
利用Python做假设检验、参数估计、方差分析、线性回归
Python 利用 回归 线性 方差分析
2023-09-14 09:14:03 时间
目录
参数估计
方差比的置信区间
import numpy as np
from scipy.stats import f
# 定义一个实现方差比置信区间的函数
def var_ratio_ci_est(data1,data2,alpha):
n1 = len(data1) # 样本1的样本容量
n2 = len(data2) # 样本2的样本容量
f_lower_value = f.ppf(alpha/2,n1-1,n2-1) # 左侧临界值
f_upper_value = f.ppf(1-alpha/2,n1-1,n2-1) # 右侧临界值
var_ratio = np.var(data1) / np.var(data2)
return var_ratio / f_upper_value,var_ratio / f_lower_value
salary_18 = [1484, 785, 1598, 1366, 1716, 1020, 1716, 785, 3113, 1601]
salary_35 = [902, 4508, 3809, 3923, 4276, 2065, 1601, 553, 3345, 2182]
print(var_ratio_ci_est(salary_18,salary_35,0.05))(0.05314530971751432, 0.8614126063098585)均值差的置信区间
import numpy as np
from scipy.stats import t
# 两个正态总体均值差的置信区间
def mean_diff_ci_t_est(data1,data2,alpha,equal=True):
n1 = len(data1) # 样本1的样本容量
n2 = len(data2) # 样本2的样本容量
mean_diff = np.mean(data1) - np.mean(data2) # 两个样本的均值差(两个总体均值差的无偏点估计)
sample1_var = np.var(data1) # 样本1的方差
sample2_var = np.var(data2) # 样本2的方差
if equal: # 方差未知且相等
sw = np.sqrt(((n1-1)*sample1_var + (n2-1)*sample2_var) / (n1+n2-2))
t_value = np.abs(t.ppf(alpha/2,n1+n2-2)) # t值
return mean_diff - sw*np.sqrt(1/n1+1/n2)*t_value, \
mean_diff + sw*np.sqrt(1/n1+1/n2)*t_value
else: # 方差未知且不等
df_numerator = (sample1_var/n1+sample2_var/n2)**2 # 自由度分子
# 自由度分母
df_denominator = (sample1_var/n1)**2/(n1-1) + (sample2_var/n2)**2/(n2-1)
df = df_numerator / df_denominator # 自由度
t_value = np.abs(t.ppf(alpha/2,df))
return mean_diff - np.sqrt(sample1_var/n1 + sample2_var/n2)*t_value, \
mean_diff + np.sqrt(sample1_var/n1 + sample2_var/n2)*t_value
salary_18 = [1484, 785, 1598, 1366, 1716, 1020, 1716, 785, 3113, 1601]
salary_35 = [902, 4508, 3809, 3923, 4276, 2065, 1601, 553, 3345, 2182]
print(mean_diff_ci_t_est(salary_18,salary_35,0.05,equal=True)) # 方差相等
print(mean_diff_ci_t_est(salary_18,salary_35,0.05,equal=False)) # 方差不等(-2196.676574582891, -199.32342541710875)
(-2227.5521493017823, -168.4478506982175)一个正态总体方差的点估计和置信区间
import numpy as np
from scipy.stats import chi2
# 定义计算方差的置信区间的函数
def var_ci_est(data,alpha):
n = len(data) # 样本容量
s2 = np.var(data) # 样本方差
# chi2.ppf(alpha/2,n-1)的意思是返回左侧面积为alpha/2的卡方值
chi2_lower_value = chi2.ppf(alpha/2,n-1)
# # chi2.ppf(1-alpha/2,n-1)的意思是返回左侧面积为1-alpha/2的卡方值
chi2_upper_value = chi2.ppf(1-alpha/2,n-1)
return (n-1) * s2 / chi2_upper_value,(n-1) * s2 / chi2_lower_value
salary_18 = [1484, 785, 1598, 1366, 1716, 1020, 1716, 785, 3113, 1601]
salary_35 = [902, 4508, 3809, 3923, 4276, 2065, 1601, 553, 3345, 2182]
# 样本方差是总体方差的无偏点估计,再调用函数计算方差的置信区间
print(np.std(salary_18),np.var(salary_18),var_ci_est(salary_18,0.05))
print(np.std(salary_35),np.var(salary_35),var_ci_est(salary_35,0.05))631.0754629994736 398256.24 (188421.9056837747, 1327329.3204650925)
1364.3074580167038 1861334.8399999999 (880629.6611156773, 6203554.546528138)一个正态总体均值的点估计和置信区间
import numpy as np
from scipy.stats import norm, t
# 计算一个正态总体均值的置信区间的函数
def mean_ci_est(data,alpha,sigma=None):
n = len(data) # 样本容量
sample_mean = np.mean(data) # 样本均值
if sigma is None: # 方差未知的情况
s = np.std(data)
se = s / np.sqrt(n)
# t.ppf(alpha / 2,n-1)返回的是左侧面积为alpha / 2对应的t值
t_value = np.abs(t.ppf(alpha / 2,n-1))
# 根据公式返回置信区间
return sample_mean - se * t_value,sample_mean + se * t_value
else: # 方差已知的情况
se = sigma / np.sqrt(n) # 标准误
# norm.ppf(alpha / 2)返回的是左侧面积为alpha / 2对应的z值
z_value = np.abs(norm.ppf(alpha / 2))
# 根据公式返回置信区间
return sample_mean - se * z_value,sample_mean + se * z_value
salary_18 = [1484, 785, 1598, 1366, 1716, 1020, 1716, 785, 3113, 1601]
salary_35 = [902, 4508, 3809, 3923, 4276, 2065, 1601, 553, 3345, 2182]
# 样本均值是总体均值的无偏点估计,并调用函数计算均值的置信区间
print(np.mean(salary_18),mean_ci_est(salary_18,0.05))
print(np.mean(salary_35),mean_ci_est(salary_35,0.05))1518.4 (1066.9558093661096, 1969.8441906338905)
2716.4 (1740.433238065152, 3692.366761934848)假设检验
初始化设置
import pandas as pd
import scipy.stats as ss
import matplotlib
# 解决绘图的兼容问题
%matplotlib inline
matplotlib.rcParams['font.sans-serif'] = ['SimHei']单样本t检验的SciPy实现方式
ccss = pd.read_excel("CCSS_sample.xlsx",sheet_name="CCSS") # 读取Excel文件中名称为CCSS的表单
ccss.head()
# 广州基期的消费信心指数的描述统计
ccss.query("s0 == '广州' & time == 203004" ).index1.describe()
from scipy import stats as ss
# 单样本t检验
ss.ttest_1samp(ccss.query("s0 == '广州' & time == 203004" ).index1,100)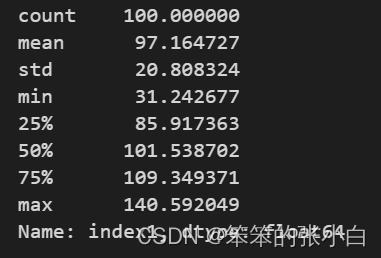
Ttest_1sampResult(statistic=-1.3625667518512996, pvalue=0.17611075148299993)我们可以看出P值大于0.05,接受H0,没有显著性差异
单样本t检验的statsmodels实现方式
from statsmodels.stats import weightstats as ws
des = ws.DescrStatsW(ccss.query("s0 == '广州' & time == 203004").index1)
des.mean97.16472701710536# 置信水平为95%的置信区间(可信区间)
des.tconfint_mean()(93.03590418536487, 101.29354984884586)# 单样本t检验
des.ttest_mean(100)(-1.3625667518512996, 0.17611075148299993, 99.0)
我们可以看出P值大于0.05,接受H0,没有显著性差异
两样本t检验SciPy的实现方式
from scipy import stats as ss
# 消费的信心指数分布的对称性考察
ccss.index1.plot.hist()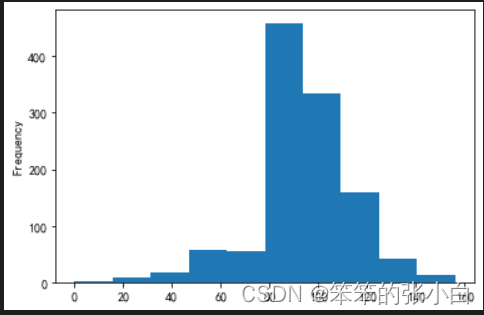
# 不同婚姻状况的消费信心指数分组描述
ccss.groupby('s7').index1.describe()
# 方差齐性检验
ss.levene(ccss.index1[ccss.s7 == '未婚'],ccss.index1[ccss.s7 == '已婚'])LeveneResult(statistic=0.6178738290825966, pvalue=0.4320031337363959)# 两样本t检验(方差齐性)
ss.ttest_ind(ccss.index1[ccss.s7 == '未婚'],ccss.index1[ccss.s7 == '已婚'])Ttest_indResult(statistic=2.4052614244262576, pvalue=0.01632071963816213)# 两样本t检验(方差不齐性)
ss.ttest_ind(ccss.index1[ccss.s7 == '未婚'],ccss.index1[ccss.s7 == '已婚'],
equal_var=False)Ttest_indResult(statistic=2.466907208318663, pvalue=0.013870358702526698)两样本t检验statsmodels的实现方式
from statsmodels.stats import weightstats as ws
d1 = ws.DescrStatsW(ccss.index1[ccss.s7 == '未婚']) # 未婚的消费信心指数数据
d2 = ws.DescrStatsW(ccss.index1[ccss.s7 == '已婚']) # 已婚的消费信心指数数据
comp = ws.CompareMeans(d1,d2) # 创建CompareMeans对象
comp.ttest_ind() # 两组独立样本t检验(方差齐性)(2.4052614244262576, 0.01632071963816213, 1131.0)comp.ttest_ind(usevar='unequal') # 两组独立样本t检验(方差不齐性)(2.4669072083186636, 0.013870358702526675, 690.0875773844764)配对t检验的SciPy实现
import scipy.stats as ss
import pandas as pd
ccss_p.loc[:,['index1','index1n']].describe() # 取出4月和12月信心指数,并描述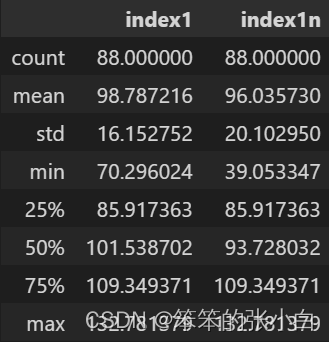
# 用相关分析确认配对信息是否的确存在
ss.pearsonr(ccss_p.index1,ccss_p.index1n)(0.2638011798615908, 0.01301162367951006)# 配对t检验
ss.ttest_rel(ccss_p.index1,ccss_p.index1n)Ttest_relResult(statistic=1.1616334792419984, pvalue=0.24856144386191056)
方差分析
单因素方差分析的SciPy实现
导包
import pandas as pd
import scipy.stats as ss
import matplotlib
# 解决绘图的兼容问题
%matplotlib inline
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] ccss = pd.read_excel("CCSS_sample.xlsx",sheet_name="CCSS") # 读取Excel文件中名称为CCSS的表单
# 分别提取出北京四个时间段的消费信心数据
a = ccss.query("s0 == '北京' & time == 203004 ").index1
b = ccss.query("s0 == '北京' & time == 203012 ").index1
c = ccss.query("s0 == '北京' & time == 203112 ").index1
d = ccss.query("s0 == '北京' & time == 203212 ").index1
ss.levene(a,b,c,d) # 方差齐性检验LeveneResult(statistic=0.44332330387152036, pvalue=0.7221678627997157)ss.f_oneway(a,b,c,d) # 单因素方差分析F_onewayResult(statistic=5.630155391280303, pvalue=0.0008777240313291846)事后检验
# 需要先在环境中安装scikit_posthocs包:pip install scikit_posthocs
import scikit_posthocs as sp
# 创建对象,该对象接收事后检验的数据,并且设置p值校正的方法(控制两两比较的α值)为'bonferroni'
pc = sp.posthoc_conover(ccss,val_col='index1',group_col='time',
p_adjust='bonferroni')# 使用热力图显示比较结果
heatmap_args = {'linewidths': 0.25, 'linecolor': '0.5', 'clip_on': False,
'square': True, 'cbar_ax_bbox': [0.80, 0.35, 0.04, 0.3]}
sp.sign_plot(pc,**heatmap_args) # 绘制热力图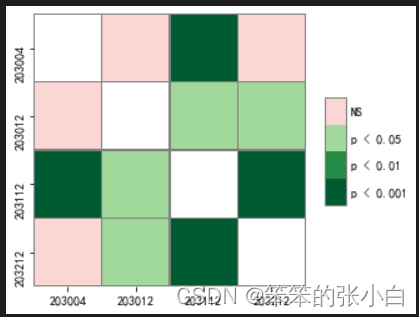
非参数方法
SciPy实现有符号秩和检验
import numpy as np
from scipy import stats
data = [36, 32, 31, 25, 28, 36, 40, 32, 41, 26, 35, 35, 32, 87, 33, 35]
data = np.array(data) # 转换为numpy数组,方便运算
# 检验总体均值是否为37
k = min(len(data[data>37]),len(data[data<37]))
pvalue = 2*stats.binom.cdf(k,len(data),0.5)
print(pvalue)0.021270751953125SciPy实现秩和检验
import scipy.stats as stats
weight_high=[134,146,104,119,124,161,107,83,113,129] # 高蛋白人群的体重的样本
weight_low=[70,118,101,85,112,132,94,100,68,86] # 低蛋白人群的体重的样本
# mannwhitneyu方法针对样本容量相等或不等都是适用的
stats.mannwhitneyu(weight_high,weight_low,alternative='two-sided')MannwhitneyuResult(statistic=81.0, pvalue=0.0211339281291611)
一元线性回归
import pandas as pd
import scipy.stats as ss
ccss = pd.read_excel("CCSS_sample.xlsx",sheet_name="CCSS") # 读取Excel文件中名称为CCSS的表单
# 建立年龄和总消费信心指数的回归方程
ss.linregress(ccss.s3,ccss.index1)LinregressResult(slope=-0.3576848241677336, intercept=108.89832302796889, rvalue=-0.2190793138600294, pvalue=6.243013355018415e-14, stderr=0.047077765734542185, intercept_stderr=1.815504369310354)# 以k*2形式的二维数组提供数据
ss.linregress(ccss.loc[:,['s3','index1']])LinregressResult(slope=-0.3576848241677336, intercept=108.89832302796889, rvalue=-0.2190793138600294, pvalue=6.243013355018415e-14, stderr=0.047077765734542185, intercept_stderr=1.815504369310354)
相关文章
- [Python]架设python虚拟环境以及部署PythonWeb服务
- Python中random模块生成随机数详解
- 【Python】python对象与json相互转换
- python操作docker SDK:Docker SDK for Python
- Python之ffmpeg-python:ffmpeg-python库的简介、安装、使用方法之详细攻略
- Python语言学习:利用python获取当前/上级/上上级目录路径(获取路径下的最后叶目录的文件名、合并两个不同路径下图片文件名等目录/路径案例、正确加载图片路径)之详细攻略
- Python编程语言学习:利用open函数将文本内容追加写入到txt文件中(两种方法实现)
- Python语言学习之打印输出那些事:python输出图表和各种吊炸天的字符串或图画、版权声明(如README.md)等之详细攻略
- IDE之VS:利用 Visual Studio中的IDE配置python语言进行编程
- py之textgenrnn:Python利用textgenrnn库实现训练文本生成网络
- Python语言学习:Python语言学习之正则表达式常用函数之re.search方法【输出仅一个匹配结果(内容+位置)】、re.findall方法【输出所有匹配结果(内容)】案例集合之详细攻略
- Python语言编程学习:利用python输出当前python版本、MSC版本型号
- Python:利用python语言实现18位身份证号码和15位身份证号码相互转换
- Python语言学习:利用python获取当前/上级/上上级目录路径(获取路径下的最后叶目录的文件名、合并两个不同路径下图片文件名等目录/路径案例、正确加载图片路径)之详细攻略
- Python之pyecharts:利用pyecharts绘制2020年11月16日微博话题热度排行榜实时变化
- 利用python采集数据,让自己的耳朵随时充满美妙声音~
- 【Python成长之路】python 基础篇 -- global/nonlocal关键字使用
- 如何利用 Python 批量合并 Excel?
- Python编程:python面向对象
- Python: yield, python 实现tail -f
- Python使用技巧(五):快速解决安装python-lxml模块库报错问题并简单使用
- python基础===数据伪造模块faker
- python基础===jieba模块,Python 中文分词组件
- python基础===利用PyCharm进行Python远程调试(转)
- 学习目录-Python-opencv-图像处理