
03-如何快速搭建网络资产的信息收集
在之前有针对“信息收集”相关的知识点进行过梳理,个人觉得不是特别的完善。再次编写“信息收集”相关的知识点也是对之前的一种补充,同时也是实战当中能够快速的进行资产收集的常用方法的总结。
https://blog.csdn.net/weixin_42250835/article/details/111411855 信息收集初识
https://blog.csdn.net/weixin_42250835/article/details/111460459 如何绕过CDN查询网站真实IP
https://blog.csdn.net/weixin_42250835/article/details/111464945 子域名的信息收集
https://blog.csdn.net/weixin_42250835/article/details/111474285 Git信息泄漏漏洞与GitHack使用方法
https://blog.csdn.net/weixin_42250835/article/details/111488925 信息泄露漏洞
https://blog.csdn.net/weixin_42250835/article/details/111566350 信息收集篇总结
常见的基础信息收集
操作系统识别:大小写,TTL值,组合对应等
1、Linux对大小写敏感,Windows对大小写不敏感
实例:通过URL改变大小写查看页面响应是否正常
TTL值:通过ping命令得到对方服务的TTL回显值(不是很标准)
组合对应:根据Linux、Windows服务器搭建特性或常见的搭建组合去猜解
aspx mssql windows iis
php mysql windows/linux apache
jsp mssql/oracle windows/linux tomcat
javaee mysql/oracle/ windows/linux weblogic/jboos/tomcat
2.中间件平台识别:返回数据包,端口探针,组合对应等
3.数据库类型识别:端口探针,组合对应,应用规模猜测等
4.脚本开发语言识别:URL获取,搜索引擎探针,组合对应等
5.WEB类接口信息识别:扫描探针,特定访问,端口扫描等
一定要了解常见各种搭建资产识别技术,常见搭建组合归类,部分信息收集技术
架构资产信息收集
1.IP类站点获取:直接利用返回IP进行测试访问
举例:比如一个IP站点不同的端口开放的是不同的站点,这样的情况下就是一个IP对应多个可渗透站点,可以扩大攻击面。
2.目录类站点获取:利用目录爬行或目录扫描等进行获取
举例:有的时候,不同的目录也是不同的站点,同样也可以利用来进行攻击面的扩大。比如一个域名下面存在xxx.com/bbs/系统
目录爬行:通过爬虫爬取网站地图获取目录信息,代表工具AWVS简称“WVS”
目录爆破:利用工具通过字典爆破,根据返回的响应状态获取有效的目录信息,代表 工具7kbscan
3.端口类站点获取:利用端口扫描进行服务探针进行获取
通过端口扫描发现开放的对应端口,发现对应的服务站点,可通过端口进行访问
4.子域名站点获取:利用子域名查询平台或工具进行获取
通过子域名资产工具针对子域名资产进行收集。
了解站点架构搭建上的区别及如何获取此类信息来源,部分信息收集技术
源码资产信息收集
1.如何获取源码类信息:CMS名称,特定文件,版本信息等
当知道一个网站使用的CMS(内容管理系统)的时候,就可以根据当前网站所使用的CMS去搜集对应的版本信息、源码以及公开的可利用的漏洞,直接一步到位。
CMS检测平台(网上有很多可自行百度)
国外:https://whatcms.org/ ->
国内:http://whatweb.bugscaner.com/ ->
工具:https://github.com/Tuhinshubhra/CMSeeK ->
CMS检测小技巧:当网站没有明确的标识使用的CMS内容管理系统,可通过访问网站的请求包里的特定的路径通过搜索引擎找到该网站使用CMS。
2.如何下载到源码程序:源码站(黑白),备份,泄漏,监控,手工分析搜索等
详见下文“源码安全”
工具平台识别配合人工进行特定搜索等操作,根据不同的WEB应用类型进行方法选择
域名资产信息收集
域名类信息:whois,备案,子域名,类似域名等
了解域名上的资产信息收集思路及拓展,涉及工具及平台人工等操作
第三方平台使用,工具或脚本使用,类似域名获取测试
https://github.com/shmilylty/OneForAll
python oneforall.py --target=xiaodi8.com run
除了OneForAll这款子域名挖掘神器之外还有Recon-ng、Layer挖掘机、DNSenum、御剑等,都是常备的信息收集工具,使用方面这里不做过多描述,网上有很多。比如谢公子的博客专栏上就有很多详细的介绍。
注册接口配合搜索引擎关键字等技术获取其他类似域名。
源码安全的信息收集
参考:https://www.secpulse.com/archives/124398.html
题外话:
信息泄露,是指网站在无意间的情况下向用户泄露的敏感信息。结合上下流量包信息,网站可能会将各种各样的信息泄漏给潜在的攻击者。
包括但不限于:
有关其他用户的数据,例如用户名或财务信息
敏感的商业信息或商业数据
有关网站服务器及其基础架构的技术细节
泄露敏感信息或业务数据给用户,本身就是相当危险的行为,同样的泄露相关技术信息有时也会造成很严重的危险后果。
可能某些信息用途有限,但它可能是暴露其他攻击面的起点。当攻击者试图发起一次高强度攻击没有收获时,往往收集的这些基础信息就可以解决这个问题。
有时,敏感信息可能会不慎泄露给仅以正常方式浏览网站的用户。但是更常见的是,攻击者需要通过以意外或恶意的方式与网站进行交互来触发信息泄露。然后,攻击者会仔细研究网站的响应,以尝试找出可以利用的信息来作为攻击的支撑。
- git源码泄露
- svn源码泄露
- hg源码泄漏
- 网站备份压缩文件
- WEB-INF/web.xml 泄露
- DS_Store 文件泄露
- SWP 文件泄露
- CVS泄露
- Bzr泄露
- GitHub源码泄漏
其中hg、SWP、CVS相对于其他来说算是比较老的版本控制系统了,现在已经很少人使用了,这里就不做过多的介绍,有兴趣的同学可以自行百度。
网站备份压缩文件
在网站的使用过程中,往往需要对网站中的文件进行修改、升级。此时就需要对网站整站或者其中某一页面进行备份。当备份文件或者修改过程中的缓存文件因为各种原因而被留在网站web目录下,而该目录又没有设置访问权限时,便有可能导致备份文件或者编辑器的缓存文件被下载,导致敏感信息泄露,给服务器的安全埋下隐患。
漏洞成因及危害:
该漏洞的成因主要有以下两种:
服务器管理员错误地将网站或者网页的备份文件放置到服务器web目录下。
编辑器在使用过程中自动保存的备份文件或者临时文件因为各种原因没有被删除而保存在web目录下。
漏洞检测:
该漏洞往往会导致服务器整站源代码或者部分页面的源代码被下载,利用。源代码中所包含的各类敏感信息。
如服务器数据库连接信息,服务器配置信息等会因此而泄露,造成巨大的损失。被泄露的源代码还可能会被用于代码审计。
进一步利用而对整个系统的安全埋下隐患。
.rar
.zip
.7z
.tar.gz
.bak
.swp
.txt
.html
git 源码泄露
Git是一个开源的分布式版本控制系统,在执行git init初始化目录的时候,会在当前目录下自动创建一个.git目录,用来记录代码的变更记录等。发布代码的时候,如果没有把.git这个目录删除,就直接发布到了服务器上,攻击者就可以通过它来恢复源代码。
漏洞利用工具:GitHack
github项目地址:https://github.com/lijiejie/GitHack
用法示例:
GitHack.py http://www.openssl.org/.git/
修复建议:删除.git目录或者修改中间件配置进行对.git隐藏文件夹的访问。
SVN 源码泄露
SVN是一个开放源代码的版本控制系统。在使用SVN管理本地代码过程中,会自动生成一个名为.svn的隐藏文件夹,其中包含重要的源代码信息。网站管理员在发布代码时,没有使用‘导出’功能,而是直接复制代码文件夹到WEB服务器上,这就使.svn隐藏文件夹被暴露于外网环境,可以利用.svn/entries文件,获取到服务器源码。
在服务器上布署代码时。如果是使用 svn checkout 功能来更新代码,而没有配置好目录访问权限,则会存在此漏洞。黑客利用此漏洞,可以下载整套网站的源代码。
使用svn checkout后,项目目录下会生成隐藏的.svn文件夹(Linux上用ls命令看不到,要用ls -al命令)。
svn1.6及以前版本会在项目的每个文件夹下都生成一个.svn文件夹,里面包含了所有文件的备份,文件名为 .svn/text-base/文件名.svn-base
漏洞利用工具:Seay SVN漏洞利用工具
漏洞利用工具:svnExploit漏洞利用工具
修复建议:删除web目录中所有.svn隐藏文件夹,开发人员在使用SVN时,严格使用导出功能,禁止直接复制代码。
参考:https://www.cnblogs.com/hilfloser/p/10517856.html SVN信息泄露漏洞分析
Bazaar/bzr泄露
bzr也是个版本控制工具, 虽然不是很热门, 但它也是多平台支持, 并且有不错的图形界面。
运行示例:
rip-bzr.pl -v -u http://www.example.com/.bzr/
WEB-INF/web.xml 泄露
WEB-INF是Java的WEB应用的安全目录,如果想在页面中直接访问其中的文件,必须通过web.xml文件对要访问的文件进行相应映射才能访问。
WEB-INF 主要包含一下文件或目录:
WEB-INF/web.xml : Web应用程序配置文件, 描述了servlet和其他的应用组件配置及命名规则.
WEB-INF/database.properties : 数据库配置文件
WEB-INF/classes/ : 一般用来存放Java类文件(.class)
WEB-INF/lib/ : 用来存放打包好的库(.jar)
WEB-INF/src/ : 用来放源代码(.asp和.php等)
通过找到 web.xml 文件,推断 class 文件的路径,最后直接 class 文件,再通过反编译 class 文件,得到网站源码。
漏洞成因:
通常一些web应用我们会使用多个web服务器搭配使用,解决其中的一个web服务器的性能缺陷以及做均衡负载的优点和完成一些分层结构的安全策略等。在使用这种架构的时候,由于对静态资源的目录或文件的映射配置不当,可能会引发一些的安全问题,导致web.xml等文件能够被读取。
漏洞检测以及利用方法:
通过找到web.xml文件,推断class文件的路径,最后直接class文件,在通过反编译class文件,得到网站源码。
一般情况,jsp引擎默认都是禁止访问WEB-INF目录的,Nginx 配合Tomcat做均衡负载或集群等情况时,问题原因其实很简单,Nginx不会去考虑配置其他类型引擎(Nginx不是jsp引擎)导致的安全问题而引入到自身的安全规范中来(这样耦合性太高了),修改Nginx配置文件禁止访问WEB-INF目录就好了: location ~ ^/WEB-INF/* { deny all; } 或者return 404; 或者其他!
DS_Store 文件泄露
".DS_Store"是Mac下Finder用来保存如何展示 文件/文件夹 的数据文件,每个文件夹下对应一个。如果将.DS_Store上传部署到服务器,可能造成文件目录结构泄漏,特别是备份文件、源代码文件。
漏洞利用工具:
github项目地址:https://github.com/lijiejie/ds_store_exp
用法示例:
ds_store_exp.py http://hd.zj.qq.com/themes/galaxyw/.DS_Store
GitHub源码泄漏
GitHub是一个面向开源及私有软件项目的托管平台,很多人喜欢把自己的代码上传到平台托管。攻击者通过关键词进行搜索,可以找到关于目标站点的敏感信息,甚至可以下载网站源码。
类似的代码托管平台还有很多,人才是最大的漏洞。
https://github.com/search?q=smtp+user+@qq.com&type=code
还有一种GitHub监控
参考:http://sc.ftqq.com/3.version Server酱 申请-配置-写入-测试
WAF识别-后期测试绕过点
如何判断网站是否存在WAF并识别-wafw00f或看图识别
wafw00f
wafw00f-GIT地址 https://github.com/EnableSecurity/wafw00f
https://blog.csdn.net/weixin_42250835/article/details/115313988 wafw00f简介及防火墙探测
看图识WAF
1.D盾

2.云锁
3.UPUPW安全防护

4.宝塔网站防火墙

5.网防G01
6.护卫神

7.网站安全狗
8.智创防火墙

9.360主机卫士或360webscan
10.西数WTS-WAF

11.Naxsi WAF

12.腾讯云
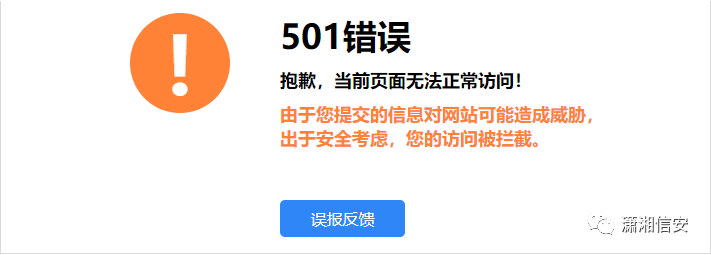
13.腾讯宙斯盾
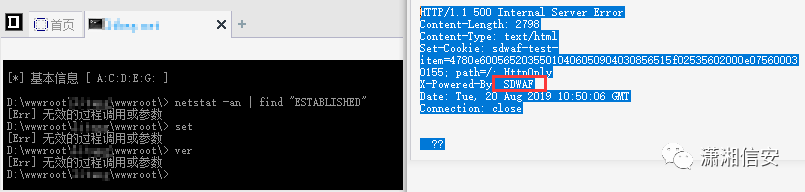
14.百度云
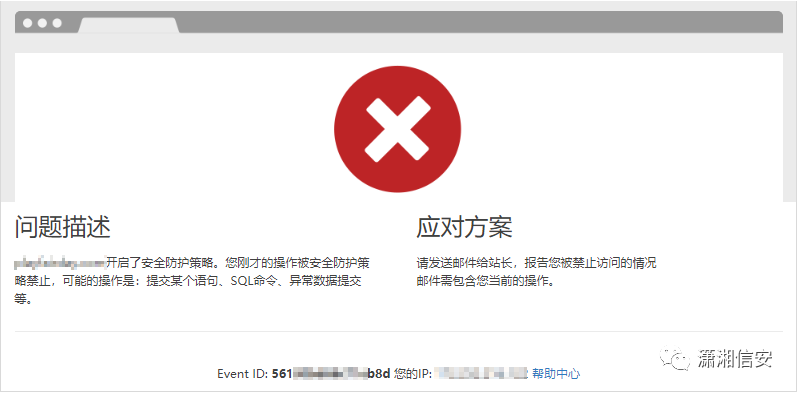
15.华为云

16.网宿云

17.创宇盾
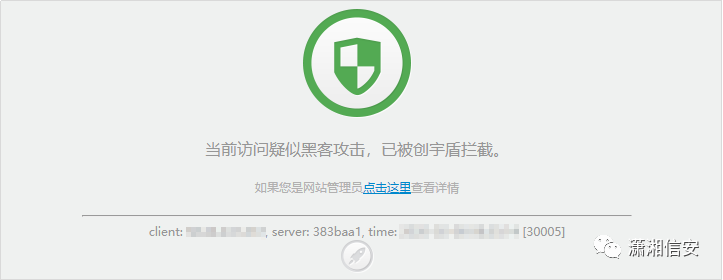
18.玄武盾
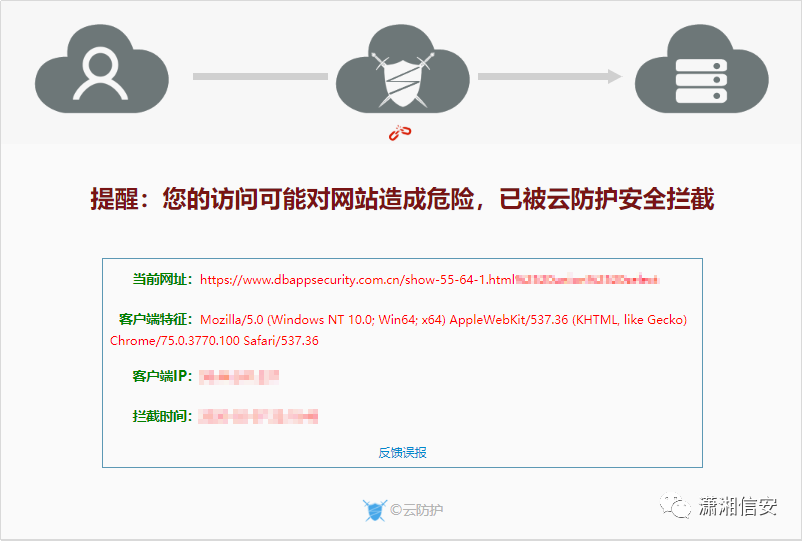
19.阿里云盾
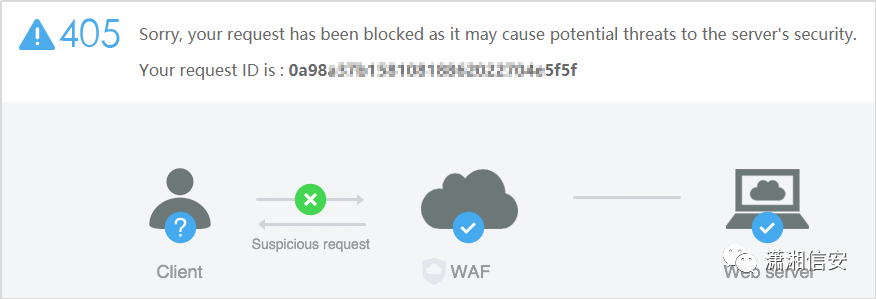
20.360网站卫士

21.奇安信网站卫士
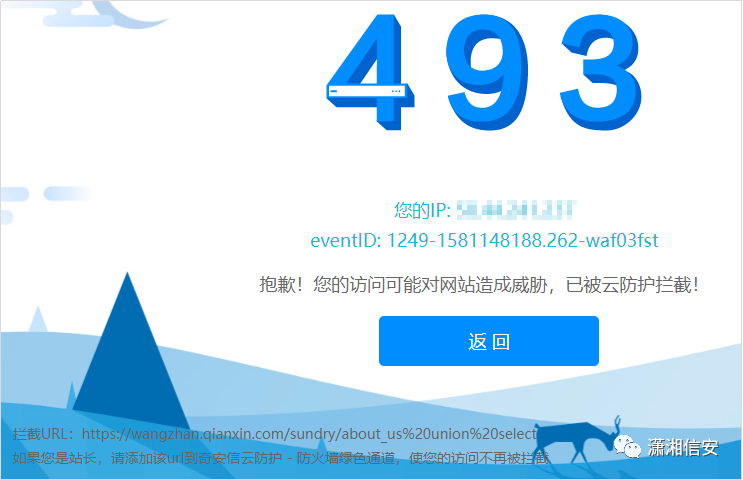
22.安域云WAF

23.铱讯WAF

24.长亭SafeLine
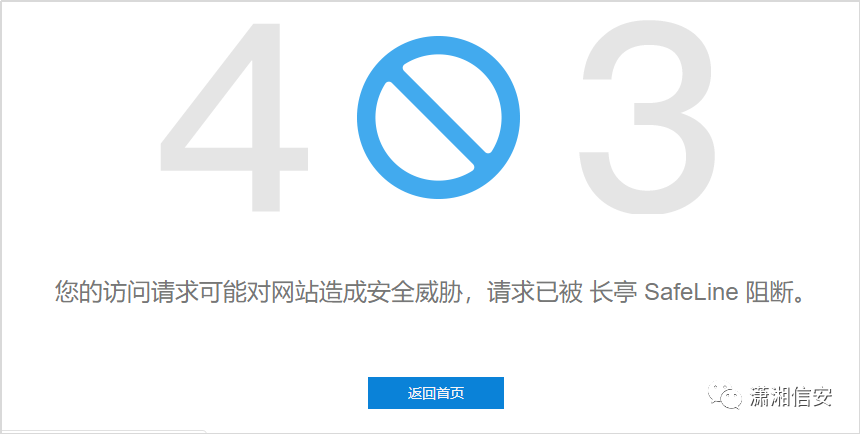
25.安恒明御WAF

26.F5 BIG-IP


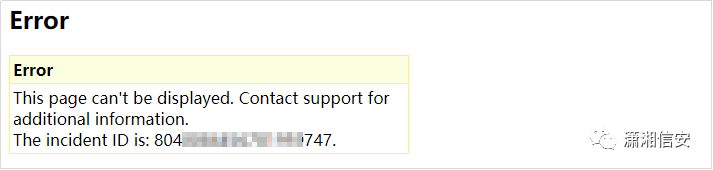
27.Mod_Security

28.OpenRASP
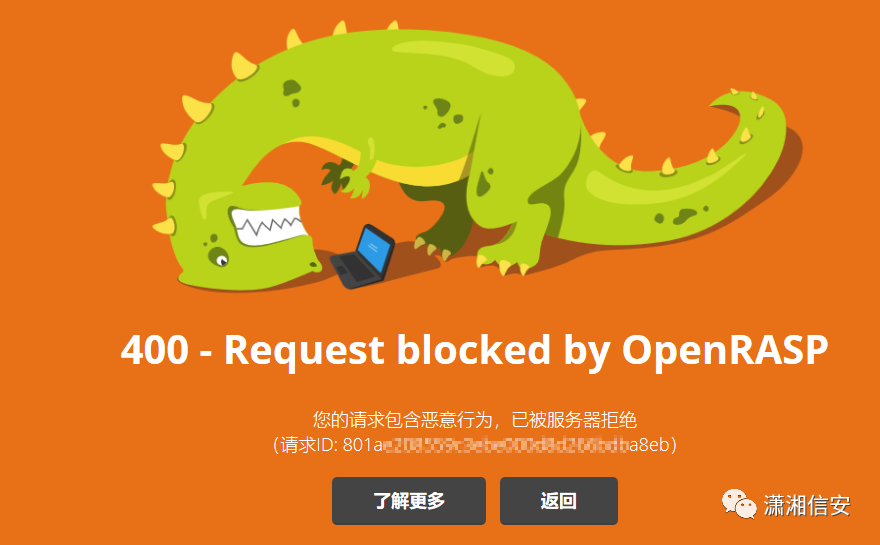
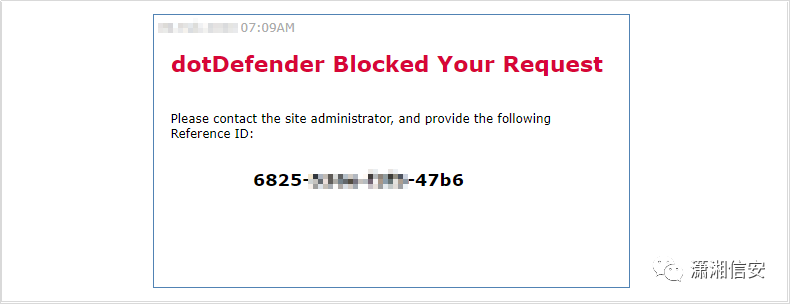
29.dotDefender
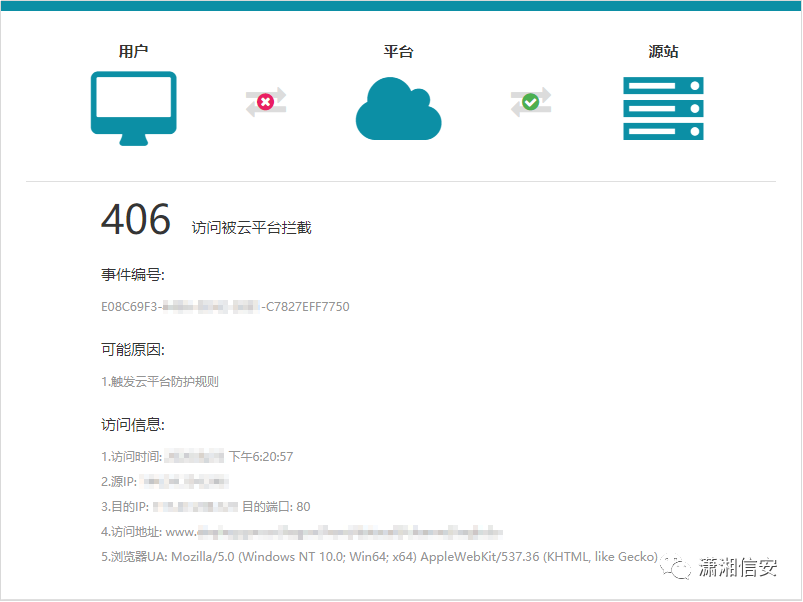
30.未知云WAF
旁注,C段,IP反查-后期测试思路点
发现保存了好几篇以前收集的一些相关文章。文章都比较类似,方法大同小异,做个汇总,也添加一些自己积累。
旁注:同服务器下不同站点
旁注:服务器上存在A,B两个站点,A是测试目标,没有发现漏洞无法测试,这个时候可以借助旁注查询获取B站点,通过B站点的测试进一步获取A目标的权限。
IP反查:利用IP获取服务器解析域名 a
C段:如果服务器是独立站点或其他站点也无漏洞利用时,可以获取同网段服务器下的站点信息,进行安全测试,获取到同网段下的某台服务器权限,进行内网安全测试获取指定服务器权限。
C段:同网段不同服务器下不同站点
CDN绕过-后期测试绕过点
1.传统访问:用户访问域名–>解析服务器IP–>访问目标主机
2.普通CDN:用户访问域名–>CDN节点–>真实服务器IP–>访问目标主机
3.带WAF的CDN:用户访问域名–>CDN节点(WAF)–>真实服务器IP–>访问目标主机
如何判断网站是否存在CDN
nslookup,各地ping
如何获取网站真实IP地址
子域名,去掉www,邮件服务器,国外访问,证书查询,APP抓包
参考:https://zhuanlan.zhihu.com/p/33440472 绕过CDN寻找网站真实IP的方法汇总
参考:https://blog.csdn.net/weixin_42250835/article/details/111460459 如何绕过CDN查询网站真实IP
黑暗空间引擎,通过漏洞或泄露获取,扫全网,以量打量,第三方接口查询等
https://www.17ce.com/
https://www.wepcc.com/
https://get-site-ip.com/
https://x.threatbook.cn/
https://tools.ipip.net/cdn.php
https://github.com/Tai7sy/fuckcdn
https://github.com/boy-hack/w8fuckcdn
端口扫描、服务探测
扫描神器、众神之眼—不解释
http://www.nmap.com.cn/doc/manual.shtm Nmap中文手册
https://blog.csdn.net/weixin_42250835/article/details/115339302(众神之眼)超详解端口扫描
https://blog.csdn.net/weixin_42250835/article/details/115364161 nmap(众神之眼)高级应用-IDS与防火墙规避及漏洞利用脚本篇
端口扫描-系统版本服务探针
端口扫描-自带防火墙服务探针
端口扫描-网段系统端口信息探针
nmap -sV www.xxx.com
nmap -O -A www.xxx.com
nmap -Pn -O -A www.xxx.com
黑暗引擎-Fofa,shadan,zoomeye,360
语法,玩法,功能等-关联关系,自动数据,白引擎外等
https://fofa.so/
https://www.shodan.io/
https://www.zoomeye.org/
https://quake.360.cn/quake/#/index
ARL灯塔-自动化资产侦察灯塔系统使用
安装,使用,功能,补充等
安装docker docker-compose
修改项目的版本 3修改成2
修改docker源 保证速度问题
注意:服务器记得安全组配置放行对应端口
https://github.com/TophantTechnology/ARL
https://www.cnblogs.com/zhengjim/p/13678257.html
APP、小程序抓包、搜索信息提取
工具:
Charles【实时抓到操作数举报】
抓包精灵【比较方便,安装在手机或者模拟器,即装即用】
Burpsuite【便于后期其他安全工具的联动】
Wireshark【抓取网卡全部流量】
集中信息收集:信息收集-APP/小程序:外部展示和内部源码分析
基本应用版本功能加固,涉及引用协议(WEB,IP,接口等),代码逻辑安全问题,涉及资源类文件,关键性密匙,下载来源,应用获取操作权限等信息。
这里简单说一下,APP、小程序的渗透歧视也没有那么难,毕竟也会使用WEB协议进行数据上的交互,在获得基于HTTP代理的URL、请求响应之后完全可以当作WEB端进行渗透。
以下是服务端漏洞检测常见的思路
基于HTTP代理思路:
水平权限风险检测
垂直权限风险检测
SQL注入漏洞检测
XSS漏洞检测
敏感信息检测(硬编码、用户密码、银行卡、身份证等敏感信息明文传输)
基于TCP或者UDP(socket)代理思路:
敏感信息检测(硬编码、用户密码、银行卡、身份证等敏感信息明文传输)
html5漏洞检测
APK静态调试安全检测-平台
https://www.cnblogs.com/xiaozi/p/12749801.html 免费好用的APP安全在线检测平台
https://console.cloud.tencent.com/ms/scan 腾讯云移动应用安全测评
外部展现抓包历史-两种工具
https://github.com/huolizhuminh/NetWorkPacketCapture/releases
抓包精灵,Burpsuite配置抓包测试
举例“Fofa-“index/login/login/token”-121.127.227.20-MetaTrade 5”
抓取历史数据包,对比抓包工具抓取结果,分析后续思路
内部关键搜索特征-自动提取
https://github.com/TheKingOfDuck/ApkAnalyser
利用apkAnalyser自动化脚本提取对应其他结果(需要结合抓包进行分析,两者结合才能保证信息搜集的更全。工具毕竟是工具,分析的结果有一定的误报。)
内部关键搜索特征-反编译搜索
搜索fuliqh,MetaTrade(这是测试用的APK包)两个反编译后,IDEA全局搜索特定关键字(利用一键反编译工具)
6/9/2021 10:47:26 PM
!!!—多动手,只看只听是不行的—!!!
三天打鱼,不深入了解原理,仅会用工具只能成为脚本小子
相关文章
- linux网络配置出现E325,Linux CentOS E325错误,如何解决?VI如何使用?「建议收藏」
- 如何正确的理解RPN网络的train和test[通俗易懂]
- 一个好的网络服务器主机经销商应该具备的
- 【高效笔记】网络设备Console密码网络怎么办?如何快速恢复!
- Linux下用netstat查看网络状态、端口状态详解程序员
- Linux网络连接指南:快速实现安全上网!(linux如何连接网络)
- 我国活跃用户数已达5.28亿:IPv6网络如何跨越拐点走向“通车”
- 网络配置Linux下无线网络配置实践指南(基于linux的无线)
- 互联网化疗 —— BrickerBot 僵尸网络创建者的行动
- “GANs之父”Goodfellow 38分钟视频亲授:如何完善生成对抗网络?(上)
- Linux网络编程:地址绑定实现与优化(linux地址绑定)
- Linux下如何实现映射网络驱动器?(linux映射网络驱动器)
- 如何使用Linux配置和管理VLAN网络(linuxvlan)
- 教你如何搭建高效稳定的 Linux CDN 网络(linuxcdn搭建)
- 探究Linux服务器如何解析域名:深入理解网络基础架构(linux服务器解析域名)
- lan探究Linux如何轻松Ping WLAN网络(linuxpingw)
- Linux双网卡联机: 通往更快,更安全的网络体验(linux双网卡上网)
- 快速指南:Linux下如何删除网络配置(linux删除网络配置)
- 如何优化Linux SCP传输速度? 参考实用技巧、检查网络、调整SSH配置等方法,解决Linux SCP传输速度慢的烦恼。(linuxscp速度慢)
- Linux如何检测和配置网卡网络设置(linux怎么检查网卡)
- 如何在Linux上配置网络命令(linux配置网络命令)
- MySQL无法在外部网络中访问,如何解决(mysql不能外网访问)
- 北京海淀法院:近10年网络犯罪女黑客比例高,职业黑客渐常见