
>>>
相加之和的结果是: 25
相加之和的结果是: 21
闭包的特点:
- 能够保存返回闭包时的状态,不会受后面输入参数变化的影响。
5、匿名函数
简化函数的定义
定义格式:lambda 参数1,参数2 : 运算
有lambda,底层就会给你创建一个函数,这个函数是没有名字的,匿名的,前面是参数,:后面的就相当于 return 返回的结果。
# s 是一个函数
s = lambda a,b : a+b
result = s(1,2)
print(result)
>>>
3
匿名函数可以作为参数:
def func(x, y, func):
print(x, y)
print(func)
s = func(x, y)
print(s)
func(1, 2, lambda a, b : a + b)
>>>
1 2
<function <lambda> at 0x0000023896096378>
3
list1 = [3,4,5,6,8]
m = max(list1)
print('列表最大值:',m)
list2 = [{'a':10,'b':20},{'a':13,'b':20},{'a':9,'b':20},{'a':29,'b':20}]
# 找 a 的最大值
m = max(list2, key = lambda x:x['a'])
print('列表的最大值:',m)
>>>
列表最大值: 8
列表的最大值: {'a': 29, 'b': 20}
6、系统自带的函数
1、map() 函数,对列表中元素进行操作,免去了之前的for循环
# map(操作函数,操作对象)
map(lambda ..., list1)
list1 = [3,4,5,6,7,9]
result1 = map(lambda x : x+2, list1)
print(list(result1))
>>>
[5, 6, 7, 8, 9, 11]
如果是偶数,则返回偶数本身,如果不是偶数,则进行+1操作:
# 方法一
func = lambda x : x if x%2 == 0 else x+1
result = func(5)
print(result)
>>>
6
# 方法二,对列表中的奇数进行+1,偶数不变
result = map(lambda x : x if x%2 == 0 else x+1, list1)
print(list(result))
>>>
[4, 4, 6, 6, 8, 10]
2、reduce() 函数,对列表(可迭代的)中的元素进行 ±*/
from functools import reduce
tuple1 = (3,5,6,7,8)
result = reduce(lambda x, y: x+y, tuple1)
print(result)
>>>
29
3、filter() 函数,过滤符合条件的元素,且原始的list不会被改变
list1 = [3,4,5,6,8]
result = filter(lambda x:x>5, list1)
print(list(result))
>>>
[6, 8]
students = [{'name':'lucy','age':21},
{'name':'tomy','age':20},
{'name':'jack','age':19},
{'name':'json','age':18},]
result = filter(lambda x:x['age']>20,students)
print(list(result))
>>>
[{'name': 'lucy', 'age': 21}]
按照年龄从小到大排序:
result = sorted(students, key=lambda x:x['age'])
print(result)
>>>
[{'name': 'json', 'age': 18}, {'name': 'jack', 'age': 19}, {'name': 'tomy', 'age': 20}, {'name': 'lucy', 'age': 21}]
总结:
max(), min(), sorted():都可以结合key来选择
map():将列表中的每个元素进行统一操作
reduce(): 对列表中的元素进行累加啊
filter():过滤
7、递归函数
普通函数:def func(): pass
匿名函数: lambda 参数:返回结果
递归函数:普通函数的一种表现形式,函数自己调用自己
递归函数的特点:
- 一定要有终点(加判断)
- 通常都会有一个入口
def sum(n):
if n == 0:
return 0
else:
return n+sum(n-1)
sum(10)
>>>
55
二、文件操作
1、mode:
- r : read 读,纯文本文件
- w: write 写,纯文本文件
- rb:read binary 二进制读,包括纯文本、图片、音乐、MV等
- wb:write binary 二进制写
- a: append 追加
这里的读写,其实就是确定管道的类型:读、写
系统函数:
open(file, mode, buffering...)
open 就相当于给 file.txt 和 pycharm 建立了一个管道,.read() 就相当于把文件中的东西给读出来,通过管道传递出来。
2、读
stream = open(filename, 'r')
# 返回值是一个stream,流管道
# 然后用 read 去读
container = stream.read()
stream = open(r'file.txt')
# .read() 读所有内容
container = stream .read()
print(container)
# .readable() 判断是否可以读取
container = stream.readable()
print(container)
>>>
hello world!
hello kitty!
hello May!
-----------------------
True
-----------------------
stream = open(r'file.txt')
# .readline() 一行一行读
line = stream.readline()
print(line)
>>>
hello world!
readline() 通常用 for 循环
stream = open(r'file.txt')
while True:
line = stream.readline()
print(line)
if not line:
break
>>>
hello world!
hello kitty!
hello May!
# .readlines(),全部读取,保存在列表里
stream = open(r'file.txt')
lines = stream.readlines()
print(lines)
print('---------------------------')
for i in lines:
print(i)
>>>
['hello world!\n', 'hello kitty!\n', 'hello May!']
---------------------------
hello world!
hello kitty!
hello May!
读取图片,要使用 rb 方式
stream = open(r’image.jpg’,‘rb’)
container = stream.read()
3、写
写
- stream.write('内容‘)
- stream.writelines(Iterable),没有换行的效果,可以自己加\n
特点:
- 在对 stream 的操作时,都会把原来的内容覆盖掉。也就是上次写的内容覆盖掉,但不会把这一次读写的内容覆盖掉。
从得到一个 stream 到关闭这个 stream 叫一次读/写,这一次的读/写中,可以多次对这个 stream 进行操作。
stream = open('file.txt','w')
s = 'hello xiao ming!'
stream.write(s)
stream.write('hello xiao hua!')
stream.close()

换行写:
stream = open('file.txt','w')
stream.write('hello jenny!')
stream.writelines(['hello denny!\n','hello xiao hong!\n'])

4、追加模式 a
在写的时候,不会把之前的内容擦掉,会在后面追加
stream = open('file.txt','a')
stream.write('hello jenny!\n')
stream.writelines(['hello denny!\n','hello xiao hong!\n'])
5、文件的复制
原文件:\img\image.jpg
目标文件:\img\image1.jpg
每次要打开,要关闭 stream 会比较麻烦,可以直接用 with,with可以帮助我们自动释放资源。
with open('image.jpg','rb') as stream:
container = stream.read()
with open('image1.jpg','wb') as wstream:
wstream.write(container)
print('文件复制完成!')
>>>
文件复制完成!
三、os 模块
operation system
模块的概念:.py就是一个模块
stream.name 可以得到文件的路径+名称
os.path:
- os.path.dirname(‘file’) :获取当前文件所在的文件目录(绝对路径)
- os.path.join(path,‘img.jpg’):返回一个拼接后的新路径
# 1、绝对路径
os.path.dirname()
with open('image.jpg','rb') as stream:
container = stream.read()
path = os.path.dirname('__file__')
path1 = os.path.join(path,'image2.jpg')
with open(path1,'wb') as wstream:
wstream.write(container)
print('文件复制完成!')
with open('p1/image1.jpg','rb') as stream:
container = stream.read()
print(stream.name)
file = stream.name
filename = file[file.rfind('/')+1:] # 截取文件名
path = os.path.dirname('__file__')
path1 = os.path.join(path, filename)
with open(path1,'wb') as wstream:
wstream.write(container)
print('文件复制完成!')
>>>
p1/image1.jpg
文件复制完成!
1、os.path
os.path
- absolute:绝对路径
- 表示当前文件的上一级,…/
import os
# 1、判断是否是绝对路径
os.path.isabs(r'p1/image.jpg')
>>>
False
获取文件所在文件夹的当前路径:
path = os.path.dirname('__file__')
print(path)
>>>
C:\Users\man.wang\python\python\part4.py
获取绝对路径:
path = os.path.abspath('file.txt')
print(path)
>>>
C:\Users\man.wang\python\python\file.txt
获取当前文件的绝对路径:
path = os.path.abspath('__file__')
print(path)
获取当前文件的文件夹所在的路径:
path = os.getcwd() #
print(path)
>>>
C:\Users\man.wang\python\python
文件名切分:split
- os.path.split(path):把文件名前的路径和文件名分别存成元组的两个元素
- os.path.splitext():文件和扩展名分开,存放成元组的两个元素
# os.path.split()
path = r'C:\Users\man.wang\python\python\file.txt'
result = os.path.split(path)
print(result)
print(result[1])
>>>
('C:\\Users\\man.wang\\python\\python', 'file.txt')
file.txt
# os.path.splitext()
path = r'C:\Users\man.wang\python\python\file.txt'
result = os.path.splitext(path)
print(result)
>>>
('C:\\Users\\man.wang\\python\\python\\file', '.txt')
得到文件的大小,单位是字节个数:
- os.path.getsize(path)
path = r'C:\Users\man.wang\python\python\file.txt'
result = os.path.getsize(path)
print(result)
>>>
92
2、os 里边的函数
获取当前文件所在的目录:os.getcwd()
result = os.getcwd()
print(result)
>>>
C:\Users\man.wang\python\python
获取文件夹中的所有文件/文件夹的名字:os.listdir()
path = r'C:\Users\man.wang\python\python'
result = os.listdir(path)
print(result)
>>>
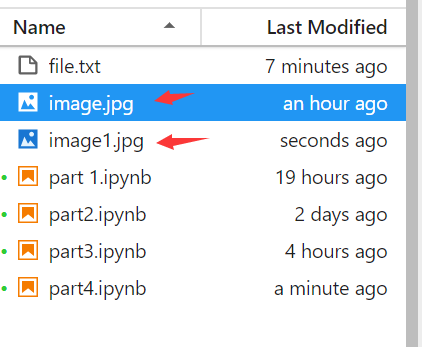
['.ipynb_checkpoints', 'file.txt', 'image.jpg', 'image1.jpg', 'image2.jpg', 'p1', 'p2', 'part 1.ipynb', 'part2.ipynb', 'part3.ipynb', 'part4.ipynb']
创建文件夹:os.mkdir(),如果存在则报错
所以用 os.mkdir() 时候,最好先判断文件夹是否存在
dirc = 'p3'
if not os.path.exists(dirc):
os.mkdir('p3')
删除空文件夹:os.rmdir()
os.rmdir('p3')
删除非空文件夹:要一层一层的删 os.removedirs('p3)
删除文件:os.remove()
os.remove(r'C:\Users\man.wang\python\python\p1\image.jpg')
# 删除 p1 文件夹中的所有文件
path = r'C:\Users\man.wang\python\python\p1'
filelist = os.listdir(path)
for file in filelist:
path1 = os.path.join(path,file)
os.remove(path1)
# 删除p1
else:
os.rmdir(path)
print('删除成功')
>>>
删除成功
切换目录:os.chdir()
# 切换目录,可以切换到指定目录下
f = os.chdir(r'C:\Users\man.wang\python\python\p2')
print(os.getcwd())
>>>
C:\Users\man.wang\python\python\p2
四、异常
语法没报错,运行的时候报错
def chu(a,b):
return a/b
chu(1,0)
>>>
ZeroDivisionError: division by zero
异常处理:
try:
可能出现异常的代码
except:
如果有异常,则执行此处的代码
finally:
无论是否存在异常,都会被执行的代码
如果不加异常,这段代码有问题的话,下面的所有的代码都不会被执行。
def func():
try:
n1 = int(input('输入第一个数字:'))
n2 = int(input('输入第二个数字:'))
# 加法
result = n1 + n2
print('两数之和为:',result)
except:
print('必须输入数字!')
func()
>>>
输入第一个数字: 2
输入第二个数字: w
必须输入数字!
def func():
try:
n1 = int(input('输入第一个数字:'))
n2 = int(input('输入第二个数字:'))
oper = input('请输入运算符号:(+-*/)')
result = 0
if oper == '+':
result = n1 + n2
elif oper == '-':
result = n1 - n2
elif oper == '*':
result = n1 * n2
elif oper == '/':
result = n1 / n2
else:
print('符号输出错误!')
print('结果为:',result)
except ZeroDivisionError:
print('除数不能为 0!')
except ValueError:
print('必须输入数字!')
func()
>>>
输入第一个数字: 1
输入第二个数字: 0
请输入运算符号:(+-*/) /
除数不能为 0!
如果用了 else,在 try 代码中不能出现 return,如果走了 try,然后直接就终止代码了。
情况1:
try:
pass
except:
pass
情况2:打印错误原因
try:
pass
except Exception as err:
print(err)
情况3:没有异常的时候,会执行的 else 的代码,但 try 里边不能用 return,因为没有异常的时候,
try:
pass
except ValueError:
pass
else:
print('')
异常抛出:
# 实现用户名小于6位时抛出异常
def register():
username=input('请输入用户名:')
if len(username)<6:
raise Exception('用户名长度必须6位以上!')
else:
print('输入的用户名是:',username)
register()
>>>
input-> www
Exception: 用户名长度必须6位以上!
五、推导式
从旧的列表推导得到一个新的列表
1、列表推导式
格式:
- [表达式 for 变量 in 旧列表]
- [表达式 for 变量 in 旧列表 if 条件]
符合 if 条件的变量,扔到最前面的表达式中
# 过滤掉长度 <= 3 的人名
names = ['tom','lily','jack','json','bob']
# 第一个 name 就放的是names中符合长度 >3 条件的 name
result = [name for name in names if len(name)>3]
print(result)
result = [name.capitalize() for name in names if len(name)>3]
print(result)
result = [name.title() for name in names if len(name)>3]
print(result)
>>>
['lily', 'jack', 'json']
['Lily', 'Jack', 'Json']
['Lily', 'Jack', 'Json']
# 列表推导式等价实现
names = ['tom','lily','jack','json','bob']
new_name=[]
def func(names):
for name in names:
if len(name)>3:
name = name.title()
new_name.append(name)
return new_name
func(names)
>>>
['Lily', 'Jack', 'Json']
# 将 1~100 之间,能被 3 整除的扔出来
newlist = [i for i in range(1,101) if i%3 == 0]
print(newlist)
>>>
[3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48, 51, 54, 57, 60, 63, 66, 69, 72, 75, 78, 81, 84, 87, 90, 93, 96, 99]
# 将 1~100 之间,能被 3 整除,并且能被5整除的拿出来放到一个列表
newlist = [i for i in range(1,101) if i%3 == 0 and i%5 == 0]
print(newlist)
>>>
[15, 30, 45, 60, 75, 90]
# 求 0~5 之间的偶数,和 0~5 之间的奇数,构成一个元组,放到列表里边
def func():
new_list=[]
for i in range(5):
if i%2 == 0:
for j in range(5):
if j%2 != 0:
new_list.append((i,j))
return new_list
func()
>>>
[(0, 1), (0, 3), (2, 1), (2, 3), (4, 1), (4, 3)]
# 列表推导式写
# 在for后面再写for,就相当于循环中的嵌套
new_list = [(x,y) for x in range(5) if x%2==0 for y in range(5) if y%2 != 0]
print(new_list)
>>>
[(0, 1), (0, 3), (2, 1), (2, 3), (4, 1), (4, 3)]
练习:不带条件的列表推导式,直接取就好啦
'''
list1 = [[1,2,3],[4,5,6],[7,8,9]] -----> list2=[3,6,9]
'''
list1 = [[1,2,3],[4,5,6],[7,8,9]]
new_list = [i[-1] for i in list1]
print(new_list)
>>>
[3, 6, 9]
练习:带 else 的列表推导式,把 for 放到最后
dict1={'name':'tom','salary':5000}
dict2={'name':'lili','salary':8000}
dict3={'name':'jack','salary':3000}
list1 = [dict1, dict2, dict3]
# 如果薪资 > 5000 加工资 200,低于等于 5000 加工资 500
new_list = [person['salary']+200 if person['salary']>5000 else person['salary']+500 for person in list1 ]
print(new_list)
>>>
[5500, 8200, 3500]
2、集合推导式
# 遍历 list 里边的元素,把元素放到集合里边,相当于去重
list1 = [1,2,3,4,5,6,3,1,2,3]
set1 = {x for x in list1}
print(set1)
set2 = {x+1 for x in list1 if x>3}
print(set2)
>>>
{1, 2, 3, 4, 5, 6}
{5, 6, 7}
3、字典推导式
# key 和 value 进行交换
dict1 = {'a':'A','b':'B','c':'C','d':'C'}
new_dict = {value:key for key,value in dict1.items()}
print(new_dict)
>>>
{'A': 'a', 'B': 'b', 'C': 'd'}
六、生成器
通过列表生成式(列表推导式),可以直接创建一个列表,但是,收到内存的限制,列表容量肯定是有限的,而且,创建一个包含100w个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面的大多数元素占用的空间就白白浪费了。所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算后续的元素呢,这样就不必创建整个list了,从而能够大量的节省空间,在 python 中,这种一边循环,一边计算的机制,成为生成器(generator)。
得到生成器的方式:
- 通过列表推导式得到生成器(用小括号)
# [0,3,6,9,12,15,18,21,24,27]
# 1、列表推导式
new_list = [x*3 for x in range(20)]
print(new_list)
>>>
[0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48, 51, 54, 57]
# 2、列表生成式,只要调一下,就产生一次
# 得到生成器
g = (x*3 for x in range(20))
print(type(g))
print(g)
# 方式一
print(g.__next__())
print(g.__next__())
print(g.__next__())
>>>
<class 'generator'>
<generator object <genexpr> at 0x000002BFF85C4F48>
0
3
6
# 方式二:next(),每调用一次,就会产生一个元素
print(next(g))
print(next(g))
print(next(g))
>>>
9
12
15
# 生成器产生元素完毕,你再次调用的时候,就会报错
print(next(g))
>>>
StopIteration:
使用一个循环来搞定:
g = (x*3 for x in range(10))
while True:
try:
e = next(g)
print(e)
except:
print('没有更多元素啦!')
break
>>>
0
3
6
9
12
15
18
21
24
27
没有更多元素啦!
yield():函数里边有yield,说明函数就不是函数了,就变成了生成器
'''
使用函数得到生成器:
1、定义一个函数,函数中使用yield
2、调用函数,并接收调用的结果
3、得到生成器
4、借助 next()/__next()__ 得到元素
'''
# 调用 func() 的时候是不会走到函数里边去的
# 只有用 next() 的时候才会走到函数里边
def func():
n = 0
while True:
n += 1
yield n # return+暂停
g = func()
>>>
<generator object func at 0x000002BFF923EC78>
# yield 就相当于 return + 暂停,把 n 扔出去,并且停下来,不进行循环了,当你下次再用 next() 的时候,值再走到 while true里边,进行下一次循环。
def func():
n = 0
while True:
n += 1
yield n
g = func()
print(next(g))
print(next(g))
print(next(g))
print(next(g))
>>>
1
2
3
4
斐波那契数列:
def fib(length):
a, b = 0, 1
n = 0
while n<length:
# print(b)
yield b
a, b = b, a+b
n += 1
return '没有更多元素!'
g = fib(8)
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
>>>
1
1
2
3
5
8
13
21
StopIteration: 没有更多元素!
生成器方法:
- next():获取下一个元素
- send():像每次生成器中传值的,第一次调用的时候必须先传一个 None
生成器应用:
进程>线程>协程
一个进程可以用多个线程来并行完成,一个线程又可以用多个协程来并完成。
# 任务是前后进行的,先搬完砖才能听歌
def task1(n):
for i in range(n):
print('正在搬第{}块转'.format(n))
def task2(n):
for i in range(n):
print('正在听第{}首歌'.format(n))
task1(3)
task2(3)
>>>
正在搬第0块转
正在搬第1块转
正在搬第2块转
正在听第0首歌
正在听第1首歌
正在听第2首歌
# 两个任务同时进行
def task1(n):
for i in range(n):
print('正在搬第{}块转'.format(i))
yield None
def task2(n):
for i in range(n):
print('正在听第{}首歌'.format(i))
yield None
g1 = task1(3)
g2 = task2(3)
while True:
try:
g1.__next__()
g2.__next__()
except:
break
>>>
正在搬第0块转
正在听第0首歌
正在搬第1块转
正在听第1首歌
正在搬第2块转
正在听第2首歌
生成器的构成:
- 通过列表推导式完成
- 通过 函数 + yield 完成
产生元素:
- next(generator)
- 生成器自己的方法
- generator._ next _(),产生完毕再次调用,会产生异常
- generator.send(),给生成器送值
生成器的应用:在协程中使用
七、迭代器
可迭代的对象:
- 生成器
- 元组、列表、集合、字典、字符串
如何判断是否可迭代:isinstance()
from collections import Iterable
# 列表是可迭代的
list1 = [1,2,3]
isinstance(list1,Iterable)
>>>
True
# 整型是不可迭代的
isinstance(1,Iterable)
>>>
False
# 生成器是可迭代的
g = (x +1 for x in range(10))
isinstance(g,Iterable)
>>>
True
迭代器:可以被 next() 函数调用并不断返回下一个值的对象,称为迭代器 iterator
- 迭代器是访问集合元素的一种方式
- 迭代器是可以记住遍历位置的对象,迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问结束
- 迭代器只能往前,不能后退
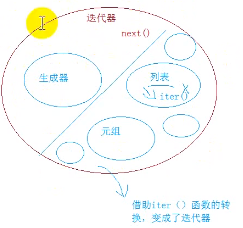
生成器:可迭代,也是迭代器(可以用 next() 方法)
列表:可迭代,但不是迭代器(不可以 next() 方法)
怎么把一个可迭代的对象变成迭代器:iter(obj)
list1 = [1,2,3]
print(type(list1))
list1 = iter(list1)
print(type(list1))
print(next(list1))
print(next(list1))
>>>
<class 'list'>
<class 'list_iterator'>
1
2
生成器:为了节省内存,一个个拿到元素,生成的方式有两种,一种是 列表生成式的方式,另一种是借助函数+yield方式。
迭代器:只要能够调用 next得到下一个元素的,就叫迭代器
迭代器是一个大的范围, 生成器是迭代器的一种,生成器也是迭代器。
列表/元组等不是一个迭代器,但也可以变成一个迭代器。
迭代器:
- 借助 iter() 转换,可以得到
- 不借助,本身就是迭代器
相关文章
- 归纳整理Python中的控制流语句的知识点
- Python进阶学习之特殊方法实例详析
- Python子进程 (subprocess包)
- 【Python实战】python中含有中文字符无法运行
- Python multiprocessing WHY and HOW
- 【Python基础】python爬虫之异步网络爬虫ǃ
- Python之tkinter:动态演示调用python库的tkinter带你进入GUI世界(Button展示图片事件)
- Python之tkinter:动态演示调用python库的tkinter带你进入GUI世界(Find/undo事件)
- Python编程语言学习:python中与数字相关的函数(取整等)、案例应用之详细攻略
- Python语言学习:基于python五种方法实现使用某函数名【func_01】的字符串格式('func_01')来调用该函数【func_01】执行功能
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- 《看漫画学Python》1、2版分享,python最佳入门教程,中学生用业余时间都能学会,北大教授看完都这样定义它
- python采集最新世界大学排名, 来看看你的母校上榜没~
- Python 初学者进阶的九大技能
- 容易被忽视的python装饰器的特性
- 【华为机试真题 Python实现】统计文本数量
- Python编程:查看python环境支持的whl
- Python——用正则求时间差
- python里使用正则表达式的连接符
- python web py入门(7)- 创建论坛的首页
- 微软开源最强Python自动化神器Playwright,不用写一行代码
- python后台架构Django教程——manage.py命令
- 排列python
- 学习C++:C++进阶(六)如何在C++代码中调用python类,实例化python中类的对象,如何将conda中的深度学习环境导入C++项目中
- 【Python】3.python实现图片上传到阿里云OSS