
【java】HashMap底层的实现原理(JDK8)
文章目录
HashMap的底层是通过数组 + 单向链表/红黑树实现的。
知识点回顾
数组特点
- 存储区间是连续的,且占用内存严重,空间复杂度也很大,时间复杂度为 O(1)。
- 优点: 随机读取效率很高,原因是数组是连续的(随机访问性强,查找速度快)。
- 缺点: 插入和删除数据效率低,因插入数据,这个位置后面的数据在内存中要后移,且大小固定不易动态扩展。
链表特点
- 区间离散,占用内存宽松,空间复杂度小,时间复杂度 O(n)。
- 优点: 插入删除速度快,内存利用率高,没有大小固定,扩展灵活。
- 缺点: 不能随机查找,每次都是从第一个开始遍历(查询效率低)。
以上数组和链表,大家都知道各自优缺点。那么我们能不能把以上两种结合在一起使用,从而实现查询效率高和删除插入效率也高的数据结构呢?答案是可以的,那就是哈希表可以满足,接下来我们一起复习下 HashMap
哈希表特点
实现查询效率高和删除插入效率也高的数据结构
接下来我们一起复习下 HashMap 中的 put() 和 get() 方法实现原理。
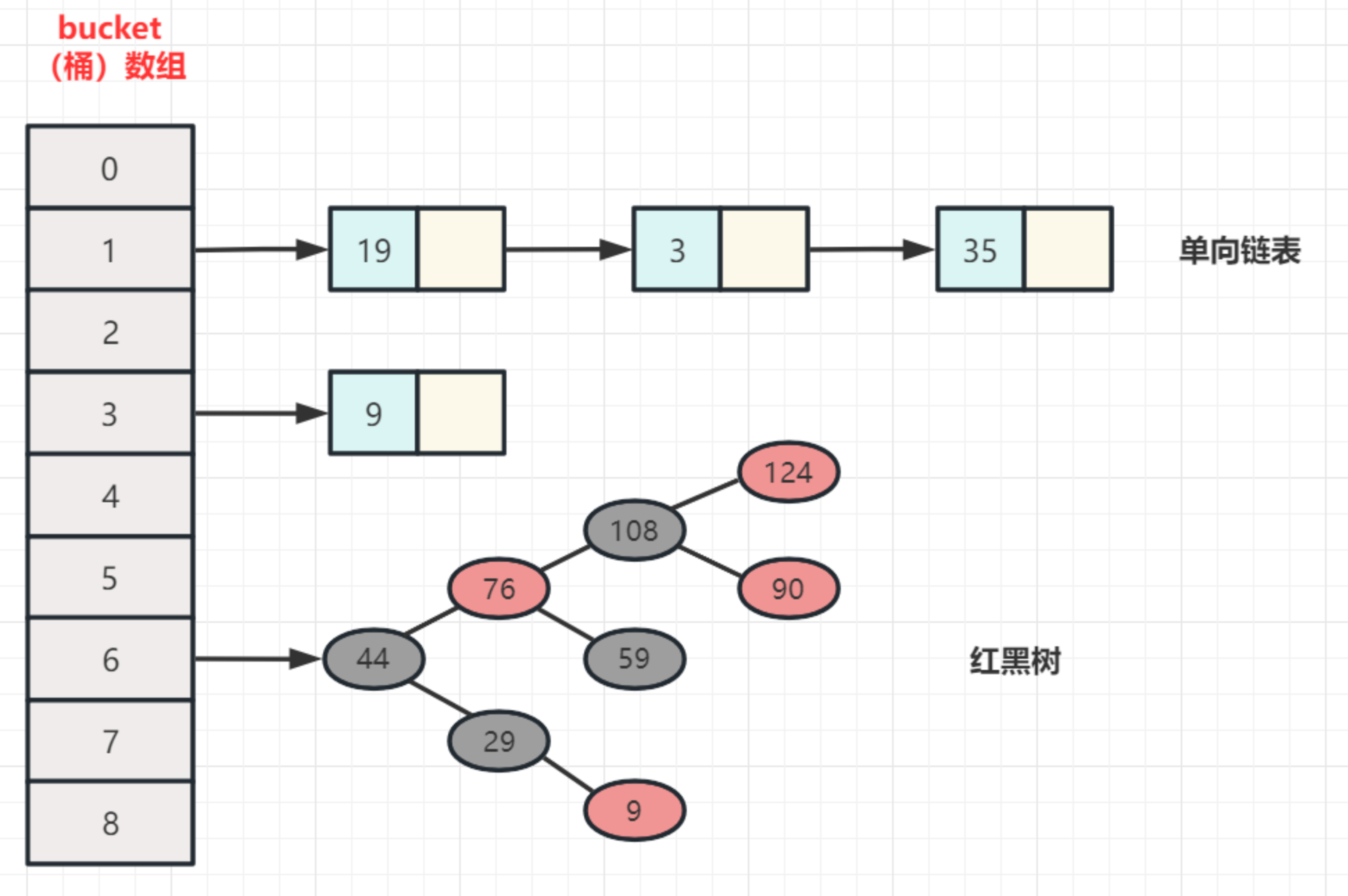
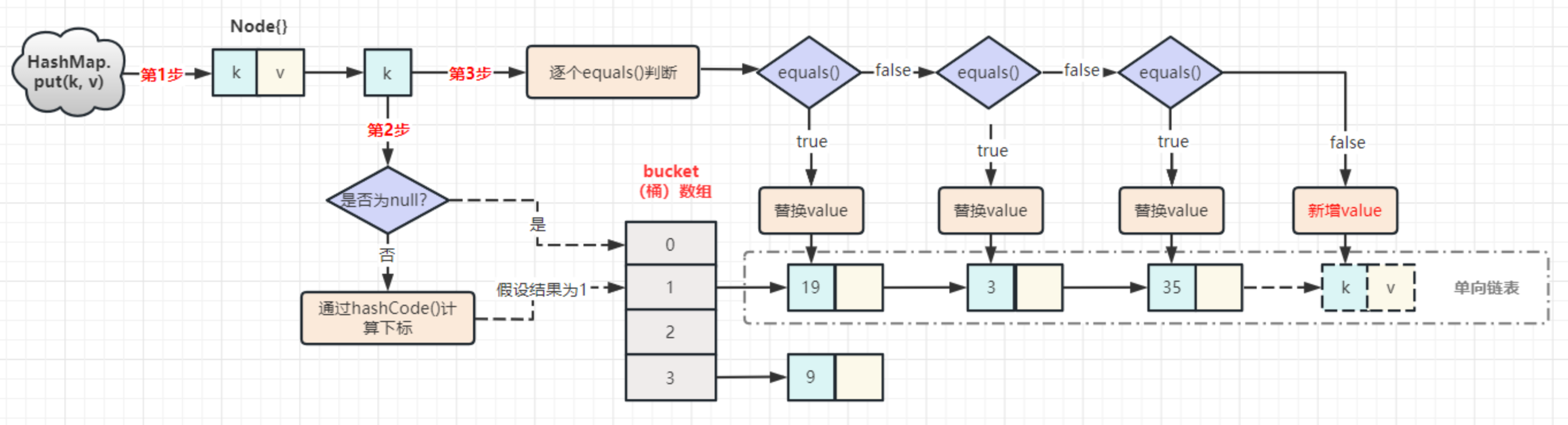
HashMap 的 put() 和 get() 的实现
map.put(k, v) 实现原理
-
第1步,首先将 k, v 封装到 Node 对象当中(节点)。
-
第2步,它的底层会调用 K 的 hashCode() 方法得出 hash 值。
-
第3步,通过哈希表函数/哈希算法,将 hash 值转换成数组的下标:
- 下标位置上如果没有任何元素,就把 Node 添加到这个位置上;
- 如果说下标对应的位置上有链表,就会拿着 k 和链表上每个节点的 k 进行 equals:
- 如果所有的 equals 方法返回都是 false,那么这个新的节点将被添加到链表的末尾;
- 如其中有一个 equals 返回了 true,那么这个节点的 value 将会被覆盖。
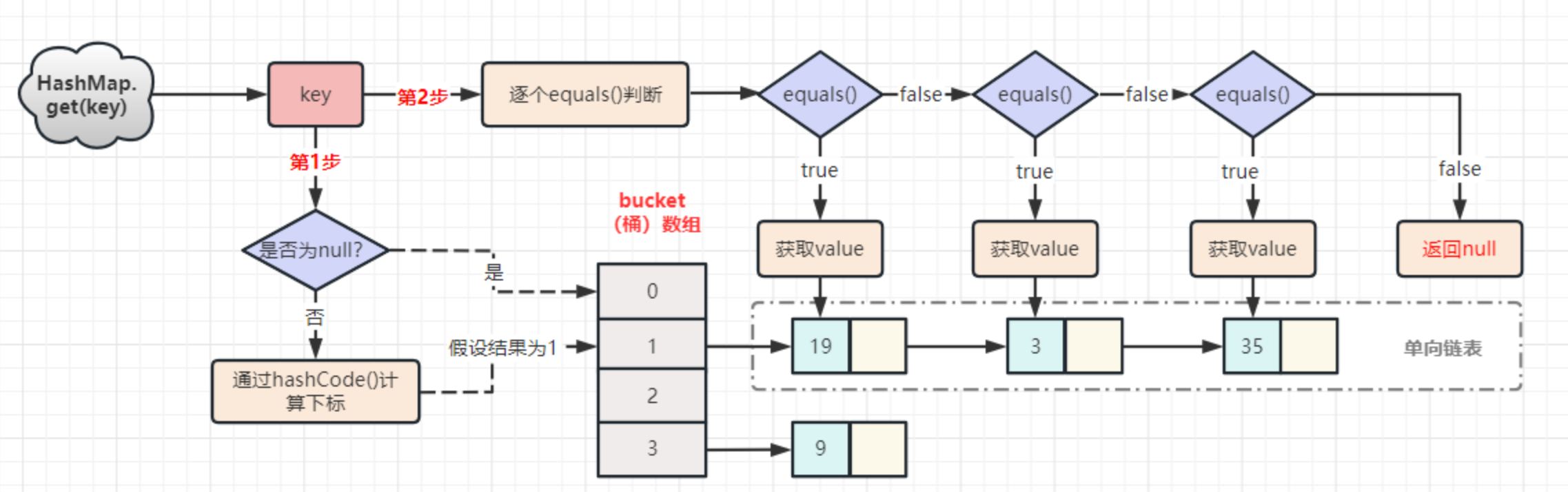
map.get(k) 实现原理
- 第1步,先调用 k 的 hashCode() 方法得出哈希值,并通过哈希算法转换成数组的下标。
- 第2步,通过上一步哈希算法转换成数组的下标之后,再通过数组下标快速定位到链表所在位置上。
- 如果这个位置上什么都没有,则返回 null;
- 如果这个位置上有单向链表,那么它就会拿着参数 k 和单向链表上的每一个节点的 k 进行 equals:
- 如果所有 equals 方法都返回 false,则 get 方法返回 null;
- 如果其中一个节点的 k 和参数 k 进行 equals 返回 true,那么此时该节点的 value 就是我们要找的 value 了,get 方法最终返回这个要找的 value。
HashMap 的常见面试题
为何随机增删、查询效率都很高?
增删是在链表上完成的,而查询主要是通过数组定位,然后扫描部分链表,所以效率高。
HashMap 集合的 key,会先后调用两个方法:hashCode() 和 equals() 方法,所以当对象充当 key 时,这两个方法都需要重写。
为什么放在 HashMap 集合 key 部分的元素需要重写 equals 方法?
因为 equals 默认比较的是两个对象的内存地址,如果想根据对象的属性来判断,则需要重写。
HashMap 的 key 为什么是无序的?
因为不一定挂到哪一个单向链表上,因此加入顺序和取出也不一样。
HashMap 怎么保持不可重复?
使用 equals 方法来保证 HashMap 的 key 不可重复。如果 key 重复的话,value 就会覆盖。存放在 HashMap 集合中的 key,其实就是存放在 HashSet 集合中,所以 HashSet 集合也需要重写 equals() 和 hashCode() 方法。
HashMap 是如何扩容的?
HashMap 集合的默认初始化容量为16,默认加载因子为 0.75,也就是说当 HashMap 集合底层数组的容量达到 75% 时,数组就开始扩容。HashMap 集合初始化容量是 2 的倍数,是为了达到散列均匀,提高 HashMap 集合的存取效率。
HashMap 在 JDK7 和 JDK8 有什么不同?
-
new HashMap<>(),底层不会再创建一个长度为 16 的数组,改为首次调用 put() 方法时创建;
-
jdk8 底层的数组是 Node[],而非 Entry[];
-
jdk7 底层结构只有:数组+链表,jdk8 中底层结构:数组+链表+红黑树。
-
形成链表时,七上八下
- jdk7:头插法,新元素指向旧元素(多线程修改会有死锁问题);
- jdk8:尾插法,旧元素指向新元素;
-
为什么要用红黑树:
- 首先,正常场景下不会一下子产生特别多的 Hash 冲突,只有非常规的场景下才会出现 Hash 冲突,需要转化为红黑树结构。
- 红黑树解决了超长链表查询效率低下的问题,但是小数据量的链表并不比红黑树的查询效率要低。
- Hash 值如果足够随机,则在 Hash 表内按泊松分布,在负载因子 0.75 的情况下,长度超过 8 的链表出现概率时 0.00000006,选择 8 就是为了尽量降低树化的几率。
-
树化的两个条件:(必须都满足)
- 哈希单向链表中的元素数 > 8
- 当前数组的长度 > 64
-
退化链表的条件:(任何一个满足)
- 红黑树上的节点数 < 6
- remove 节点时,若 root、root.left、root.right、root.left.left 有任意一个为 null,也会退化为链表。
HashMap 的哈希碰撞
如果 key1 和 key2 的哈希值相同,就会存放到同一个单向链表上。
如果 key1 和 key2 的哈希值不同,但由于哈希算法执行结束之后转换的数组下标可能相同,此时会发生哈希碰撞。
HashMap 的 key 允许为 null 吗?
允许
JDK8 中 HashMap 的 put() 方法:
public V put(K key, V value) {
// 采用 hash(key) 来计算 key 的 hashCode 值
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
// 当 key 为 null 的时候,不走 hashCode() 方法
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashMap 中使用 hash() 方法来计算 key 的哈希值,当 key 为 null 时,直接令 key 的哈希值为0,不走 key.hashCode() 方法,所以即使为 null 也不会抛出空指针异常。
相关文章
- java中数组转列表_Java数组转list
- 手机java程序_2020年最流行的Java开发技术
- java出现中文乱码_Java开发中中文乱码总结
- 安卓java游戏模拟器_Java手机游戏模拟器
- java oracle数据备份_Java实现Oracle数据库备份
- java 生成xml dom4j_Java生成xml——DOM4J生成
- 【深入浅出Java原理及实战】「源码分析系列」深入分析JDK动态代理的分析原理机制
- Java 并发集合的实现原理详解编程语言
- Java线程池实现原理详解编程语言
- 如何使用Java连接MySQL数据库(java怎么连接mysql数据库)
- Java实现MSSQL数据库连接(java连接mssql)
- 开发开创Linux更美好的Java开发环境(linux集成java)
- Redis Java过期机制实现原理及应用(redisjava过期)
- 使用Java实现Redis数据存储(redis集成java)
- 数据处理Java实现Redis过期数据处理(redisjava过期)
- Java–读写锁的实现原理
- Java编程实现MySQL表备份(java备份mysql表)
- 实现Java实现Redis锁的研究与应用(redis锁java)
- 程序Oracle调用Java程序的实现方法(oracle调用java)
- Java操作Redis实现数据快速存取(java访问redis)
- 使用Java连接SQL Server数据库,轻松实现数据交互(java连sqlserver)
- 管理Linux下Java版本管理:轻松实现多版本切换(linux下java版本)
- 编程Oracle数据库中实现Java编程的突破之道(oracle使用java)
- Redis面试中Java相关技术面试题汇总(redis面试题java)
- 使用Java实现Redis锁定的实现(redis锁定 java)