
Spring Cloud网关路由谓词

目录
一、前言
Spring Cloud Gateway提供了一个基于Spring生态系统的API网关,其中包括:Spring 5,Spring Boot 2和项目Reactor。Spring Cloud网关的目的是提供一种简单而有效的方法来路由到API,并向它们提供跨领域的关注,例如:安全性,监视/度量和弹性。
1、注意事项
Spring Cloud网关需要Spring Boot和Spring Webflux提供的Netty运行环境。它不能在传统的Servlet容器中或作为WAR构建。如果不希望启用网关,则设置spring.cloud.gateway.enabled=false。
2、词汇表
- 路由:路由网关的基本构建块。它由ID,目标URI,谓词集合和过滤器集合定义。如果聚合谓词为true,则匹配路由。
- 谓词:这是 Java 8 Function谓词。输入类型为 Spring Framework ServerWebExchange。这使开发人员可以匹配HTTP请求中的任何内容,例如标头或参数。
- 过滤器:这些是使用特定工厂构造的实例 Spring Framework GatewayFilter。在此,可以在发送下游请求之前或之后修改请求和响应。
3、工作原理
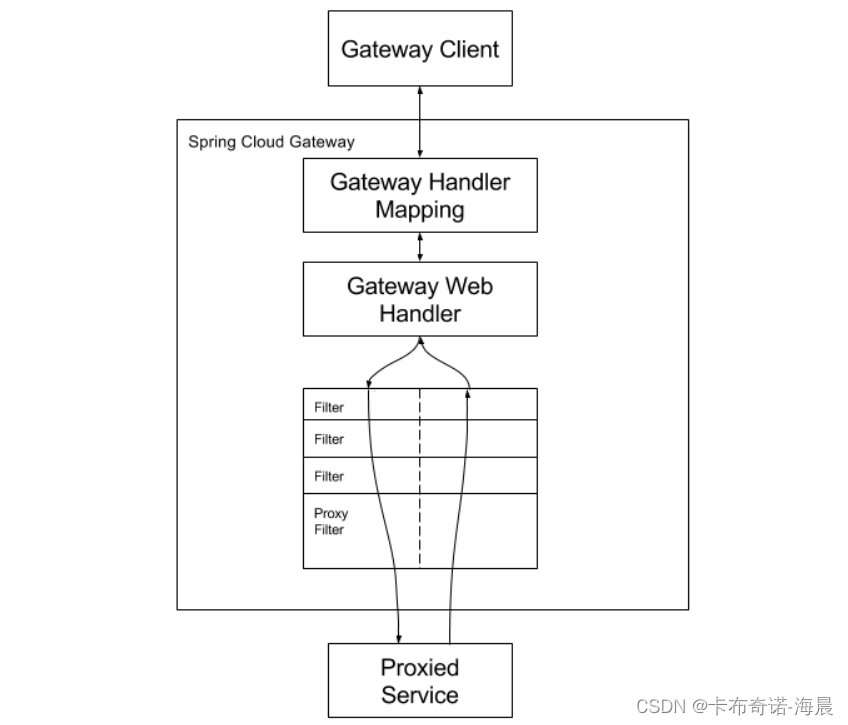
客户端向Spring Cloud网关发出请求。如果网关处理程序映射确定请求与路由匹配,则将其发送到网关Web处理程序。该处理程序运行通过特定于请求的筛选器链发送请求。筛选器由虚线分隔的原因是,筛选器可以在发送代理请求之前或之后执行逻辑。执行所有“前置”过滤器逻辑,然后发出代理请求。发出代理请求后,将执行“后置”过滤器逻辑。 拦截器也同样有前进和逆过程,即前置后置处理。
二、配置路由谓词工厂
有两种配置谓词和过滤器的方法:快捷方式和完全扩展的参数。下面的大多数示例都使用快捷方式。配置路由谓词工厂使用application.yml配置文件。
1、快捷方式
1.1、快捷方式配置
快捷方式配置由过滤器名称识别,后跟等号(=),后跟由逗号分隔的参数值(,)。
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- Cookie=mycookie,mycookievalue先前的示例使用两个参数定义了Cookie Route Predicate Factory,即cookie名称mycookie和与mycookievalue相匹配的值。
1.2、完全展开的参数
完全扩展的参数看起来更像带有名称/值对的标准Yaml配置。通常,将有一个name键和一个args键。args键是用于配置谓词或过滤器的键值对的映射。
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- name: Cookie
args:
name: mycookie
regexp: mycookievalue这是上面显示的Cookie谓词的快捷方式配置的完整配置。
2、路由谓词工厂
Spring Cloud网关将路由匹配为Spring WebFlux HandlerMapping基础结构的一部分。Spring Cloud网关包括许多内置的Route Predicate工厂。所有这些谓词都与HTTP请求的不同属性匹配。多个路由谓词工厂可以合并,也可以通过逻辑and合并。
2.1、路由谓词工厂之后
After路由谓词工厂采用一个参数,即datetime(这是Java ZonedDateTime)。该谓词匹配在当前日期时间之后发生的请求。
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- After=2017-01-20T17:42:47.789-07:00[America/Denver]该路线与2017年1月20日17:42山区时间(丹佛)之后的所有请求匹配。
2.2、路线谓词工厂之前
Before路由谓词工厂采用一个参数datetime(它是Java ZonedDateTime)。该谓词匹配当前日期时间之前发生的请求。
spring:
cloud:
gateway:
routes:
- id: before_route
uri: https://example.org
predicates:
- Before=2017-01-20T17:42:47.789-07:00[America/Denver]该路线与2017年1月20日17:42山区时间(丹佛)之前的所有请求匹配。
2.3、路由谓词工厂之间
Between路由谓词工厂采用两个参数datetime1和datetime2,它们是Java ZonedDateTime对象。该谓词匹配在datetime1之后和datetime2之前发生的请求。datetime2参数必须在datetime1之后。
spring:
cloud:
gateway:
routes:
- id: between_route
uri: https://example.org
predicates:
- Between=2017-01-20T17:42:47.789-07:00[America/Denver], 2017-01-21T17:42:47.789-07:00[America/Denver]该路线与2017年1月20日山区时间(丹佛)之后和2017年1月21日17:42山区时间(丹佛)之后的所有请求匹配。这对于维护时段可能很有用。
3、Cookie路线谓词工厂
Cookie Route Predicate Factory采用两个参数,即cookie name和regexp(这是Java正则表达式)。该谓词匹配具有给定名称的cookie,并且值匹配正则表达式。
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: https://example.org
predicates:
- Cookie=chocolate, ch.p此路由与请求匹配,具有一个名为chocolate的cookie,该cookie的值与ch.p正则表达式匹配。
4、标头路由谓词工厂
Header Route Predicate Factory具有两个参数,标头name和regexp(这是Java正则表达式)。该谓词与具有给定名称的标头匹配,并且值与正则表达式匹配。
spring:
cloud:
gateway:
routes:
- id: header_route
uri: https://example.org
predicates:
- Header=X-Request-Id, \d+如果请求具有名为X-Request-Id的标头,且其值与\d+正则表达式匹配(具有一个或多个数字的值),则此路由匹配。
5、主机路由谓词工厂
Host Route Predicate Factory采用一个参数:主机名patterns的列表。模式是Ant样式的模式,以.作为分隔符。该谓词与匹配模式的Host头匹配。
spring:
cloud:
gateway:
routes:
- id: host_route
uri: https://example.org
predicates:
- Host=**.somehost.org,**.anotherhost.org还支持URI模板变量,例如{sub}.myhost.org。
如果请求的Host标头的值为www.somehost.org或beta.somehost.org或www.anotherhost.org,则此路由将匹配。
该谓词提取URI模板变量(如上例中定义的sub)作为名称和值的映射,并使用在ServerWebExchangeUtils.URI_TEMPLATE_VARIABLES_ATTRIBUTE中定义的键将其放置在ServerWebExchange.getAttributes()中。这些值可供GatewayFilter工厂使用。
6、方法路线谓词工厂
Method路由谓词工厂采用一个methods参数,该参数是一个或多个要匹配的HTTP方法。
spring:
cloud:
gateway:
routes:
- id: method_route
uri: https://example.org
predicates:
- Method=GET,POST如果请求方法是GET或POST,则此路由将匹配。
7、路径路线谓词工厂
Path路由谓词工厂采用两个参数:Spring PathMatcher patterns的列表和matchOptionalTrailingSeparator的可选标志。
spring:
cloud:
gateway:
routes:
- id: host_route
uri: https://example.org
predicates:
- Path=/foo/{segment},/bar/{segment}如果请求路径为例如/foo/1或/foo/bar或/bar/baz,则此路由将匹配。
该谓词提取URI模板变量(如以上示例中定义的segment)作为名称和值的映射,并使用在ServerWebExchangeUtils.URI_TEMPLATE_VARIABLES_ATTRIBUTE中定义的键将其放置在ServerWebExchange.getAttributes()中。这些值可供GatewayFilter工厂使用。
可以使用实用程序方法来简化对这些变量的访问。
Map<String, String> uriVariables = ServerWebExchangeUtils.getPathPredicateVariables(exchange);
String segment = uriVariables.get("segment");8、查询路由谓词工厂
Query Route Predicate Factory采用两个参数:必需的param和可选的regexp(这是Java正则表达式)。
spring:
cloud:
gateway:
routes:
- id: query_route
uri: https://example.org
predicates:
- Query=baz如果请求包含baz查询参数,则此路由将匹配。
spring:
cloud:
gateway:
routes:
- id: query_route
uri: https://example.org
predicates:
- Query=foo, ba.如果请求包含一个foo查询参数,其值与ba.正则表达式匹配,则此路由将匹配,因此bar和baz将匹配。
9、RemoteAddr路由谓词工厂
RemoteAddr路由谓词工厂采用sources的列表(最小大小1),它是CIDR表示法(IPv4或IPv6)字符串,例如192.168.0.1/16(其中192.168.0.1是IP地址, 16是子网掩码)。
spring:
cloud:
gateway:
routes:
- id: remoteaddr_route
uri: https://example.org
predicates:
- RemoteAddr=192.168.1.1/24如果请求的远程地址为192.168.1.10,则此路由将匹配。
10、重量路线谓词工厂
Weight Route Predicate Factory接受两个参数group和weight(一个int)。权重是按组计算的。
spring:
cloud:
gateway:
routes:
- id: weight_high
uri: https://weighthigh.org
predicates:
- Weight=group1, 8
- id: weight_low
uri: https://weightlow.org
predicates:
- Weight=group1, 2此路由会将约80%的流量转发到https://weighthigh.org,并将约20%的流量转发到https://weighlow.org
10.1、修改解析远程地址的方式
默认情况下,RemoteAddr路由谓词工厂使用传入请求中的远程地址。如果Spring Cloud网关位于代理层后面,则此地址可能与实际的客户端IP地址不匹配。
可以通过设置自定义RemoteAddressResolver来自定义解析远程地址的方式。Spring Cloud网关带有一个基于 X-Forwarded-For标头XForwardedRemoteAddressResolver的非默认远程地址解析器。
XForwardedRemoteAddressResolver有两个静态构造方法,它们采用不同的安全性方法:
XForwardedRemoteAddressResolver::trustAll返回一个RemoteAddressResolver,该地址始终使用在X-Forwarded-For标头中找到的第一个IP地址。这种方法容易受到欺骗,因为恶意客户端可能会为X-Forwarded-For设置一个初始值,该初始值将被解析程序接受。XForwardedRemoteAddressResolver::maxTrustedIndex获取一个索引,该索引与在Spring Cloud网关前面运行的受信任基础结构的数量相关。例如,如果Spring Cloud网关只能通过HAProxy访问,则应使用值1。如果在访问Spring Cloud网关之前需要两跳可信基础结构,则应使用值2。
给定以下标头值:
<span style="color:#000000"><span style="background-color:#f8f8f8">X-Forwarded-For: 0.0.0.1, 0.0.0.2, 0.0.0.3</span></span>下面的maxTrustedIndex值将产生以下远程地址。
maxTrustedIndex | 结果 |
|---|---|
| [ | (invalid, |
| 1 | 0.0.0.3 |
| 2 | 0.0.0.2 |
| 3 | 0.0.0.1 |
| [4, | 0.0.0.1 |
使用Java配置:
GatewayConfig.java
RemoteAddressResolver resolver = XForwardedRemoteAddressResolver
.maxTrustedIndex(1);
...
.route("direct-route",
r -> r.remoteAddr("10.1.1.1", "10.10.1.1/24")
.uri("https://downstream1")
.route("proxied-route",
r -> r.remoteAddr(resolver, "10.10.1.1", "10.10.1.1/24")
.uri("https://downstream2")
)
相关文章
- Spring学习笔记(五)——JdbcTemplate和spring中声明式事务
- Spring学习笔记(九)——SpringMVC实现文件上传
- spring cloud总览和架构图[通俗易懂]
- Spring Cloud Alibaba:将 Sentinel 熔断限流规则持久化到 Nacos 配置中心
- Spring Cloud Gateway夺命连环10问?
- 【11】Spring源码-分析篇-事务源码分析
- spring cloud gateway 路由转发原理_微服务网关的作用是什么
- Spring Cloud Alibaba系列学习文章二
- Spring-JDBCTemplate
- Spring Cloud Config
- spring常用注解
- Spring Cloud 2020.0.4 发布!
- Spring Boot 2.4.3、2.3.9 版本发布,你准备好了吗?
- Spring Cloud Gateway路由的基本概念
- Spring Cloud Gateway 过滤器的作用(二)
- Spring Cloud Stream 高级特性-消息转换和序列化
- Spring Cloud Stream 高级特性-消息路由和过滤(一)
- Spring Cloud Security的核心组件-Cloud OAuth2 Client
- Spring Cloud Security,使用redis存储token
- Spring Cloud Task 集成Spring Cloud Task Batch(二)
- Spring Cloud Data Flow 进行多租户部署和管理
- spring中注解的使用详解编程语言
- Spring——scope详解编程语言
- Spring Hiernate整合详解编程语言
- Spring系列之bean的使用详解编程语言
- Spring getType方法:获取JavaBean的类型
- Maximizing Performance: Harnessing the Power of Redis and Spring Framework(redisspring)