
【机器学习实战】11、利用SVD简化数据
文章目录
###14.1 SVD的应用
餐馆可以划分为很多类别,比如中式、美式、快餐、素食等等,但是人们可以喜欢某些混合的类别,比如中式素食的子类别,我们可以对记录用户关于餐馆观点的数据进行处理,并且从中提取背后的因素,这些因素可能与类别、配料或其他任意对象一致。
提取这些信息的方法称为奇异值分解(Singular Value Decomposition,SVD)。

作用:能够用小得多的数据集来表示原始数据集
原理:去除了噪声和冗余信息,也就是从噪声数据中抽取信息。
14.1.1 隐形语义索引
SVD最早的应用之一就是信息检索,称为隐形语义索引(Latent Semantic Indexing,LSI)或隐形语义分析(Latent Semantic Analysis,LSA)。
LSI中,一个矩阵是由文档和词语组成的,当在该矩阵上应用SVD时,就会构建多个奇异值,这些奇异值代表了文档中的概念或者主题,这一特点可以用于更高效的文档搜索。
14.1.2 推荐系统
SVD的另一个应用就是推荐系统。 先利用SVD从数据中构建一个主题空间, 然后在该主题空间下计算相似度。
上述矩阵由餐馆的菜和品菜师对这些菜的意见构成的。品菜师采用1到5之间的任意一个整数来对菜评级,如果品菜师没有尝过某道菜,则评级为0。对上述矩阵进行SVD分解,会得到两个奇异值(注意其特征值位2),也即仿佛有两个概念或主题与此数据集相关联。


SVD是矩阵分解的一种类型,而矩阵分解时将数据矩阵分解为多个独立部分的过程,下面首先介绍矩阵分解。
14.2 矩阵分解(SVD矩阵分解)
在很多情况下,数据中的一小段携带了数据集中的大部分信息,其他信息则要么是噪声,要么就是毫不相关的信息。在线性代数中还有很多矩阵分解技术。 矩阵分解可以将原始矩阵表示成新的易于处理的形式。
SVD将原始数据集矩阵 D a t a m ∗ n Data_{m*n} Datam∗n分解为三个矩阵:
矩阵 Σ \Sigma Σ:
1)只有对角元素(也称奇异值),其他元素均为0
2)对角元素是从大到小排列的
3)奇异值就是矩阵
D
a
t
a
∗
D
a
t
a
T
Data*Data^T
Data∗DataT特征值的平方根
在某个奇异值(r个)之后, 其它的奇异值由于值太小,被忽略置为0, 这就意味着数据集中仅有r个重要特征,而其余特征都是噪声或冗余特征。如下图所示:

如何选择数值r?
解答: 确定要保留的奇异值数目有很多启发式的策略,其中一个典型的做法就是保留矩阵中90%的能量信息.为了计算能量信息,将所有的奇异值求其平方和,从大到小叠加奇异值,直到奇异值之和达到总值的90%为止;另一种方法是,当矩阵有上万个奇异值时, 直接保留前2000或3000个.,但是后一种方法不能保证前3000个奇异值能够包含钱90%的能量信息,但是操作简单.
SVD分解很耗时,通过离线方式计算SVD分解和相似度计算,是一种减少冗余计算和推荐所需时间的办法.
14.3 利用python实现SVD
Numpy的linalg的线性代数工具箱来实现,其有包括处理求范式、逆、行列式、伪逆、秩、qr分解、svd分解等等函数。
from numpy import *
from numpy import linalg as la
def loadExData():
return [[1,1,1,0,0],
[2,2,2,0,0],
[5,5,5,0,0],
[1,1,0,2,2],
[0,0,0,3,3],
[0,0,0,1,1]]
Data=loadExData()
U,Sigma,VT=la.svd(Data)
#由于Sigma是以向量的形式存储,故需要将其转为矩阵,
sig3=mat([[Sigma[0],0,0],[0,Sigma[1],0],[0,0,Sigma[2]]])
# 也可以用下面的方法,将行向量转化为矩阵,并且将值放在对角线上,取前面三行三列
# Sig3=diag(Sigma)[:3,:3]
print(Sigma)
#重构原始矩阵
print(U[:,:3]*sig3*VT[:3,:])
结果:
U:
[[ -1.80802750e-01 -1.71990790e-02 1.86518261e-02 9.66314851e-01
1.32410225e-01 -1.23975026e-01]
[ -3.61605500e-01 -3.43981580e-02 3.73036522e-02 -2.19496756e-01
8.71711981e-01 -2.42086892e-01]
[ -9.04013750e-01 -8.59953949e-02 9.32591306e-02 -1.05464268e-01
-3.75166837e-01 1.21629762e-01]
[ -1.36839850e-01 5.33014079e-01 -8.34967572e-01 -7.16304166e-16
-3.46093235e-16 2.46957870e-16]
[ -2.29617316e-02 7.97696413e-01 5.12984591e-01 -2.63326233e-02
-9.04630306e-02 -3.01865919e-01]
[ -7.65391052e-03 2.65898804e-01 1.70994864e-01 7.89978699e-02
2.71389092e-01 9.05597757e-01]]
Sigma:
[ 9.56627891e+00 5.29323150e+00 6.84111192e-01 3.10730143e-16
4.98171926e-32]
VT:
[[ -5.81304643e-01 -5.81304643e-01 -5.67000247e-01 -3.66097214e-02
-3.66097214e-02]
[ 3.21952849e-03 3.21952849e-03 -9.74777636e-02 7.03731964e-01
7.03731964e-01]
[ -4.02584831e-01 -4.02584831e-01 8.17929585e-01 5.84897501e-02
5.84897501e-02]
[ 7.07106781e-01 -7.07106781e-01 5.19776737e-17 1.98940359e-17
1.98940359e-17]
[ -0.00000000e+00 1.80770896e-17 -1.42706714e-17 7.07106781e-01
-7.07106781e-01]]
sig3 :
[[ 9.56627891 0. 0. ]
[ 0. 5.2932315 0. ]
[ 0. 0. 0.68411119]]
重构矩阵(和原始矩阵非常接近):
[[ 1.00000000e+00 1.00000000e+00 1.00000000e+00 -9.14152286e-16
-9.14152286e-16]
[ 2.00000000e+00 2.00000000e+00 2.00000000e+00 -3.49477979e-16
-3.49477979e-16]
[ 5.00000000e+00 5.00000000e+00 5.00000000e+00 6.09916192e-16
6.09916192e-16]
[ 1.00000000e+00 1.00000000e+00 2.79971461e-16 2.00000000e+00
2.00000000e+00]
[ -6.37559172e-17 5.31300838e-17 2.94979631e-16 3.00000000e+00
3.00000000e+00]
[ -4.45609774e-17 -5.59897708e-18 1.68959598e-16 1.00000000e+00
1.00000000e+00]]
重构矩阵和原始矩阵非常接近,类似于压缩图像,只保留图像分解后的两个方阵和一个对角阵的对角元素,就可以恢复原始图像。
观察上述结果中的Sigma,可以发现前三个数值比后面两个大了很多,于是可以将后面两个值去掉。
原始数据集就和下面结果近似:
###14.4 基于协同过滤(collaborative filtering)的推荐引擎
近些年来,推荐引擎对因特网用户而言已经不是什么新鲜事物了,Amazon会根据顾客的购买历史向他们推荐物品,新闻网站会对用户推荐新闻报道等。
接下来我们介绍被称为“协同过滤”的方法,来实现推荐功能。协同过滤是通过将用户和其他用户的数据进行对比来实现推荐的。
数据组织成了类似图14-2所给出的矩阵的形式,当数据采用这种方式进行组织时,我们就可以比较用户或物品之间的相似度了,当知道相似度后,就可以利用已有的数据来预测未知用户喜好。
例如: 试图对某个用户喜欢的电影进行预测,搜索引擎会发现有一部电影该用户还没看过,然后它会计算该电影和用户看过的电影之间的相似度, 如果相似度很高, 推荐算法就会认为用户喜欢这部电影.
缺点: 在协同过滤情况下, 由于新物品到来时由于缺乏所有用户对其的喜好信息,因此无法判断每个用户对其的喜好.而无法判断某个用户对其的喜好,也就无法利用该商品.
14.4.1 相似度计算
不利用专家给出的重要属性来描述物品从而计算其相似度,而是利用用户对他们的意见来计算相似度,这就是协同过滤使用的方法。并不关心物品的描述属性,而是严格按照许多用户的观点来计算相似度。
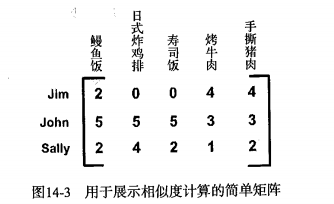
一、欧氏距离
手撕猪肉和烤牛肉间的欧氏距离:
手撕猪肉和鳗鱼饭的欧氏距离:
因此手撕猪肉和烤牛肉更为相似
相似性度量方式: 0~1之间的变化,可以使用 相似度 = 1 1 + 距离 相似度=\frac{1}{1+距离} 相似度=1+距离1来度量,距离为0时,相似度为1,距离很大时,相似度趋于0。
二、皮尔逊相关系数(person correlation)
度量两个向量之间的相似度,相对于欧式距离的优势在于对用户评级的量级并不敏感。
Numpy中实现:corrcoef()
取值范围:[-1,1],通过 0.5 + 0.5 ∗ c o r r c o e f ( ) 0.5+0.5*corrcoef() 0.5+0.5∗corrcoef()函数来计算,将其取值范围归一化到[0,1]。
三、余弦相似度(cosine similarity)
度量两个向量夹角的余弦值,如果夹角为90°,则相似度为0,如果两个向量方向相同,相似度为1。
取值范围:[-1,+1],因此也需要将其归一化到(0,1)之间。
定义: c o s θ = A ⋅ B ∣ ∣ A ∣ ∣ ∣ ∣ B ∣ ∣ cos\theta=\frac{A\cdot B}{||A|| ||B||} cosθ=∣∣A∣∣∣∣B∣∣A⋅B
其中, ∣ ∣ A ∣ ∣ ||A|| ∣∣A∣∣、 ∣ ∣ B ∣ ∣ ||B|| ∣∣B∣∣表示向量的2范数,例如向量 [ 4 , 2 , 2 ] [4,2,2] [4,2,2]的2范数为 4 2 + 2 2 + 2 2 \sqrt{4^2+2^2+2^2} 42+22+22
Numpy中,范数的计算方法:linalg.norm()
2范数=x到0点的欧氏距离
其他距离:
代码实现:

#!/usr/bin/env python
# coding=utf-8
from numpy import *
from numpy import linalg as la
def loadExData():
return [[1,1,1,0,0],
[2,2,2,0,0],
[5,5,5,0,0],
[1,1,0,2,2],
[0,0,0,3,3],
[0,0,0,1,1]]
# 利用不同的方法计算相似度
def eulidSim(inA, inB):
return 1.0/(1.0+la.norm(inA - inB))#根据欧式距离计算相似度
def pearsSim(inA, inB):
if len(inA)<3:
return 1.0
else:
return 0.5+0.5*corrcoef(inA, inB, rowvar = 0)[0][1]
def cosSim(inA, inB):
num = float(inA.T*inB) #向量inA和向量inB点乘,得cos分子
denom = la.norm(inA)*la.norm(inB) #向量inA,inB各自范式相乘,得cos分母
return 0.5+0.5*(num/denom) #从-1到+1归一化到[0,1]
myMat = mat(loadExData())
print(eulidSim(myMat[:,0], myMat[:,4])) #第一行和第五行利用欧式距离计算相似度
print(eulidSim(myMat[:,0], myMat[:,0])) #第一行和第一行欧式距离计算相似度
print(cosSim(myMat[:,0], myMat[:,4])) #第一行和第五行利用cos距离计算相似度
print(cosSim(myMat[:,0], myMat[:,0])) #第一行和第一行利用cos距离计算相似度
print(pearsSim(myMat[:,0], myMat[:,4])) #第一行和第五行利用皮尔逊距离计算相似度
print(pearsSim(myMat[:,0], myMat[:,0])) #第一行和第一行利用皮尔逊距离计算相似度
结果(相似度):
0.135078105936
1.0
0.548001536074
1.0
0.204196010845
1.0
14.4.2 基于物品的相似度还是基于用户的相似度?
菜肴之间的距离:基于物品(item-based)的相似度
用户之间的距离:基于用户(user-based)的相似度
行与行之间比较的是基于用户的相似度,列与列之间比较的则是基于物品的相似度。
基于物品相似度计算的时间会随物品数量的增加而增加,基于用户的相似度计算的时间则会随用户数量的增加而增加。如果用户的数目很多,那么我们可能倾向于使用基于物品相似度的计算方法。对于大部分产品导向的推荐系统而言,用户的数量往往大于物品的数量,即购买商品的用户数会多于出售的商品种类。
14.4.3 推荐引擎的评价
使用交叉测试的方法,具体做法就是我们将某些已知的评分值去掉,然后对它们进行预测,最后计算预测值与真实值之间的差异。通常使用的指标为最小均方根误差(Root Mean Squared Error, RMSE)。
14.5 示例:餐馆菜肴推荐系统
假设他不知道去哪里吃饭,该点什么菜,则我们的系统可以推荐给他。
步骤:
1)构建一个基本引擎,能够寻找用户没有品尝过的菜肴
2)通过SVD来减少特征空间,并提高推荐效果
3)将程序打包并通过用户可读的人机界面提供给人们使用
14.5.1 推荐未尝过的菜肴
过程:
给定一个用户,系统会为此用户返回N个最好的推荐菜。需要:
- 寻找用户没有评级的菜肴,即在用户-物品矩阵中的0值。
- 在用户没有评级的所有物品中,对每个物品预计一个可能的评级分数。
- 对这些物品的评分从高到低进行排序,返回前N个物品。
from numpy import *
from numpy import linalg as la
def loadExData():
return [[1,1,1,0,0],
[2,2,2,0,0],
[5,5,5,0,0],
[1,1,0,2,2],
[0,0,0,3,3],
[0,0,0,1,1]]
# 利用不同的方法计算相似度
def eulidSim(inA, inB):
return 1.0/(1.0+la.norm(inA - inB))#根据欧式距离计算相似度
def pearsSim(inA, inB):
if len(inA)<3:
return 1.0
else:
return 0.5+0.5*corrcoef(inA, inB, rowvar = 0)[0][1]
def cosSim(inA, inB):
num = float(inA.T*inB) #向量inA和向量inB点乘,得cos分子
denom = la.norm(inA)*la.norm(inB) #向量inA,inB各自范式相乘,得cos分母
return 0.5+0.5*(num/denom) #从-1到+1归一化到[0,1]
def standEst(dataMat,user,simMeas,item):
"""
计算在给定相似度计算方法的前提下,用户对物品的估计评分值
:param dataMat: 数据矩阵
:param user: 用户编号
:param simMeas: 相似性度量方法
:param item: 物品编号
:return:
"""
#数据中行为用于,列为物品,n即为物品数目
n=shape(dataMat)[1]
simTotal=0.0
ratSimTotal=0.0
#用户的第j个物品
for j in range(n):
userRating=dataMat[user,j]
if userRating==0:
continue
#寻找两个用户都评级的物品
overLap=nonzero(logical_and(dataMat[:,item].A>0,dataMat[:,j].A>0))[0]
if len(overLap)==0:
similarity=0
else:
similarity=simMeas(dataMat[overLap,item],dataMat[overLap,j])
simTotal+=similarity
ratSimTotal+=simTotal*userRating
if simTotal==0:
return 0
else:
return ratSimTotal/simTotal
def recommend(dataMat,user,N=3,simMeas=cosSim,estMethod=standEst):
"""
推荐引擎,会调用standEst()函数
:param dataMat: 数据矩阵
:param user: 用户编号
:param N:前N个未评级物品预测评分值
:param simMeas:
:param estMethod:
:return:
"""
#寻找未评级的物品,nonzeros()[1]返回参数的某些为0的列的编号,dataMat中用户对某个商品的评价为0的列
#矩阵名.A:将矩阵转化为array数组类型
#nonzeros(a):返回数组a中不为0的元素的下标
unratedItems=nonzero(dataMat[user,:].A==0)[1]
if len(unratedItems)==0:
return 'you rated everything!'
itemScores=[]
for item in unratedItems:
estimatedScore=estMethod(dataMat,user,simMeas,item)
itemScores.append((item,estimatedScore))
return sorted(itemScores,key=lambda jj:jj[1],reverse=True)[:N]
myMat = mat(loadExData())
myMat[0,3] = myMat[0,4] = myMat[1,4] = myMat[2,3] = 4
myMat[4,1] = 2
print(myMat)
print(recommend(myMat, 4))
print(recommend(myMat, 4,simMeas = eulidSim))
print(recommend(myMat, 4,simMeas = pearsSim))
结果:
[[1 1 1 4 4]
[2 2 2 0 4]
[5 5 5 4 0]
[1 1 0 2 2]
[0 2 0 3 3]
[0 0 0 1 1]]
[(2, 5.6806547361770336), (0, 5.6789547243533818)]
[(0, 6.9478362016501283), (2, 6.9253660746962069)]
[(0, 5.9000000000000004), (2, 5.666666666666667)]
我们可知:
用户4对物品2的预测评分值为5.6806547361770336;
用户4对物品0的预测评分值为5.6789547243533818;
14.5.2 利用SVD提高推荐效果
下面展示一个更加真实的矩阵的例子:

from numpy import *
from numpy import linalg as la
def loadExData2():
return [[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
U, Sigma, VT = la.svd(mat(loadExData2()))
print('Sigma:\n',Sigma)
#查看到底多少个奇异值能够达到总能量的90%
#对Sigma求平方
Sig2 = Sigma ** 2
print('Sig2:\n',Sig2)
#计算总能量(542.0)
print('sum(Sig2):',sum(Sig2))
#计算总能量的90%(487.8)
print('sum(Sig2) * 0.9:',sum(Sig2) * 0.9)
#计算前两个元素包含的能量(378.829559511)
print('前两个元素包含的能量:',sum(Sig2[:2]))
#由于前两个的和未达到总和的90%,所以计算前三个的和
print('前三个元素包含的能量:',sum(Sig2[:3]))
结果:
Sigma:
[ 15.77075346 11.40670395 11.03044558 4.84639758 3.09292055
2.58097379 1.00413543 0.72817072 0.43800353 0.22082113
0.07367823]
Sig2:
[ 2.48716665e+02 1.30112895e+02 1.21670730e+02 2.34875695e+01
9.56615756e+00 6.66142570e+00 1.00828796e+00 5.30232598e-01
1.91847092e-01 4.87619735e-02 5.42848136e-03]
sum(Sig2): 542.0
sum(Sig2) * 0.9: 487.8
前两个元素包含的能量: 378.829559511
前三个元素包含的能量: 500.500289128
前三个元素包含的能量超过了总能量的90%,故可以将这11维矩阵转化为3维矩阵,对转化后的三维空间构造一个相似度计算函数,利用SVD将所有的菜肴映射到一个低维空间。
from numpy import *
from numpy import linalg as la
def loadExData2():
return [[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
# 利用不同的方法计算相似度
def eulidSim(inA, inB):
return 1.0/(1.0+la.norm(inA - inB))#根据欧式距离计算相似度
def pearsSim(inA, inB):
if len(inA)<3:
return 1.0
else:
return 0.5+0.5*corrcoef(inA, inB, rowvar = 0)[0][1]
def cosSim(inA, inB):
num = float(inA.T*inB) #向量inA和向量inB点乘,得cos分子
denom = la.norm(inA)*la.norm(inB) #向量inA,inB各自范式相乘,得cos分母
return 0.5+0.5*(num/denom) #从-1到+1归一化到[0,1]
def standEst(dataMat,user,simMeas,item):
"""
计算在给定相似度计算方法的前提下,用户对物品的估计评分值
:param dataMat: 数据矩阵
:param user: 用户编号
:param simMeas: 相似性度量方法
:param item: 物品编号
:return:
"""
#数据中行为用于,列为物品,n即为物品数目
n=shape(dataMat)[1]
simTotal=0.0
ratSimTotal=0.0
#用户的第j个物品
for j in range(n):
userRating=dataMat[user,j]
if userRating==0:
continue
#寻找两个用户都评级的物品
overLap=nonzero(logical_and(dataMat[:,item].A>0,dataMat[:,j].A>0))[0]
if len(overLap)==0:
similarity=0
else:
similarity=simMeas(dataMat[overLap,item],dataMat[overLap,j])
simTotal+=similarity
ratSimTotal+=simTotal*userRating
if simTotal==0:
return 0
else:
return ratSimTotal/simTotal
def recommend(dataMat,user,N=3,simMeas=cosSim,estMethod=standEst):
"""
推荐引擎,会调用standEst()函数
:param dataMat: 数据矩阵
:param user: 用户编号
:param N:前N个未评级物品预测评分值
:param simMeas:
:param estMethod:
:return:
"""
#寻找未评级的物品,nonzeros()[1]返回参数的某些为0的列的编号,dataMat中用户对某个商品的评价为0的列
#矩阵名.A:将矩阵转化为array数组类型
#nonzeros(a):返回数组a中不为0的元素的下标
unratedItems=nonzero(dataMat[user,:].A==0)[1]
if len(unratedItems)==0:
return 'you rated everything!'
itemScores=[]
for item in unratedItems:
estimatedScore=estMethod(dataMat,user,simMeas,item)
itemScores.append((item,estimatedScore))
return sorted(itemScores,key=lambda jj:jj[1],reverse=True)[:N]
#======================基于SVD的评分估计==========================
def SVDEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0
ratSimTotal = 0.0
U, Sigma, VT = la.svd(dataMat)
Sig4 = mat(eye(4)*Sigma[:4]) #化为对角阵,或者用linalg.diag()函数可破
xformedItems = dataMat.T*U[:,:4]*Sig4.I#构造转换后的物品
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j == item:
continue
similarity = simMeas(xformedItems[item,:].T, xformedItems[j, :].T)
print("the %d and %d similarity is: %f" %(item,j,similarity))
simTotal += similarity
ratSimTotal += similarity*userRating
if simTotal ==0 :
return 0
else:
return ratSimTotal/simTotal
myMat = mat(loadExData2())
print(recommend(myMat, 1, estMethod = SVDEst))
print(recommend(myMat, 1, estMethod = SVDEst, simMeas = pearsSim))
结果:
the 0 and 3 similarity is: 0.490950
the 0 and 5 similarity is: 0.484274
the 0 and 10 similarity is: 0.512755
the 1 and 3 similarity is: 0.491294
the 1 and 5 similarity is: 0.481516
the 1 and 10 similarity is: 0.509709
the 2 and 3 similarity is: 0.491573
the 2 and 5 similarity is: 0.482346
the 2 and 10 similarity is: 0.510584
the 4 and 3 similarity is: 0.450495
the 4 and 5 similarity is: 0.506795
the 4 and 10 similarity is: 0.512896
the 6 and 3 similarity is: 0.743699
the 6 and 5 similarity is: 0.468366
the 6 and 10 similarity is: 0.439465
the 7 and 3 similarity is: 0.482175
the 7 and 5 similarity is: 0.494716
the 7 and 10 similarity is: 0.524970
the 8 and 3 similarity is: 0.491307
the 8 and 5 similarity is: 0.491228
the 8 and 10 similarity is: 0.520290
the 9 and 3 similarity is: 0.522379
the 9 and 5 similarity is: 0.496130
the 9 and 10 similarity is: 0.493617
[(4, 3.3447149384692283), (7, 3.3294020724526971), (9, 3.328100876390069)]
the 0 and 3 similarity is: 0.341942
the 0 and 5 similarity is: 0.124132
the 0 and 10 similarity is: 0.116698
the 1 and 3 similarity is: 0.345560
the 1 and 5 similarity is: 0.126456
the 1 and 10 similarity is: 0.118892
the 2 and 3 similarity is: 0.345149
the 2 and 5 similarity is: 0.126190
the 2 and 10 similarity is: 0.118640
the 4 and 3 similarity is: 0.450126
the 4 and 5 similarity is: 0.528504
the 4 and 10 similarity is: 0.544647
the 6 and 3 similarity is: 0.923822
the 6 and 5 similarity is: 0.724840
the 6 and 10 similarity is: 0.710896
the 7 and 3 similarity is: 0.319482
the 7 and 5 similarity is: 0.118324
the 7 and 10 similarity is: 0.113370
the 8 and 3 similarity is: 0.334910
the 8 and 5 similarity is: 0.119673
the 8 and 10 similarity is: 0.112497
the 9 and 3 similarity is: 0.566918
the 9 and 5 similarity is: 0.590049
the 9 and 10 similarity is: 0.602380
[(4, 3.3469521867021736), (9, 3.3353796573274703), (6, 3.307193027813037)]
14.5.3 构建推荐引擎面临的挑战


14.6 基于SVD的图像压缩
本节使用手写体“0”来展开SVD对图像的压缩,原始图像大小为32*32=1024,进行图像压缩以后,就可以节省空间或带宽开销了。
代码:
from numpy import *
from numpy import linalg as la
def printMat(inMat,thresh=0.8):
"""
打印矩阵
:param inMat:输入数据集
:param thresh:阈值
:return:
"""
#由于矩阵包含了浮点数,因此必须定义深色和浅色,通过阈值来界定
#元素大于阈值,打印1,小于阈值,打印0
for i in range(32):
for k in range(32):
if float(inMat[i,k])>thresh:
print(1),
else:
print(0),
print('')
def imgCompress(numSV=3,thresh=0.8):
"""
实现图像的压缩,允许基于任意给定的奇异值数目来重构图像
:param numSV:
:param thresh:
:return:
"""
#构建列表
myl=[]
#打开文本文件,从文件中以数值方式读入字符
for line in open("0_5.txt").readlines():
newRow=[]
for i in range(32):
newRow.append(int(line[i]))
myl.append(newRow)
myMat=mat(myl)
print("******original matrix**********")
#使用SVD对图像进行SVD分解和重构
printMat(myMat,thresh)
U,Sigma,VT=la.svd(myMat)
#建立一个全0矩阵
SigRecon=mat(zeros((numSV,numSV)))
#将奇异值填充到对角线
for k in range(numSV):
SigRecon[k,k]=Sigma[k]
#重构矩阵
reconMat=U[:,:numSV]*SigRecon*VT[:numSV,:]
print("***reconstructed matrix using %d singular values***" %numSV)
printMat(reconMat,thresh)
if __name__=='__main__':
imgCompress(2)
只需要两个奇异值就能相当精确地对图像实现重构,U和VT都是32×2的矩阵,有两个奇异值,也即只需要32×2+2+32×2=130个0、1进行存储。原来需要1024个0、1,几乎获得10倍的压缩比。
14.7 总结
SVD是一种强大的降维工具,可以利用SVD来逼近矩阵并从中提取重要特征,保留矩阵80%-90%的能量,得到重要的特征去掉噪音。推荐系统为SVD的一个成功的应用,协同过滤则是一种基于用户喜好或行为数据的推荐的实现方法。协同过滤的核心是相似度计算方法。
大规模数据集上,SVD的计算和推荐可能是一个很困难的工程问题,通过离线的方式来进行SVD分解和相似度计算,是一种减少冗余计算和推荐所需时间的办法。
相关文章
- 机器学习中的范数规则化
- 浅析机器学习的主题模型和语义分析
- 大话机器学习之数据预处理与数据筛选
- 细思极恐!大数据和机器学习揭示十二星座的真实面目
- 机器学习、数据挖掘、人工智能、统计模型这么多概念有何差异
- 机器学习、数据挖掘、人工智能、统计模型这么多概念有何差异
- 数据分析/机器学习模型无法部署的八大原因
- 机器学习笔记:常用数据集之scikit-learn内置玩具数据集
- 机器学习笔记 - 使用TensorFlow进行音乐生成
- 机器学习笔记 - tensorflow 2.8版本不同优化器对比
- 机器学习笔记 - 使用Streamlit探索对象检测数据集
- 机器学习笔记 - 灰狼优化
- 机器学习笔记 - HaGRID—手势识别图像数据集简介
- ML:MLOps系列讲解之《CRISP-ML (Q)ML生命周期过程—了解机器学习开发的标准过程模型—业务和数据理解→数据工程(数据准备)→ML模型工程→评估ML模型→模型部署→模型监控和维护》解读
- AI之FL:联邦学习(Federated Learning,分布式机器学习技术)的分类详解(纵向联邦学习/横向联邦学习)、使用方法、实战案例之详细攻略
- Py之scikit-learn:机器学习sklearn库的简介、六大基本功能介绍(数据预处理/数据降维/模型选择/分类/回归/聚类)、安装、使用方法(实际问题中如何选择最合适的机器学习算法)之详细攻略
- Python之GUI:基于Python的GUI界面设计的一套AI课程学习(机器学习、深度学习、大数据、云计算等)推荐系统(包括语音生成、识别等前沿黑科技)
- ML之DataScience:基于机器学习处理数据科学(DataScience)任务(数据分析、特征工程、科学预测等)的简介、流程、案例应用执行详细攻略
- ML之回归预测:利用13种机器学习算法对Boston(波士顿房价)数据集【13+1,506】进行回归预测(房价预测)来比较各模型性能
- ML之DT:机器学习根据大量数据,已知年龄、收入、是否上海人、私家车价格的一个人,预测是否有真实购买上海黄浦区楼房的能力
- 结合Java和机器学习技术,如何驾驭大数据提升业务效率和竞争力?
- 【go 科学计算】用于统计、机器学习和数据操作
- 跳出数据计算拯救人工智能之打败机器学习方法
- 【ML】拆分数据集以进行机器学习
- 【阶段三】Python机器学习11篇:机器学习项目实战:KNN(K近邻)回归模型
- 【机器学习】医学图像处理:ABIDE数据集下载
- 【机器学习项目实战】数据相关岗位薪资水平影响因素研究分析
- 【机器学习】Python详细实现基于欧式Euclidean、切比雪夫Chebyshew、曼哈顿Manhattan距离的Kmeans聚类
- 转行入职数据科学(数据分析挖掘,机器学习方向)需要的硬技能。
- 【ML on Kubernetes】第 4 章:机器学习平台剖析
- PAI-Diffusion模型来了!阿里云机器学习团队带您徜徉中文艺术海洋