
C语言进阶第一篇【数据的存储】
前言:Hello!我是@每天都要敲代码。从今天开始我们就一起进入C语言的进阶篇了,对于进阶的部分我感觉最主要的内容就是指针和内存,我们看代码不在只仅仅局限于代码,更多的时候要去了解数据在内存里存储的形式!下面让我们一起学习吧!
目录
补充:debug版本和release版本的区别
在我们学习数据的存储时,我们先补充一个知识点,就是debug和release版本的区别?我们不妨用一个我们曾经做过的代码传送门进行分析:

我们上次已经分析了,这里会因为越界访问造成死循环,我们上次已经通过debug版本进行调试,发现&arr[12]的地址和&i的地址是相同的:
那么问题来了,如果是release版本呢?这时我们就会奇怪的发现,代码没有死循环了!这就是release版本的特殊之处!我们不妨来做一个对比:
Debug:Debug 通常称为调试版本,通过一系列编译选项的配合,编译的结果通常包含调试信息,而且不做任何优化,为开发人员提供强大的应用程序调试能力。
Release:Release通常称为发布版本,是为用户使用的,一般客户不允许在发布版本上进行调试。所以不保存调试信息,同时,它往往进行了各种优化,以期达到代码最小和速度最优。为用户的使用提供便利。

1. 数据类型的介绍
char //字符数据类型
short //短整型
int //整形
long //长整型
long long //更长的整形
float //单精度浮点数
double //双精度浮点数
1.1 类型的基本归类:
整型:
> char
unsigned char
signed char
> short
unsigned short [int]
signed short [int]
> int
unsigned int
signed int
> long
unsigned long [int]
signed long [int]
浮点型:
> float
> double
构造类型:
> 数组类型
> 结构体类型 struct
> 枚举类型 enum
> 联合类型 union
指针类型
>int *p;
>char *p;
>float* p;
>void* p;
空类型:
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
2 数据在内存中的存储
我们之前讲过一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的。比如:一个整型占4个字节,那在内存中具体是怎样的存储的呢?
2.1 原码、反码、补码
数据在内存中以二进制的形式存储,对于整数来说:整数二进制有3中表示形式:原码 反码 补码;三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”。
原码
直接将二进制按照正负数的形式翻译成二进制就可以。
反码
将原码的符号位不变,其他位依次按位取反就可以得到了。
补码
反码+1就得到补码。对于正数:原码、反码、补码相同。
对于负数:反码是原码(除符号位)所有二进制位取反;补码又是反码+1
不太明白?我们不妨举一个例题进行分析:

我们发现对于数据-10,在内存中的存储形式居然是f6 ff ff ff,我们不妨写一下它的原码、反码、补码:

在这里我们发现数据-10的补码刚好就是对应内存中存放的数据;并且它是从最低位f6开始,我们称之为小端模式,具体小端方式是什么,我们下面会讲!这里先给出得到的两个结论:
1.一个整型数据是以补码的形式存放在内存当中的。
2.在VS2019编译器中,数据是以小端方式存取的。
2.2 大端存储和小端存储
大端存储:把数据的低地址位字节序的内容放在高地址处,高位字节序的内容放到低地址处
小端存储:把数据的低地址位字节序的内容放在低地址处,高位字节序的内容放到高地址处有了定义,那么我们怎么判断一个编译器是大端存储还是小端存储呢?这里给出两种方法:
第一种方法:利用强制类型转换

具体代码如下:

测试结果:

与我们前面结论说VS2019是小端存储结果是一致的。
第二种方法:利用联合体(联合的成员是共用同一块内存空间)
联合体也叫作共用体,从名字我们就知道它是可以几种类型共用一个内存,例如:一个char类型一个int类型,它们是共用同一块内存的!有了这一个理解我们先给出代码,在画图解释:
具体代码如下:
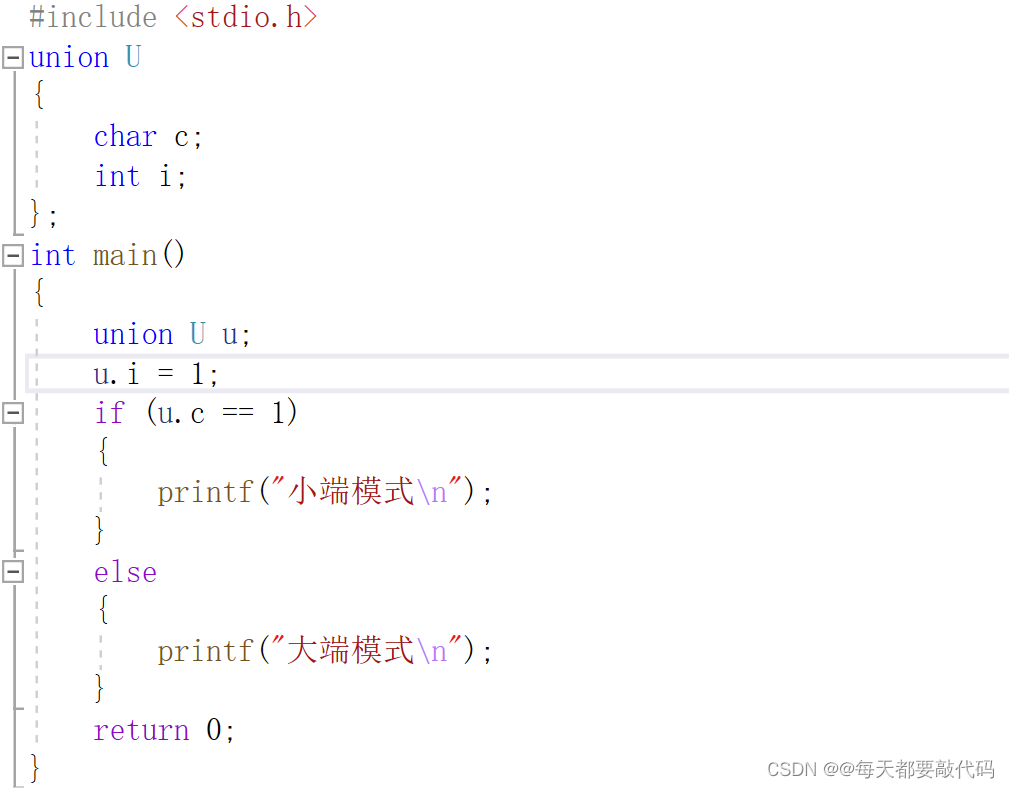
解析:
我们给i赋值为1;如果在大端模式,在内存中存储就是00 00 00 01,那么我们取出c,虽然c并没有赋值,但是联合体共用同一块内存,所以取出来c的值也就是0。如果在小端模式,在内存中存储就是01 00 00 00,那么我们取出c,虽然c并没有赋值,但是联合体共用同一块内存,所以取出来c的值也就是1。

测试结果:
与我们前面结论说VS2019是小端存储结果是一致的。
3. 数据的整型提升
关于整型提升,前面已经有一篇博客讲的很详细了,如果还没有掌握的小伙伴不妨去再复习一下传送门,相信肯定对你有所收获!
4.浮点型在内存中的存储
不同的类型在内存中存储的形式可能是不一样的;前面我们已经讲过了整形数据在内存中存储的形式是补码。这里我们不妨在分析一下浮点型数据在内存中的存储形式是怎样的呢?有了这个思考我们在提出两个疑问:
疑问1:如果我们以整型的形式存储,以浮点型的形式打印,结果怎么样?疑问2:如果我们以浮点型的形式存储,以整型的形式打印,结果又怎么样?
4.1 浮点数存储的规则
首先我们先给出浮点型数据的存储形式,在一起解决上面我们给出的两个疑问:
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
1.* M *
;
2.
3. M表示有效数字,大于等于1,小于2;
4.比如:十进制数据5.5,写成二进制的形式就是101.1,也就是1.011×
;按照上面的754标准规则可以得出:S=0,M=1.011,E=2
比如:十进制数据-5.5,写成二进制的形式就是-101.1,也就是-1.011×
4.2 IEEE 754规定:
对于32位的浮点数:最高的1位是符号位s,接着的8位是指数E,剩下的23位位有效数字M

对于64位的浮点数:最高的1位是符号位s,接着的11位是指数E,剩下的52位位有效数字M

4.3 IEEE 754对有效数字M的特别规定
(1)1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
(2)IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。例如:保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。
(3)以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
4.4 IEEE 754对于指数E的特别规定
(1)首先,E为一个无符号整数(unsigned int)
(2)这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数:
(3)对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。比如:
的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
4.4.1 指数E从内存中取出还可以再分成三种情况:
1、E不全为0或不全为1
(1)这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。
(2)比如:0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为1.0*
,其阶码为-1+127=126,表示为01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进制表示形式为:
0 01111110 00000000000000000000000
2、E全为0
浮点数的指数E等于1-127(-126)(或者1-1023(-1022))即为真实值;有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字
3、E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s)。
4.5 浮点数例题赏析:
例题:有了前面的分析,我们就可以回答上面提出的两个疑问:
疑问1:如果我们以整型的形式存储,以浮点型的形式打印,结果怎么样?
疑问2:如果我们以浮点型的形式存储,以整型的形式打印,结果又怎么样?
下面通过例题的形式去讲解:

不妨先自己动手算一算:
(1)1的值肯定是9,整型形式存储,整形形式打印;这是毫无疑问的!
(2)2的值呢?本来是整型int,然后强制类型转换为浮点型float;通过前面的分析,我们了解到它们两个在内存中的存储情况是不同的:整型int是按照补码形式存储、浮点型float是按照IEEE 754标准存储。我们不妨动手画画分析一下:
这就相当于我们以整型的形式存储,以浮点型的形式打印;最终结果就是:0.000000

(3)3的值呢?本来是浮点型数据float,我们以整型%d的方式打印;我们还是先看浮点数9.0在内存中的存储方式:
这就相当于我们以浮点型的形式存储,以整型的形式打印 结果就是:1091567616

(4)我们以浮点数的形式存储,浮点数的形式打印,结果就还是9:9.000000
打印验证,与我们分析的结果是一致的:

总结:
数据存储这一章节,我们主要讲述了:原码反码补码的讲解、大小端判断方式的判断(两种方法)、整型提升的分析、浮点数的存储;希望大家能够掌握。下一篇我们将一起学习C语言中的重中之重:指针!一起加油吧!
最后给大家分享一波我在网上找到的福利:C语言思维导图传送门
相关文章
- C语言中三目运算符_c语言中的单目运算符
- 【C语言】静态&动态&文件通讯录(超万字)
- 数据在内存中的存储方式--C语言版
- 【C语言进阶】——深入剖析数据在内存中的存储
- 【进阶】C语言——深度剖析数据在内存中的存储
- Linux下C语言实现百度云盘的存储功能(linuxc百度云盘)
- 行使用C语言连接Linux命令行的技术(c连接linux命令)
- C语言frexp()函数:提取浮点数的尾数和指数部分
- 使用Oracle、C语言和DC开发功能强大的应用(oraclecdc)
- Linux下C语言实现RPC(linuxcrpc)
- 深入Linux C语言编程:实现跨平台链接(linuxc链接)
- C语言操作Redis:实现高效数据存储(c操作redis)
- MySQL数据库安全可靠的C语言存储方案(c mysql数据存储)
- 如何使用C语言在MySQL中存储图片(c mysql怎么存图片)
- MySQL存储路径的C语言技巧(c mysql存储路径)
- C语言MySQL实现存储文件的功能(c mysql存储文件)
- C语言在MySQL中实现图片路径的存储(c mysql图片路径)
- C语言MySQL实现图片存储管理系统(C mysql图片存储)
- C语言与MySQL轻松无痛免安装(c mysql 免安装)
- 存储过程C语言调用远程Oracle存储过程的实践(c 调用远程oracle)
- C语言操作Oracle中的图片存储(c oracle读图片)
- Oracle存储过程的利用C语言程序开发(c oracle存储过程)
- 奇怪的C语言特性
- IOS开发之路--C语言存储方式和作用域