
【语义分割】9、Mining Contextual Information Beyond Image for Semantic Segmentation
文章目录

论文链接: https://arxiv.org/pdf/2108.11819.pdf
代码链接: https://github.com/CharlesPikachu/mcibi
代码合并到 sssegmentation: https://github.com/SegmentationBLWX/sssegmentation
出处:ICCV2021
一、背景
在语义分割中,探索不同类别的 “共现” 特征来建模的方法层出不穷,如 PSP/ASPP/OCR 等,但这些方法通常只在图像内建模,没有考虑到对单个图像以外的信息建模。但作者认为,深度学习模型是对一个数据集的整体数据学习,所以为了对像素进行更准确的分类,应该将其他图像中对应的相同类别的语义信息也加入学习中。
二、动机
所以为了缓解上面提到的问题,本文作者提出 “挖掘单个图像以外的上下文信息,来提升像素的特征表达”,如图 1 所示。
- 首先,在训练中,设置一个 “feature memory” 模块,来存储 dataset-level 的各个类别的历史输入
- 之后,预测当前图片的像素表达的概率分布,该概率分布是由真值的分布来监督训练的
- 最后,使用加权聚合的 dataset-level 的表达来增强每个像素表达,这里加权的全职是由相应的类概率分布决定的。
此外,为了在整个数据集层面进一步使得类内更聚合和类间更分散,作者设计了一个“表达一致性学习策略”,来使得分类头同时学习以下两者:
- 整个数据集层面:不同类别的 dataset-level 的表达
- 单个图像层面:pixel-level 的表达

三、方法
3.1 整体结构
首先,给定输入图像 I I I 经过 backbone 得到输出 R ∈ C × H 8 × W 8 R \in C \times \frac{H}{8} \times \frac{W}{8} R∈C×8H×8W,该输出矩阵中存储了图像的像素表达。
然后,使用如下方式来挖掘单个输入图像之外的上下文信息:
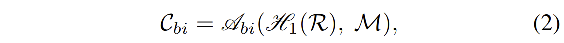
- 不同类别的 dataset-level 的表达存储在 feature memory module M M M 中
- A b i A_{bi} Abi 是提出的 dataset-level 的上下文聚合机制
- C b i ∈ C × H 8 × W 8 C_{bi} \in C \times \frac{H}{8} \times \frac{W}{8} Cbi∈C×8H×8W 存储了来自于 M M M 的 dataset-level 的上下文聚合信息
- H 1 H_1 H1 是分类头,被用来预测像素表达的类别概率分布
为了将本文提出的方法嵌入现有的分割网络中,作者给所利用的网络设计了 self-existing context scheme,称为
A
w
i
A_{wi}
Awi,于是有:
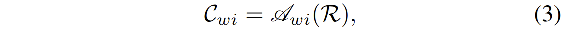
- C w i C_{wi} Cwi 存储了当前输入图像的上下文信息
之后,
R
R
R 被增强:
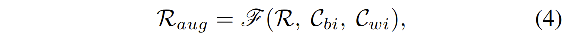
- F F F 是 transform function,被用于聚合原始表达 R R R,单个图像之外的上下文表达 C b i C_{bi} Cbi,图像内部的上下文表达 C w i C_{wi} Cwi
随后,使用
R
a
u
g
R_{aug}
Raug 来预测输入图像的每个像素的类别:
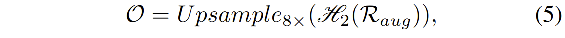
3.2 特征存储模块 Feature Memory Module
如图 2 所示,维度为
K
×
C
K \times C
K×C 的 feature memory module
M
M
M 被用来存储不同类别的 dataset-level 的特征表达,
M
M
M 的初始化采用随机初始化,在每次训练之后使用移动平均的方式来更新:
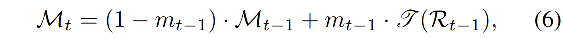
- m m m:动量
- t t t:是当前 iter
- L L L:用来把 R R R 的维度处理的和 M M M 相同
-
m
m
m:使用多项式退火方法来确定
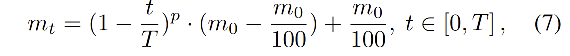
- T T T:iteration 总数
- p p p 和 m 0 m_0 m0 都为 0.9
L L L 的实现:
- 首先,定义一个大小为 K × C K\times C K×C 的矩阵 R ′ R' R′,并使用 M M M 中的值来初始化该矩阵
- R R R 被上采样,然后展成 H W × C HW\times C HW×C大小
- 然后,对于每个类别
c
k
c_k
ck,则有:
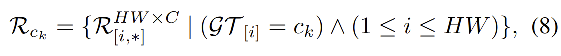
- 其中, G T GT GT of size H W HW HW 是真值
- R c k R_{ck} Rck of size N c k × C N_{ck} \times C Nck×C 存储了类别 c k c_k ck 的表达
- N c k N_{ck} Nck 是图像中真值为 c k c_k ck 的像素个数
- 之后,计算
R
c
k
R_{ck}
Rck 和
M
[
c
k
,
∗
]
M_{[c_k, *]}
M[ck,∗] 的相似矩阵
S
c
k
S_{ck}
Sck of size
N
c
k
N_{ck}
Nck
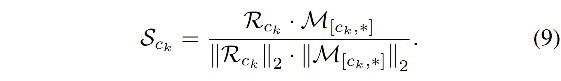
- 最后,
R
′
R'
R′ 中的
c
k
c_k
ck 的表达被更新为:
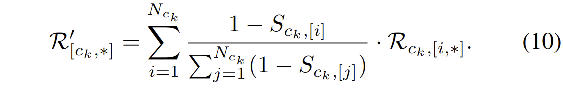
3.3 数据集层面的上下文聚合 Dataset-level Context Aggregation
首先,预测一个大小为
K
×
H
8
×
W
8
K \times \frac{H}{8} \times \frac{W}{8}
K×8H×8W 的权重矩阵
W
W
W,来存储
R
R
R 中的特征表达的类别概率分布:
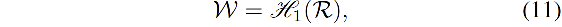
- H 1 H_1 H1:由两个 1x1 卷积和 softmax 函数组成
然后,计算粗糙的 dataset-level representation 矩阵
C
b
i
′
C_{bi}'
Cbi′:
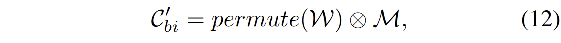
- C b i ′ C_{bi}' Cbi′:大小为 H W 64 × K \frac{HW}{64}\times K 64HW×K,存储了 dataset-level 的聚合表达
- p e r m u t e ( W ) permute(W) permute(W):将 W W W 的维度转换为 H W 64 × K \frac{HW}{64}\times K 64HW×K
由于 H 1 H_1 H1 仅仅使用了 R R R 来预测 W W W,所以像素表达可能会类别错误,所以作者计算了 R R R 和 C b i ′ C_{bi}' Cbi′ 的相关性,来获得位置置信权重来进一步 refine C b i ′ C_{bi}' Cbi′,也就是:
- 首先,使用如下方式计算相关性
P
P
P:
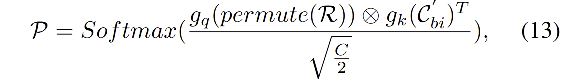
- p e r m u t e permute permute 用来将 R R R 的维度变为 H W 64 × K \frac{HW}{64}\times K 64HW×K
- 然后,refine
C
b
i
′
C_{bi}'
Cbi′
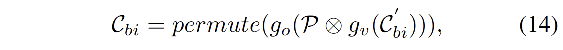
- p e r m u t e permute permute 用来将 R R R 的维度变为 C × H 8 × W 8 C \times \frac{H}{8}\times \frac{W}{8} C×8H×8W
3.4 表达一致性的学习 Representation Consistent Learning
由于分割网络的目标是将整个数据集中的每个像素的特征表达影射到一个非线性空间中,但其训练时是通过 mini-batch 的方式来训练的,这种不一致的学习会导致网络缺失从整个数据集的角度来将同类拉近,将不同类分散开的能力,于是作者提出了 representation consistent learning strategy。
实现:
在训练时,使用
H
2
H_2
H2 来预测
M
M
M 中的 dataset-level 表达的类别:
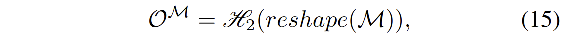
- reshape:将 M M M reshape 到 K × C × 1 × 1 K\times C\times 1 \times 1 K×C×1×1 的大小
- H 2 H_2 H2:由两个卷积层和一个 softmax 层构成
- O M O^M OM:保存了 M M M 中的 dataset-level 的预测概率分布, M M M 中的每个表达都是对整个数据集的同一类别像素表达的整合
- 所以,在预测 O O O 和 O M O^M OM 的时候使用共享的分类头可以使得 H 2 H_2 H2 能够 ① 提高图像内的每个像素的分类能力 ② 从整个数据集中学习到如何将类内拉近,将类间分散开。
3.5 Loss
该 Loss 是一个多任务 loss,涉及到 W W W、 O M O^M OM、 O O O
W W W 的 loss:
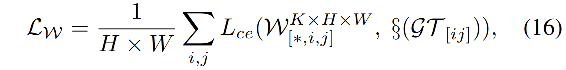
O
M
O^M
OM 的 loss:
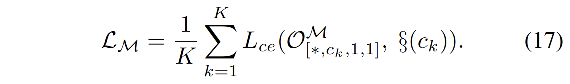
O
O
O 的 loss:
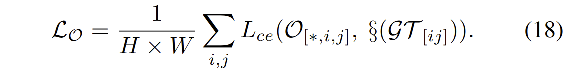
总体 loss:
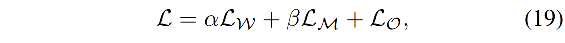
- α = 0.4 \alpha=0.4 α=0.4
- β = 1 \beta=1 β=1
M M M 的值在反向传播中不更新
四、效果
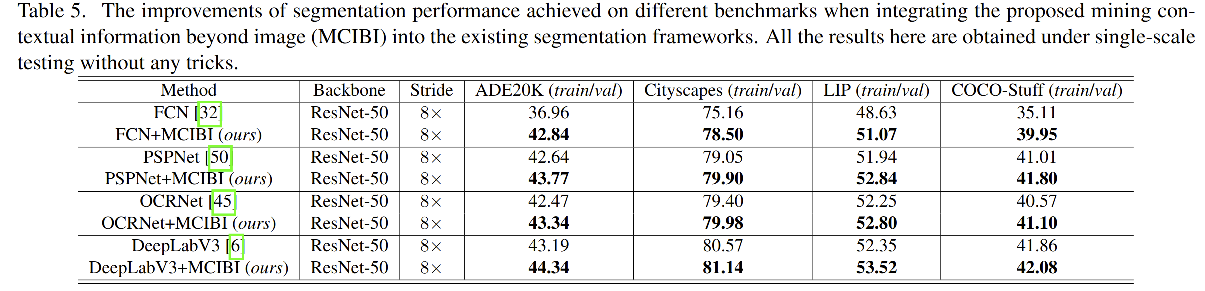
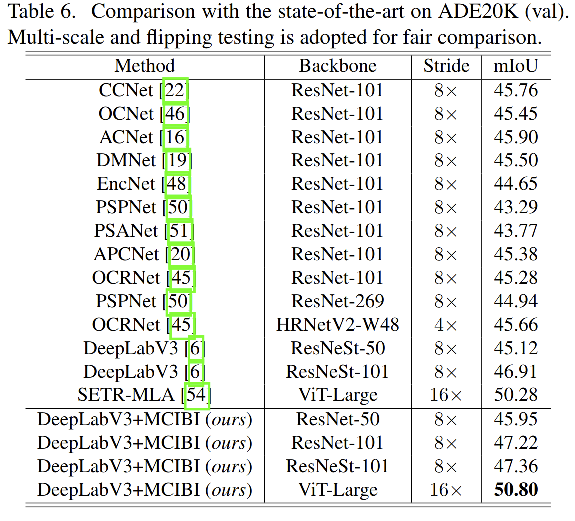
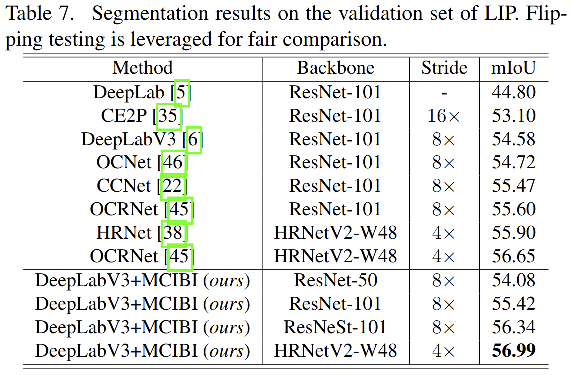
学习到的特征的可视化:

在使用了本文的方法之后,学习到的特征的空间分布更明朗了,也就是同一个类别的像素表达更加集中,不同类别的像素特征表达更加分散。

相关文章
- Performance comparison for loops of List in java
- phpcms : Uncaught Error: [] operator not supported for strings... 的解决方案
- Spire.Office for Java 7.12.4 迎接2023到来
- Spire.Office 7.9.6 for Java--2022-09-22
- 成功解决Building wheel for dlib (setup.py) ... error ERROR: Command errored out with exit status 1:
- 已解决(paddleocr库安装报错) error: subprocess-exited-with-error × Running setup.py install for python-Leve
- 不再写 Python for 循环
- 迁移学习(PCL)《PCL: Proxy-based Contrastive Learning for Domain Generalization》
- 问题解决:Failed to download metadata for repo ‘appstream‘: Cannot prepare internal mirrorlist:...
- Python for Selenium: build test environment
- Devart dotConnect for SQLite 6.0 Crack
- 【语义分割】11、Rethinking BiSeNet For Real-time Semantic Segmentation
- 【语义分割】7、OCRNet:Object-Context Representations for Semantic Segmentation
- 论文阅读【ACM_2020】SimSwap: An Efficient Framework For High Fidelity Face Swapping