
通俗的讲,网络爬虫到底是什么?
爬虫通俗来说就是抓取网页数据,比如说大家都喜欢的妹子图、小视频呀,还有电子书、文字评论、商品详情等等。
只要网页上有的,都可以通过爬虫爬取下来。
一般而言,python爬虫需要以下几步:
- 找到需要爬取内容的网页URL
- 打开该网页的检查页面(即查看HTML代码,按F12快捷键即可进入)
- 在HTML代码中找到你要提取的数据
- 写python代码进行网页请求、解析
- 存储数据
当然会撸python是前提,对于小白来说自学也不是件容易的事,需要花相当的时间去适应python的语法逻辑,而且要坚持亲手敲代码,不断练习。
如果对自己没有自信,也可以考虑看编程课程,跟着老师的节奏去学习,能比较快地掌握python语法体系,也能得到充分的案例练习。
在默认你已经有python基础的前提下,来说一说如何写代码进行网页请求、解析。
网页请求意思是把网页的HTML源码下载下来。
好了,接下来我们一步步按照套路把本问题的信息都爬下来!

一、找到需要爬取网页的URL
我们需要爬取四个信息:
- 问题描述
- 问题补充
- 关注者数
- 被浏览数
二、打开该网页的检查页面
推荐使用chrome浏览器实践,会和本文操作同步。
打开本问题的网页:
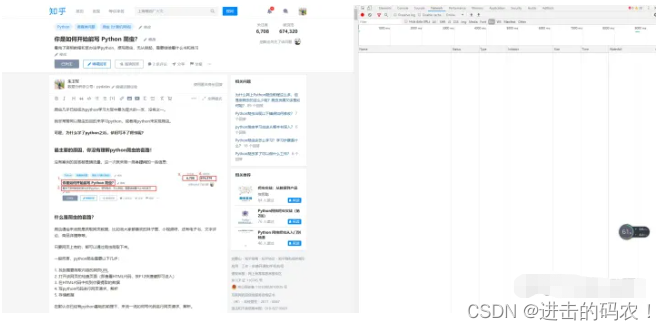
按F12键进入开发者页面:
三、在HTML代码中找到你要提取的数据
点击开发者页面左上角的‘选择元素’箭头:
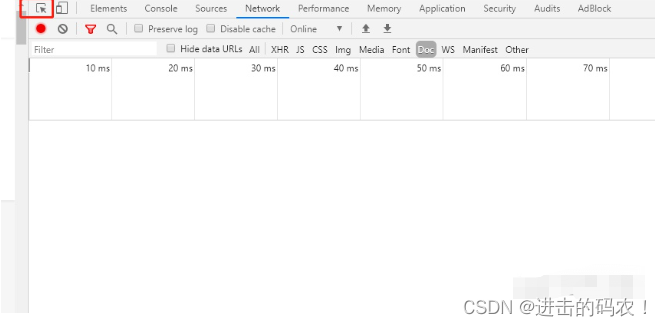
然后再点击网页上的问题描述,这时候开发者界面上出现HTML源码:
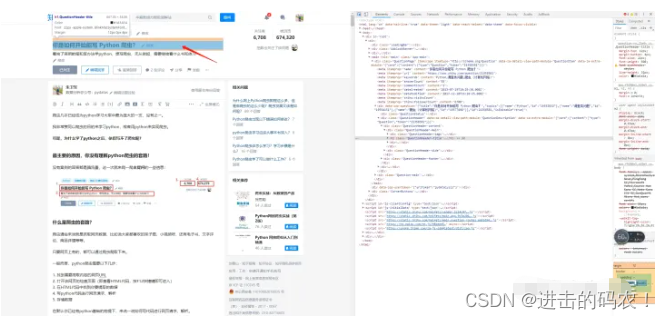
你想要的问题描述文字,就藏在html源码里:
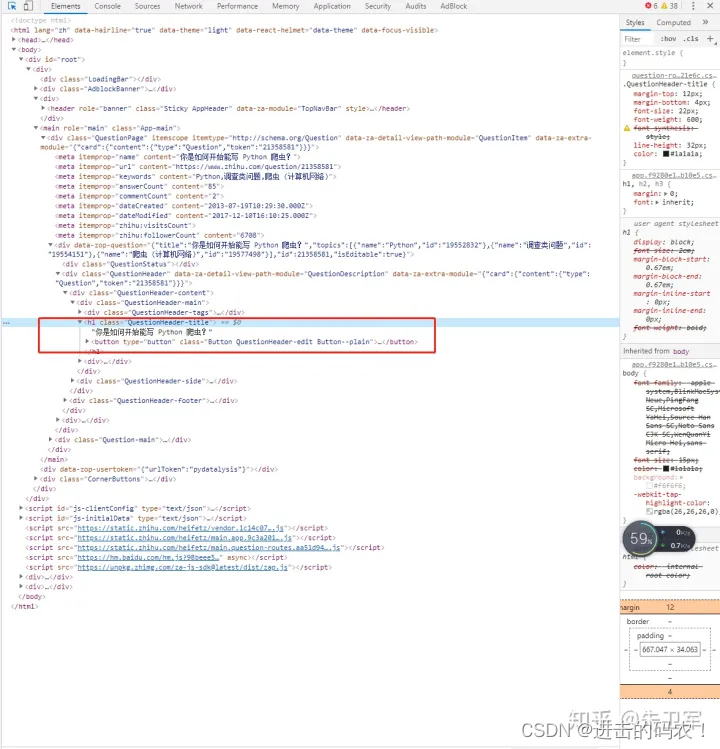
我们要爬取的第一个信息已经找到,按照上面步骤,可以找到其它三个信息在html中的位置。
四、写python代码进行网页请求、解析
这一步可能是大家最最关心的,因为涉及到python代码。
其实这里对python的要求也仅限于你需要会数据类型、变量、运算符、函数、模块之类的简单语法。
因为我们会用到好几个第三方库,帮助我们完成网页请求、解析的工作,你需要做的是知道这些库的使用方法。
Part 1
这里用到的用于网页请求的库是requests,一个非常流行的http请求库。
这里请求的是什么?不是原谅、也不是理解,而是网页的html信息。
服务器收到请求后,会返回相应的网页对象。
Requests库会自动解码来自服务器的内容,大多数 unicode 字符集都能被无缝地解码。
这一切requests都能妥妥地搞定。
我们来尝试下:
import requests
headers = {'User-Agent':你的浏览器headers}
# 传入url和请求头
r = requests.get('https://www.zhihu.com/question/21358581',headers=headers)
# 响应的内容
print(r.text)
我们会接收到服务器返回的页面,requests解析后,呈现下面这样子:
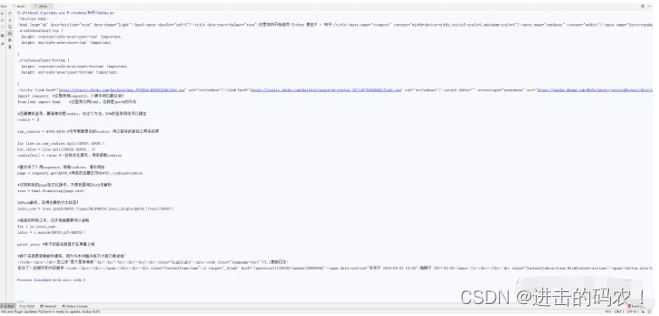
这就是我们需要的html源码呀!
接下来要做的就是从html中抽取我们需要的四个信息。
Part 2
通过网页请求,我们获取到响应的html文档,我们需要的东西都在这个文档里。
但是怎么去抽取信息呢?
XPath 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
这里用到另一个有用的库xpath,xpath库可以让你轻松的使用XPath语言查找信息。
既然XPath是在XML文档中才能起作用,然而我们刚刚获取的html只是文本字符串。
所以需要把html文档转换为XPath可以解析的对象:lxml.etree._Element(xml/html文件树中的一个节点)。
接着上面代码:
# 将html文档转换为XPath可以解析的
s = etree.HTML(r.text)
Part 3
这下我们可以使用xpath库来进行信息的提取了。
xpath的使用方法这里不赘述了,大家可以网上搜搜资料,个半小时也能学会。
这里介绍一种简单的方法,你在开发者页面中找到对应信息的源码后,直接右键复制xpath地址:
但复制的xpath很有可能会导致获取的信息为空,所以我这里用标签的属性来获取对应文本。
接上面代码:
# 获取问题内容
q_content = s.xpath('//*[@class="QuestionHeader-title"]/text()')[0]
# 获取问题描述
q_describe = s.xpath('//*[@class="RichText ztext"]/text()')[0]
# 获取关注数和浏览量,这两个属性一样
q_number = s.xpath('//*[@class="NumberBoard-itemValue"]/text()')
concern_num = q_number[0]
browing_num = q_number[1]
# 打印
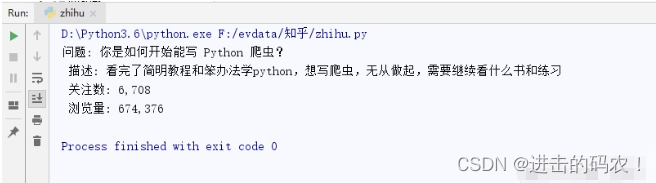
print('问题:',q_content,'\n','描述:',q_describe,'\n','关注数:',concern_num,'\n','浏览量:',browing_num)
最终呈现的结果:
全部代码:
import requests
from lxml import etree
headers = {'User-Agent':你的浏览器headers}
r = requests.get('https://www.zhihu.com/question/21358581',headers=headers)
s = etree.HTML(r.text)
# 获取问题内容
q_content = s.xpath('//*[@class="QuestionHeader-title"]/text()')[0]
# 获取问题描述
q_describe = s.xpath('//*[@class="RichText ztext"]/text()')[0]
# 获取关注数和浏览量,这两个属性一样
q_number = s.xpath('//*[@class="NumberBoard-itemValue"]/text()')
concern_num = q_number[0]
browing_num = q_number[1]
# 打印
print('问题:',q_content,'\n','描述:',q_describe,'\n','关注数:',concern_num,'\n','浏览量:',browing_num)
结论
好了,关于这个问题的信息已经通过python爬下来。
初学的小伙伴自己尝试再多爬些内容,练习requests和xpath的使用,爬虫也就能入门了。
对于小白来说自学也不是件容易的事,需要花相当的时间去适应python的语法逻辑,而且要坚持亲手敲代码,不断练习。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、Python练习题
检查学习结果。

七、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。
相关文章
- [Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
- 【Python3网络爬虫开发实战】1.7.2-mitmproxy的安装
- 【Python3网络爬虫开发实战】 1.5.4-RedisDump的安装
- 【Python3网络爬虫开发实战】1.5.3-redis-py的安装
- 【Python3网络爬虫开发实战】1.2.6-aiohttp的安装
- 《转载》python爬虫实践之模拟登录
- 网络爬虫(1)
- requests爬虫get请求三部曲(快速编码)-小结
- Python 异步网络爬虫教程大全
- 手把手教你用Python网络爬虫获取壁纸图片
- 新手python爬虫100个入门项目
- Python爬虫基础讲解:chrome开发者工具及网络面板
- 【Python3网络爬虫开发实战】1.4.2-MongoDB安装
- 【Python3网络爬虫开发实战】1.5.2-PyMongo的安装
- 【Python3网络爬虫开发实战】 1-开发环境配置
- 【Python3网络爬虫开发实战】1.7.3-Appium的安装
- 【Python3网络爬虫开发实战】3.1-使用urllib
- 【Python3网络爬虫开发实战】3.4-抓取猫眼电影排行
- 网络爬虫基本原理(二)
- 网络爬虫
- 雅虎财经数据python 网络爬虫stock股票 用 Python 通过雅虎财经获取股票数据
- 写网络爬虫天然就是择Python而用 python 网络爬虫3
- 爬虫日记(101):Twisted:使用Deferred重构异常代码
- 爬虫日记(85):Scrapy的ExecutionEngine类(二)
- python爬虫 妹子图片网
- 零基础自学用Python 3开发网络爬虫
- 爬虫----JD-GUI工具的安装与使用
- 爬虫----Android Killer的安装与配置
- 手把手教你用Python网络爬虫获取壁纸图片
- GitHub 热门:各大网站的 Python 爬虫登录汇总
- 爬虫学习(4):requests高阶篇详细教程
- 设计一个网络爬虫(Python)
- 从零开始,学会Python爬虫不再难!!! -- (5)截流:从网络包中获取数据 丨蓄力计划