
Vue2.x - Vue Router
目录
创建VueRouter实例并将其关联vm.$options.router
通过路由配置属性props简化$route.query的获取
Vue与SPA
什么是SPA
简单了解SPA
SPA(Single Page Web Application)单页面网站应用,顾名思义,只有一个网页的网站。
最简单的SPA其实就是,把一个index.html放在网站服务器上,如下
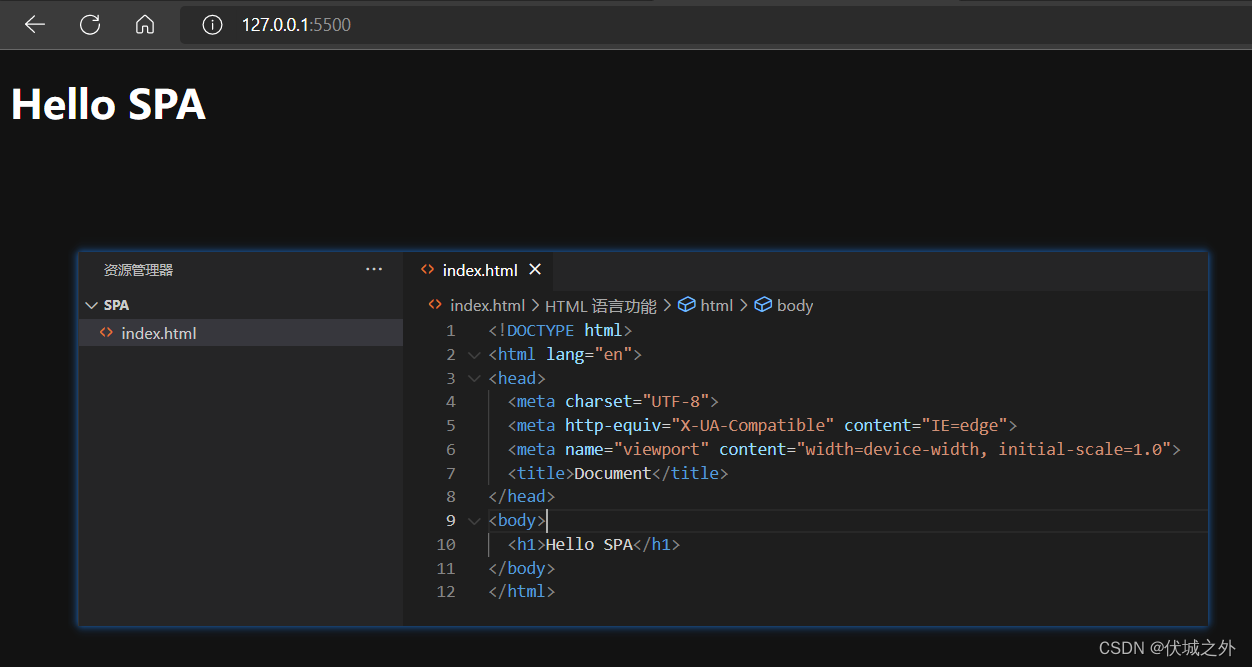
但是这种SPA网站应该不会有人光顾。因为太单调了,太简单了。
而实际上的企业级SPA网站,是要能够基本替代MPA网站,并超越MPA的网站的。
什么是MPA
MPA(Multiple Page Web Application)多页面网站应用,顾名思义,由多个网页构成的网站。
目前网络上能访问到的大部分网站都是MPA的。
MPA网站的最大特点就是,从一个网页跳转到另一个网页。
MPA网站的网页间跳转,其实本质是变更浏览器地址栏的URL,促使浏览器刷新网页,来发起HTTP GET请求,到服务器获取到最新的网页资源,这将导致两个问题:
- 消耗大量服务器性能:首先MPA是多页面网站,而浏览器每次只能展示一个页面,所以MPA意味着浏览器会向服务器多次请求不同页面资源。其次,浏览器可能会重复刷新某个页面,导致服务器收到重复页面资源的请求(PS:虽然服务器可以在响应中设置缓存头,促使浏览器缓存请求到的页面资源,防止无意义的重复的页面资源的请求,但是这并不意味着服务器不需要处理重复的页面资源请求,因为当浏览器意识到请求的页面资源已经在自身缓存中时,浏览器还是需要发送请求到服务器验证缓存的页面资源是否过期,如果过期,则服务器需要重新响应页面资源,如果未过期,则需要响应状态码304,告知浏览器可以继续使用缓存的页面资源)
- 消耗大量浏览器性能:每次网页间跳转,都会导致网页刷新,而网页刷新本质是从服务器请求到新的网页资源,或者从自身缓存中获取网页资源,然后浏览器需要重新渲染整个网页。(网页的渲染是一个极其复杂的流程,首先是构建DOM树,然后是构建CSSOM树,然后将DOM树和CSSOM树结合形成渲染树,然后....反正就是很复杂,所以渲染整个网页是非常消耗浏览器性能的,特别是大量重复无意义的网页刷新行为)
MPA网站还有一些其他的小问题,比如跳转的网页可能会在新页签中打开,这不仅会占用大量浏览器资源,而且会给用户一种混乱的感觉,再比如,每次网页跳转的默认刷新行为都是需要时间的,这段时间会去请求服务器,重新渲染网页等,浪费用户的时间,还有网页刷新会造成网页内容的抖动。
所以MPA的弊端还是挺严重的,但是目前WEB网站,还是MPA模式居多,这是为啥呢?
因为MPA网站开发简单,或者说我们前端开发更熟悉多页面的开发模式。
SPA相较于MPA的优点
那么SPA要如何取代MPA,解决MPA的诸多问题呢?
首先我们来谈谈SPA的优点
- SPA只有一个页面,当我们在浏览器初次加载SPA网站时,就已经完成了SPA所有(唯一)页面的加载,所以相较于MPA而言,对于服务器的综合性能消耗更小。
- SPA只有一个页面,所以不存在从一个网页跳转到另一个网页,SPA的都是网页内的内容切换。即SPA用单页面中内容切换,代替了,MPA多页面间跳转。而SPA单页面中的内容切换,其实就是网页的局部DOM更新。这将降低浏览器的渲染压力。
因为SPA不存在多页面间跳转,只存在单页面中内容切换(局部DOM更新),所以不会导致网页刷新,也就不会发生到服务器请求网页资源的行为,所以SPA内容切换的耗时(请求服务器+渲染)将远远小于MPA网页间跳转的耗时。并且由于没有网页刷新发生,所以也不存在网页抖动。
实现SPA的几个关键点
看来SPA无论对于服务器,还是浏览器来说都是友好的嘛!
那么最最最关键的东西来了,SPA如何实现呢?
其实SPA的实现,就是几个关键点的实现:
- 理解SPA的单页面架构(导航区+展示区)
- 前端路由的实现(浏览器地址栏URL的改变会引起展示区局部DOM的更新)
理解SPA单页面架构
我们可以将SPA单页面划分出两个基础区域:导航区、展示区。
比如下图中,我们点击导航区的“用户中心”超链接,就会导致展示区的内容改变(局部DOM更新)为用户中心的内容。

如果是MPA的话,我们点击导航区“用户中心”,则用户中心的内容会以一个独立网页的形式呈现,而不是被更新当前网页的局部。
什么是前端路由
什么是路由?
在前端中,路由其实就是:输入在浏览器地址栏的URL 与 浏览器窗口呈现的内容(网页或HTML片段)的对应关系。
什么是前端路由,什么是后端路由?
当我们在浏览器地址栏输入URL后,导致网页刷新,促使浏览器发送HTTP GET请求到后端服务器获取对应网页资源。即URL对应的网页来自于后端服务器。此时路由称为后端路由。
当我们在浏览器地址栏输入URL后,不会导致网页刷新,而是触发了浏览器原生的事件,导致对应事件回调会将准备好的HTML片段更新到网页指定位置。即URL对应的HTML片段来自前端自身。此时路由称为前端路由。(PS:SPA网站虽然只有一个网页,但是同时会存在多个HTML片段,这些HTML片段是作为SPA单页面展示区的内容的,一般来说这些HTML片段会和URL组成路由保存在js文件中,然后SPA单页面再引入该js文件即可。)
锚链接与URL中的hash值
那么输入什么样的URL,才不会导致网页刷新呢?
之前我们学习a标签时,知道a标签的href支持传入一个锚链接,所谓锚链接就是一个#id,点击超链接就可以将网页首部定位到对应id的标签上。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
ul {position:fixed;}
a {color: white;}
div {height: 950px;}
#box1 {background-color: skyblue;}
#box2 {background-color: seagreen;}
#box3 {background-color: pink;}
</style>
</head>
<body>
<ul>
<li><a href="#box1">box1-skyblue</a></li>
<li><a href="#box2">box2-seagreen</a></li>
<li><a href="#box3">box3-pink</a></li>
</ul>
<div id="box1"></div>
<div id="box2"></div>
<div id="box3"></div>
</body>
</html>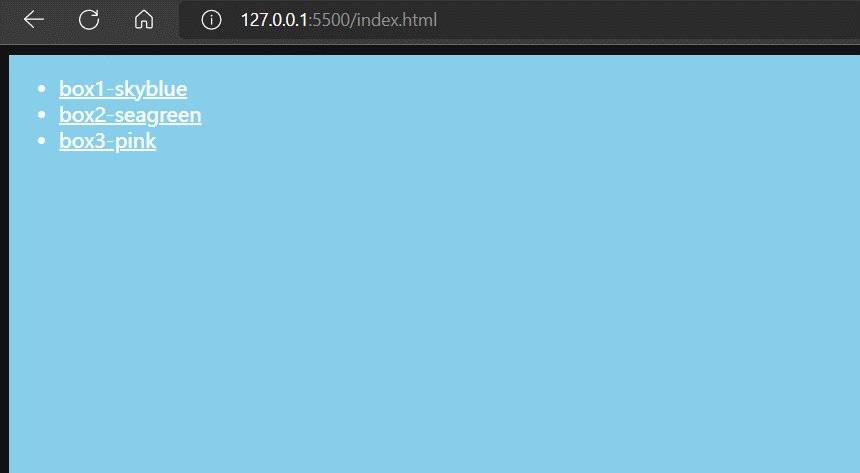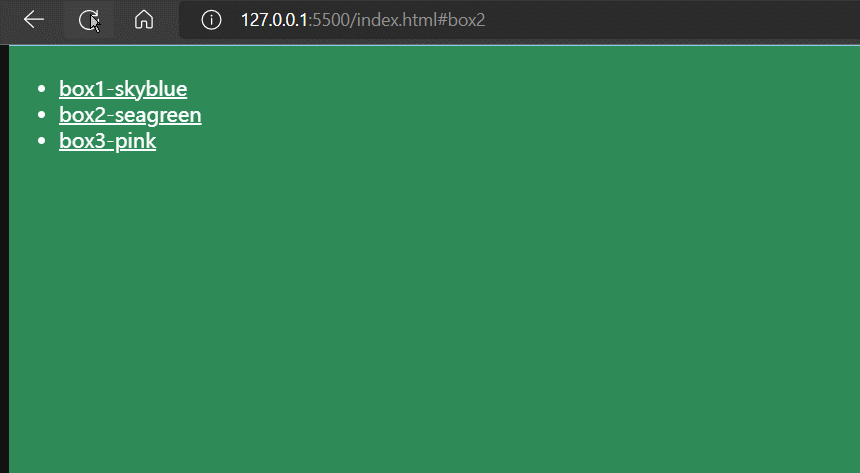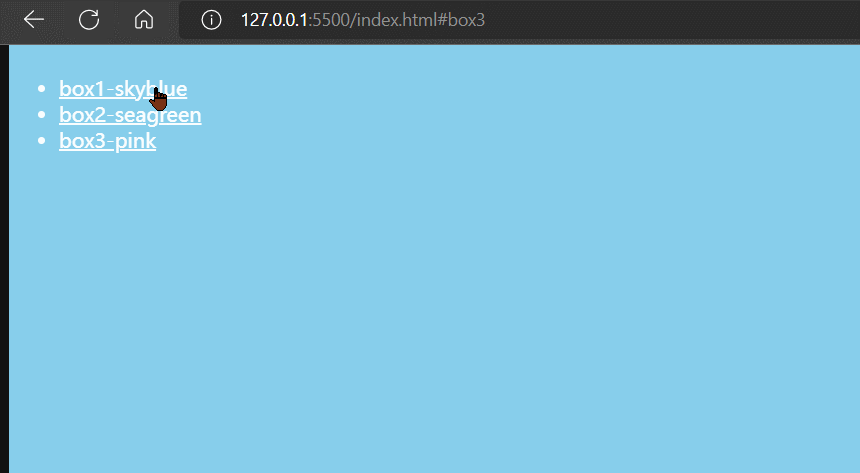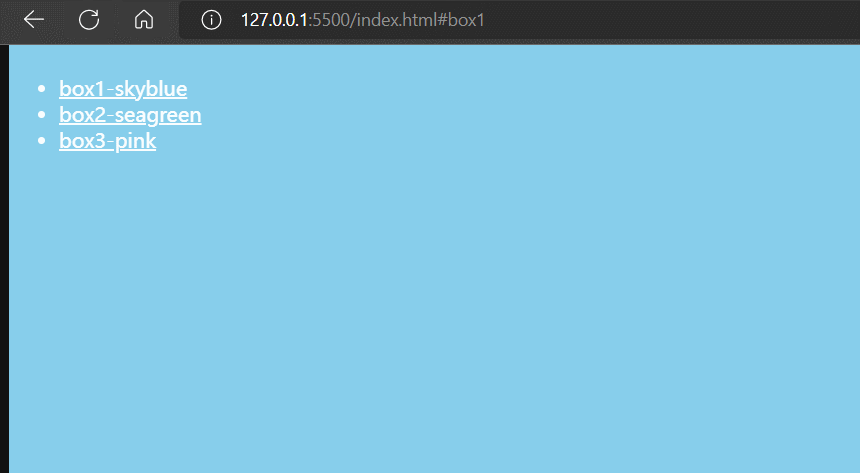
通过上面例子我们可以发现, 当我们点击锚链接时,不仅网页首部定位到对应id的标签上,而且浏览器的地址栏的URL也发生了变化,比如
初始时,浏览器地址栏的URL为
http://127.0.0.1:5500/index.html当我们点击锚链接#box2后,浏览器地址栏的URL为
http://127.0.0.1:5500/index.html#box2并且,地址栏URL改变了,并没有导致网页刷新。
⭐这是因为URL中#以后的部分(包含#)是URL的hash值,单纯变更URL的hash值,浏览器是不会刷新网页的。这是浏览器内置的一个特性。
⭐另外,如果我们强制刷新对应带有hash的URL的网页,浏览器虽然会发送HTTP GET请求到服务器,但是请求URL中不会携带hash值,即服务器不会收到URL的hash值。
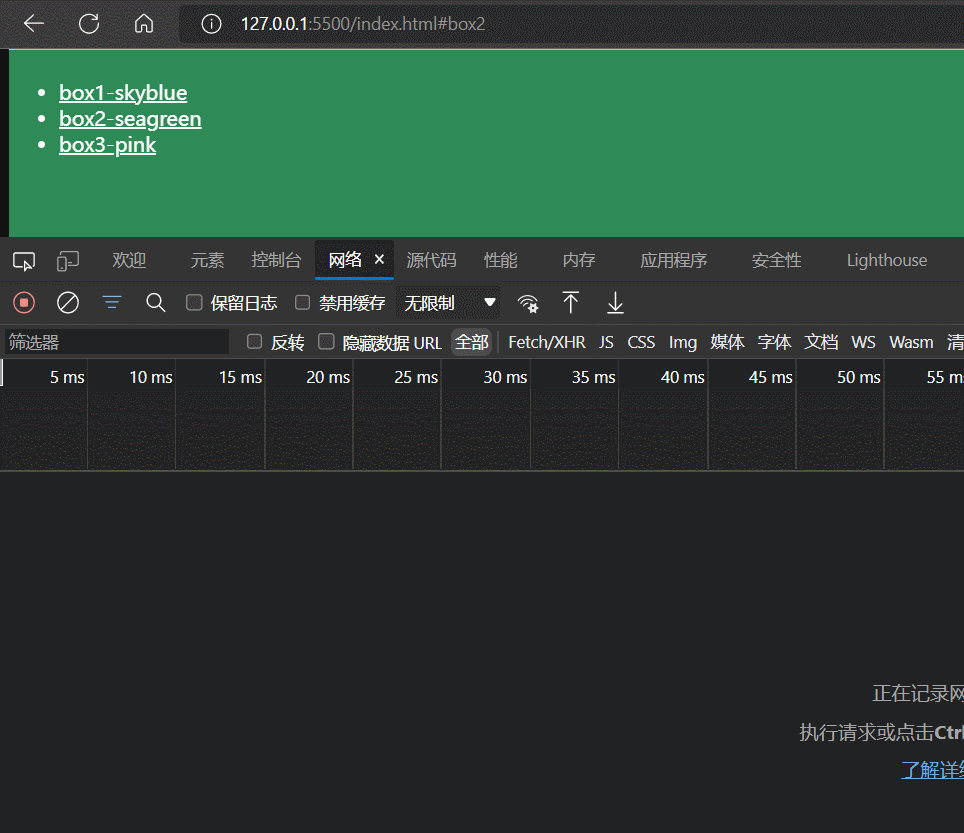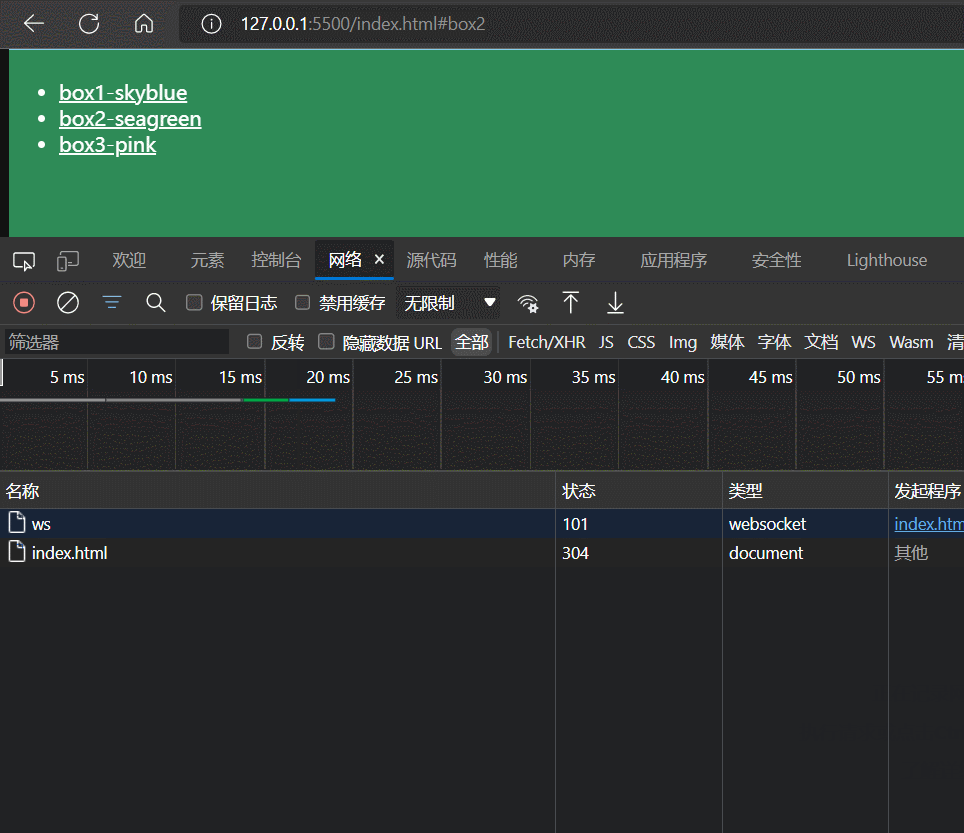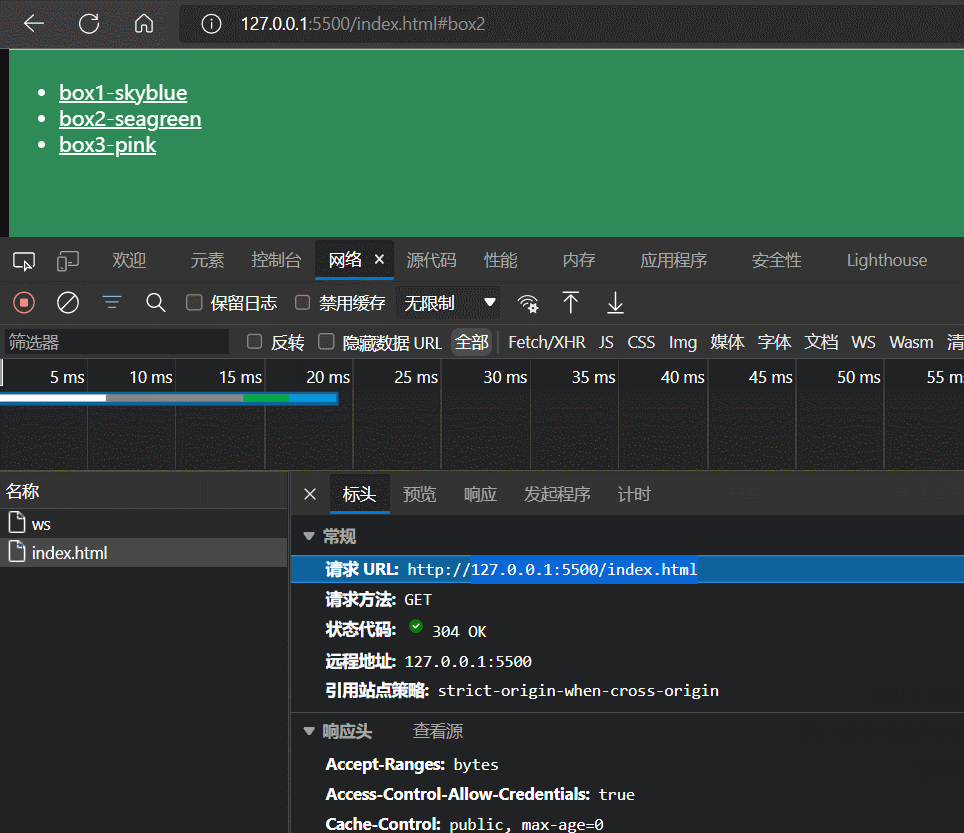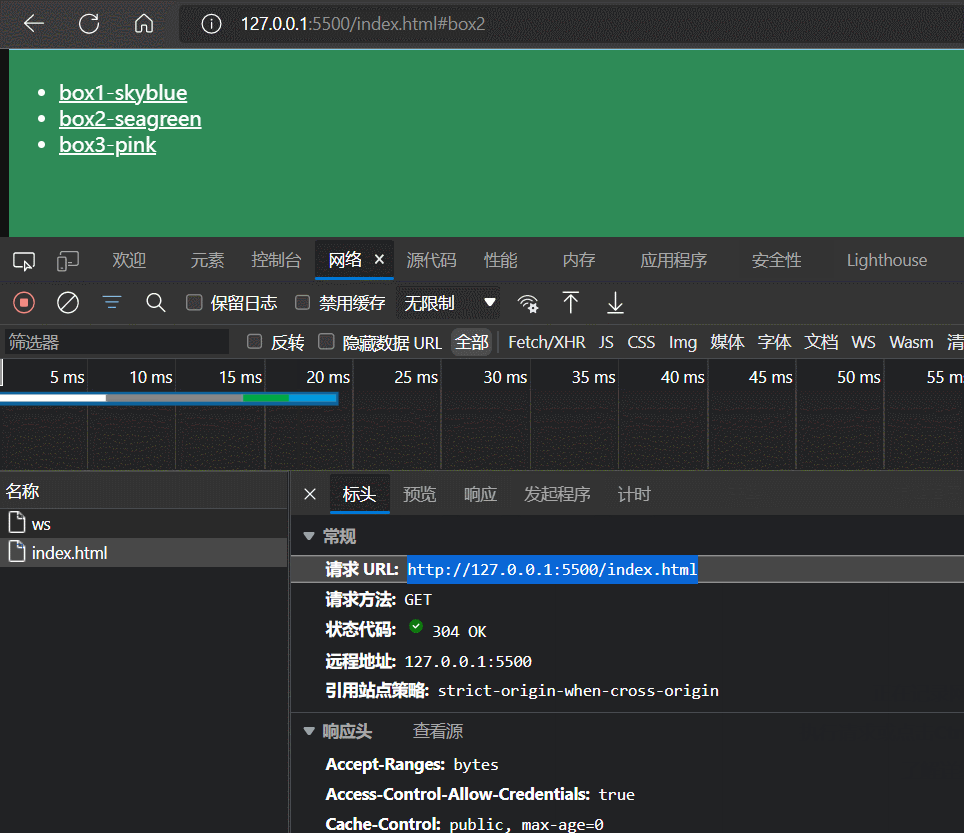
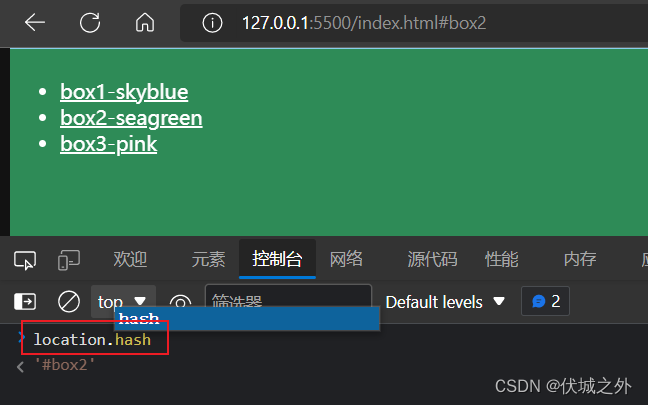
⭐我们可以通过window.location对象获取到当前地址栏URL的hash值
通过hashchange事件实现前端路由
浏览器有一个原生内置事件hashchange,如果当前网页的URL的hash值改变,则会触发hashchange事件,此时我们就可以实现前端路由了
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<ul>
<li><a href="#/home">主页</a></li>
<li><a href="#/about">关于</a></li>
</ul>
<div id="router-view"></div>
<script>
// 定义路由
const routes = [
{
hash: '',
html: '<h1>这是DEFAULT内容</h1>'
},
{
hash: '#/home',
html: '<h1>这是HOME内容</h1>'
},
{
hash: '#/about',
html: '<h1>这是ABOUT内容</h1>'
}
]
window.addEventListener('load', ()=>{alert('页面刷新了')}) // 检测网页是否刷新
window.addEventListener('DOMContentLoaded', onHashChange)
window.addEventListener('hashchange', onHashChange)
function onHashChange(){
// 当URL的hash改变时,找打对应hash的HTML片段
const {html} = routes.find(route => {
return route.hash === location.hash
})
// 将对应HTML片段更新到router-view中
const routerView = document.querySelector('#router-view')
routerView.innerHTML = html
}
</script>
</body>
</html>
编程式导航
目前我们已经根据hashchange事件简单实现了前端路由,但是还有一点美中不足的就是:我们当前只能依赖于a标签锚链接来改变URL中的hash,难道我们所有的导航都要用a标签写吗?
其实我们将a标签锚链接改变URL的hash的方式,叫做“声明式导航”。
除了声明式导航,还有“编程式导航”,编程式导航指的是通过编写代码来改变地址栏中的URL。
基于window.location.hash可读可写属性来实现URL hash的变更
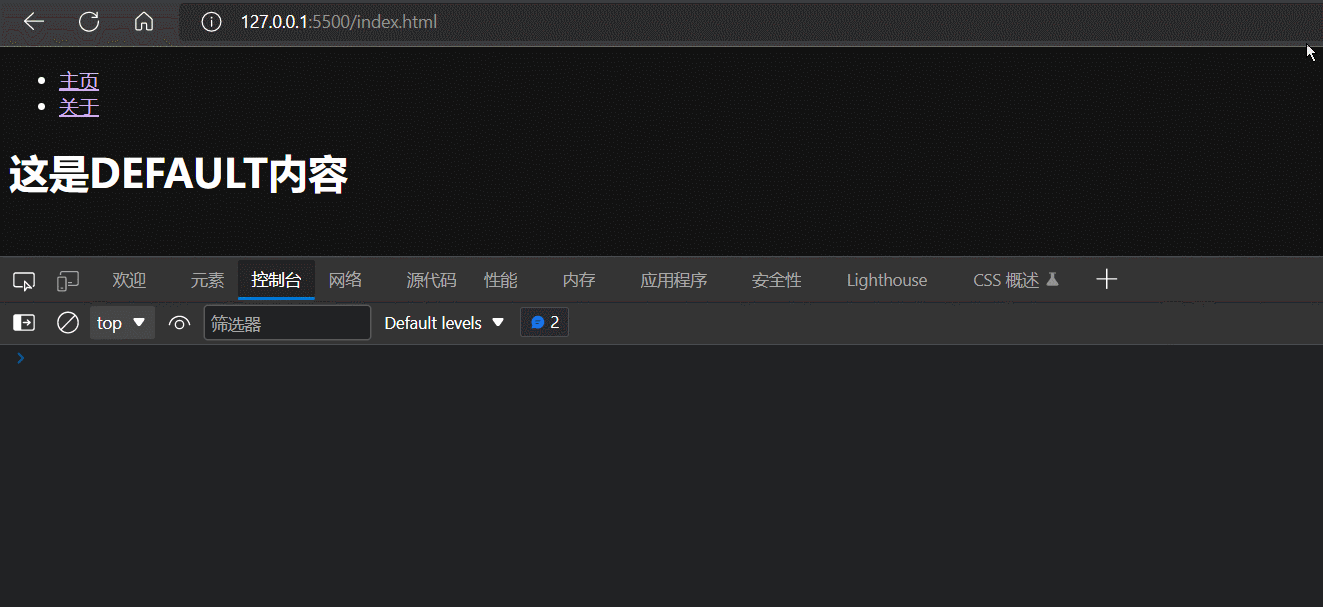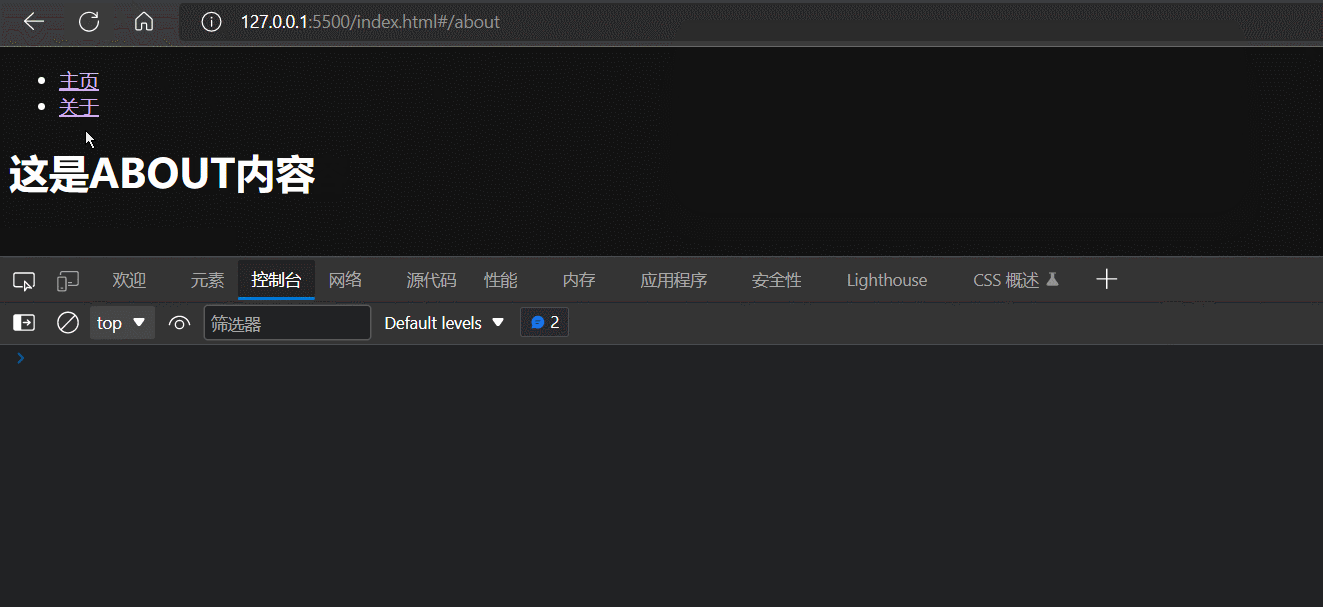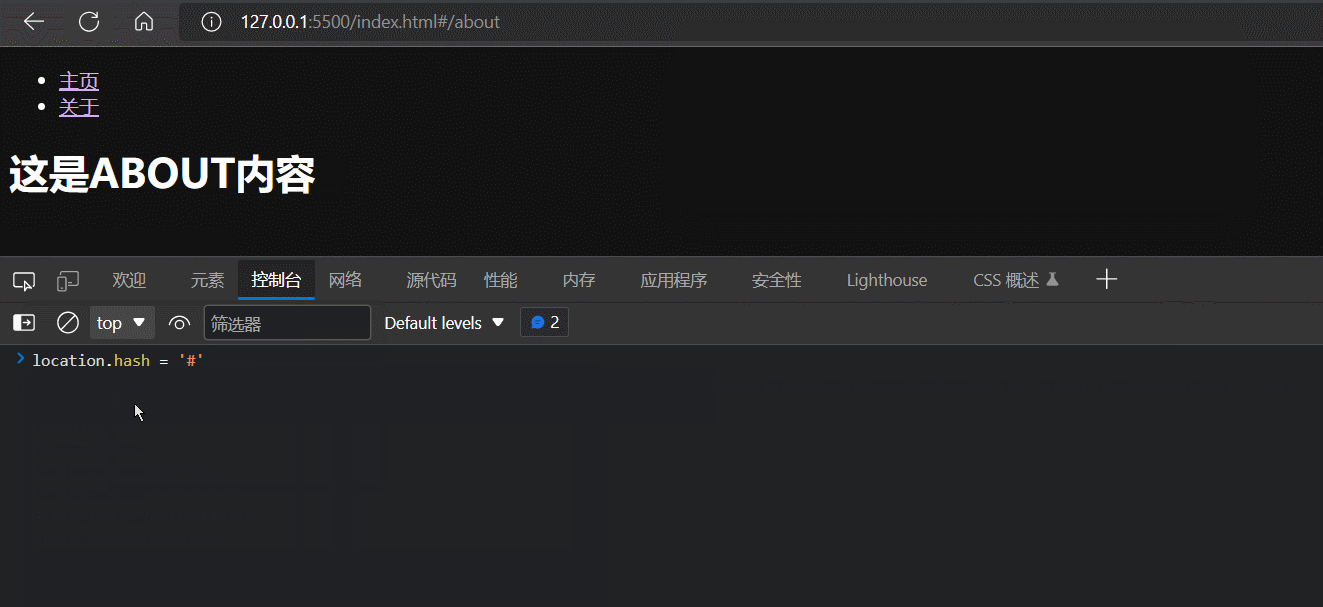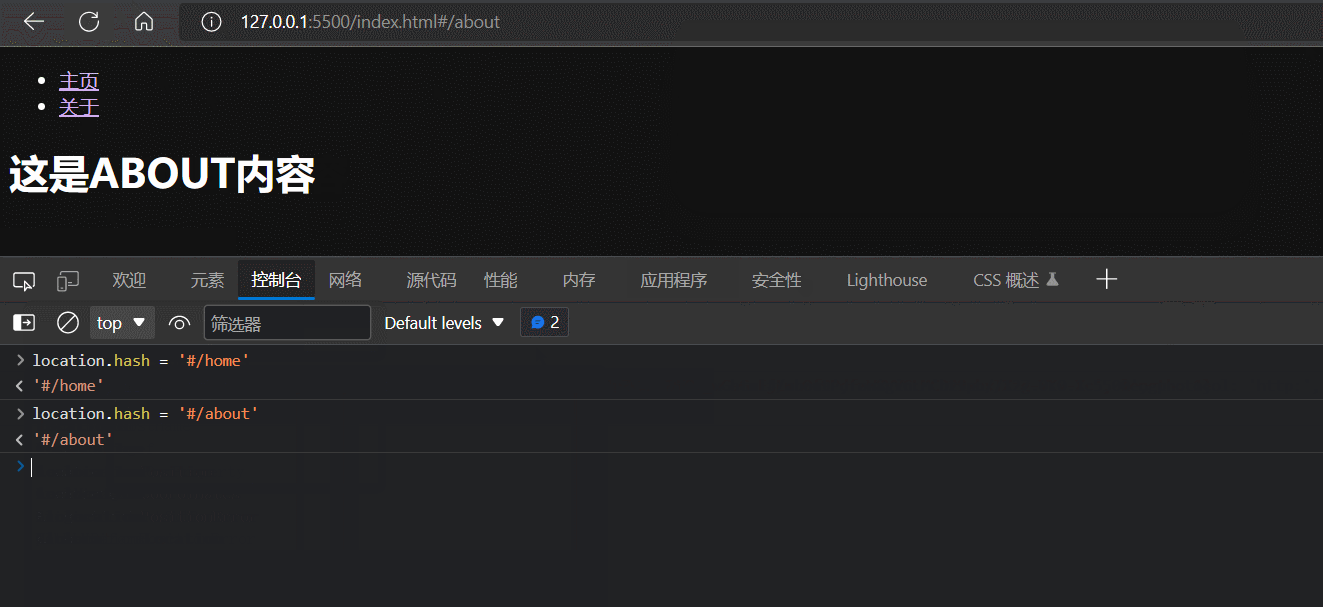
可以发现,window.location.hash不仅可以(网页无刷新地)改变地址栏的URL的hash,还可以触发hashchange事件
基于window.history.pushState方法或者replaceState方法实现URL hash的变更
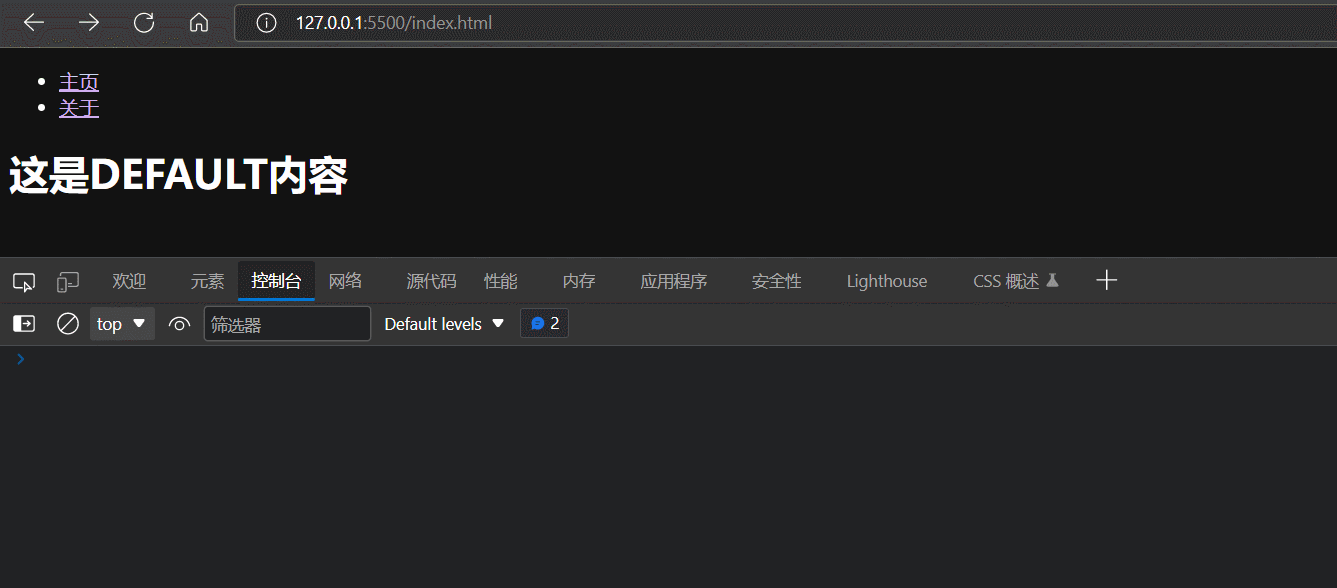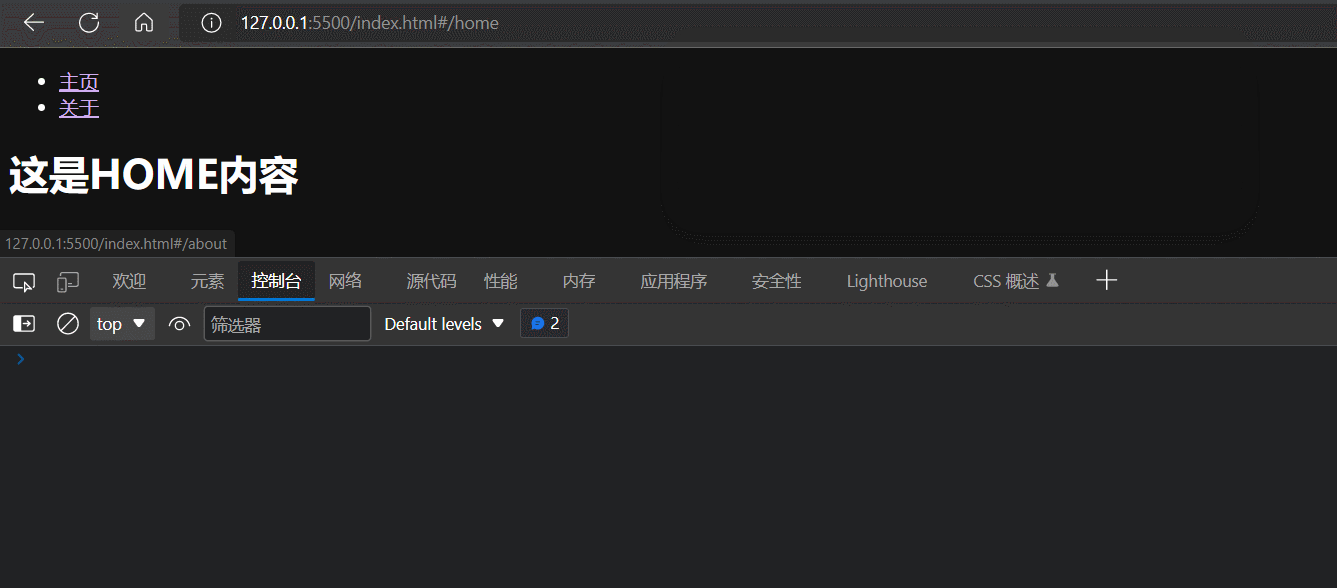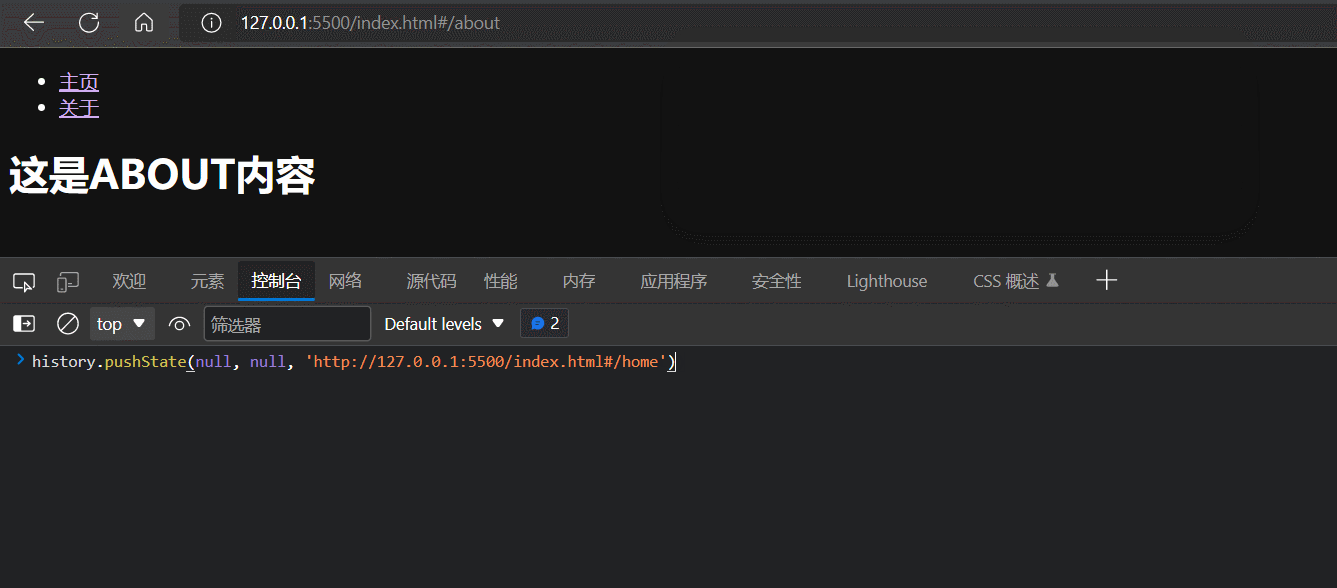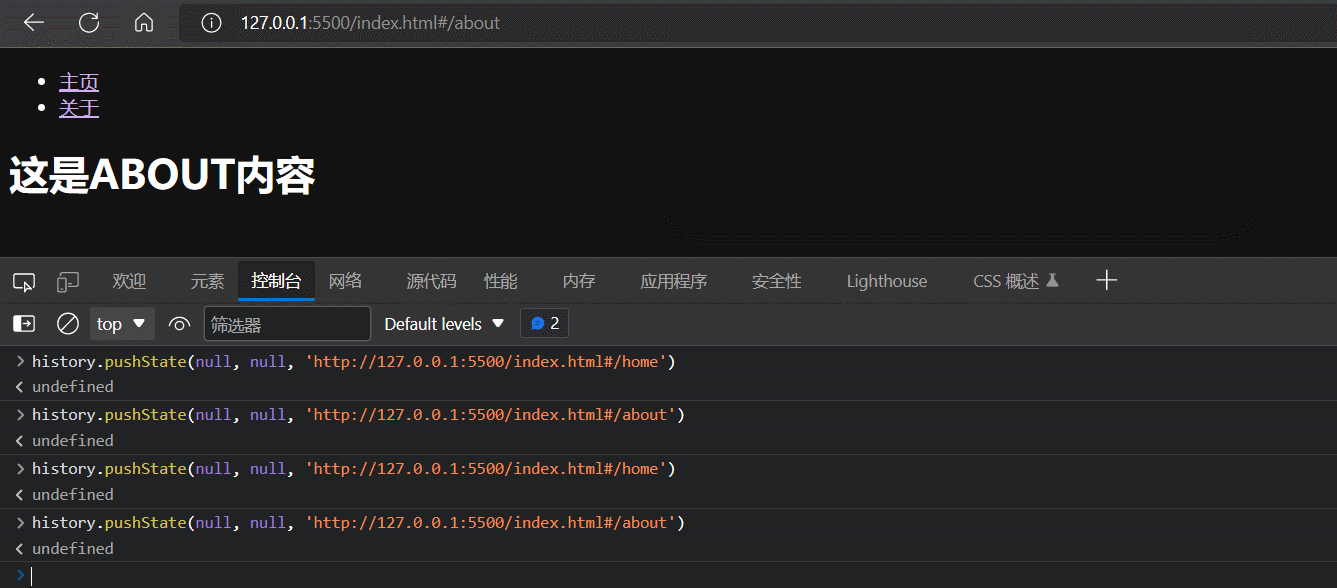
可以发现,window.history.pushState方法或者replaceState方法只能(网页无刷新地)改变地址栏的URL值,但是不能触发hashchange事件。
为什么window.history.pushState或replaceState不能触发hashchange事件呢?因为它们改变的是整个URL的值,而不是URL的hash值。
下面代码用编程式导航,代替了声明式导航,最终效果一致
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<ul>
<!-- <li><a href="#/home">主页</a></li> -->
<!-- <li><a href="#/about">关于</a></li> -->
<li><button onclick="location.hash = '#/home'">主页</button></li>
<li><button onclick="changeURL('#/about')">关于</button></li>
</ul>
<div id="router-view"></div>
<script>
// 定义路由
const routes = [
{
hash: '',
html: '<h1>这是DEFAULT内容</h1>'
},
{
hash: '#/home',
html: '<h1>这是HOME内容</h1>'
},
{
hash: '#/about',
html: '<h1>这是ABOUT内容</h1>'
}
]
window.addEventListener('load', ()=>{alert('页面刷新了')}) // 检测网页是否刷新
window.addEventListener('DOMContentLoaded', onHashChange)
window.addEventListener('hashchange', onHashChange)
function onHashChange(){
// 当URL的hash改变时,找打对应hash的HTML片段
const {html} = routes.find(route => {
return route.hash === location.hash
})
// 将对应HTML片段更新到router-view中
const routerView = document.querySelector('#router-view')
routerView.innerHTML = html
}
function changeURL(hash){
history.pushState(null, null, location.origin + hash)
// 由于window.history.pushState或replaceState无法变更URL的hash后无法触发hashchange事件
// 而我们触发hashchange事件是为了执行其事件回调
// 所以我们可以直接在pushState或replaceState修改完hash后,自己执行hashchange事件回调
onHashChange()
}
</script>
</body>
</html>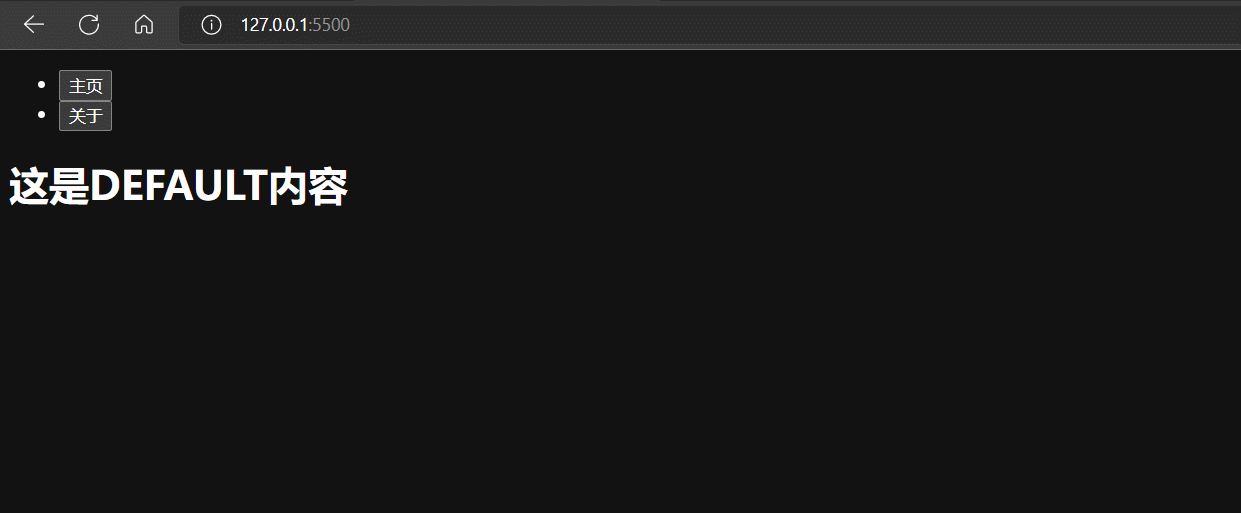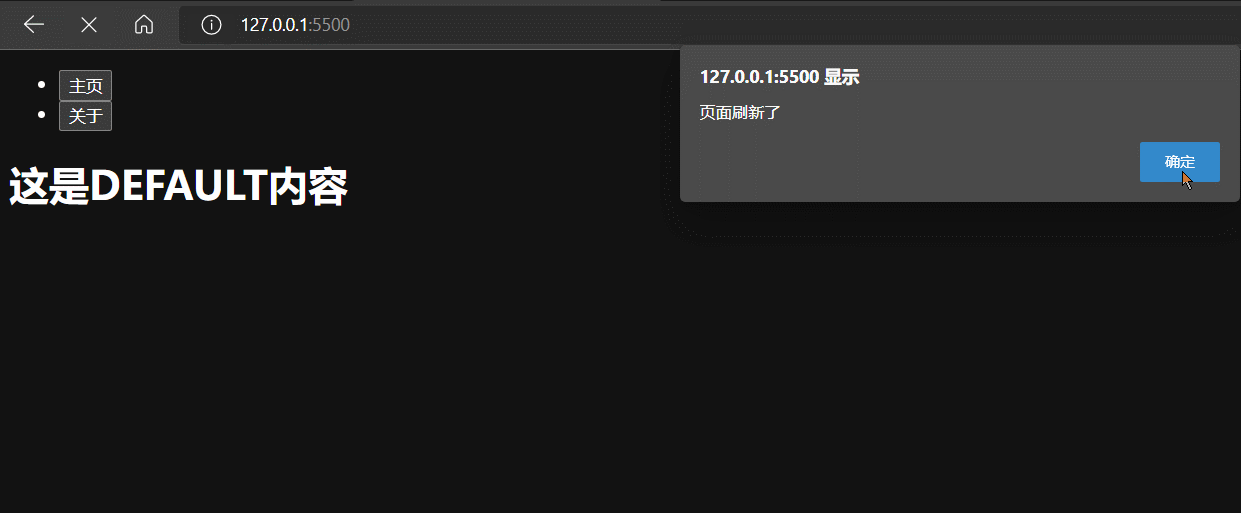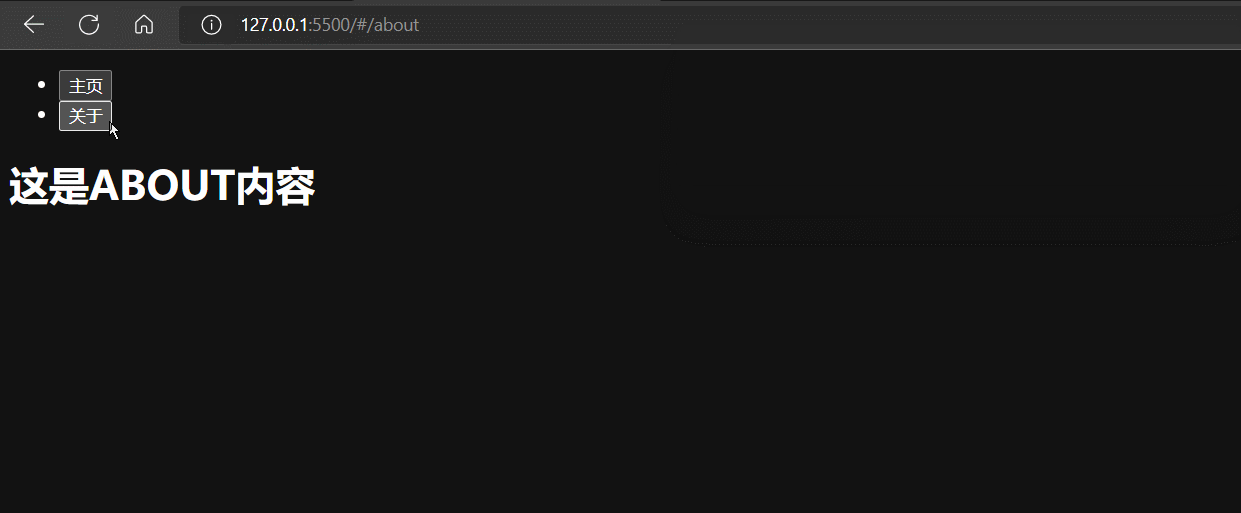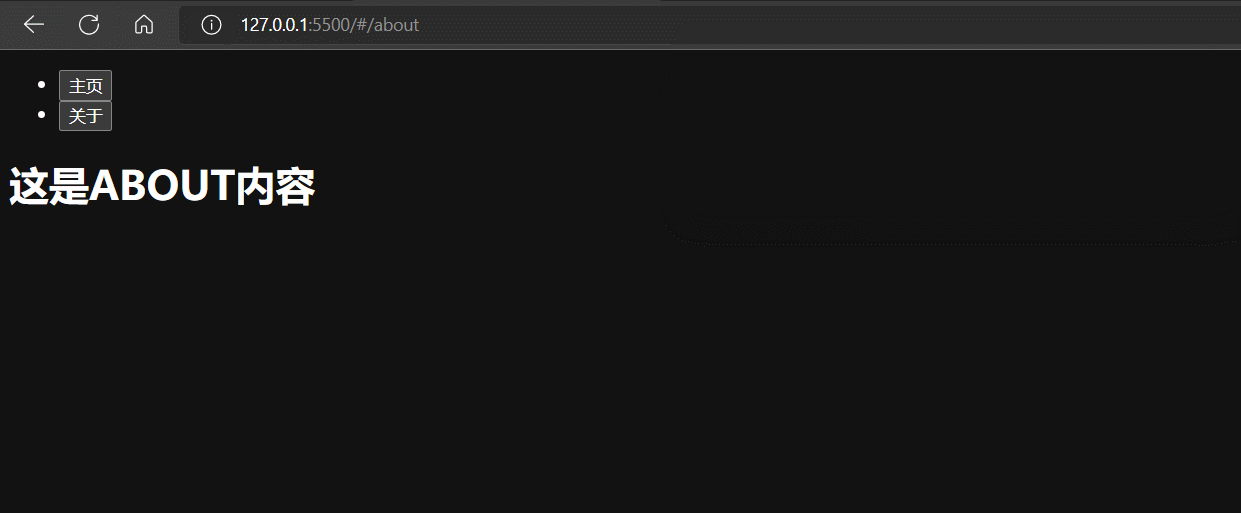
浏览器历史记录&前进后退功能
我们都知道浏览器有一个历史记录,每当我们在浏览器访问一个网页,该网页的URL就会被记录到浏览器的历史记录中。
那么仅变更了hash的URL会被放入历史记录吗?
通过实践,我们可以发现,无论是a标签锚链接,还是location.hash,还是history.pushState修改了URL的hash后,对应的URL都会被加入历史记录中。
浏览器的历史记录本质是一个栈结构,最早访问的网页的URL存储在栈底,最后访问的网页的URL存储在栈顶。
我们可以利用浏览器的前进、后退菜单键,来调出历史栈中的URL。
而URL入历史栈的方式有两种:
- push模式:该模式URL正常压入栈顶
- replace模式:该模式URL会覆盖已存在的栈顶URL
而我们通过
- a标签锚链接
- location.hash
- history.pushState
修改的URL,其实都是以push模式入历史栈。
而只有history.replaceState支持修改的URL以replace模式入历史栈

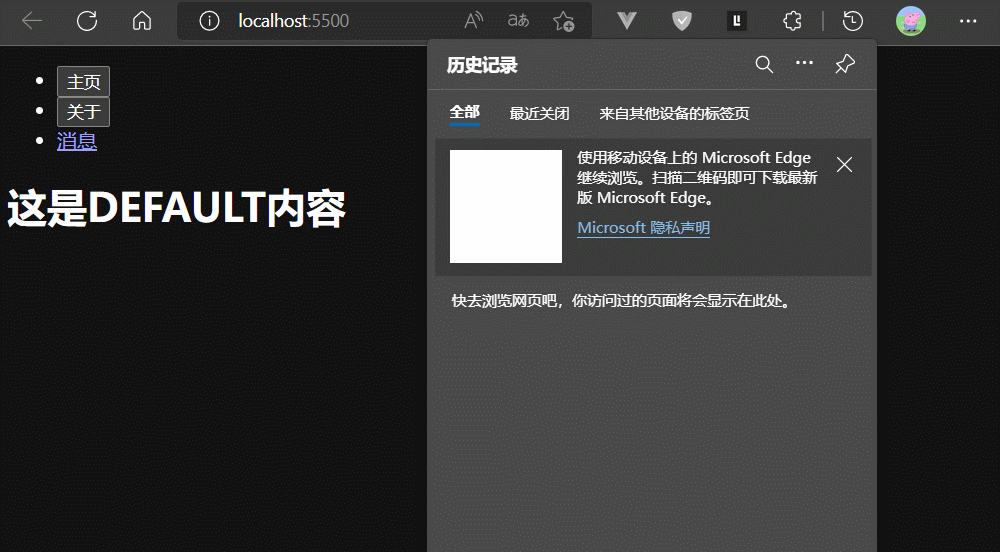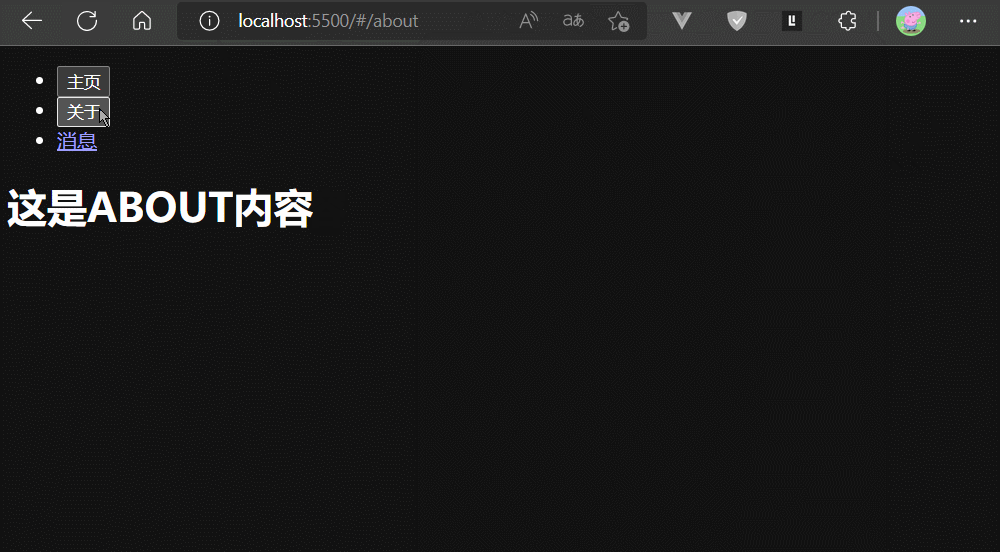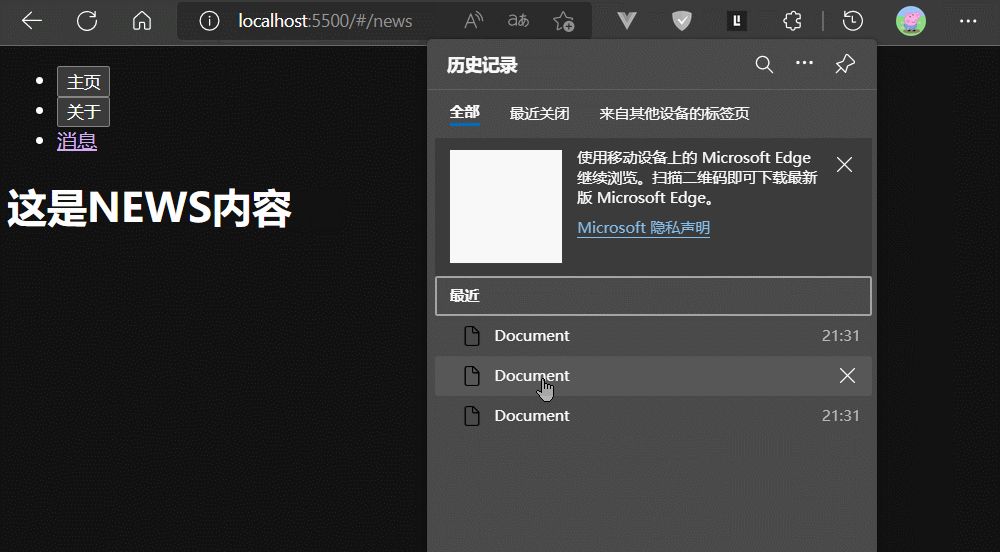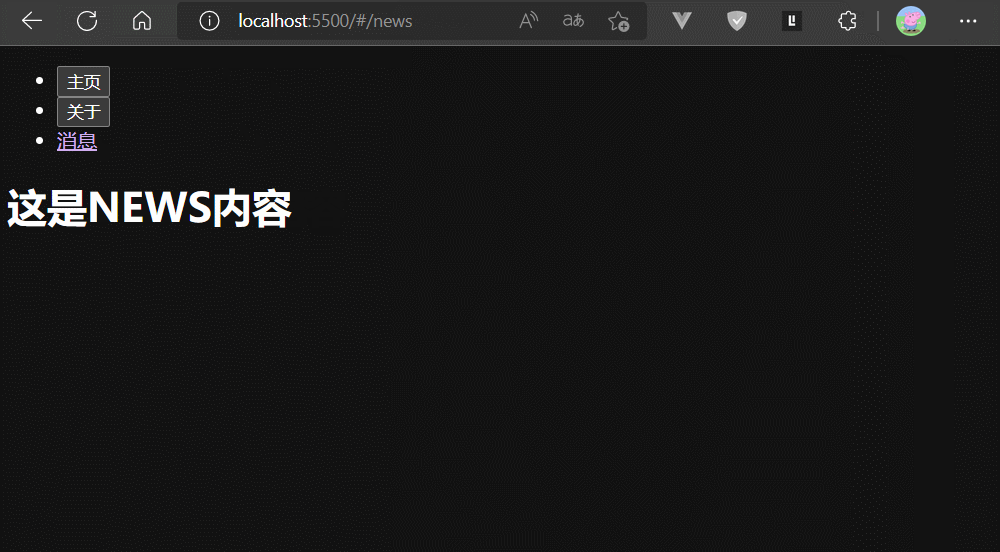
通过上面例子,我们可以发现历史记录中:hash为#/home的URL 被 hash为#/about的URL覆盖了
Vue与SPA
通过Vue认识SPA单页面丰富内容的来源
我们基于Vue脚手架打包后的项目,其实就是一个SPA项目,因为打包代码中只有一个index.html。
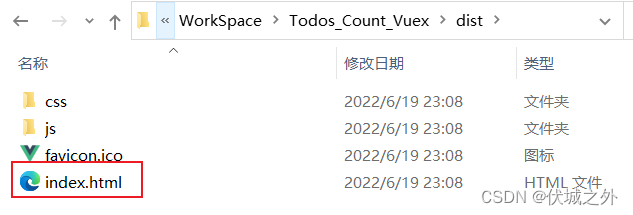
我们来通过Vue创建的SPA项目来验证几个SPA的疑问:
SPA网站虽然只有一个网页,但是有非常多的HTML代码片段,这些HTML代码片段一般保存在js文件中,然后被SPA单页面引入,被在适当时机插入到SPA单页面指定位置。
Vue项目打包后的index.html,原始内容非常简单,但是当被浏览器加载后,则会执行其引入的js文件:app.a0561165.js

在Vue项目中,HTML代码片段是包含在组件模板中的,而组件模板最终都会变转化为虚拟DOM对象

比如上面文件app.a0561165.js就是Vue项目打包后的一个js文件,在该文件中就能找到对应的虚拟DOM对象的痕迹。
而这里的虚拟DOM对象,最终会被转化为真实DOM对象,插入index.html的指定位置。
这就是SPA网站虽然只有一个网页,但是依旧可以展示大量内容的原因。
在Vue中实现前端路由
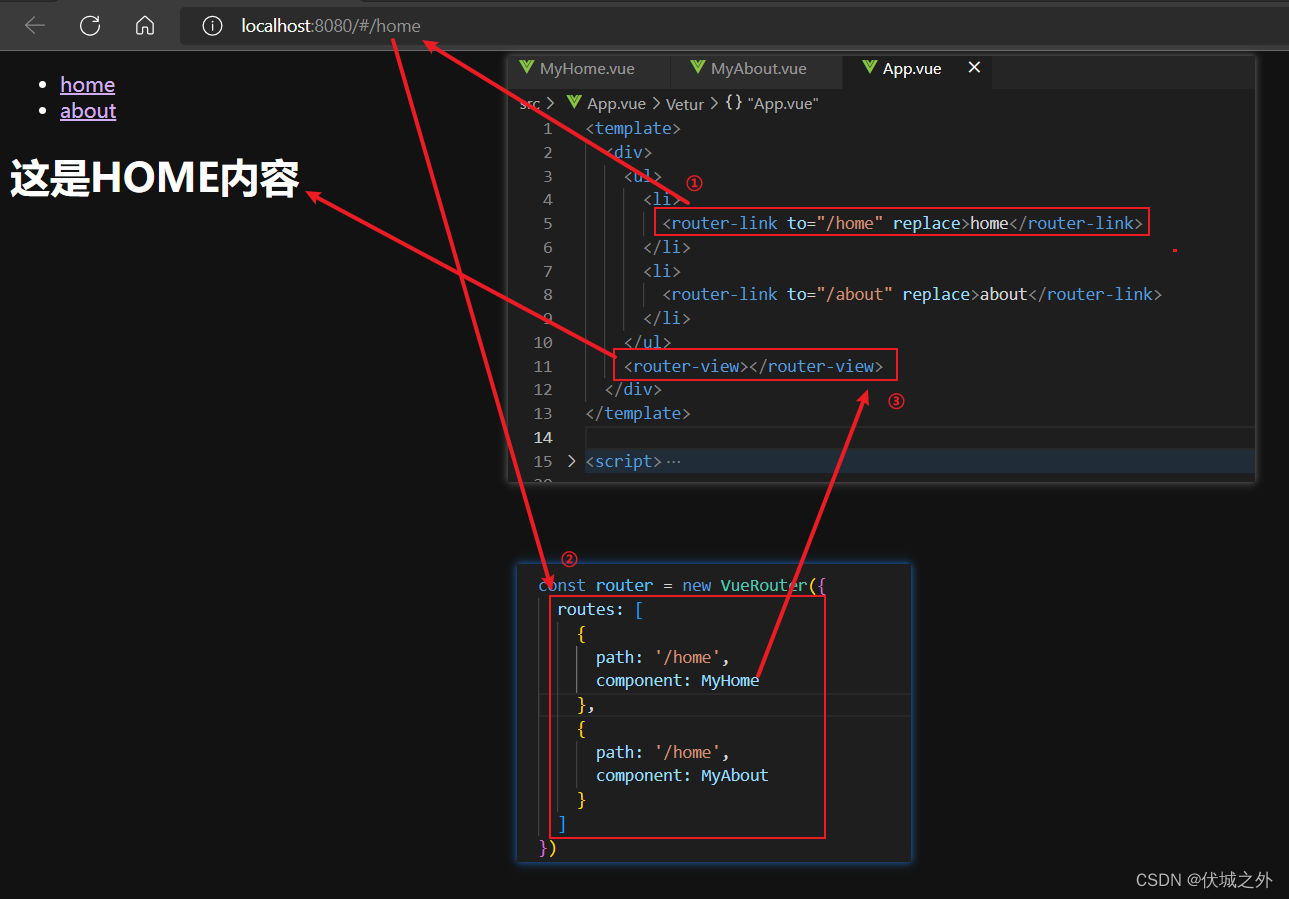
App.vue
<template>
<div>
<ul>
<li><a href="#/home">home</a></li>
<li><a href="#/about">about</a></li>
</ul>
<component :is="componentId"></component>
</div>
</template>
<script>
import MyHome from '@/components/MyHome.vue'
import MyAbout from '@/components/MyAbout.vue'
export default {
name: 'App',
components: {MyHome, MyAbout},
data(){
return {
componentId: null
}
},
methods: {
onHashChange(){
switch(location.hash) {
case '#/home': this.componentId = MyHome; break;
case '#/about': this.componentId = MyAbout; break;
}
}
},
created(){
window.addEventListener('DOMContentLoaded', this.onHashChange)
window.addEventListener('hashchange', this.onHashChange)
}
}
</script>
MyAbout.vue
<template>
<h1>这是ABOUT内容</h1>
</template>
<script>
export default {
name: 'MyAbout'
}
</script>
MyHome.vue
<template>
<h1>这是HOME内容</h1>
</template>
<script>
export default {
name: 'MyHome'
}
</script>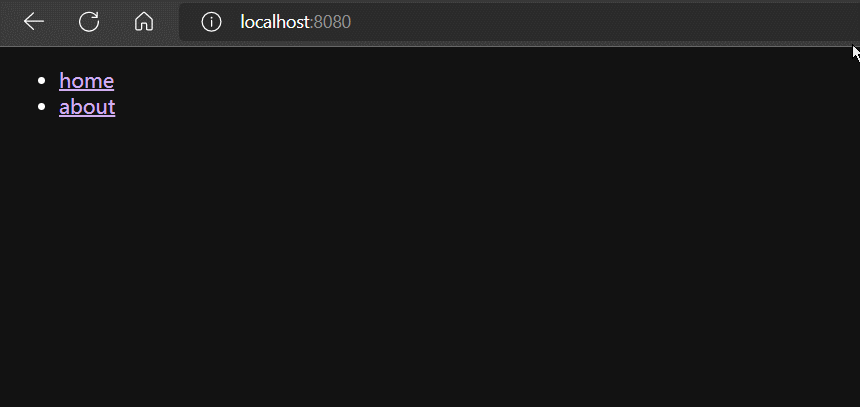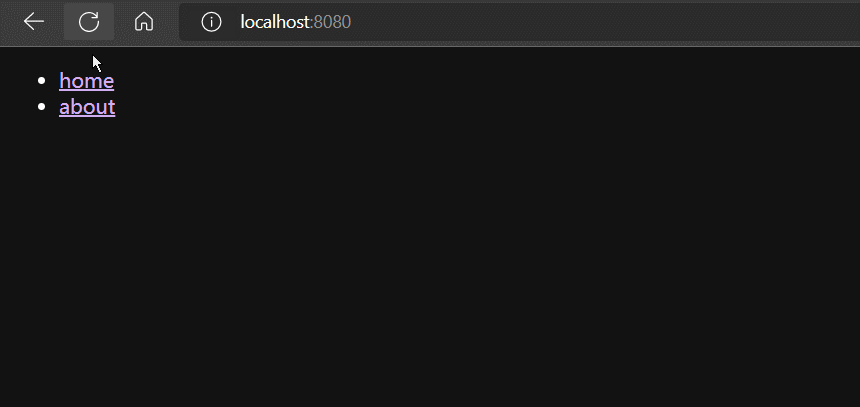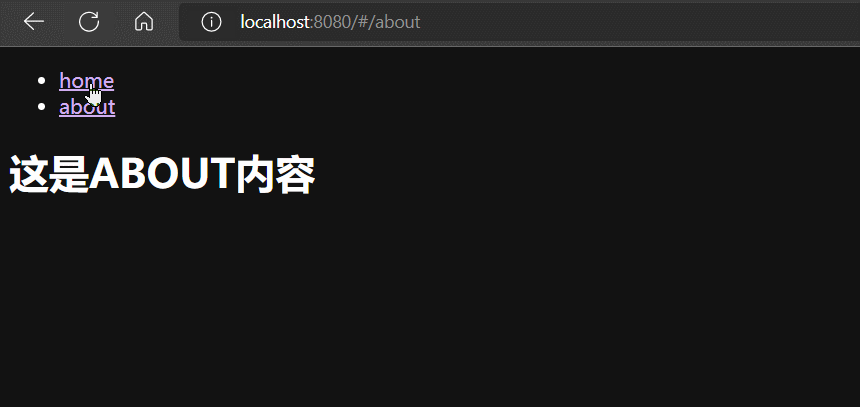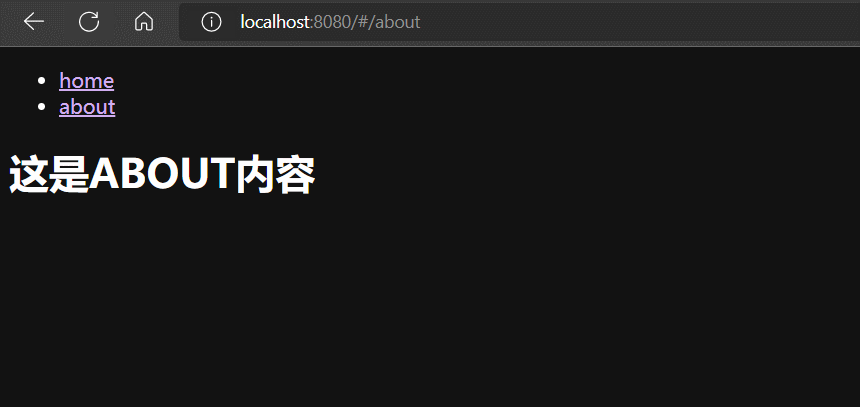
怎么说呢,虽然上面代码也可以在Vue项目中实现前端路由,但是非常地不规范,兼容性也很差,所以为了弥补Vue项目的前端路由能力,Vue官方推出了vue-router包。
Vue Router
安装和配置Vue Router
下载vue-router
Vue2.x的项目需要使用vue-router@3 版本的包,Vue3.x的项目需要使用vue-router@4 版本以上的包。
vue-router包需要被Vue项目在生产环境使用

引入vue-router到项目中
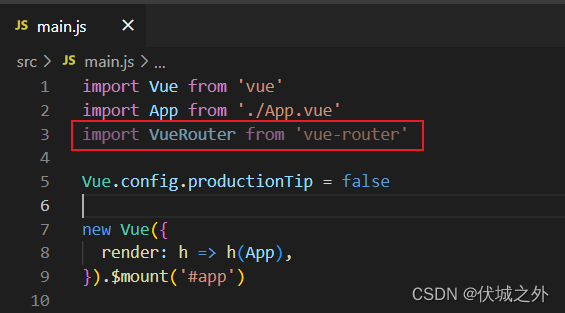
vue-router对外暴露的VueRouter,不仅是一个构造函数,还是一个Vue插件
注册VueRouter插件
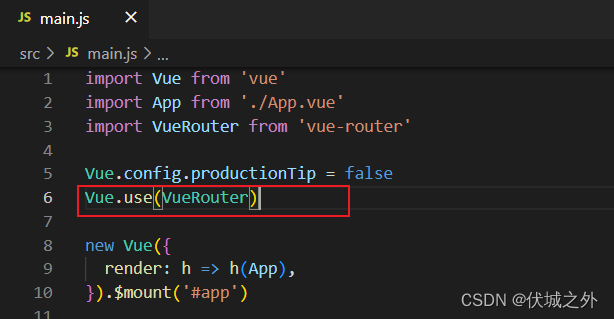
注册VueRouter插件,本质是调用其VueRouter构造函数对象的install方法
本次注册插件,会带来如下影响:
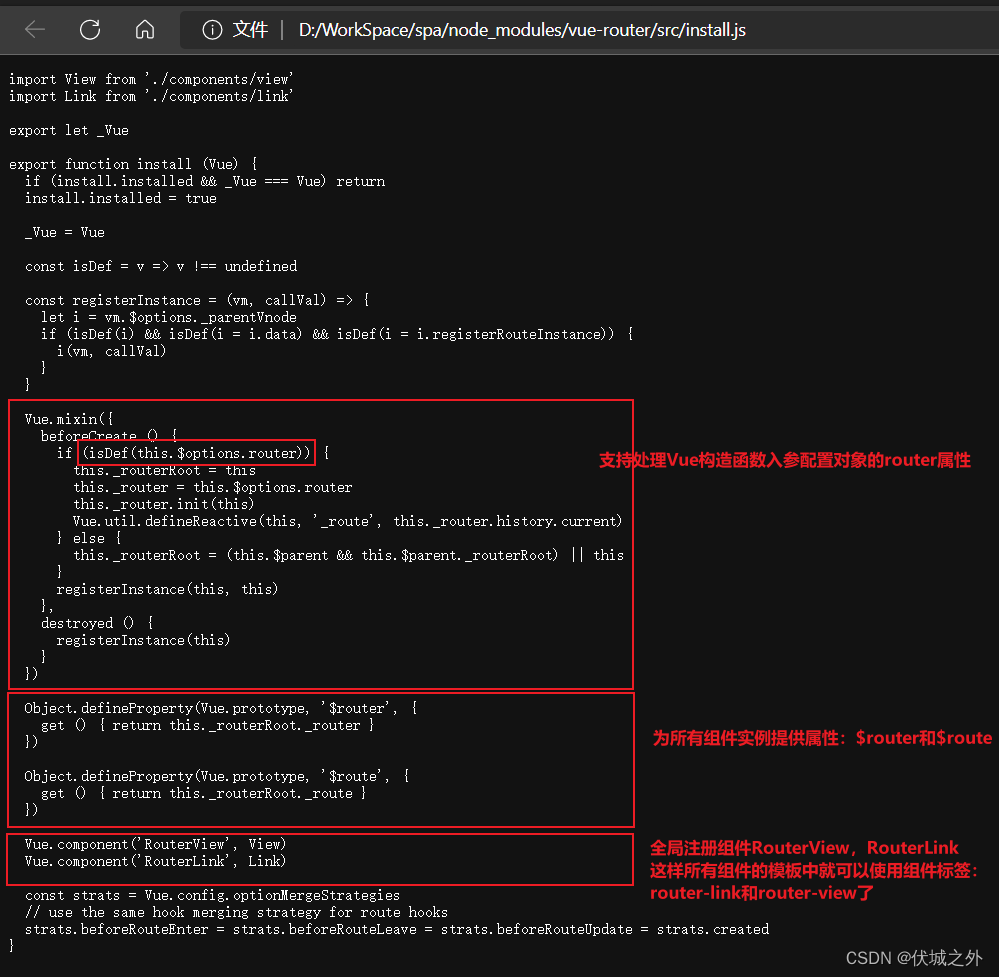
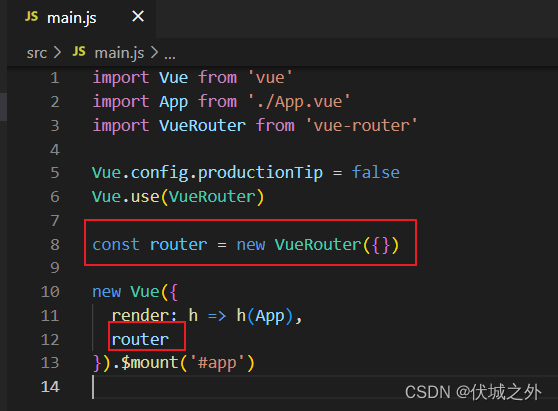
创建VueRouter实例并将其关联vm.$options.router
Vue构造函数入参配置对象,默认是不支持router属性,但是当我们Vue.use(VueRouter)后,Vue构造函数就被追加处理入参options.router属性的能力了。
路由模块
由于Vue Router最终会处理所有的前端路由逻辑,所以安装和配置Vue Router的逻辑写在main.js中,会让main.js变得臃肿,所以Vue官方推荐我们将安装和配置Vue Router的代码写到路由模块 /src/router/index.js中

认识VueRouter
路由器和路由
VueRouter是一个构造函数,它用于创建一个路由器实例。
路由器的第一个工作就是管理SPA前端路由。
在Vue项目中,前端路由指的是:URL中hash地址 与 组件 的对应关系。
http://localhost:5500/index.html#/home
上面URL中:
#/home 是 URL的 hash值
/home 是 URL的 hash地址
routes配置属性
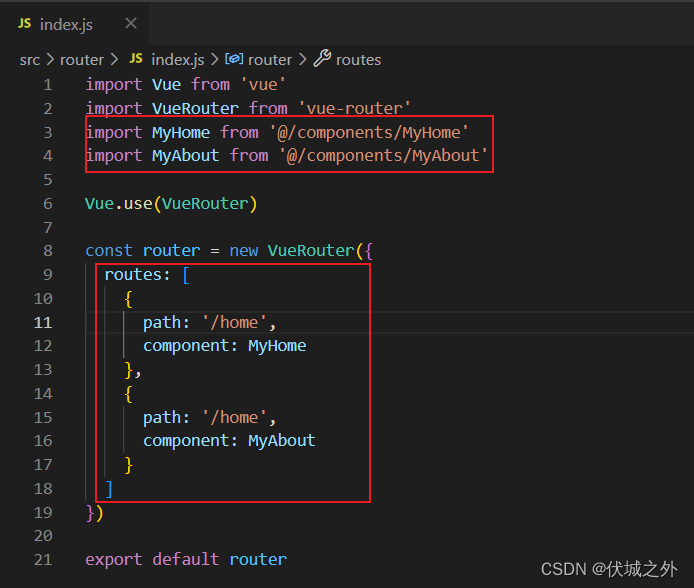
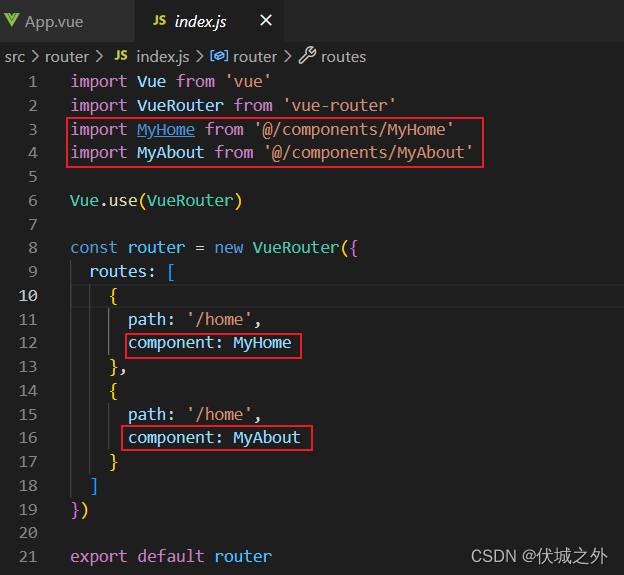
VueRouter构造函数入参配置对象有一个routes配置属性,它是一个数组,数组元素就是被VueRouter实例管理的前端路由对象。
路由对象有两个基础属性path和component,分别标识 hash地址 和 组件
路由器的第二个工作
路由器除了管理路由外,还会时刻监听浏览器地址栏URL的hash地址的变化,一旦hash地址发生改变,则从自身管理的路由中,找到hash地址对应的component组件,并将其渲染到导致hash地址改变的组件中。

此时有两个问题:
- 如何更改浏览器地址栏的URL的hash地址?
- 路由组件应该被渲染到哪里?
router-link
我们知道通过a标签的锚链接可以更改浏览器地址栏中的URL的hash地址,而VueRouter在内部对a标签进行了封装,推出了router-link组件。
router-link组件标签有一个to属性,该属性的值将在router-link标签被点击后,更新为浏览器地址栏URL新的hash地址。

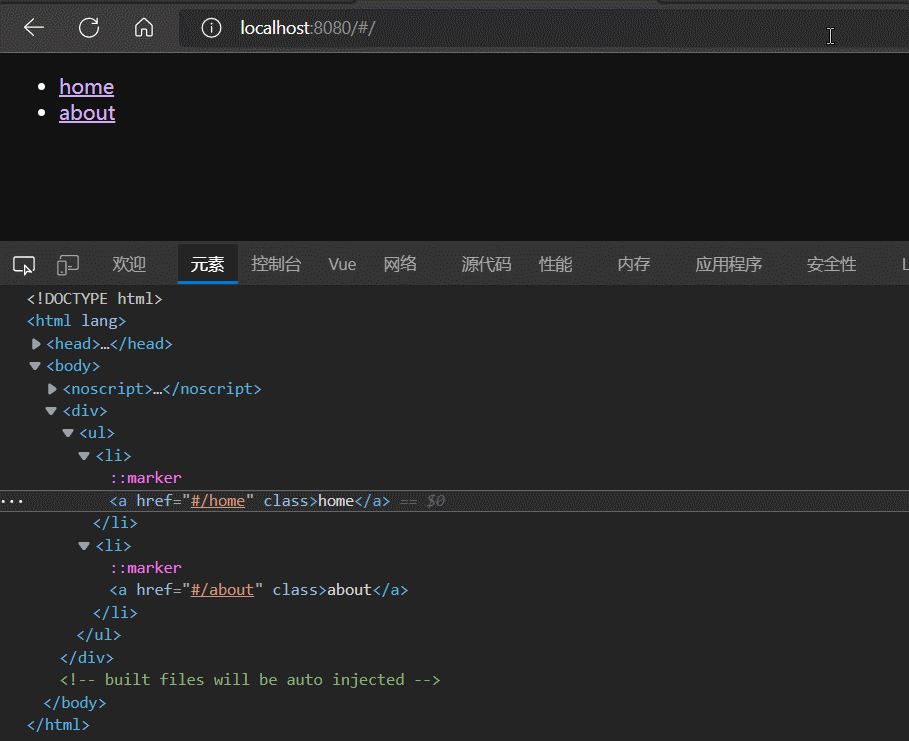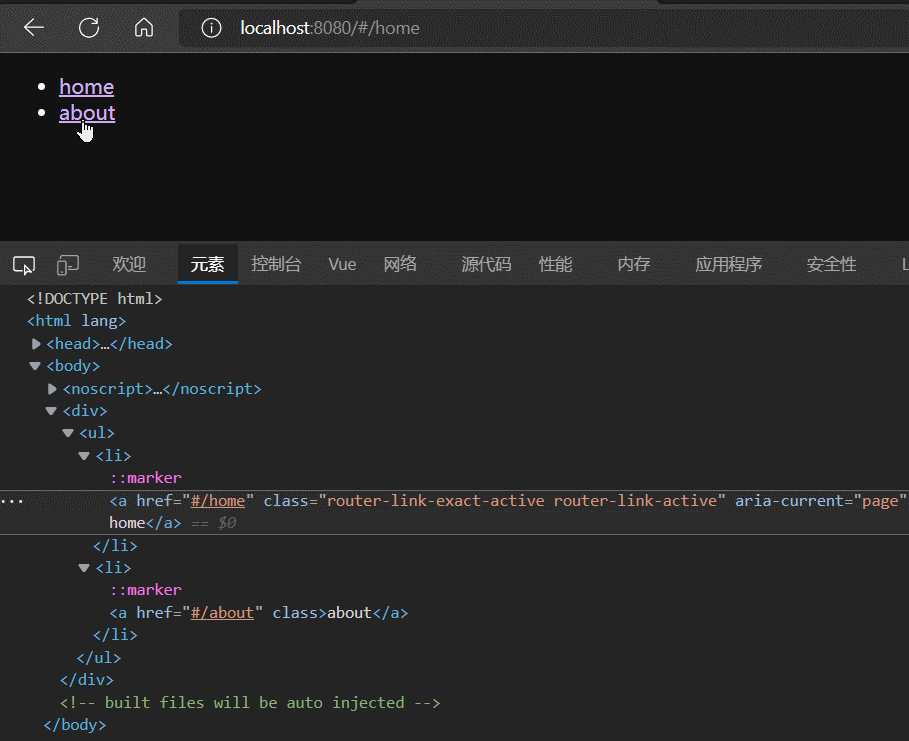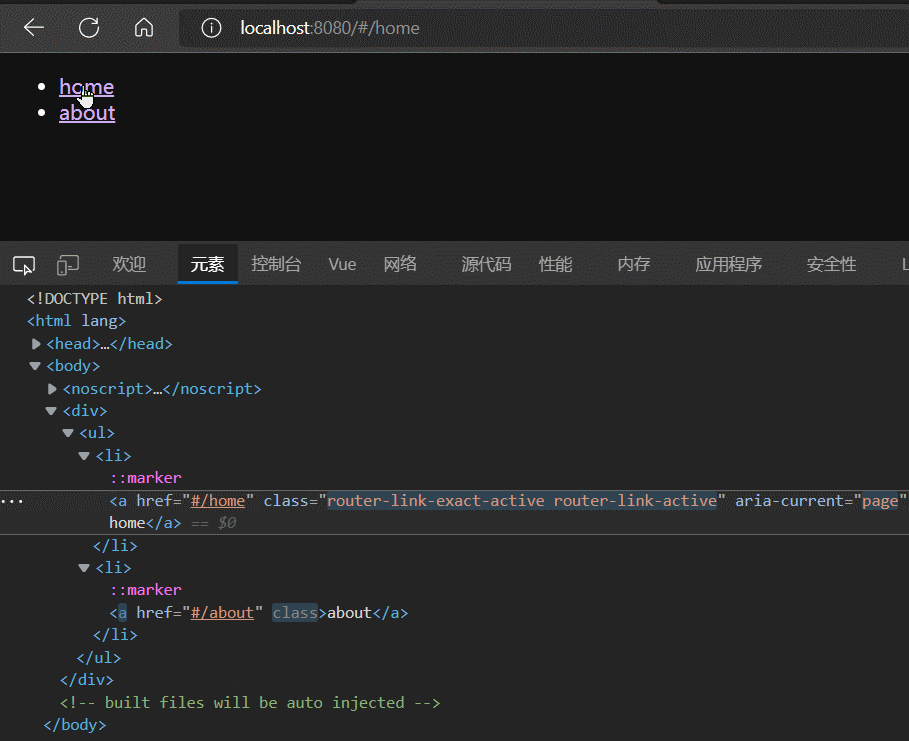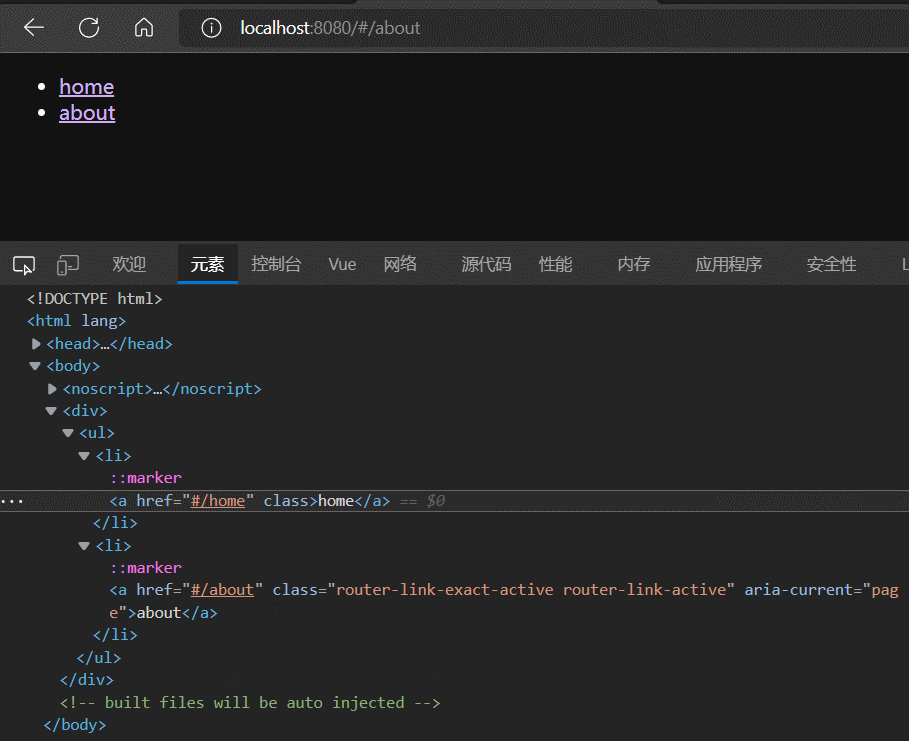
根据实践结果可以发现,router-link标签本质就是一个a标签,router-link的to属性 是对 a标签的href属性的封装。
router-link除了to属性外,还有一个active-class属性,该属性的作用是:为被点击激活的router-link标签添加指定样式(active-class属性值),且具有排他性。
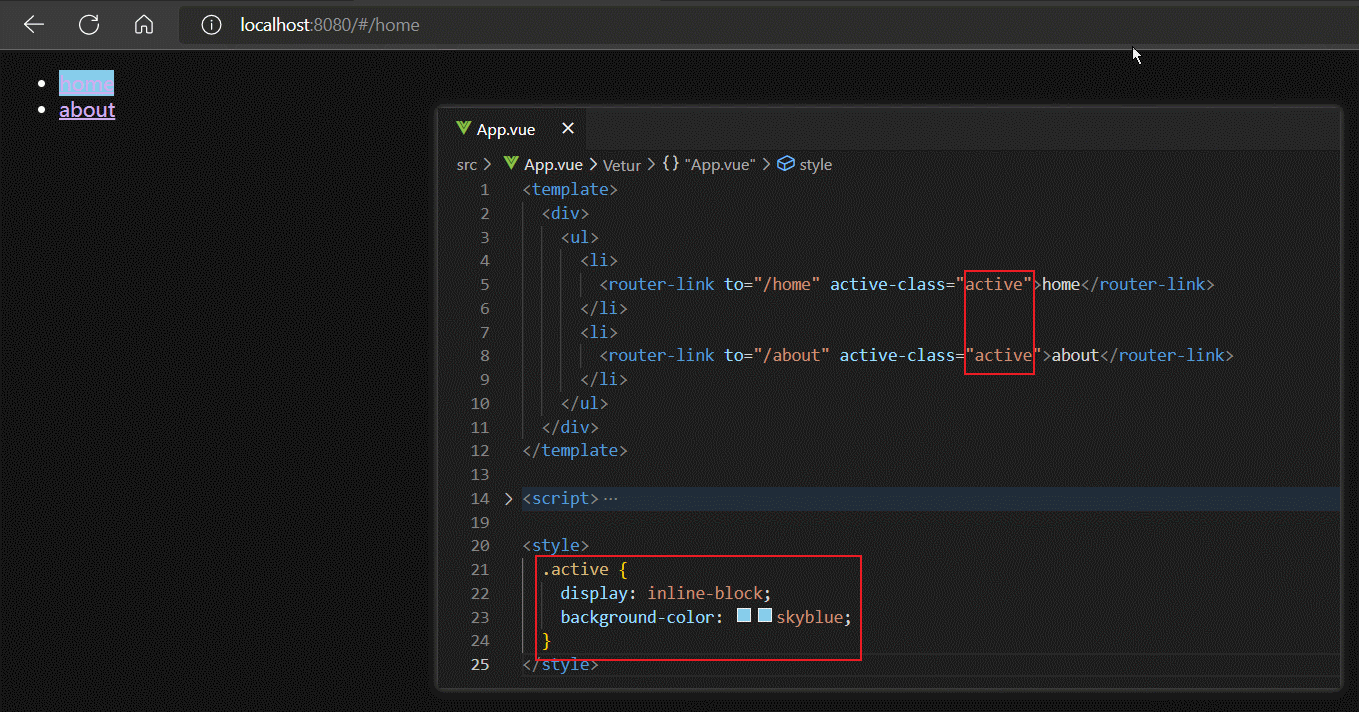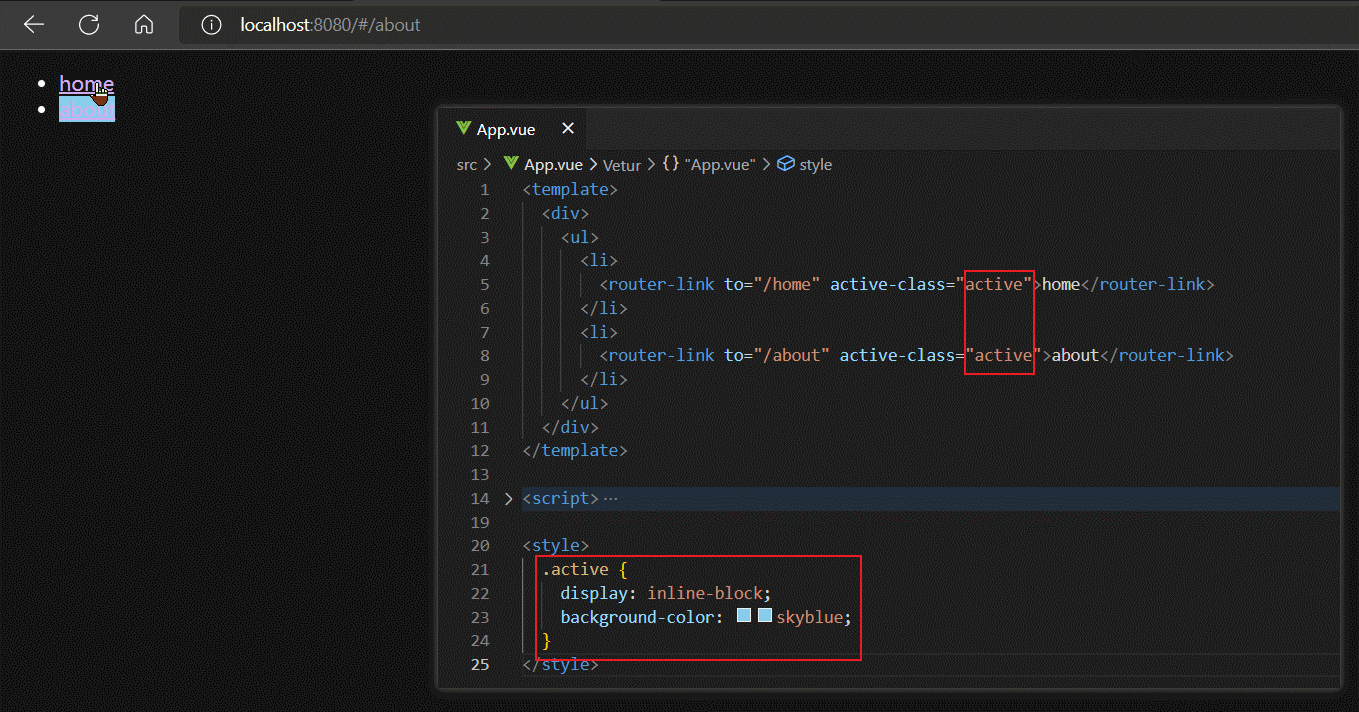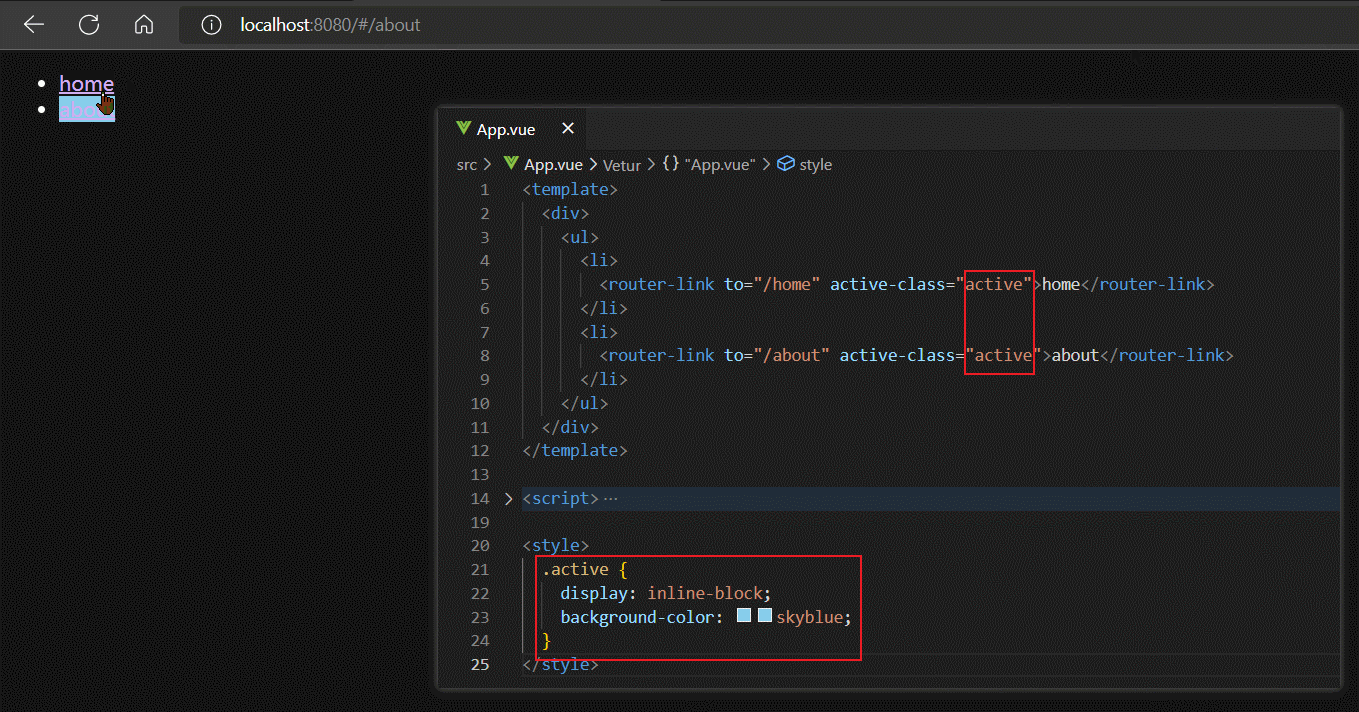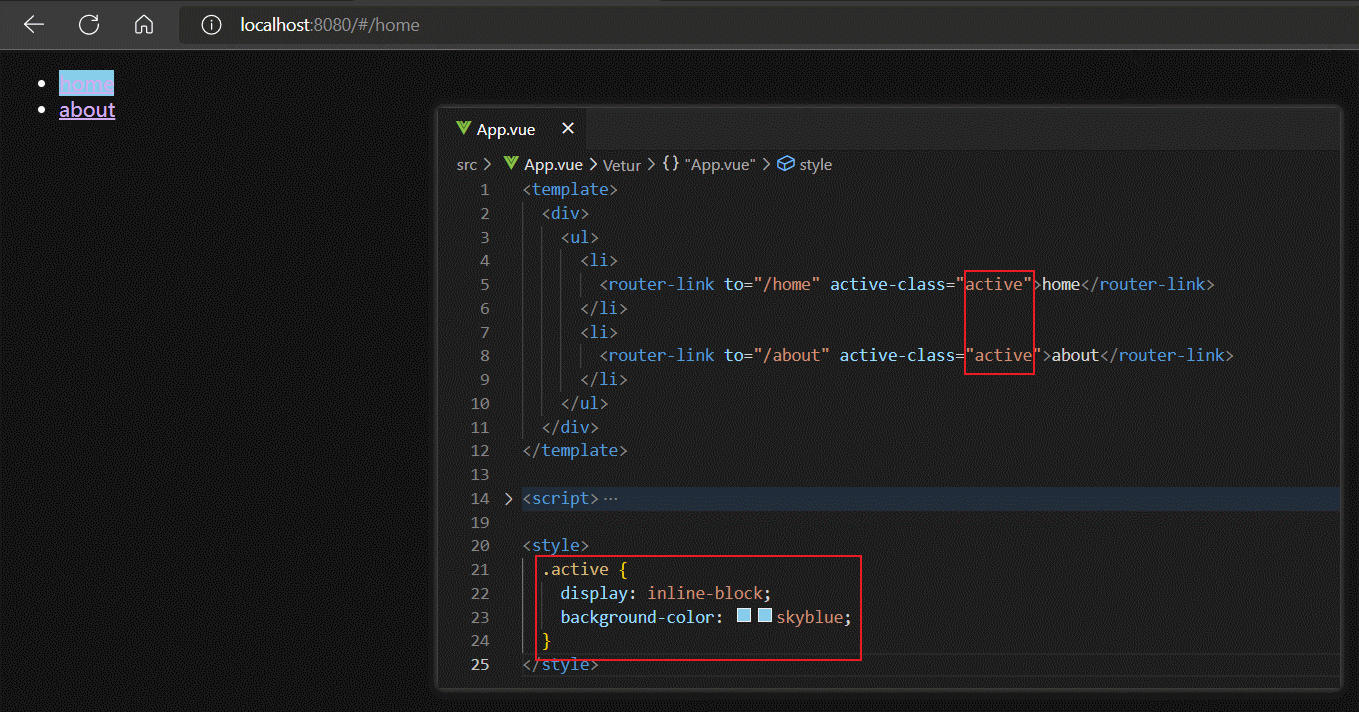
另外router-link组件还有一个tag属性,该属性默认值为'a',表示router-link组件被编译后会变为一个a标签,我们可以自定义tag属性为任何HTML标签,这样最终router-link组件被渲染出来的就是我们指定的HTML标签
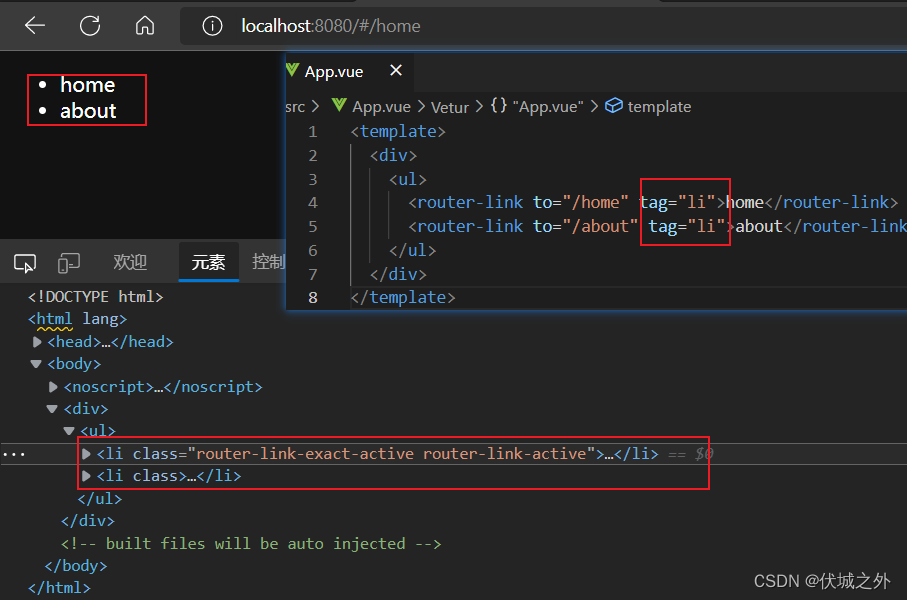
router-link组件标签还有一个replace属性,该属性值默认为false,表示router-link标签修改的浏览器地址栏URL后,URL会被以push模式加入浏览器历史记录栈中,而如果设置replace属性为true,则表示URL会被以replace模式加入历史记录栈。
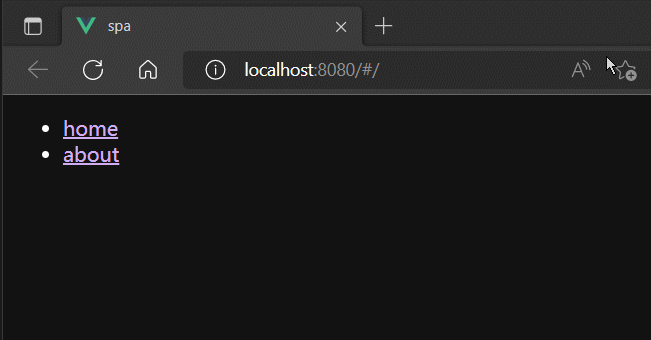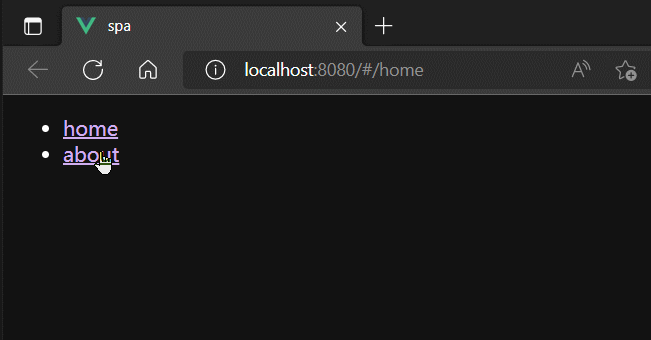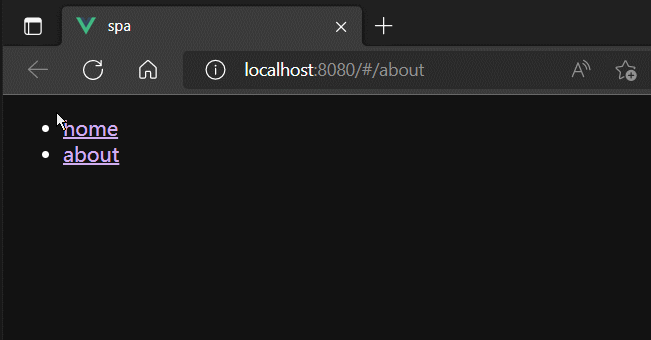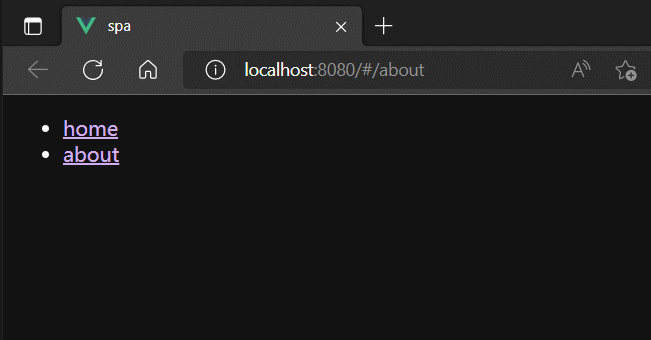
router-view
router-view组件用于占位。
当A组件中router-link修改了浏览器地址栏的URL的hash地址后,路由器就会监听到最新的hash地址,并到自身管理路由中,根据hash地址找到对应的路由组件,最终将路由组件渲染到A组件中router-view占位的地方。

认识路由组件
什么是路由组件
路由中与hash地址对应的组件,就是路由组件。
路由组件与非路由组件最大的区别在于,路由组件不会直接当成组件标签使用,而是完全交给路由器管理。路由器会将路由组件渲染到指定的router-view组件标签占位的地方。
为了在开发过程中,有效区分路由组件和非路由组件,官方推荐将
- 路由组件 放在 /src/pages 文件夹下
- 非路由组件 放在 /src/components 文件夹下
路由组件的创建和销毁时机
路由组件被切入时创建,被切出时销毁。

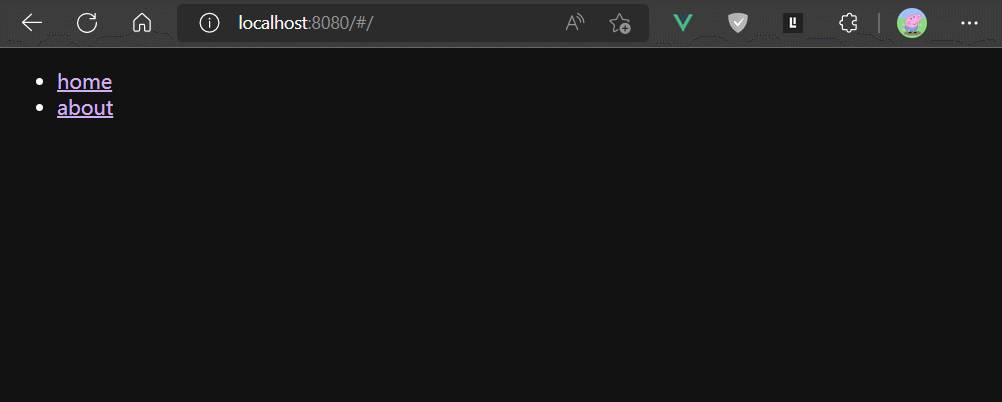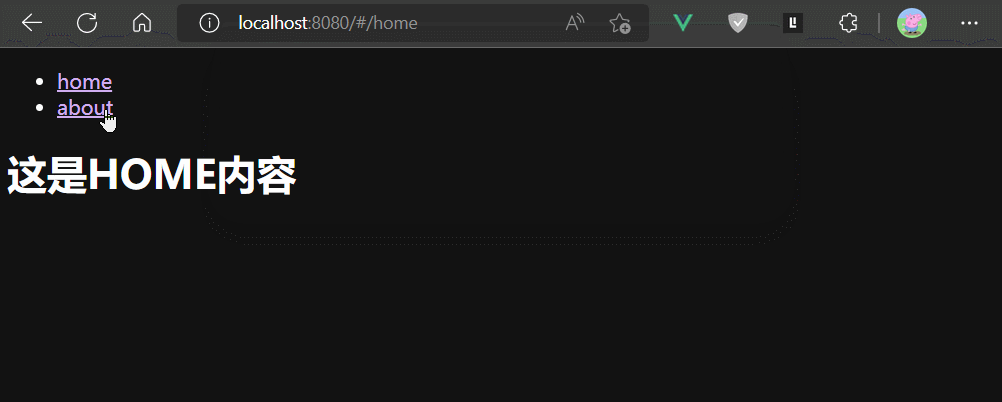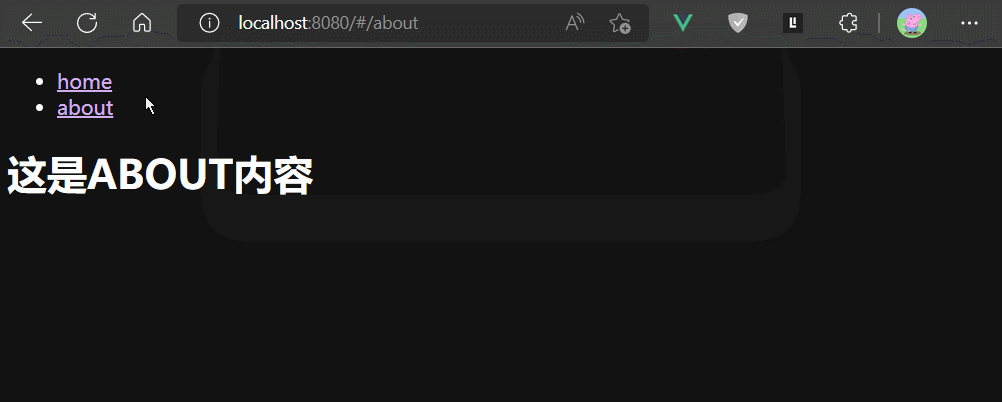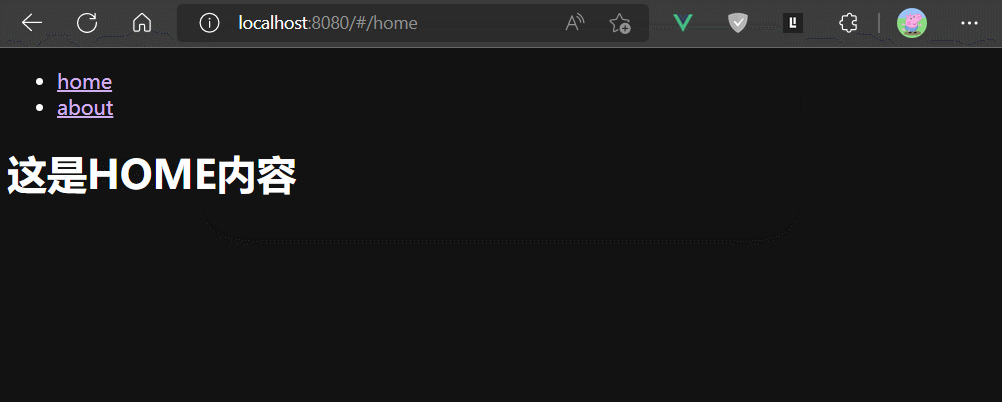
keep-alive组件
keep-alive组件是Vue的内置组件,keep-alive组件可以缓存内容组件的实例,避免组件实例被销毁。
如果我们使用keep-alive组件包裹router-view,则相当于keep-alive组件包裹了路由组件,这样可以缓存路由组件的实例,避免其被切出后销毁。
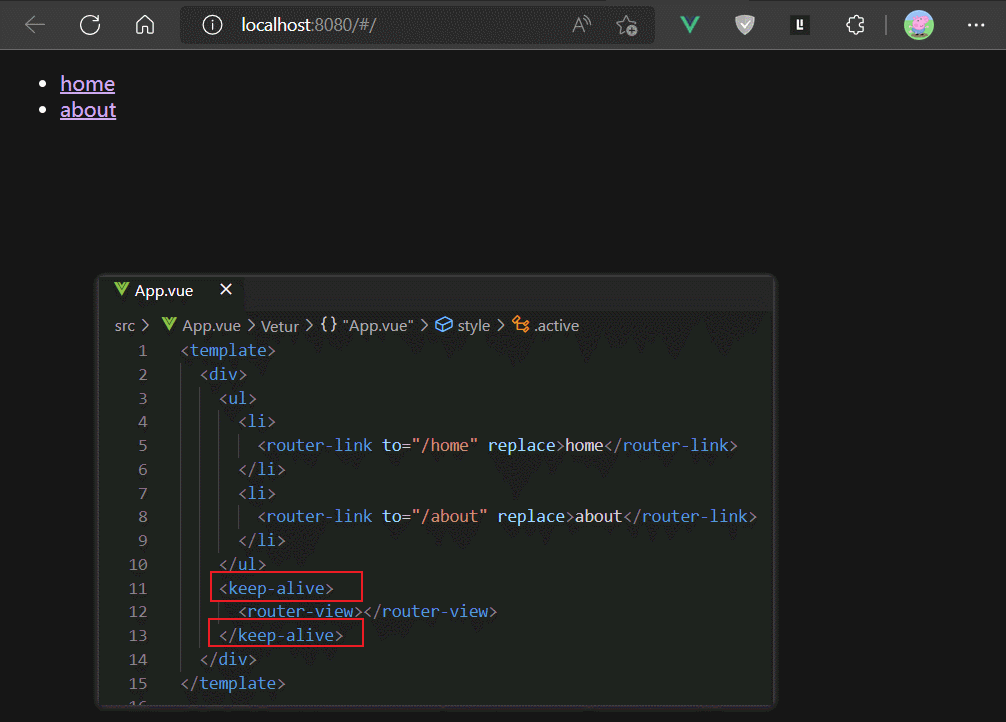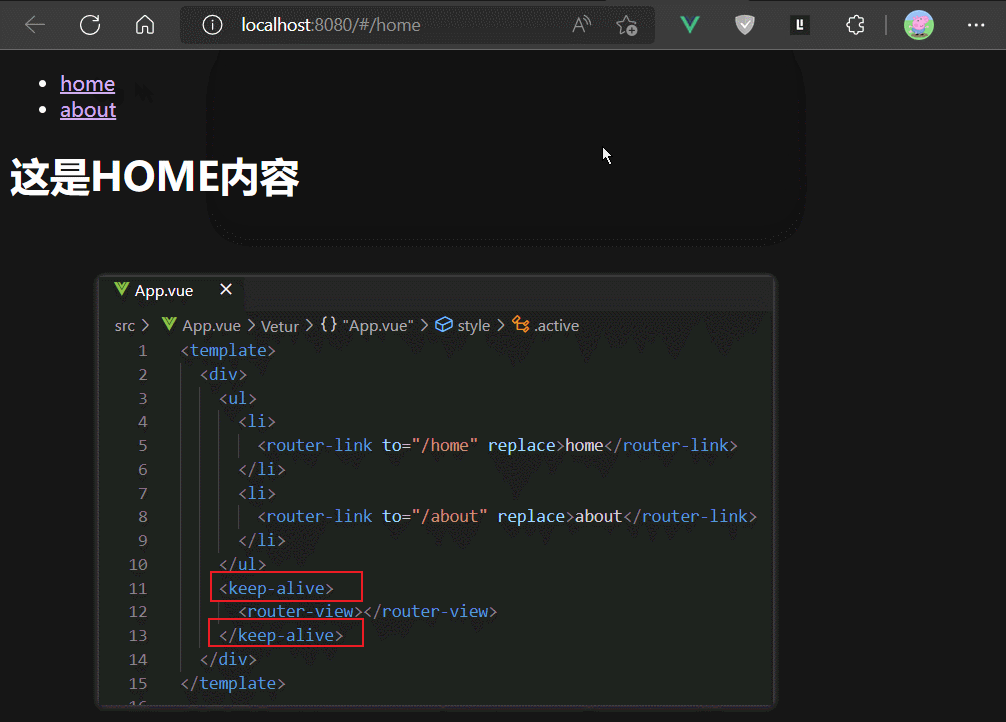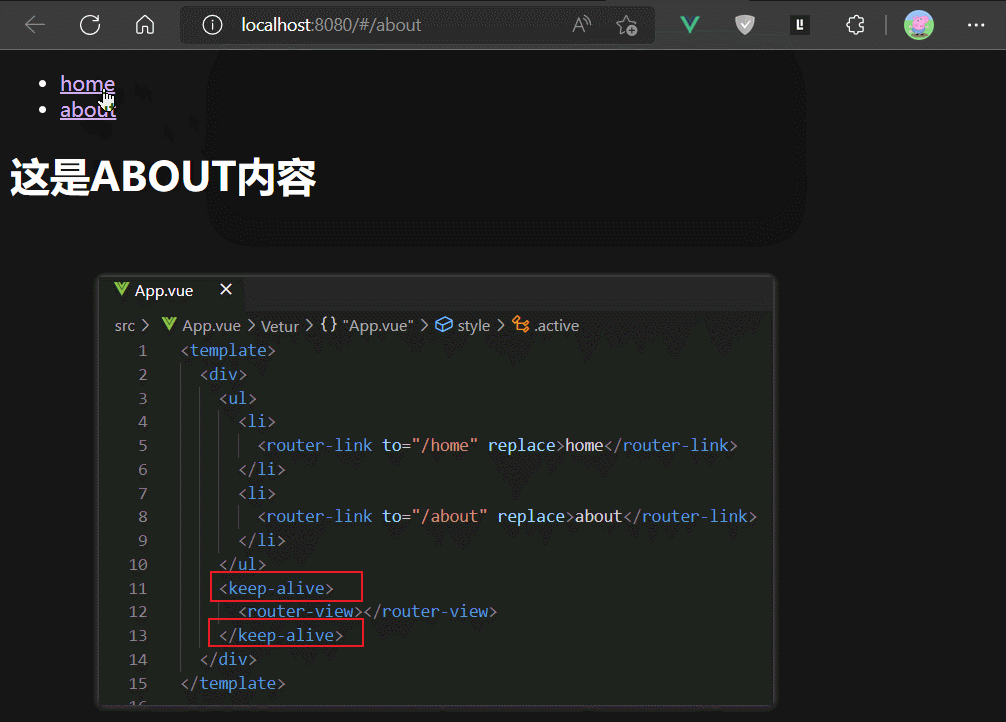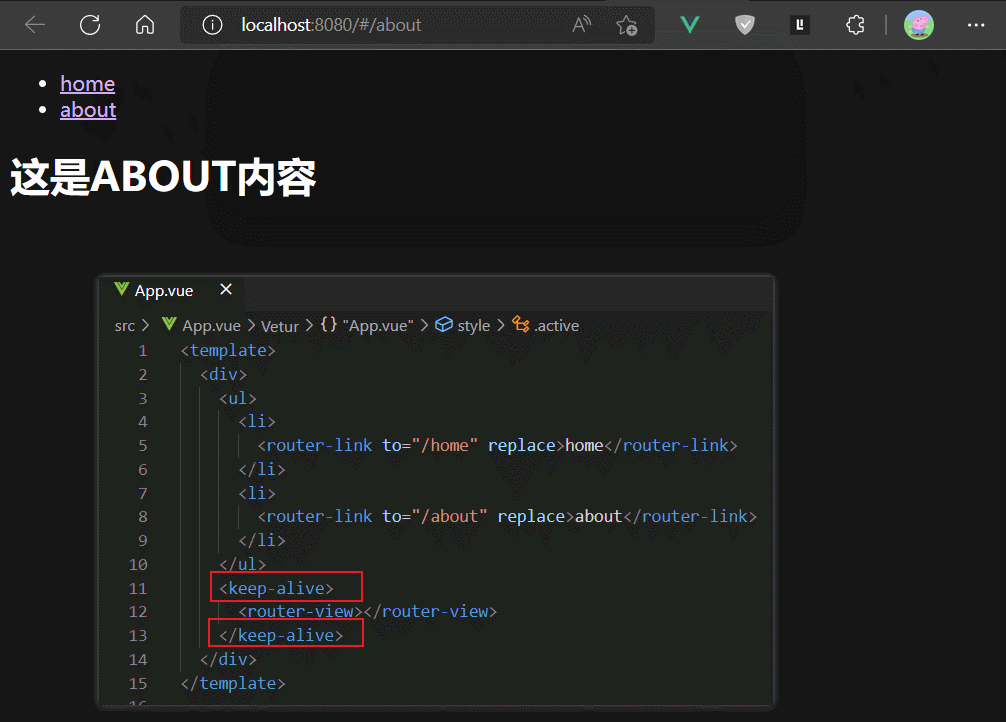
但是keep-alive默认会缓存所有渲染进router-view的组件,比上面例子中,MyAbout和MyHome组件都会被缓存。
如果我们只想缓存一个指定的组件,则可以使用keep-alive组件标签的include属性的字符串写法 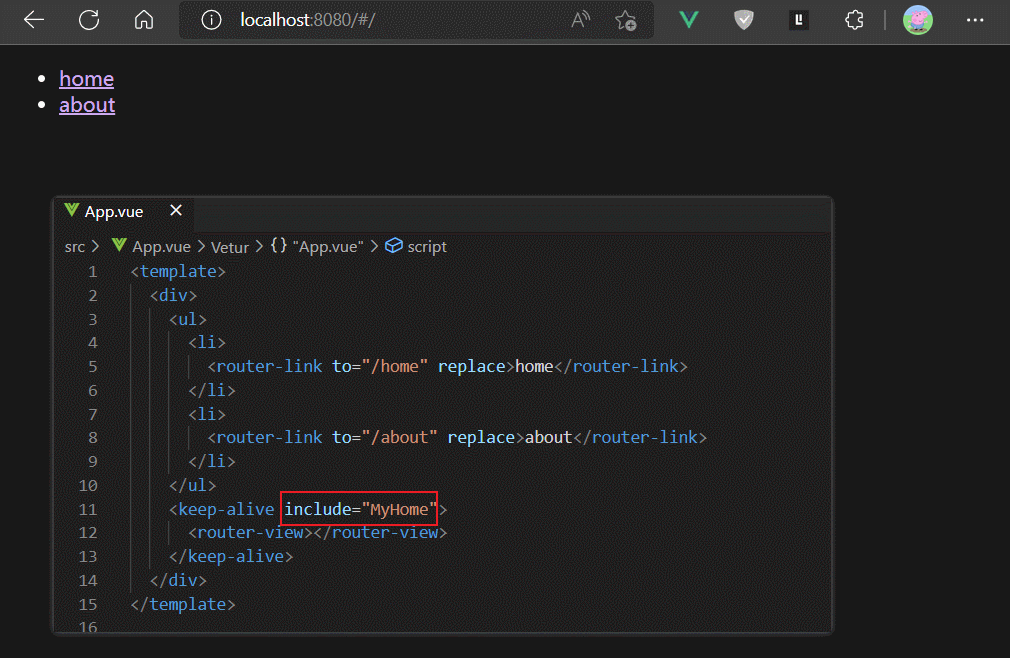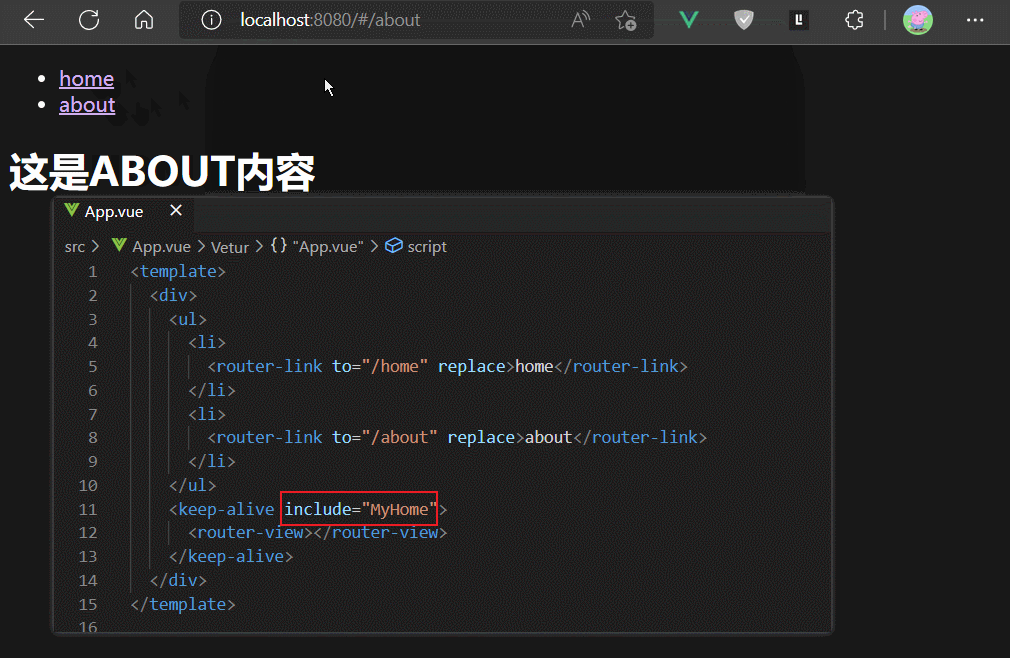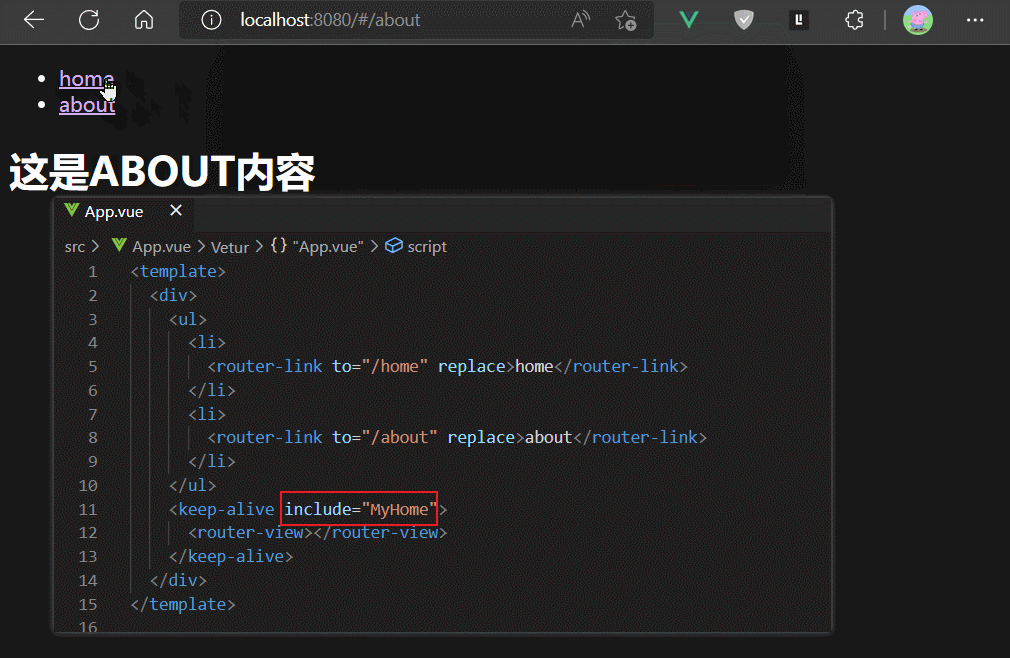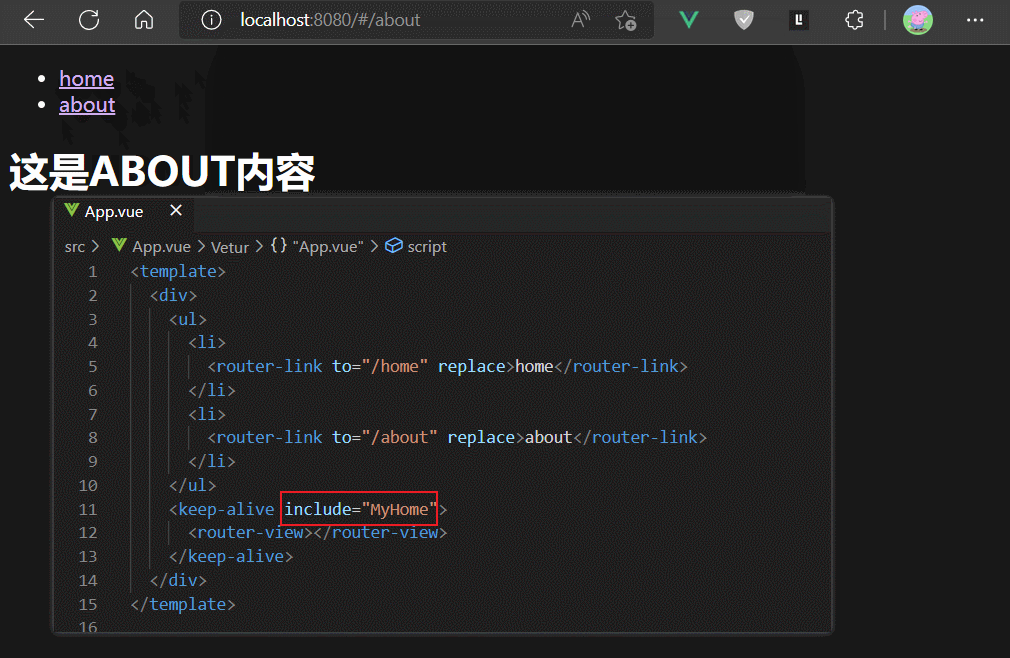
需要注意,include中写的是组件定义时的name属性值。

如果我们想缓存多个组件的实例,则可以使用include的数组写法 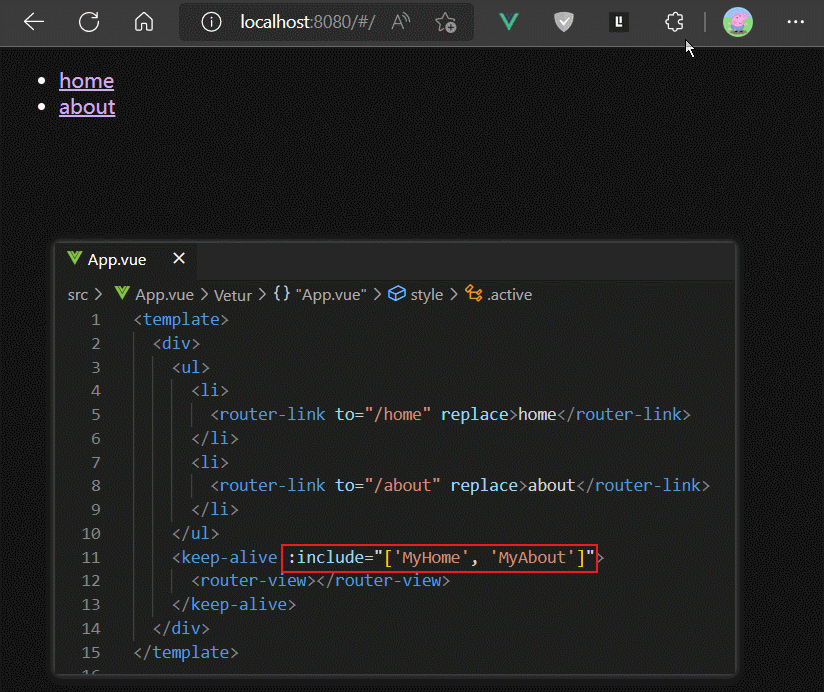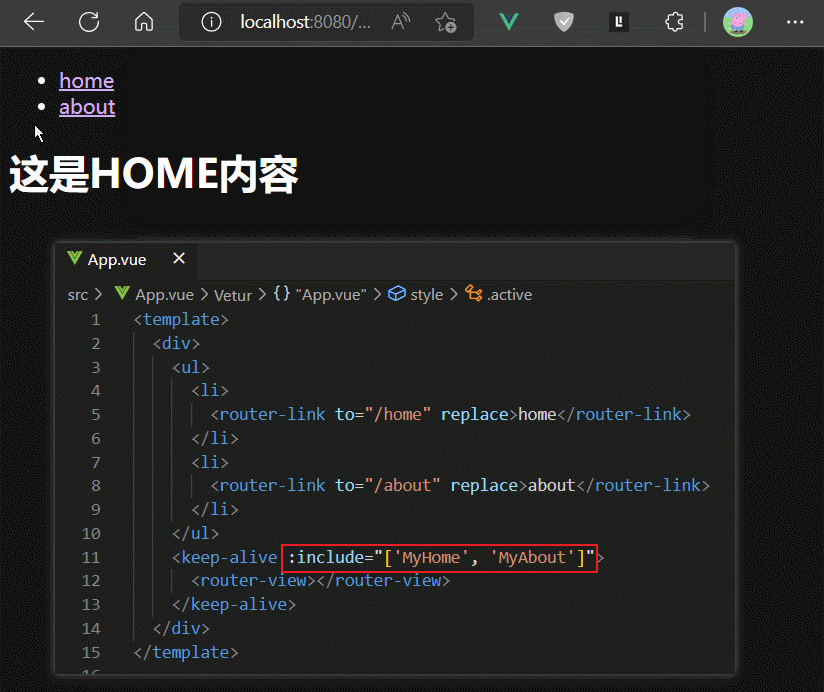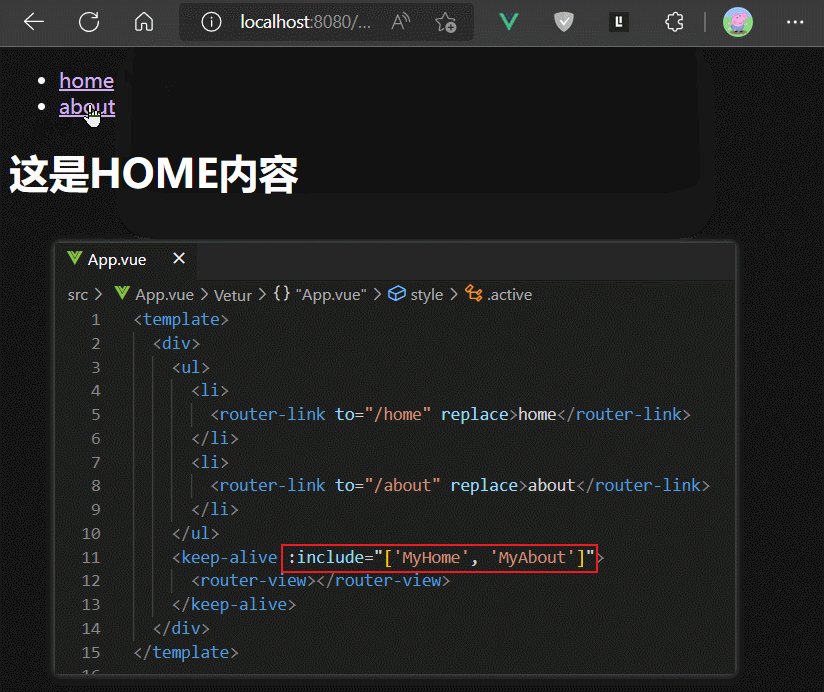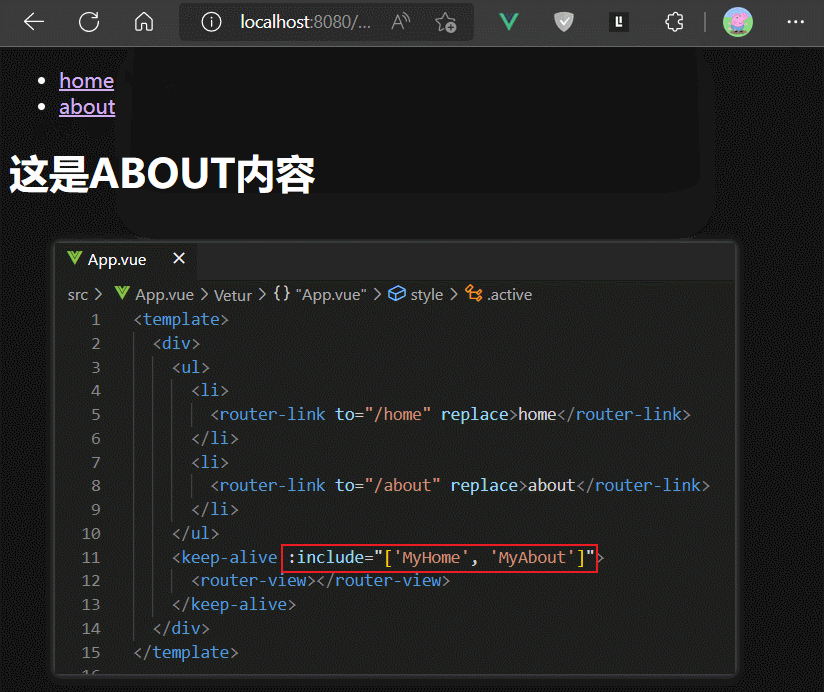
keep-alive组件标签还有一个exclude属性,用法和inclue一致,功能相反。
两个新的生命周期钩子actived,deactived
由于keep-alive可以缓存其内容组件的实例,导致组件被卸载后,组件的实例不会销毁,而是进入一种失活状态,当组件被重新装载时,组件的实例不会创建,而是直接去激活keep-alive缓存的组件实例。
而keep-alive缓存的组件实例的失活时机,和激活时机,也被加入了钩子。
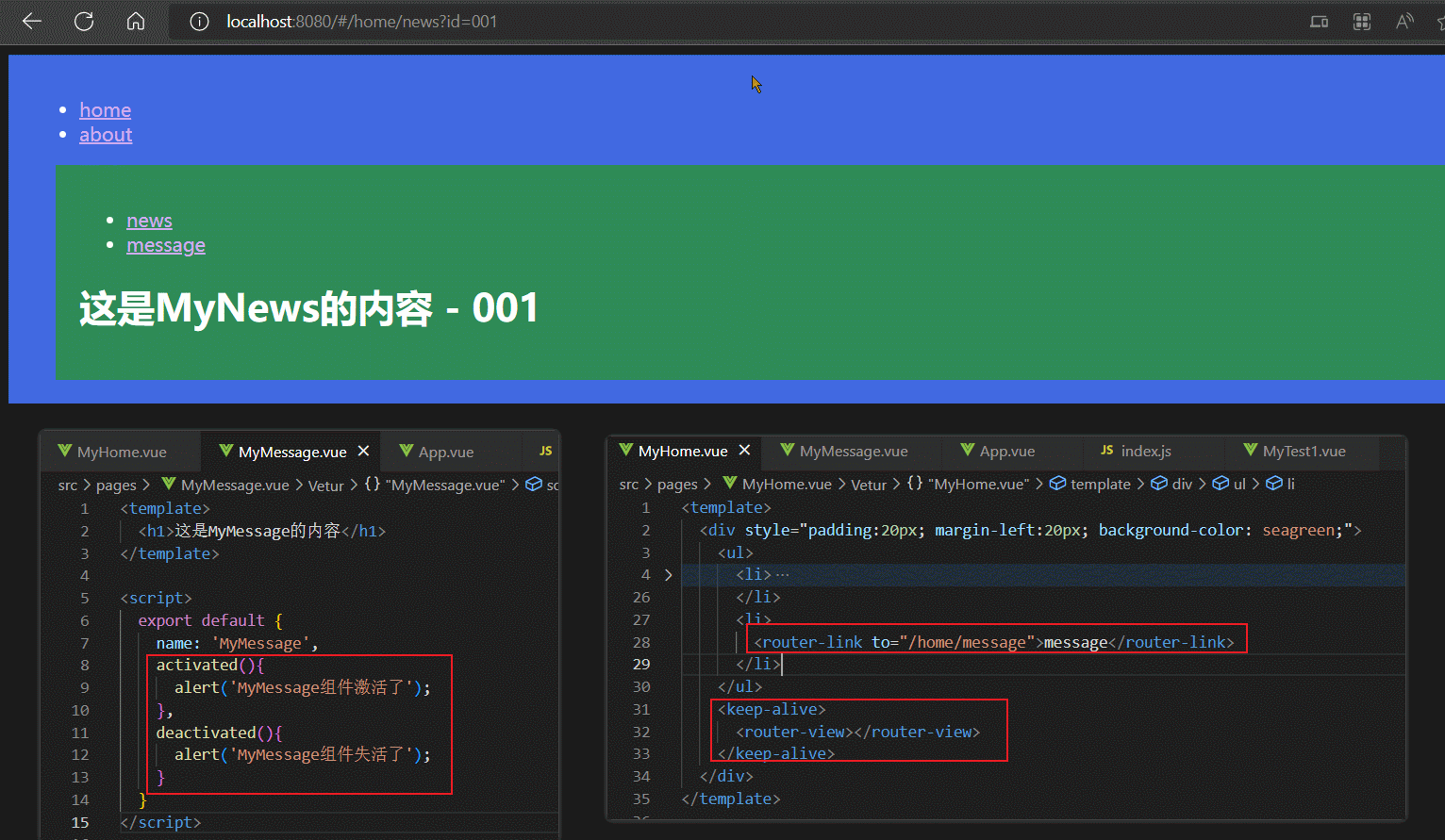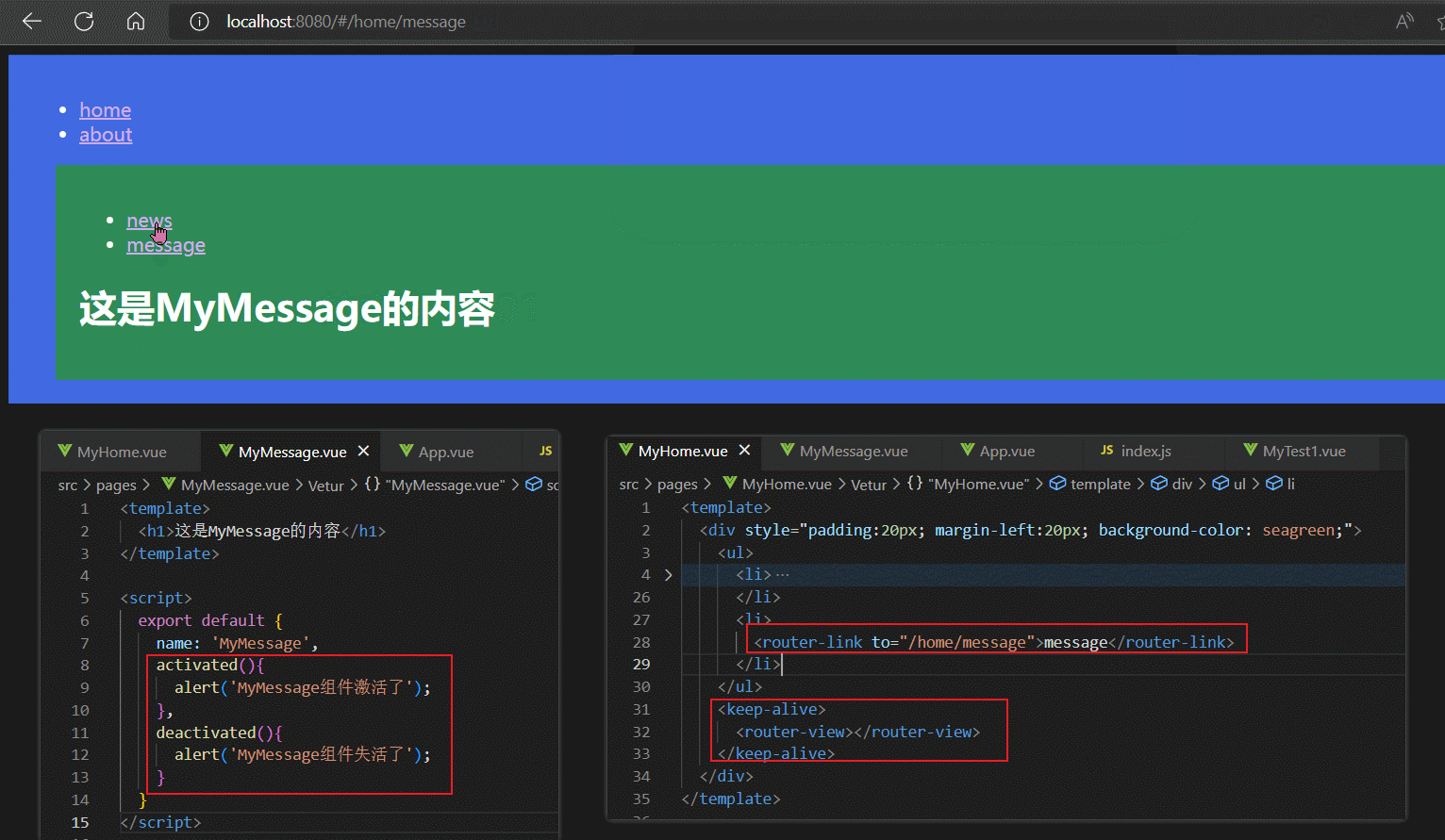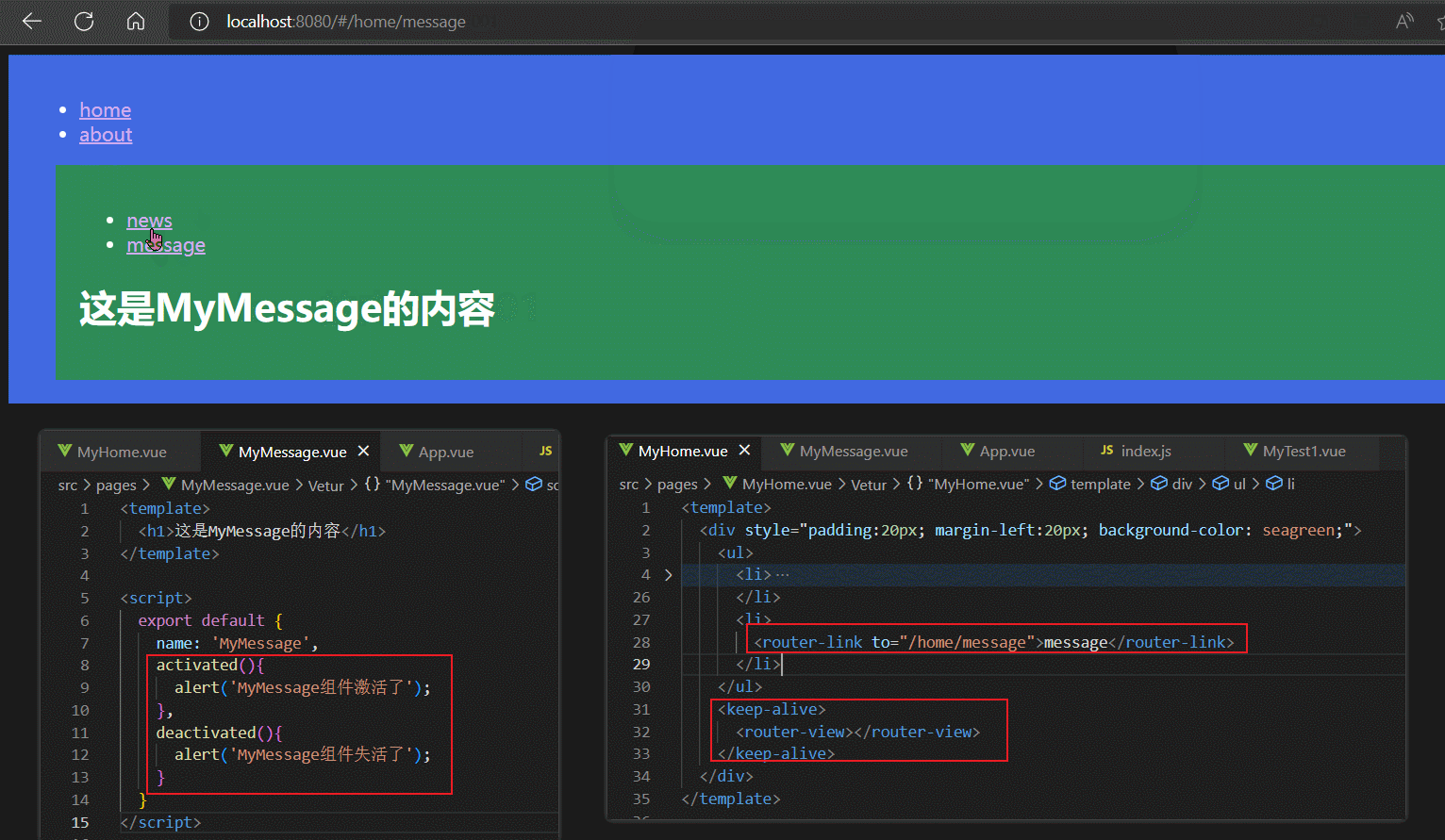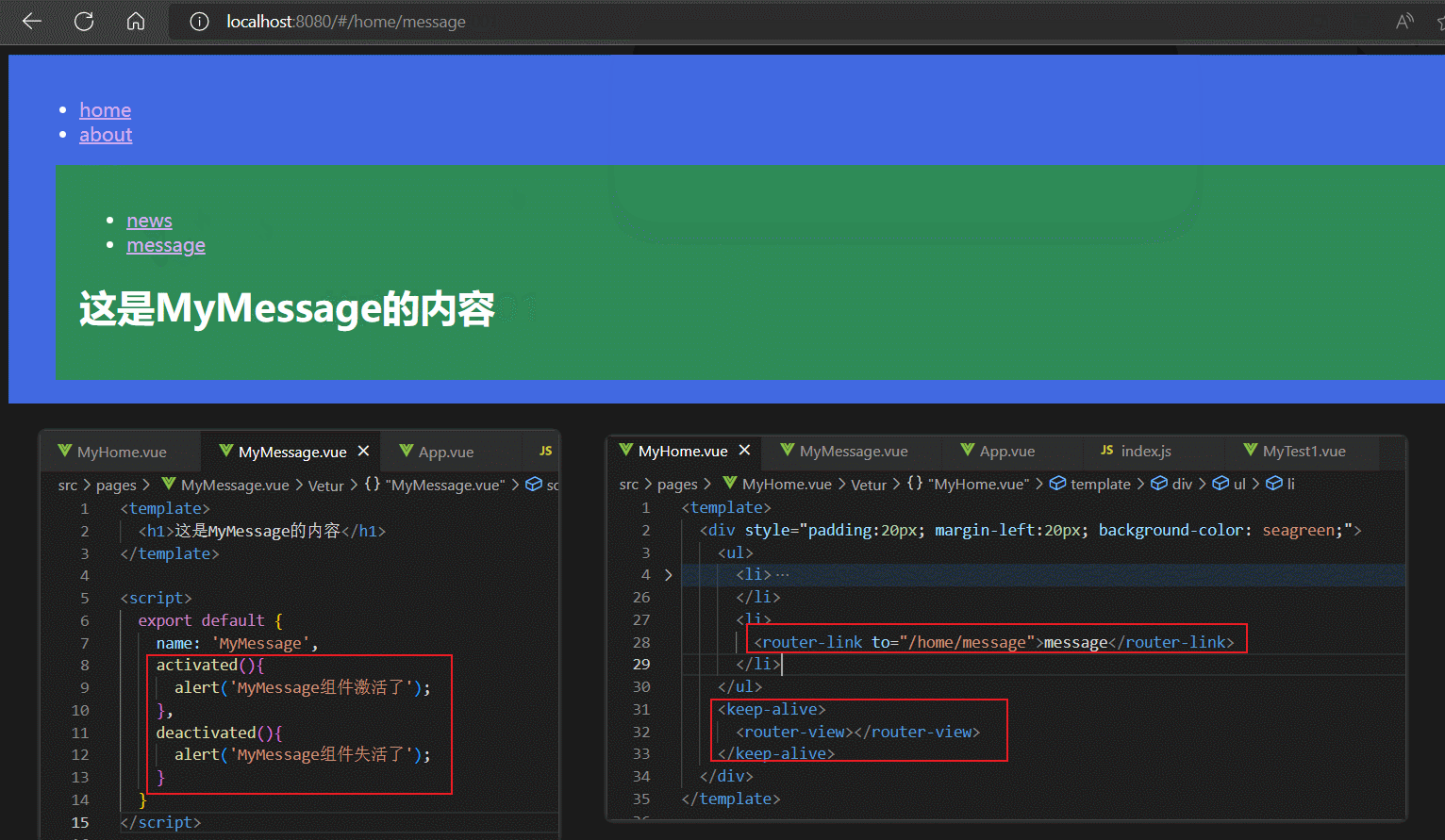
对于路由组件来说,当路由组件被切入时,其actived钩子调用,当路由组件被切出时,其deactived钩子调用。
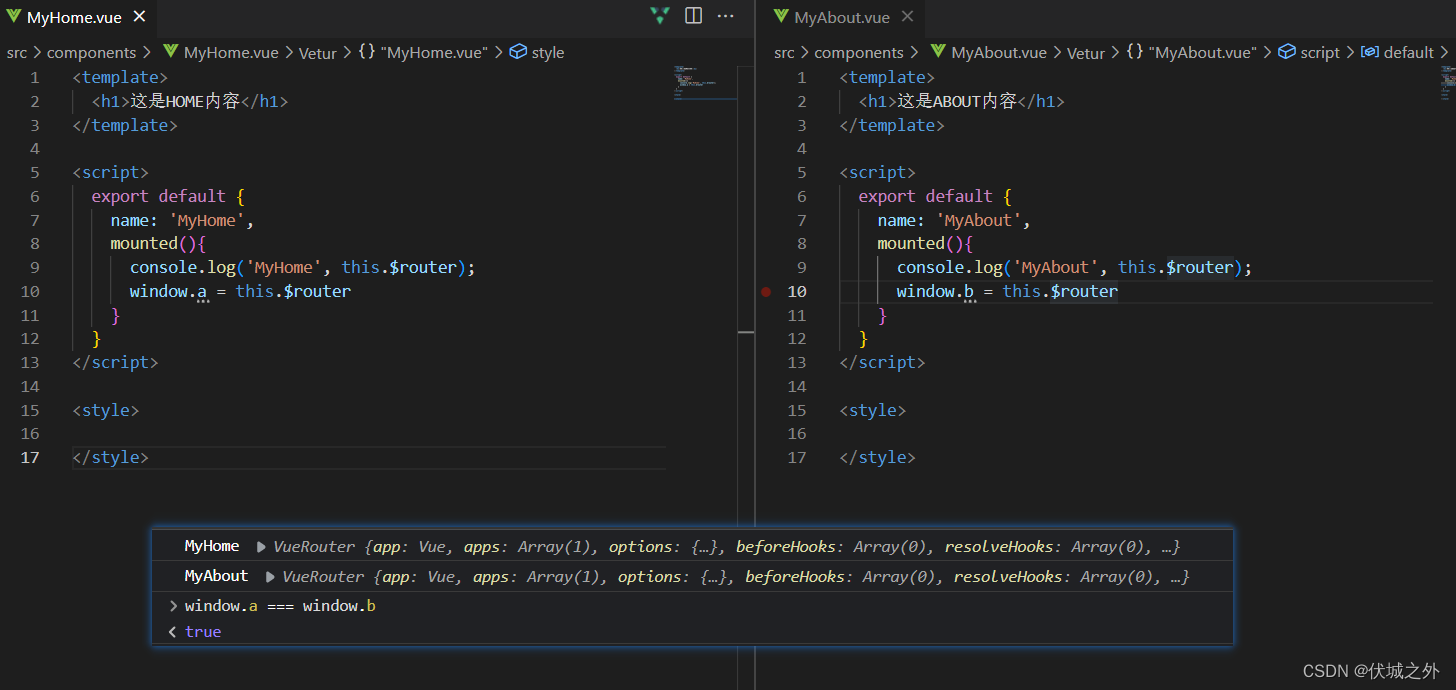
路由组件实例上的$route属性
当我们Vue.use(VueRouter)后,Vue.prototype上就会被挂载一个$route属性,则所有组件实例上就都有了一个$route属性,该属性是一个Object对象,用于收集组件的路由信息。
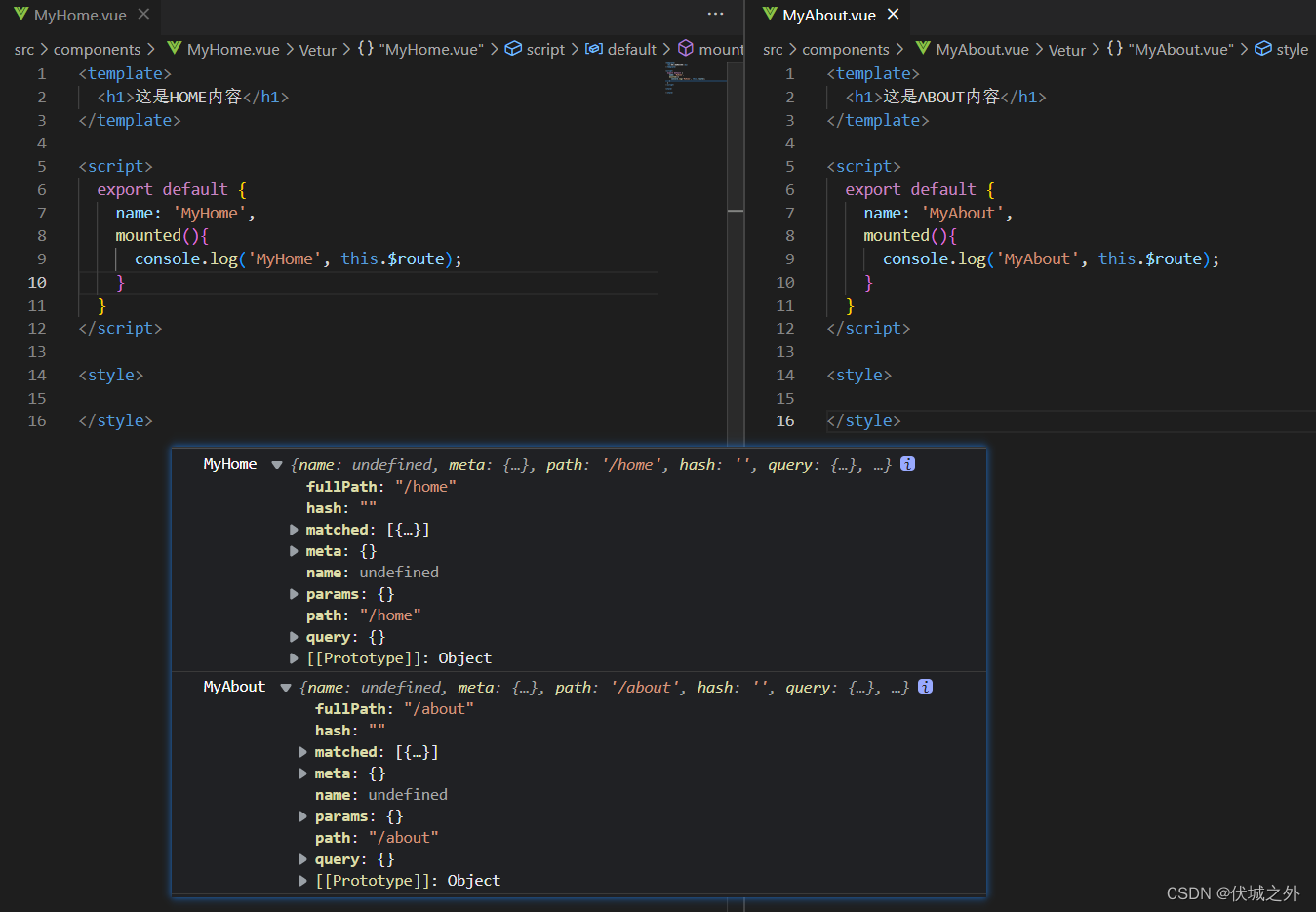
路由组件上的$router属性
当我们Vue.use(VueRouter)后,Vue.prototype上就会被挂载一个$router属性,则所有组件实例上就都有了一个$router属性,并且所有组件实例的$router都指向了同一个VueRouter实例对象,那就是我们传递给vm.$options.router的路由器对象。路由器对象上主要包含了各种导航方法,用于编程式导航。
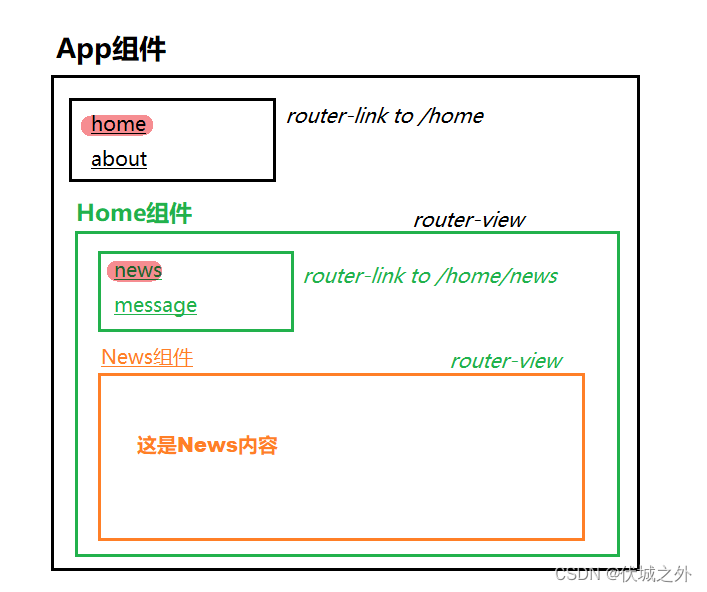
嵌套路由
什么是嵌套路由
嵌套路由,即子路由
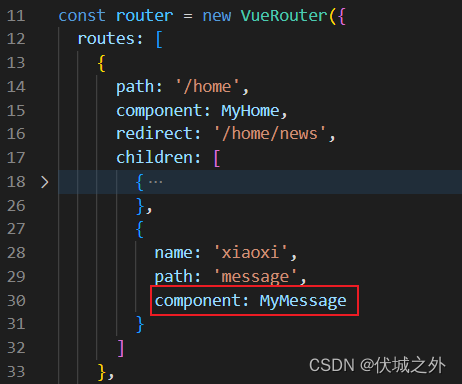
- 子路由的hash地址必然以父路由的hash地址为前缀,如父路由hash地址是/home,子路由hash地址为/home/message
- 子路由组件必然要在父路由组件中展示,表现为组件嵌套。
比如下面例子中,
当在App组件中router-link到/home时,App组件中router-view中展示就是Home组件。
当在Home组件中router-link到/home/news时,Home组件中router-view展示的就是News组件。
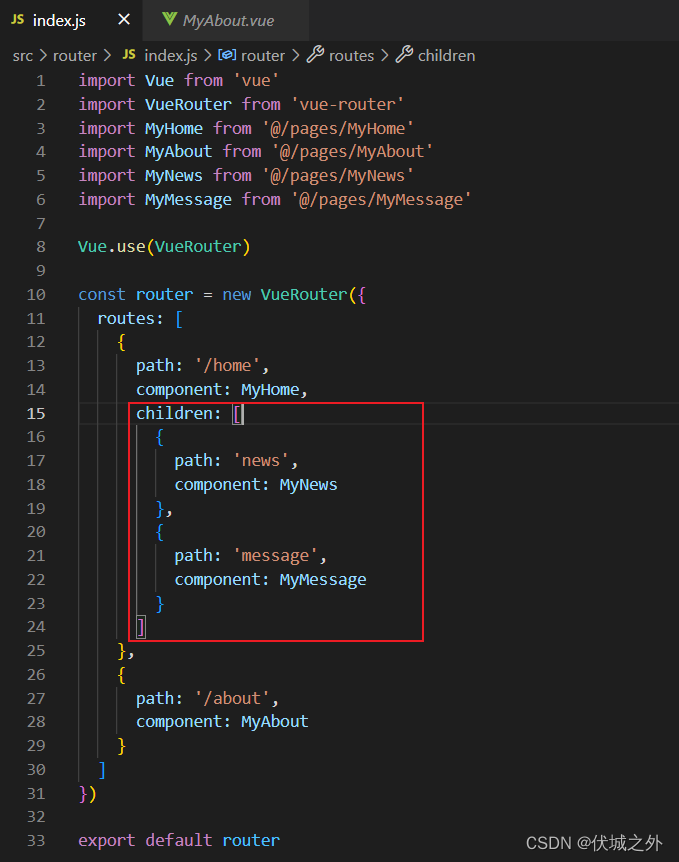
嵌套路由的实现
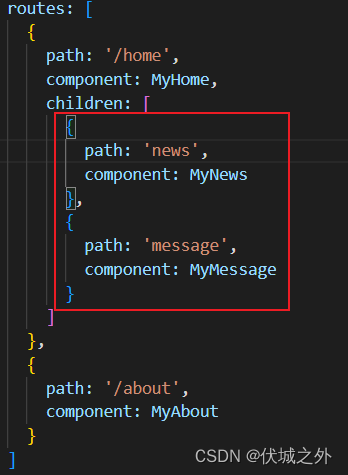
1、子路由配置属性children
VueRouter构造函数入参配置对象的属性:routes数组的元素,就是一级路由。
路由对象都有一个children属性,该属性也是一个数组,用于配置子级路由,例如一级路由对象的children属性中配置的就是二级路由;二级路由对象的children属性中配置的就是三级路由;
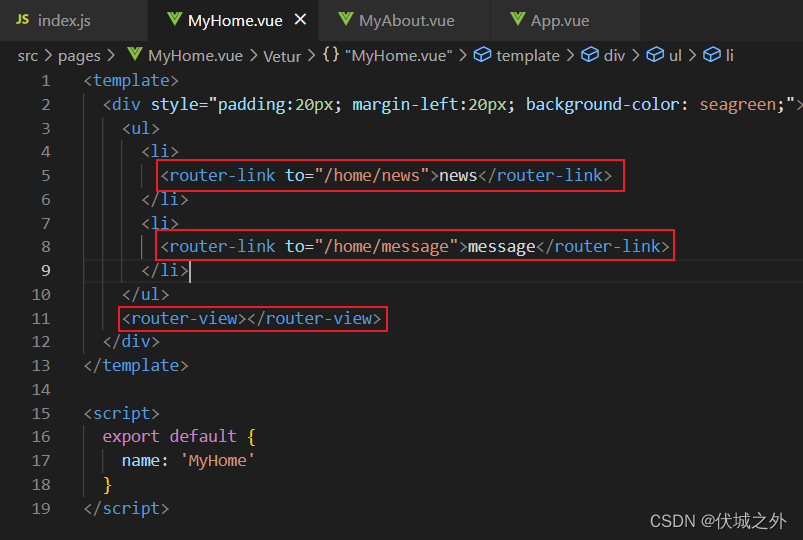
需要注意的是children中路由对象的path是不需要加 / 前缀的,如上,path: 'news',中news并不需要加/前缀,VueRouter内部会为我们自动添加。
2、子路由组件的渲染
由于子路由组件,必须要定义在父路由的组件中,比如/home/news就是/home的子路由,所以MyNews组件必然要定义到MyHome组件中,而路由组件都是交给路由器管理的,所以我们只需要在MyHome组件中router-link to /home/news,让路由器找/home/news对应的子组件,然后渲染到router-view中即可

路由重定向 redirect属性
在上面例子中,我们发现了一个问题:
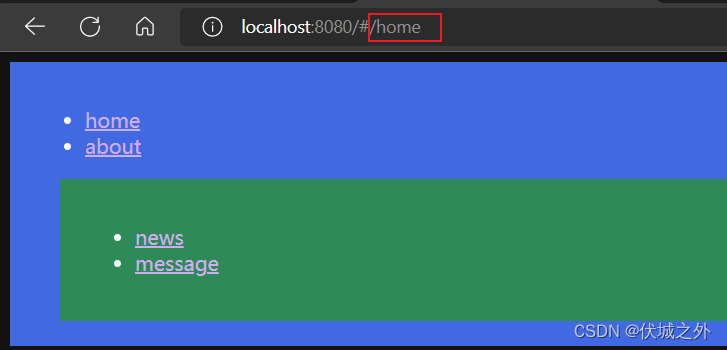
当hash地址为/home时,其实等价于/home/,即此时子路由为 ''
而/home的子路由中并没有配置 path: ‘’ 的路由,所以没有对应的子组件被渲染,导致MyHome组件的展示区空白。
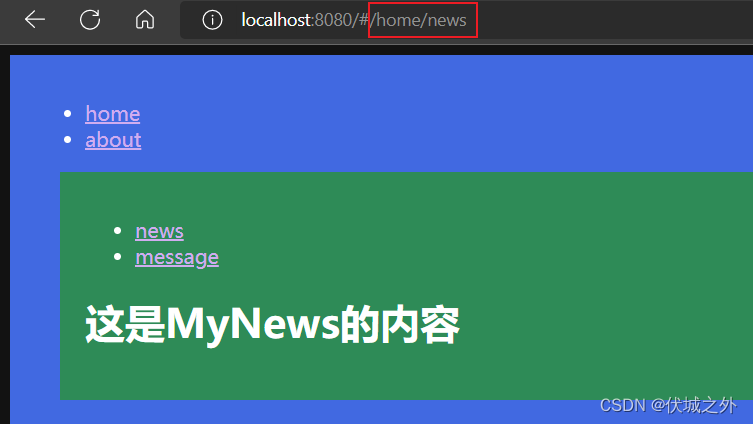
此时,我们可以设置,当路由地址为 /home 时,让其重定向到 /home/news,保证MyHome组件的展示区始终有内容展示。
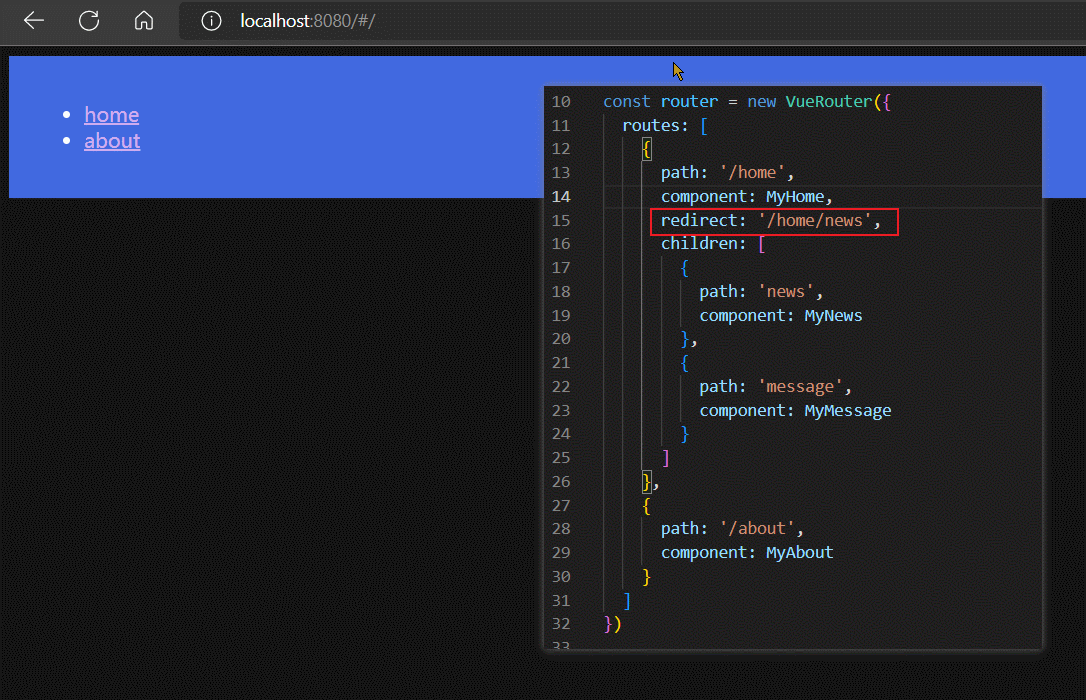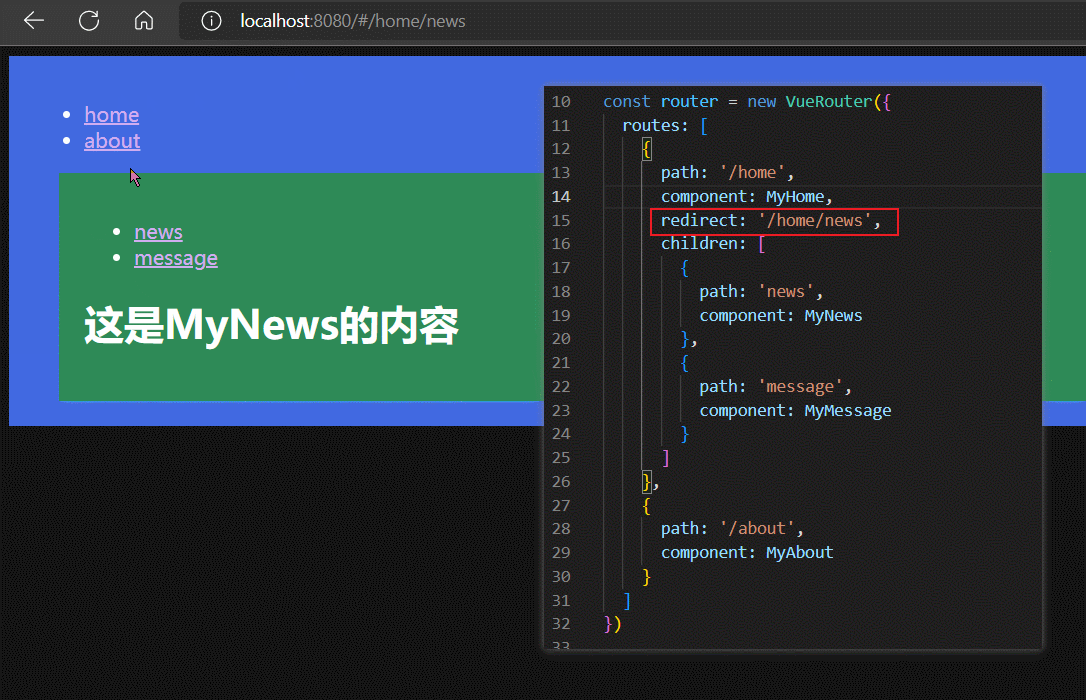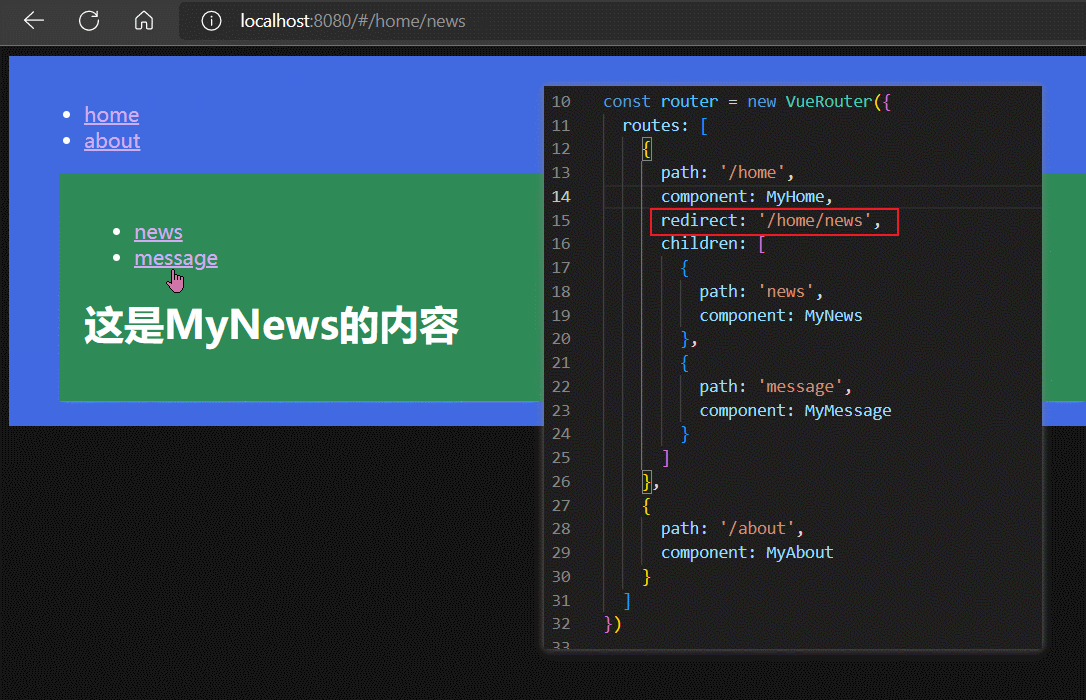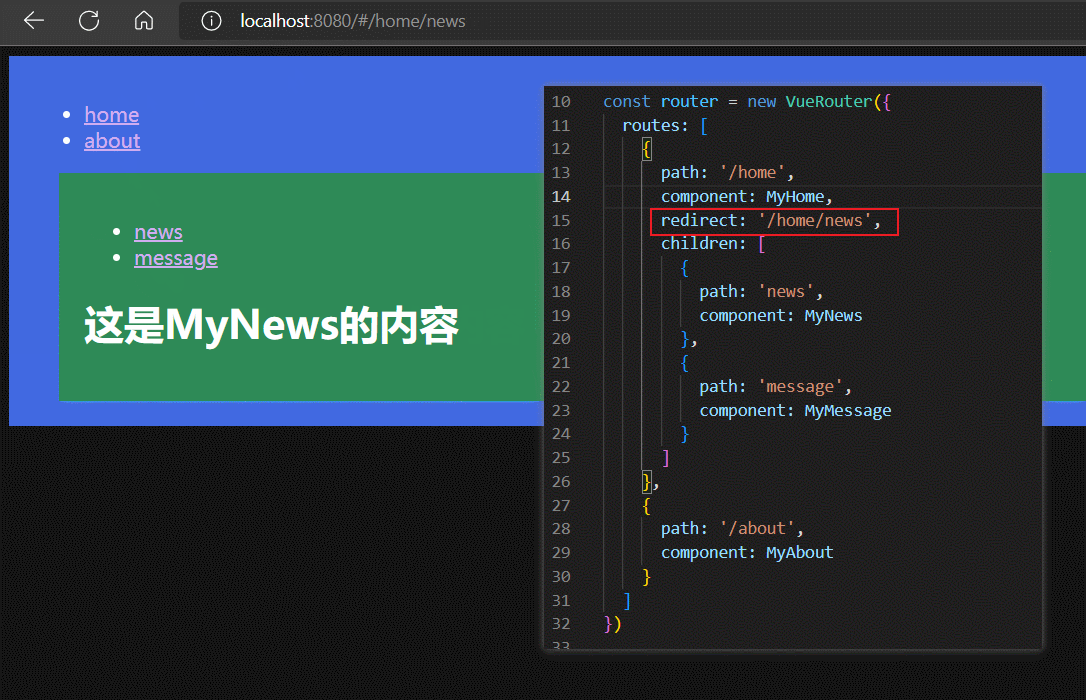
默认子路由
通过路由重定向,我们可以让 /home 和 /home/news 的展示结果一致。
而 /home 又等价于 /home/,所以路由重定向的作用是,让 /home/ 和 /home/news 路由对应同一个路由组件。
相当于:

所以此时,/home/news路由就没有存在必要了,可以简化为

我们将子路由中 path: '' 的路由,称为默认子路由。
动态路由
什么是动态路由
在Vue Router中,每一个路由hash地址都要对应一个组件,但是存在一种情况,就是hash地址中存在动态的路径参数
- /about/001
- /about/002
- /about/003
那么此时我们是否需要定义三个组件去分别展示001,002,003呢?如下
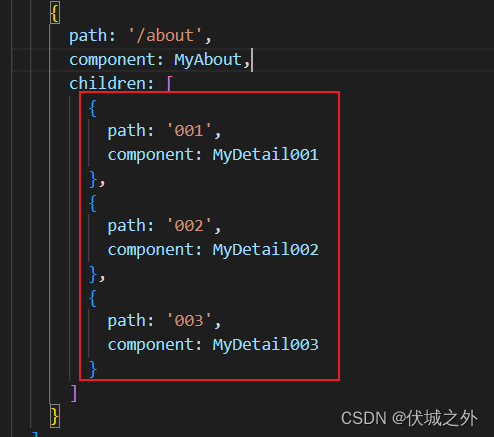
虽然可行,但是这种路由定义是有弊端的,如果有001~100的about详情,我们是否要定义100个路由组件呢?
所以Vue Router支持动态路由hash地址。
所谓动态路由hash地址,即将路由hash地址中动态的路径参数用 :参数名 代替,此时动态路由hash地址就可以匹配到 所有复合要求的路由hash了。


$route.params
此时我们已经将多个路由hash,对应到了一个路由组件中。
如:/about/001、/about/002、/about/003 都对应路由组件MyDetail。
那么路由组件应该如何获取 动态路由hash地址中动态路径参数呢?
此时我们需要借助 组件实例上的$route属性,该属性是一个对象,包含当前路由组件的所有路由相关信息
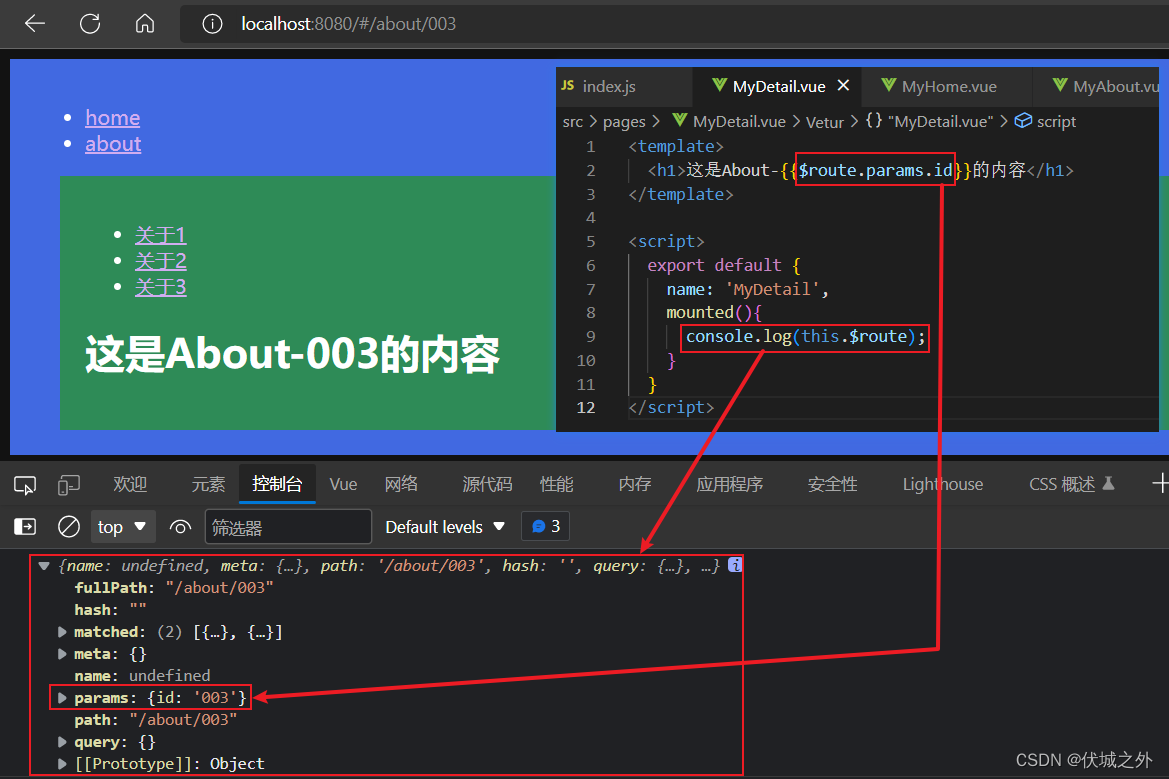
我们可以通过 动态路径参数 会挂载为当前路由组件实例身上$route.params对象的属性。
我们需要注意$route.params对象的属性的名字取决于 定义的动态路径参数名字。

将$route.params转为组件props
当前我们需要通过 $route.params.xxx 获取路径参数,形式比较繁琐。所以Vue Router支持将$route.params.xxx 转为 组件的props属性。而组件的props中属性都将挂载为组件实例的直接属性。
为啥可以将$route.params.xxx 当成 props属性 使用呢?
我们其实可以将 父路由组件中 router-link to 导航到 子路由组件的过程,看成是父路由组件给子路由组件传参的过程

而to的hash地址中的路径参数,其实就是父路由组件,传递给子路由组件的参数值。
所以这种父子组件传参,子组件通过props配置属性接收,在理论上是合情合理的。
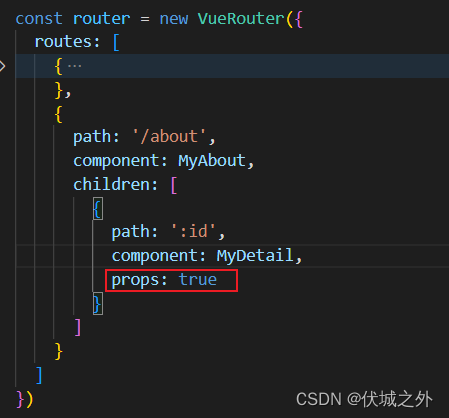
实现props获取动态路由路径参数,我们需要走两步
1、在动态路由中开启props支持,即设置props:true
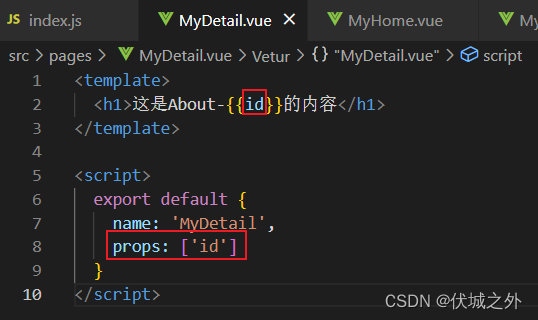
2、在动态路由对应的路由组件中,使用props配置属性接收路径参数
路由配置属性props的三种用法
前面已经介绍路由配置属性props的第一种用法,即设置路由对象的props属性为true,这样对应路由组件上的$route.params.xxx就会被交给路由组件的props,简化了我们在路由组件中获取动态路由路径参数的形式。
路由配置属性props还有另外两种用法:
- 对象式
- 函数式
我们可以利用路由配置属性props对象 传递一些固定数据给路由组件
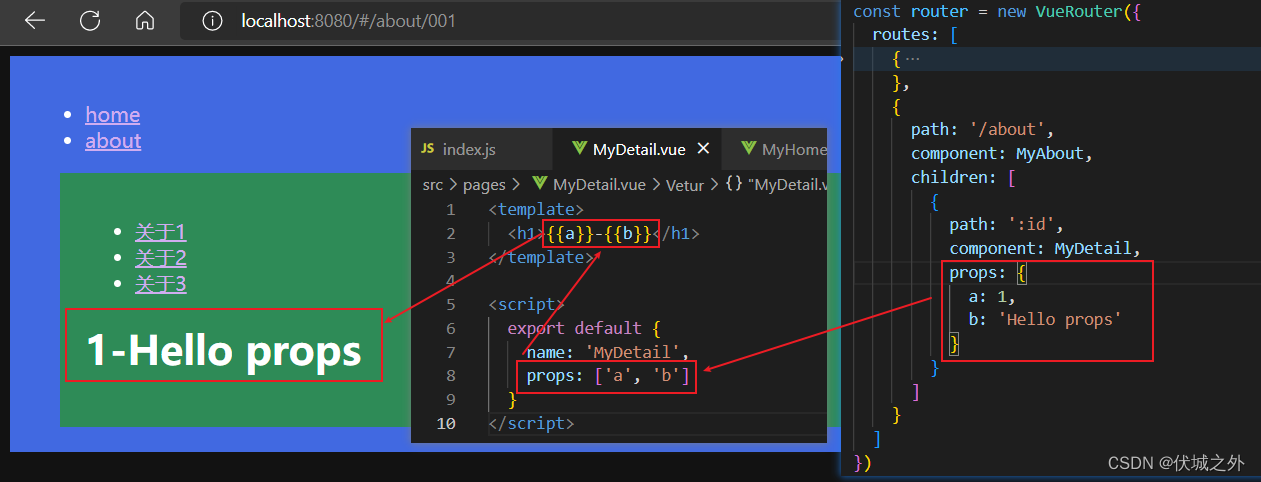
路由配置属性props还可以写成函数,此时props函数可以接收一个默认入参 $route,该入参就是当前路由组件实例的$route属性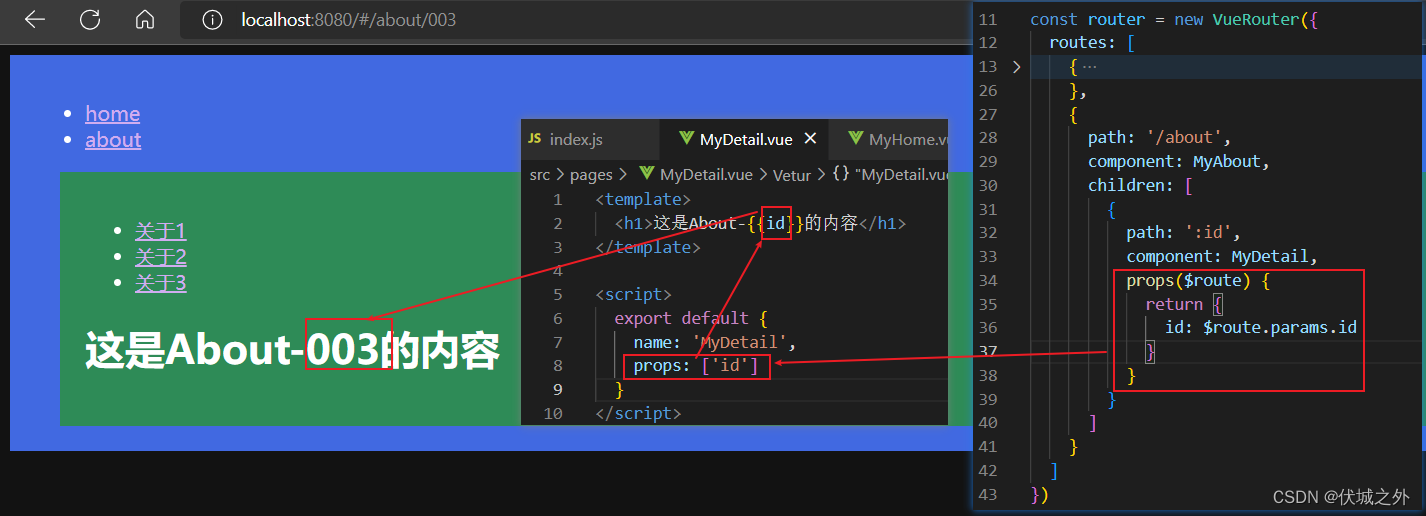
查询参数路由
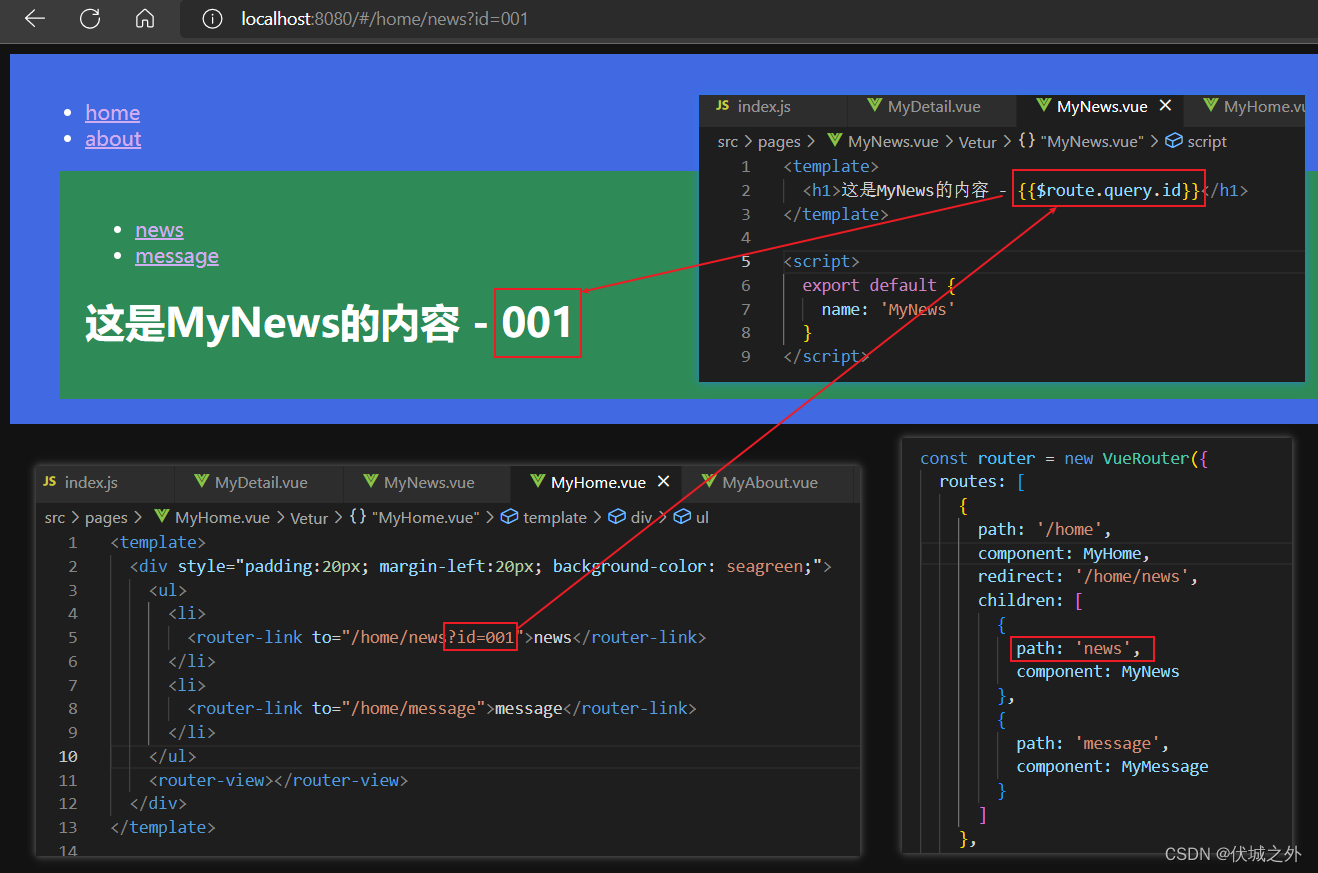
什么是查询参数路由
即 路由hash地址中带有查询参数,比如 /home/news?id=001
hash地址中的查询参数不会对hash地址造成影响,即 /home/news 和 /home/news?id=001 都会匹配到 /home下的子路由news。
$route.query
其实带有查询参数的路由,也可以看作是一种 父路由组件 向 子路由组件 传参的方式。
在子路由组件中,我们可以通过 组件实例上的$route.query属性获取到查询参数
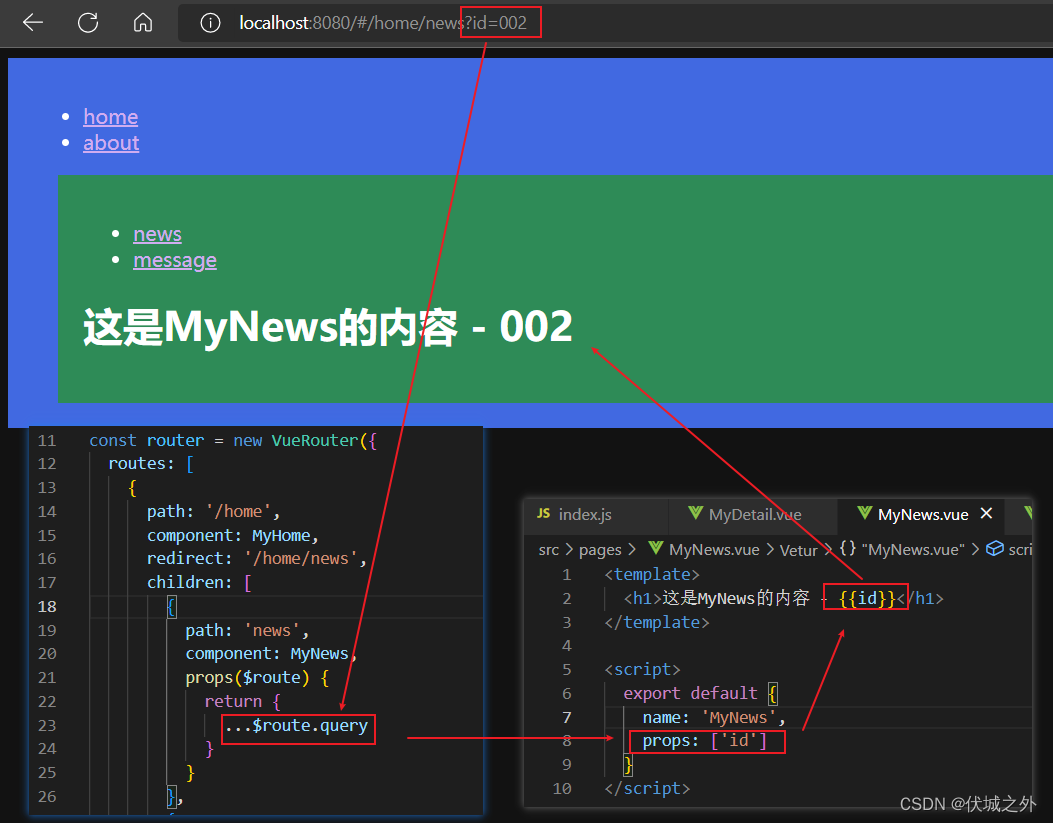
通过路由配置属性props简化$route.query的获取
目前在路由中查询参数的获取,要通过 $route.query.xxx ,形式非常繁琐,此时我们可以通过路由配置属性props来简化其获取形式
我们知道 路由配置属性props 支持三种模式:布尔式、对象式、函数式
其中props函数可以接收到对于路由组件实例的$route属性作为入参,所以
命名路由
什么是命名路由
简单说,就是给路由配置对象增加一个name属性,即给路由定义一个别名。
如下面例子,给/home/news定义了一个别名xinwen

为什么需要命名路由
随着嵌套的路由越来越多,router-link的to属性指向的hash地址也就越来越长,这将使得router-link的to属性的书写非常繁琐。
所以 Vue Router 支持给路由定义别名,让router-link的to属性指向路由的别名 来替代 冗长的hash地址。
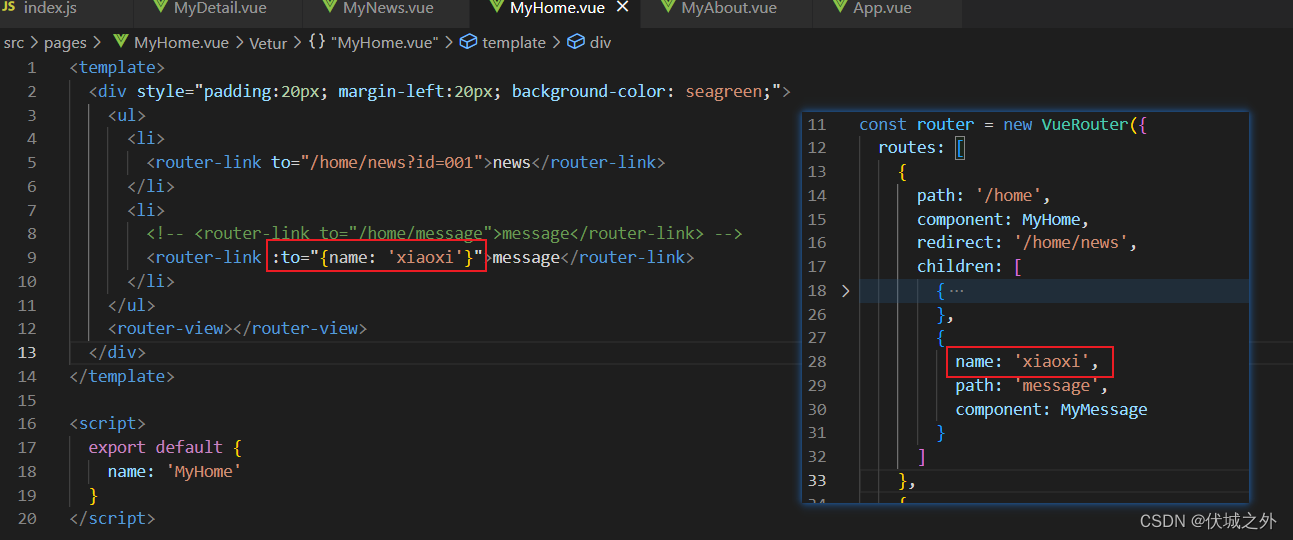
命名路由需要结合router-link组件标签的to属性的对象式写法使用。
router-link to属性的对象式写法
router-link to属性的值是一个hash地址,而目前hash地址包括三个部分:
- 路由静态路径,如/home
- 动态路径参数,如/home/about/001
- 查询参数,/home/news?id=001
目前,我们都是将这三个部分通过字符串拼接的方式定义在一起的,可读性很差。
所以to属性支持对象式写法,将这三部分作为to对象的属性
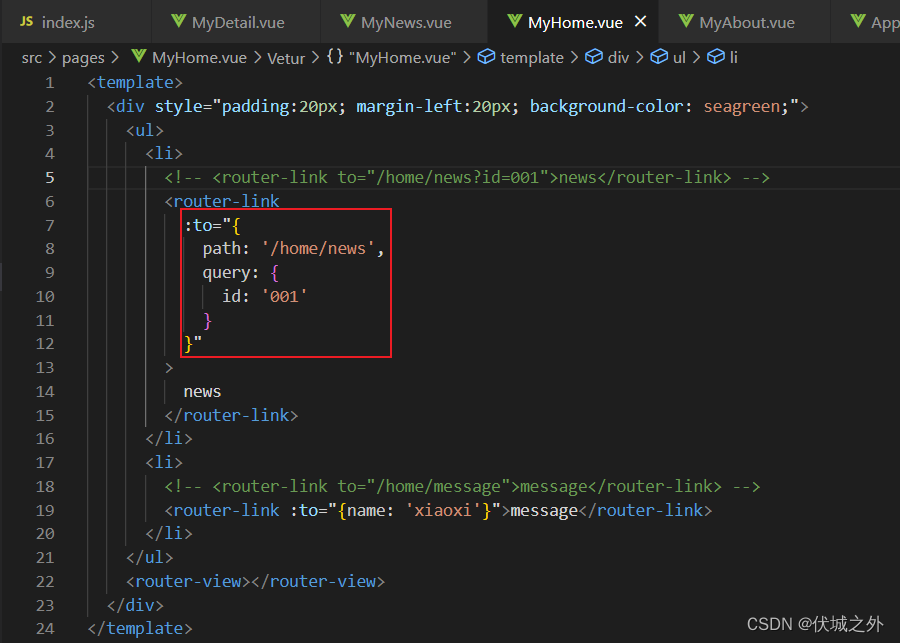
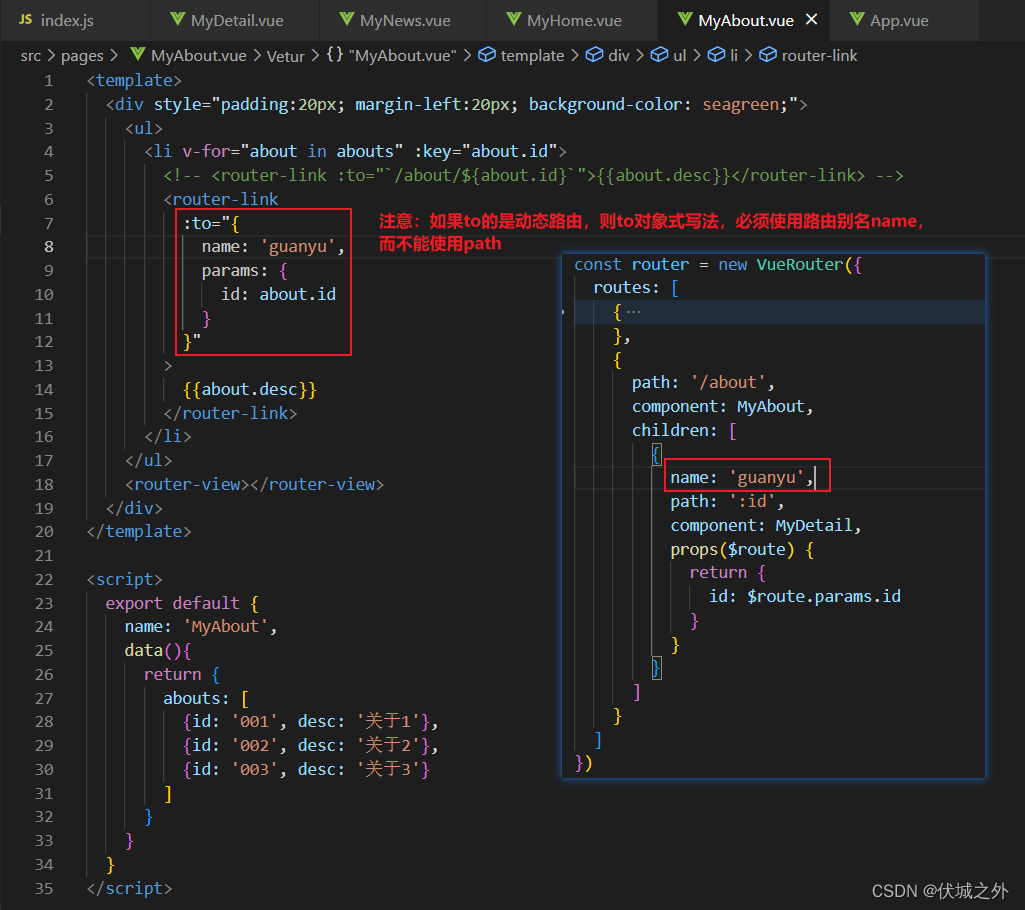
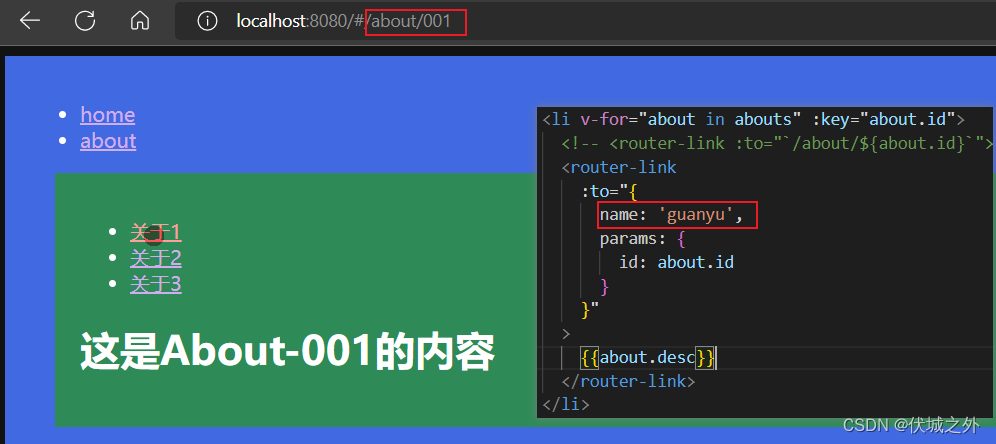
需要注意的是,如果router-link to的是动态路由,则to对象式写法只能导航到 路由别名,而不能导航到 路由hash地址。因为Vue Router不会将to对象中的path和params组合后进行路由查找,而是直接查找path对应的路由

而to对象使用name查找路由的话,则会考虑进params
命名router-view
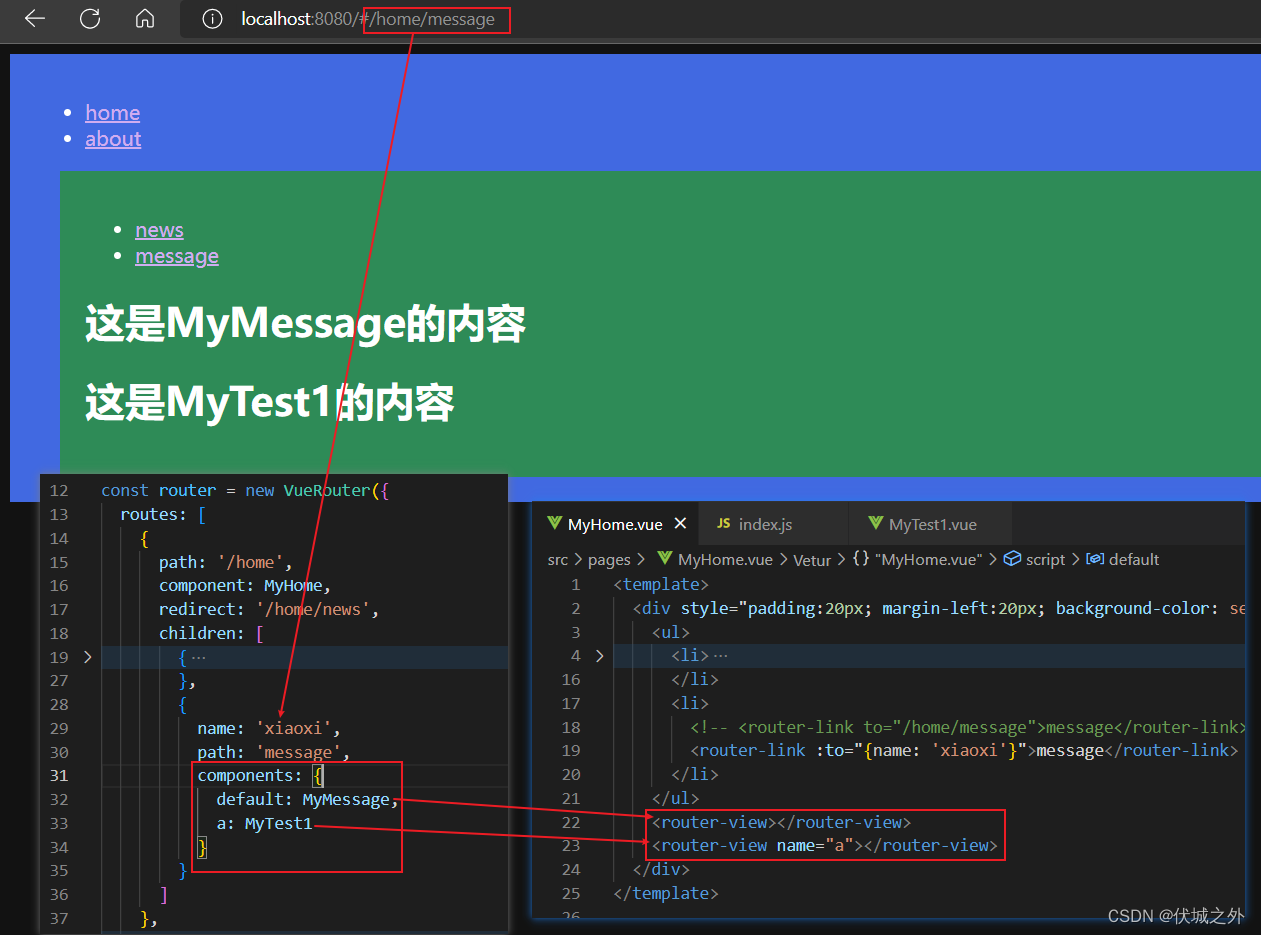
路由配置属性components的对象式写法
router-view的作用是占位,当router-link改变了地址栏hash地址后,路由器就会将对应hash地址的路由组件component渲染到router-view中。
但是一个router-view只能渲染一个路由组件,即使我们将router-view定义多次,也只是将一个路由组件渲染多次而已。
所以,为了能够在提供多种路由组件给router-view,可以使用路由配置属性components
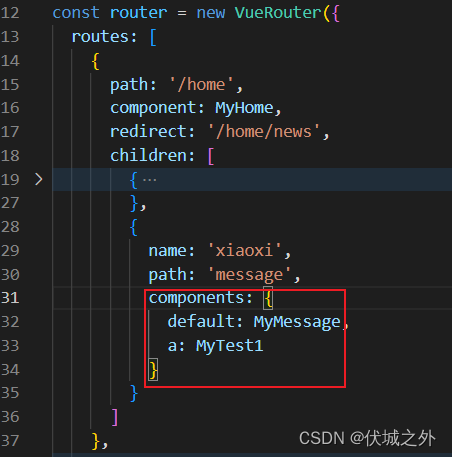
命名router-view
路由器根据hash地址找到了对应路由配置对象的components属性,然后路由器会将:
- components.default对应的组件 渲染到 未命名的router-view中
- components.xxx对应的组件 渲染到 命名为xxx的router-view中
编程式导航
什么是导航
Vue Router中导航的意思就是改变浏览器地址栏的URL的hash地址,来促使内容切换。
声明式导航
- router-link组件的to属性可以改变浏览器地址栏的URL的hash地址
- a标签的href属性可以改变浏览器地址栏的URL的hash地址
上面这种通过标签点击改变hash地址的方式,称为声明式导航
编程式导航
使用代码来改变浏览器地址栏的URL的hash地址 的方式就是编程式导航。
之前介绍SPA路由时,我们尝试了:
- location.hash
- history.pushState,history.replaceState
来改变hash地址,这些方式就是编程式导航。
而Vue Router对这些方式进行了更加完整的封装,并定义为了 路由器实例 router的方法
- router.push(hash | routeObj,onComplete, onAbort)
- router.replace(hash | routeObj,onComplete, onAbort)
- router.go(n)
编程式导航相较于声明式导航的自由度更高,可以进行异步导航。
router.push
router.push有三个入参
- hash | routeObj:hash即hash地址,routeObj即相当于router-link to的对象
- onComplete:可选,成功回调
- onAbort:可选,中止回调

router.replace
router.replace与router.push用法相同,只是在URL存入历史记录栈的方式不同。
router.push是将URL压入栈顶
router.replace是先将栈顶URL出栈,再将replace的URL压入栈顶,表现为替换掉栈顶URL。
router.go
router.go只有一个入参,入参是一个数值。
该方法是模拟浏览器的前进、后退菜单键功能。
入参正数值,表示前进n个,入参负数值,表示后退n个。


导航守卫
什么是导航守卫
所谓导航守卫,就是导航拦截。
即,当你访问某hash地址对应的路由组件时,路由器会先拦截你的访问,然后校验你的权限信息,如果权限合法,则放开拦截,让你访问对应路由组件,否则就保持拦截。
为什么需要导航守卫
可能大家一听到权限校验相关的东西,下意识决定应该是后端的事情,但是实际企业开发中,基本上所有的校验都要求前后端保持一致。
如果前端未加校验,只在后端加校验,则虽然有后端兜底,不会发生安全问题,但是前端给用户的体验会变差,让用户怀疑网站的安全性。
如果前端加了校验,后端没加校验,则黑客可以绕过前端的校验,直接与后端对话,造成安全问题。
说白了,前端校验就是个样子工程,不做虽然不会导致大问题,但是面子过不去。
所以,前端是需要导航守卫的,虽然是个面子工程。
导航守卫的分类
- 全局导航守卫:前置、后置
- 路由独享守卫
- 组件内的守卫:路由进入前,路由离开后
全局导航前置守卫
全局导航前置守卫,就是路由器实例的一个方法beforeEach,该方法接收一个回调函数作为入参。
当导航触发时,beforeEach的参数回调函数就会被调用,底层会依次传入
- to:到哪个路由去
- from:从哪个路由来
- next:放行函数
作为beforeEach的参数回调函数的入参。
下面例子,定义了一个全局导航前置守卫

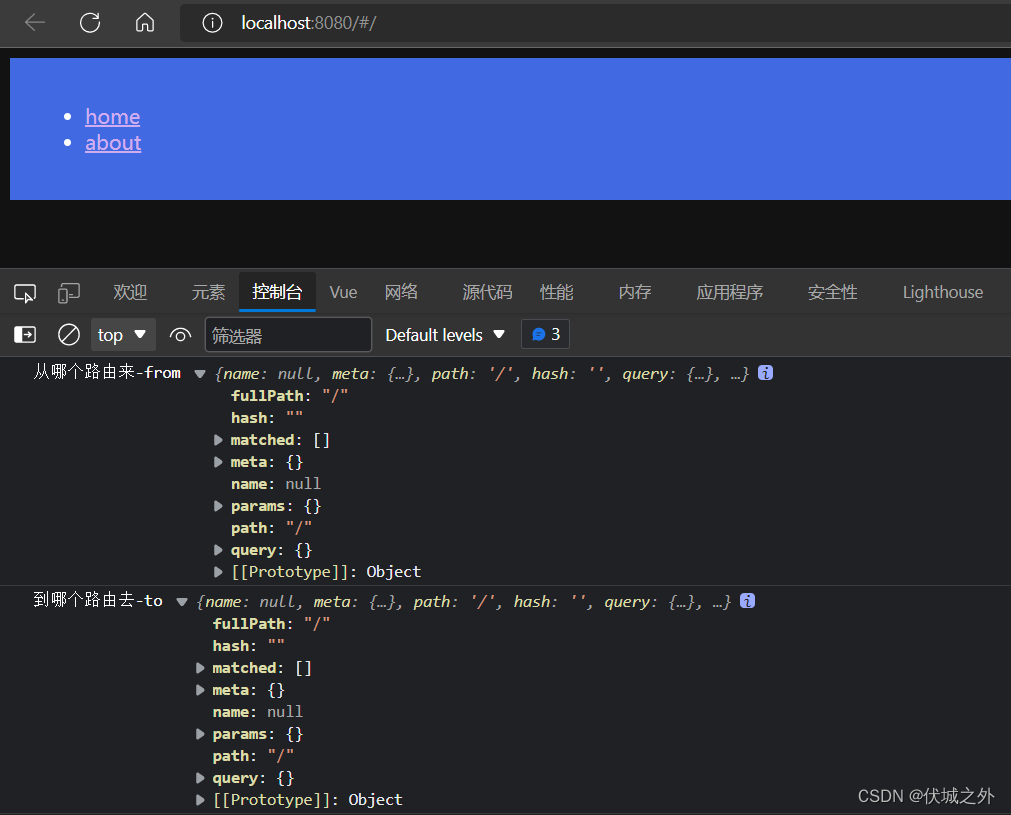
全局导航前置守卫的回调函数执行时机是:
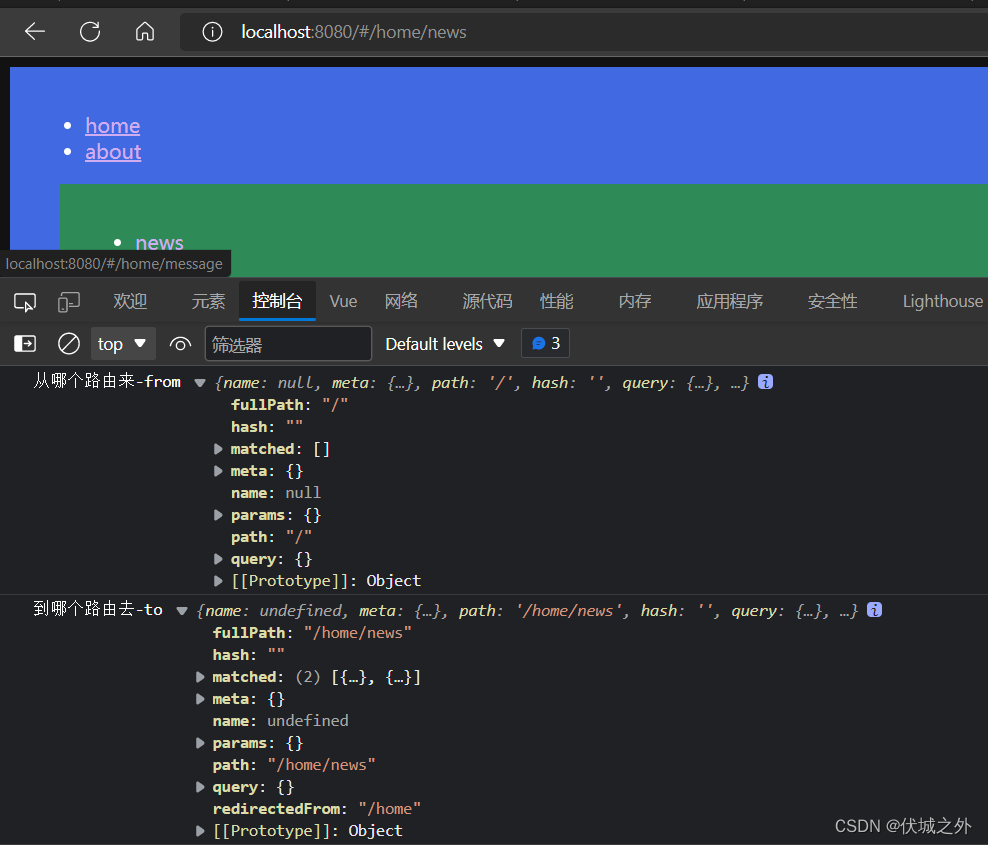
1、项目首次加载时,此时相当于hash地址从 / 到 /
2、hash地址发生改变时,如下例中,hash地址从 / 变为 /home/news
关于next函数的四种调用方式
next函数是放行函数,它有四种调用方式:
- next():放行到目的路由
- next(hash):放行到指定hash地址对应的路由
- next(false):不放行,阻止路由跳转,保持在本路由
- next(err):err是一个Error对象,此时next执行会触发router.onError的参数回调函数
router.beforeEach((to, from, next) => {
const token = JSON.parse(localStorage.getItem('token'))
let permission = 0; // 未登录
if (token) {
const { name, pass } = token
if (name == 'qfc' && pass == '123456') {
permission = 2 // 已登录,最高权限
} else {
permission = 1 // 已登录,普通权限
}
}
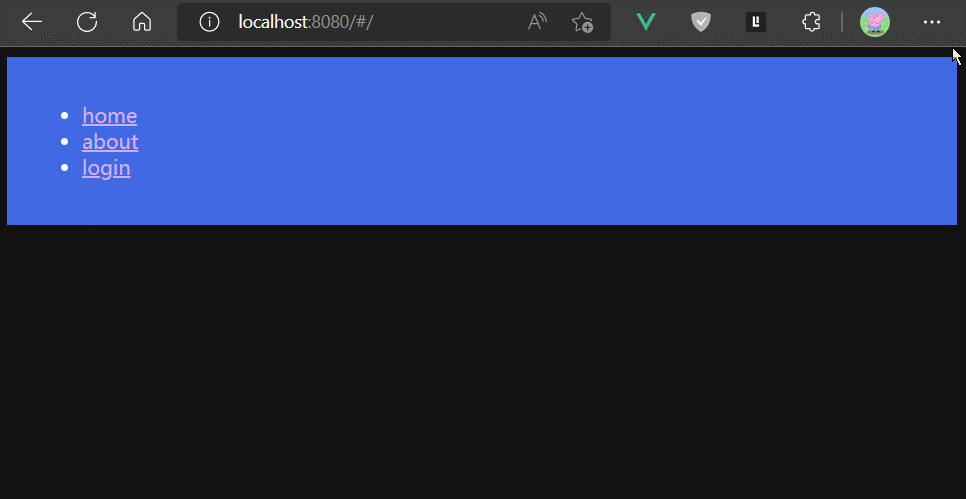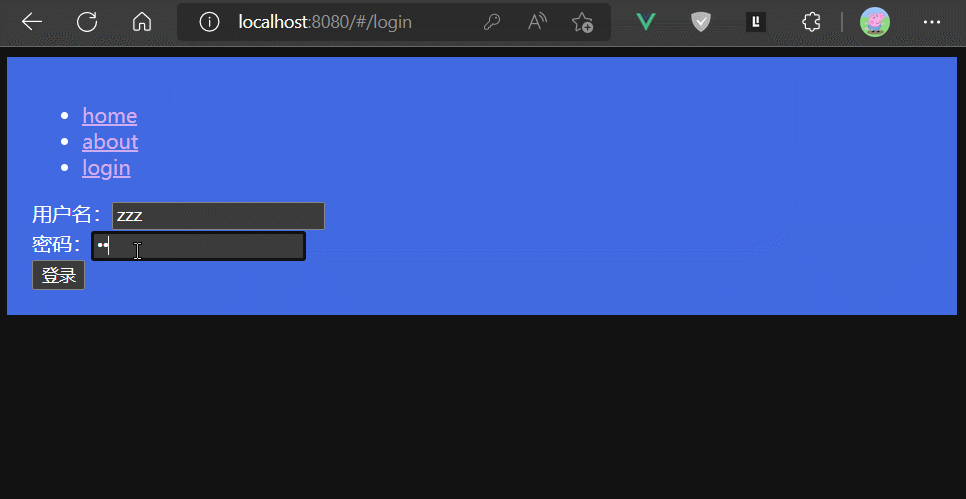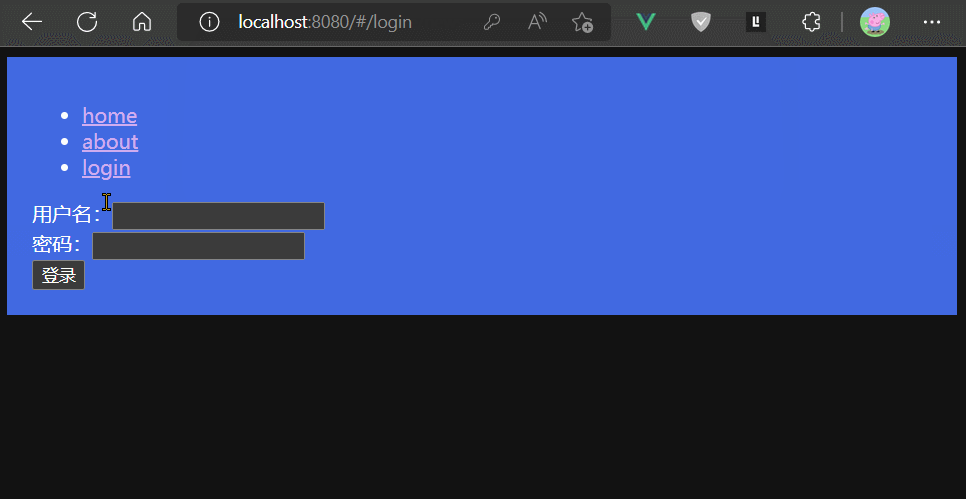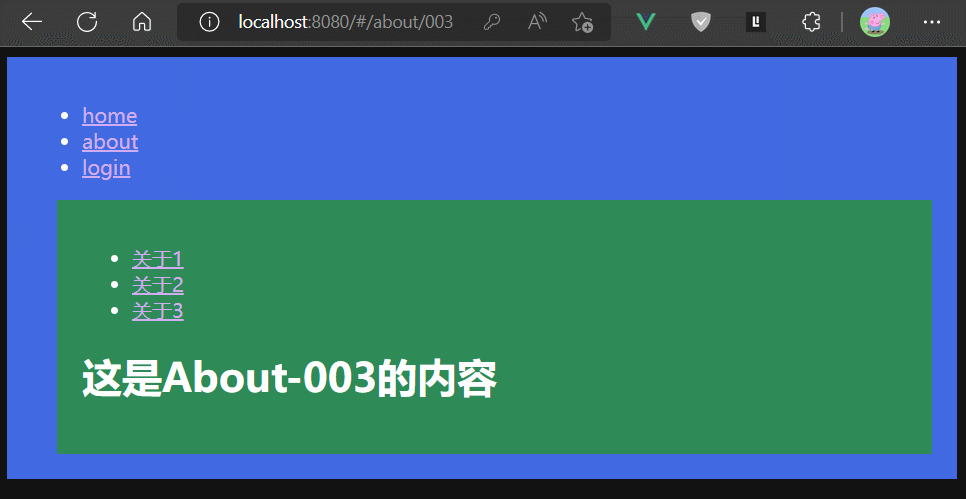
if (to.path === '/login' || permission === 2) {
return next()
}
if (permission === 0) {
alert('未登录,请先登录')
return next('/login')
}
if (permission === 1 && to.path.startsWith('/about')) {
alert('权限不足,访问被中止')
return next(false)
}
next()
})

上面例子分别演示了next放行函数的三种常用用法。
我们需要注意的是,导航守卫中next方法能且只能严格调用一次。
- 如果导航守卫中next方法被一次也没被调用,则导航流程阻塞
- 如果导航守卫中next方法被调用了多次,理论上只有最后一次有效
全局导航后置守卫
全局导航后置守卫,就是路由器实例的一个方法afterEach,该方法接收一个回调函数作为入参。
当导航结束时,afterEach的参数回调函数就会被调用,底层会依次传入
- to:目的路由对象
- from:源路由对象
作为afterEach的参数回调函数的入参
和beforeEach参数回调函数入参不同的是,afterEach的参数回调函数没有next函数,这表明了afterEach并不会起到拦截作用。
afterEach参数回调的调用时机是:
- 当路由切换成功时,afterEach参数回调被调用。
- 当路由切换失败或者被阻止,则afterEach参数回调不会被调用。
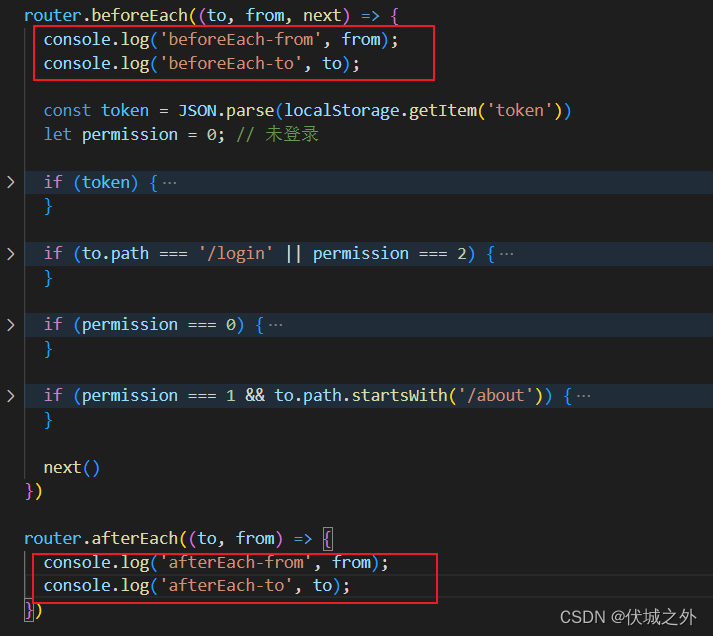

通过上面例子,我们可以发现,
- 只要触发导航,则beforeEach的参数回调就会调用,无论导航最终成功还是中止
- 而afterEach的参数回调只有在导航成功完成时,才会被调用
afterEach的作用是,当导航到目标路由后,做一些beforeEach中不好做的统一收尾工作。
比如我们想要变更document.title为当前路由的对应的信息,如果我们在beforeEach中处理的话
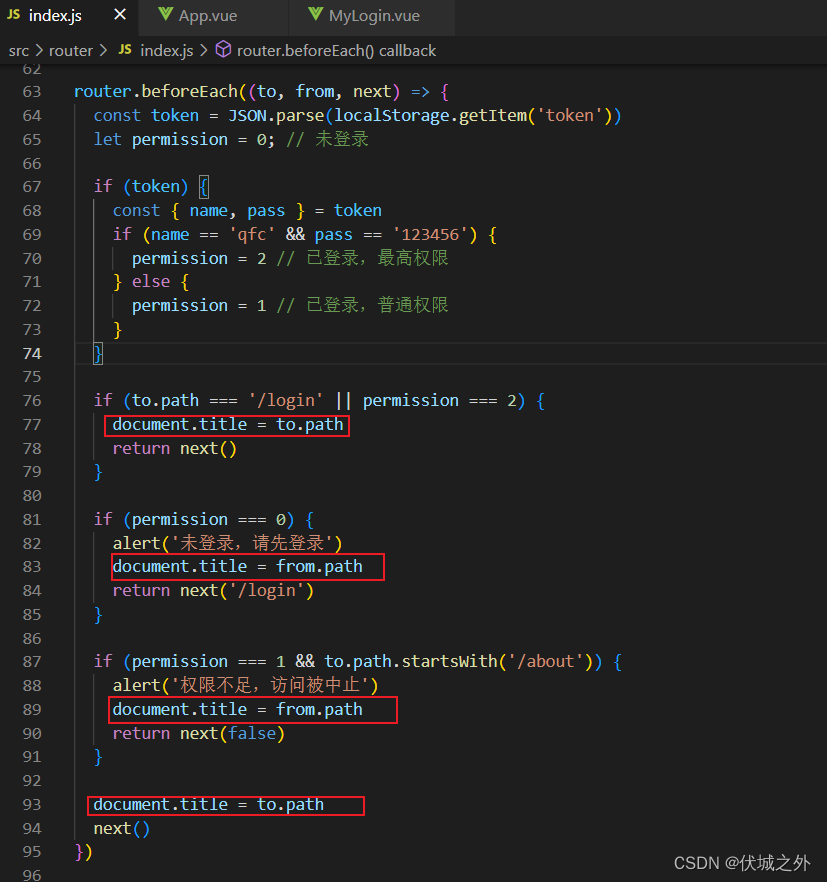
可以发现在beforeEach中需要在每次next调用前进行document.title的设置,即需要设置多次,并且要考虑路由跳转中止的话,不能使用to.path作为document.title,只能使用from.path作为document.title。
而在afterEach中,只需要设置一次,且由于afterEach的参数回调只有在路由跳转成功后才会调用,所以可以仅使用to.path作为document.title。

路由元信息属性 meta
前面在实现路由校验时,除了要校验用户登录状态,还要校验用户是否有访问对应路由的权限。而当前,我们只能在router.beforeEach中判断各种路由path是否需要权限,此时router.beforeEach中的逻辑非常难看,且后期不容易维护
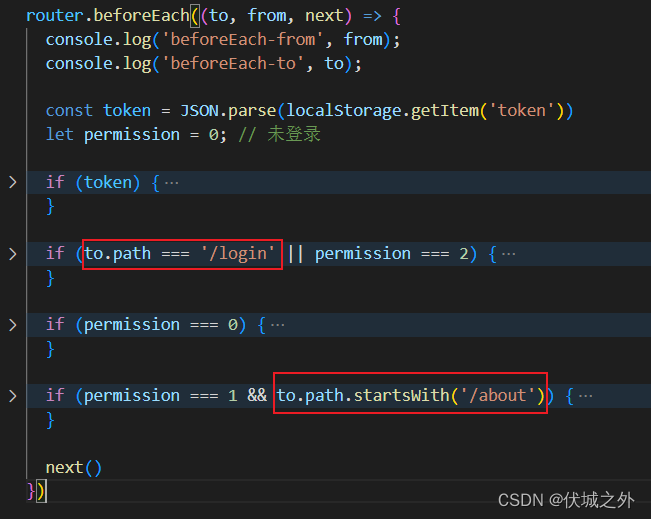
此时我们可以在路由对象中为路由设置元信息,来标记该路由是否需要权限校验
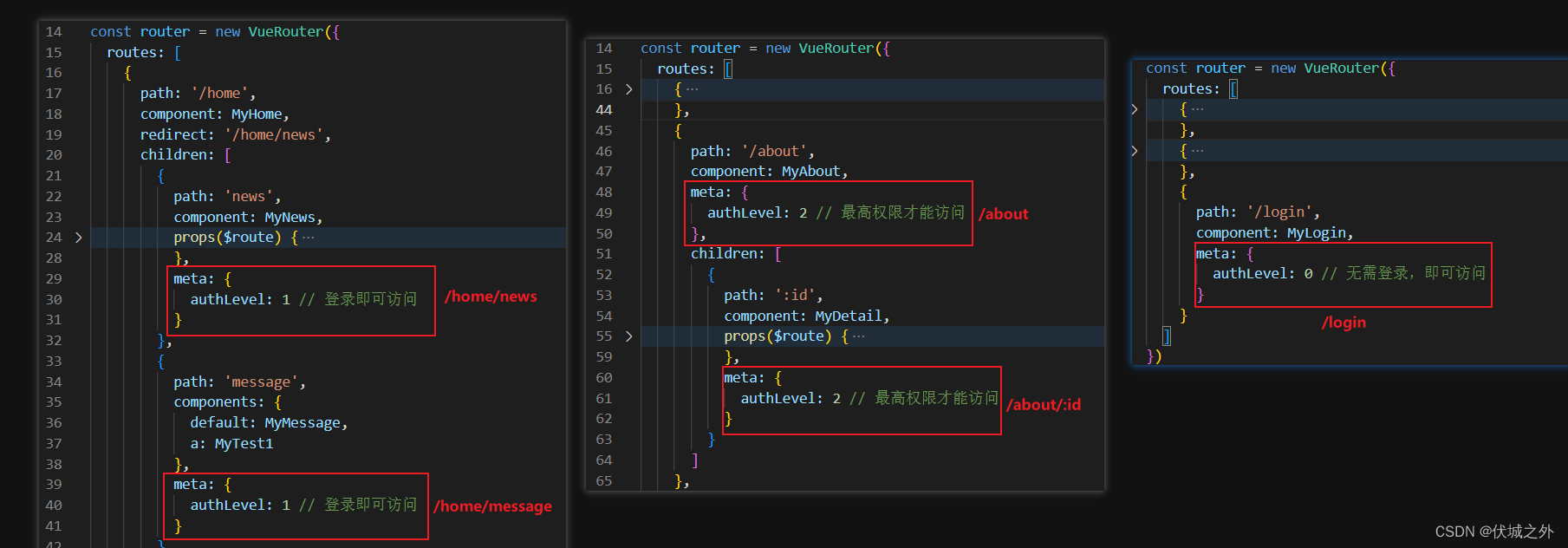
然后在router.beforeEach参数回调中就不需要维护固定path的权限校验了,而是改为统一权限校验

路由独享守卫
路由独享守卫 只作用于 当前路由,即当导航到当前路由时,会触发当前路由的独享守卫。
我们可以在路由配置对象中,定义路由独享守卫属性beforeEnter,它是一个函数,底层依次传入
- to
- from
- next
三个入参给beforeEnter。
beforeEnter的调用时机为:当导航到beforeEnter所在路由时,就会触发beforeEnter的执行。
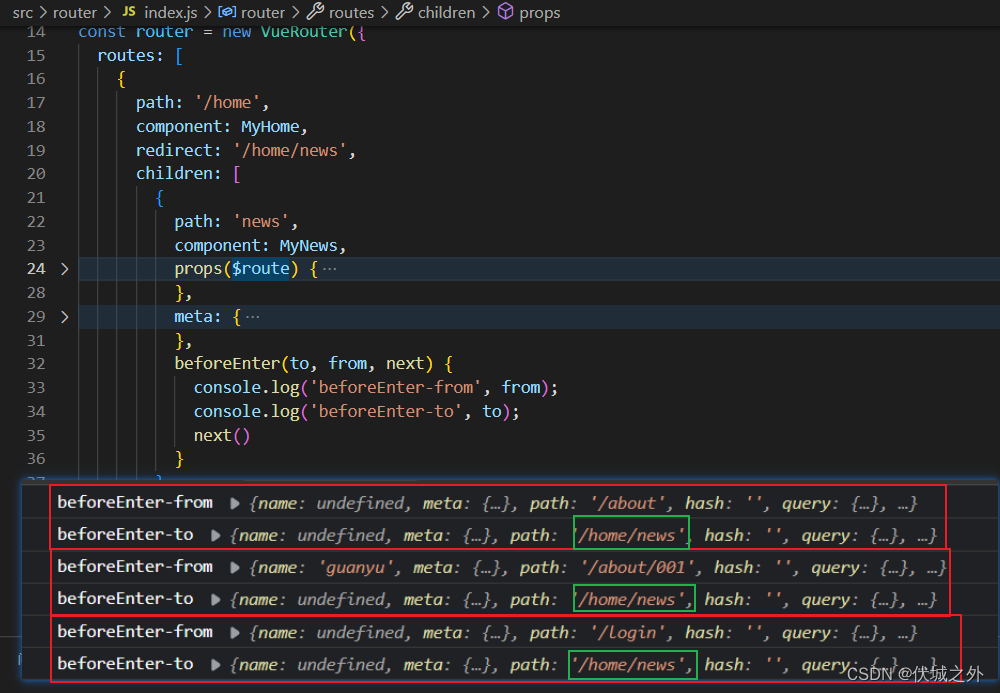
我们可以发现beforeEnter入参的to,永远都是自己所在的路由。
路由独享守卫,可以做一些路由私有的权限校验。
而如果一个路由,既被路由独享守卫作用,也被全局导航守卫作用,则各守卫执行顺序如下
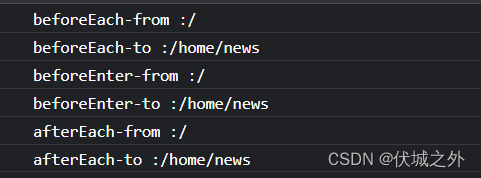
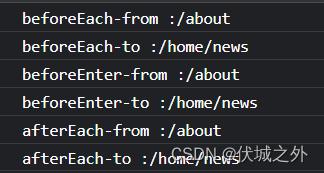
可以发现,执行顺序是:全局导航前置守卫 => 路由独享守卫 => 全局导航后置守卫
组件内守卫
组件内路由守卫有三个
- beforeRouteEnter(to, from, next)
- beforeRouteUpdate(to, from, next)
- beforeRouteLeave(to, from, next)
而组件内路由守卫,既可以当成导航守卫使用,也可以当成路由组件特有的生命周期钩子使用。
需要注意的是,这三个钩子函数,只有路由组件才有,非路由组件没有。
其实一个组件既可以用作路由组件,也可以用作非路由组件。如下例中,MyLogin既当成了非路由组件使用,又当成了路由组件使用。
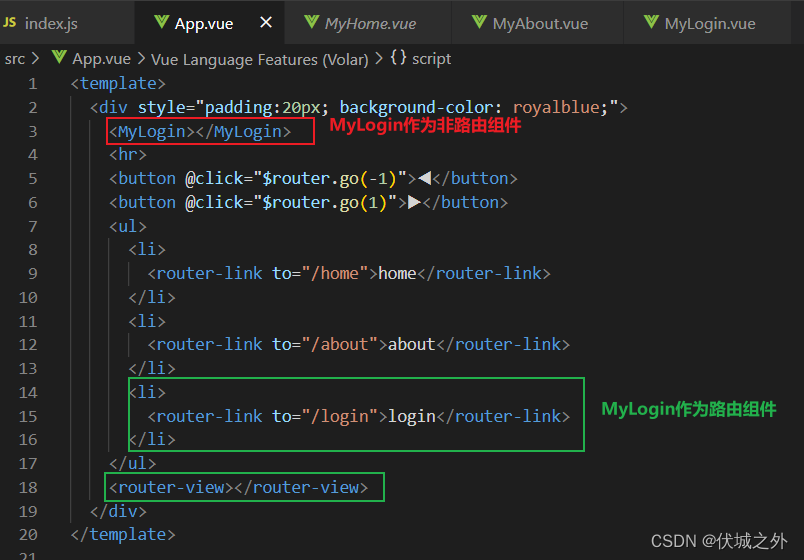
- 作为非路由组件的MyLogin来说,它无法触发上面三个钩子。
- 作为路由组件的MyLogin来说,它可以触发上面三个钩子。
其根本原因是,当路由组件是由路由器管理渲染的,而路由器在渲染路由组件的过程中,会调用上面三个钩子。
而非路由组件不是由路由器管理渲染的,所以即使非路由组件定义了上面三个钩子,也没有路由器去调用。
总结,只有组件被路由器渲染时,才会触发组件的beforeRouteEnter、beforeRouteUpdate、beforeRouteLeave三个钩子。
beforeRouteEnter是在路由组件被渲染之前,即被创建之前调用的,因此此时beforeRouteEnter中是无法访问到组件实例this的。
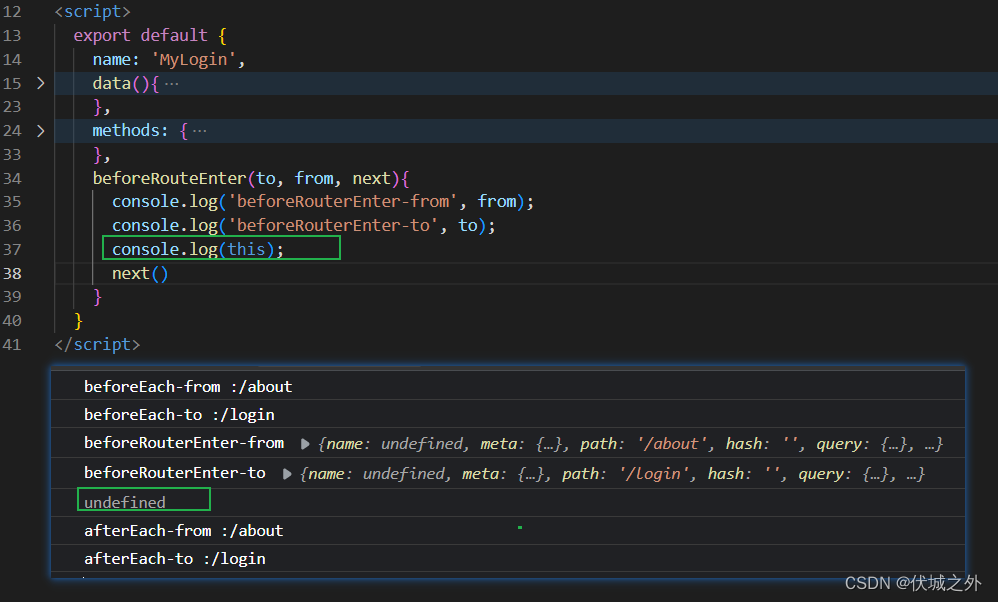
beforeRouteUpdate 是在路由组件更新时触发的,这里的更新特指:动态路由之间切换时,比如/about/001到/about/002
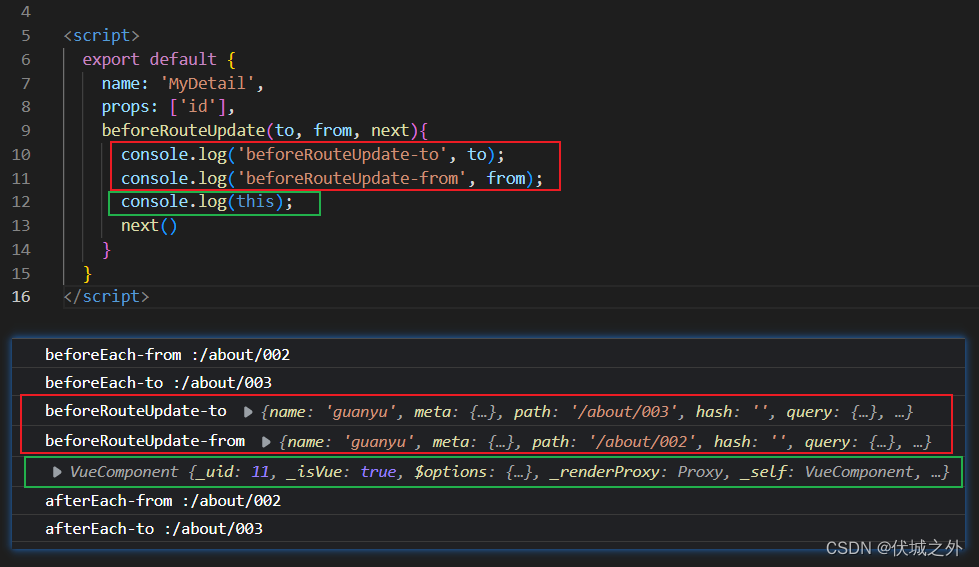
并且,此时beforeRouteUpdate 中可以访问到组件实例。
beforeRouteLeave是在路由组件被卸载之前调用的,即从当前路由 导航到 其他路由前调用
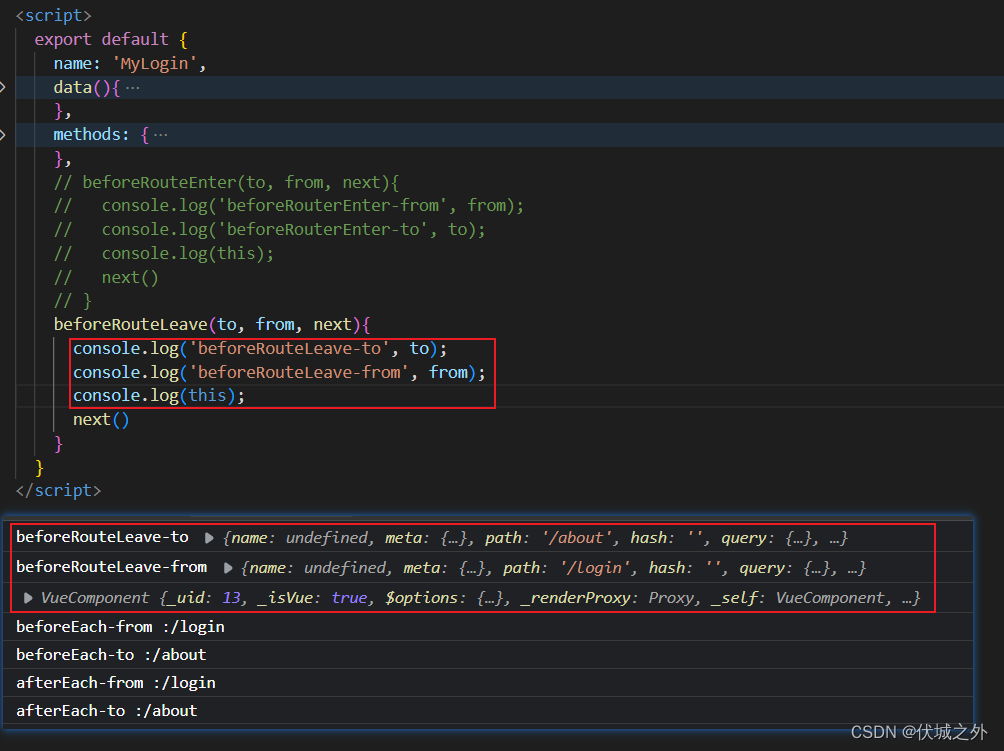
需要注意的是,beforeRouteLeave会在全局导航前置守卫前执行。
beforeRouteLeave可以用来提示用户输入未保存,阻止其跳转到其他路由.
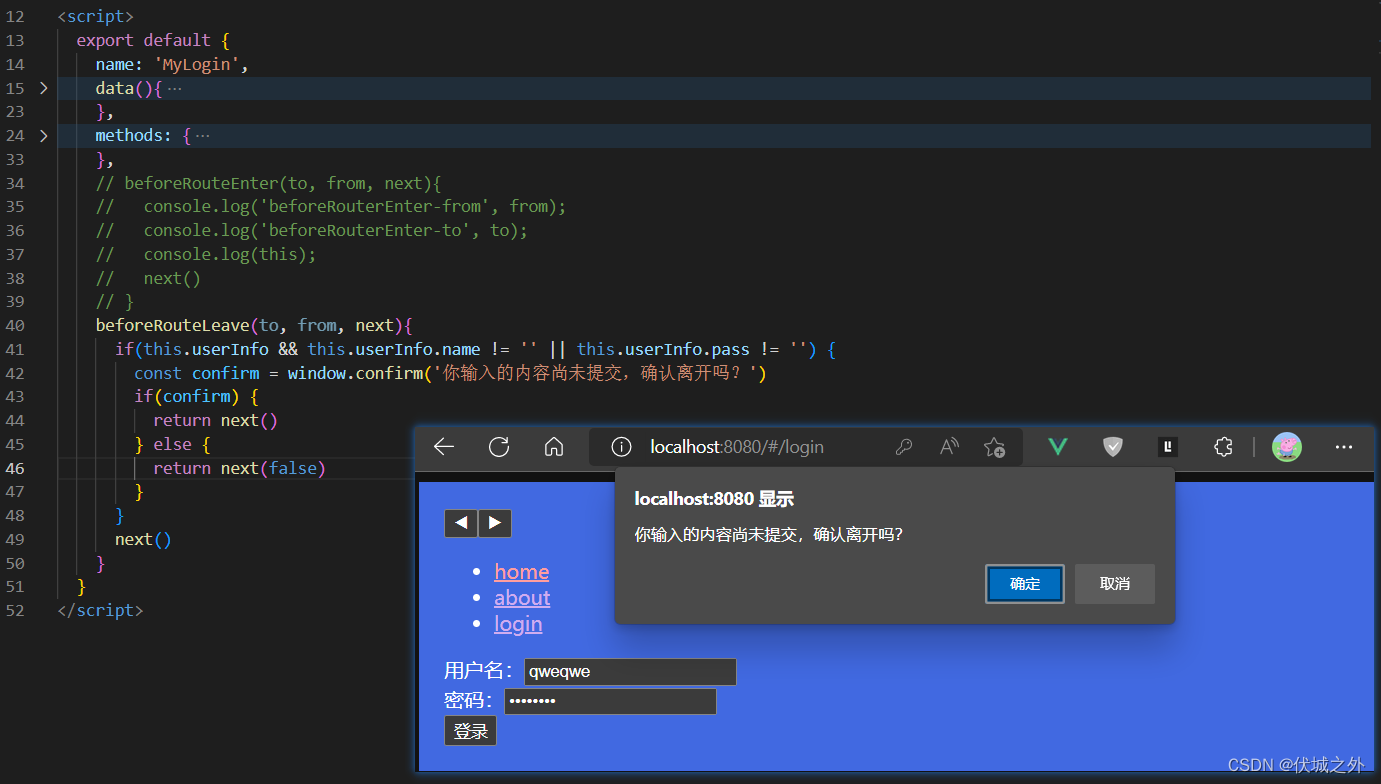
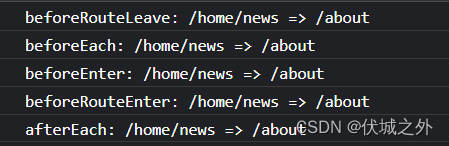
完整的导航解析流程
当一个导航触发后,必然是从一个路由from 跳转到 另一个路由to;
如果from、to都是同一个动态路由,则
- beforeEach触发
- to路由的beforeRouteUpdate触发
- afterEach触发

如果from、to有一个不是动态路由,则
- from路由的beforeRouteLeave触发
- beforeEach触发
- to路由的beforeEnter触发
- to路由的beforeRouteEnter触发
- afterEach触发
路由器的两种工作模式
hash模式
VueRouter的默认工作模式就是hash模式。
而hash工作模式,指的是:路由器通过监听浏览器地址栏中URL的hash地址的变化,来实现前端路由。
此模式的特点是,浏览器地址栏中URL中必定有一个#,如

不适合有强迫症的人群。但是此时模式兼容性好。
并且URL中的hash地址仅用于前端路由,不会发送给后端服务器。
histroy模式
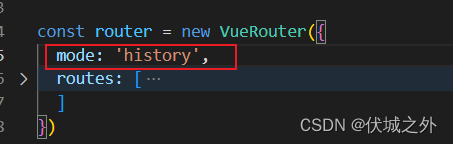
所谓history模式,即路由器监听的是浏览器地址栏URL的变化,此时URL不需要携带#。
比如 localhost:8080/about
我们可以在定义路由器实例的VueRouter入参配置对象中增加一个属性:mode: 'history'
来开启路由器的history工作模式。
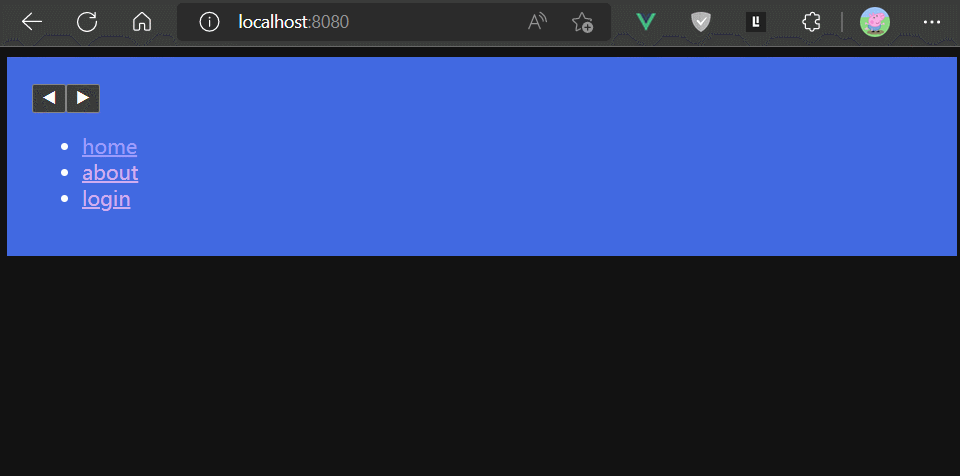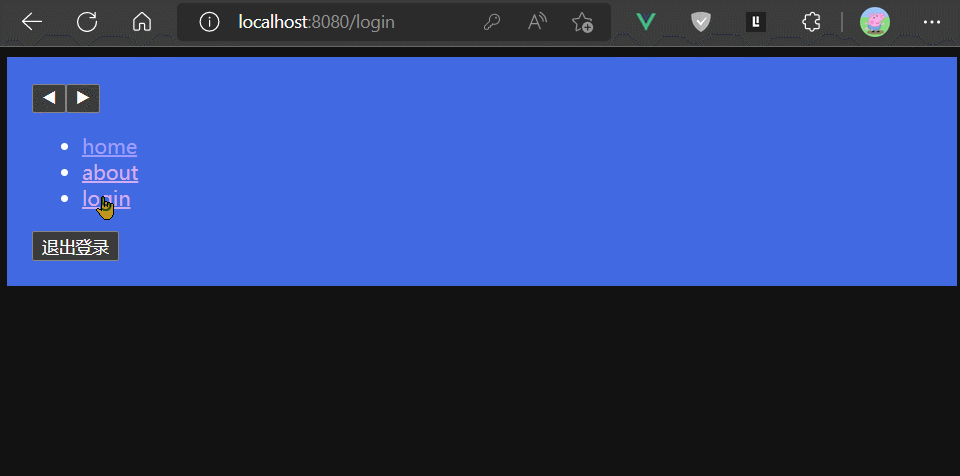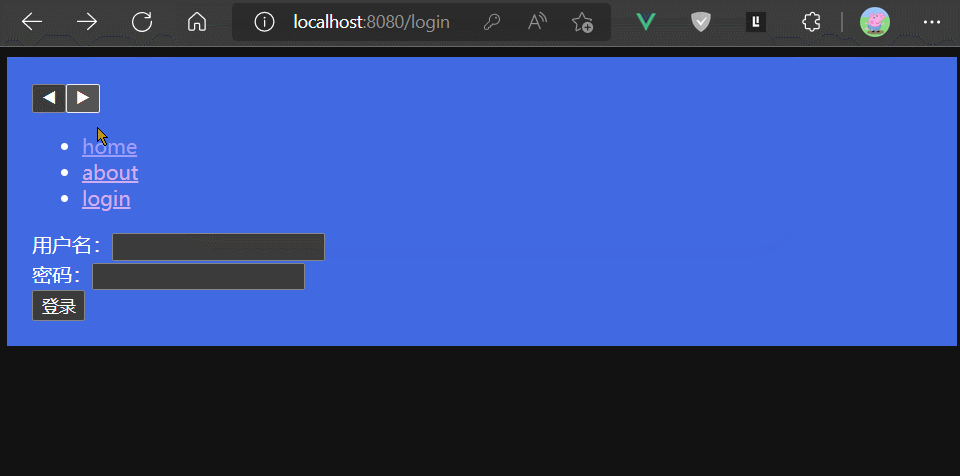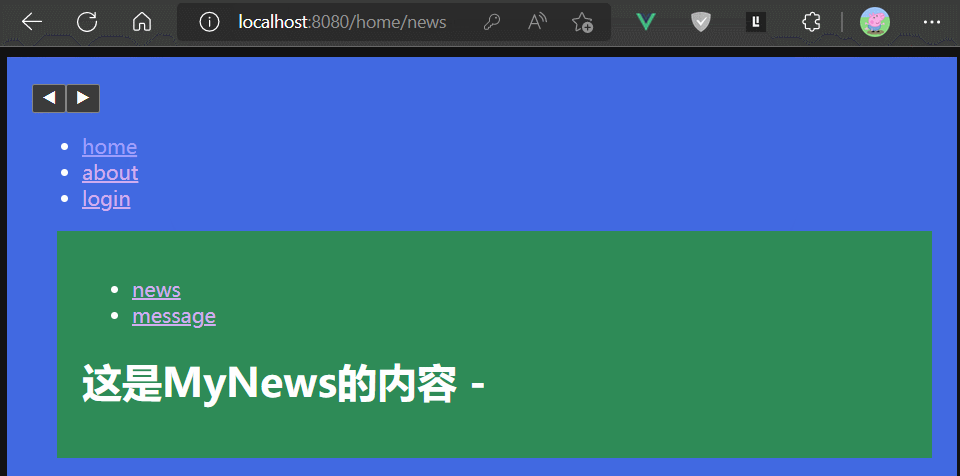
注意观察上面例子中,浏览器地址栏的变化,可以发现此时地址栏URL不再带有#。
这种工作模式的优点是:提升了强迫症患者的视觉感受
但是history模式的缺点却十分致命:
- 兼容性不好,一些老版本的浏览器不支持history模式
- history模式下的网页刷新可能会导致发送未知的请求到服务器,如果服务器未做特殊处理的话,则SPA应用将发生错误。
对于第二种缺点,我们可以将Vue项目打包后部署到一个服务器上
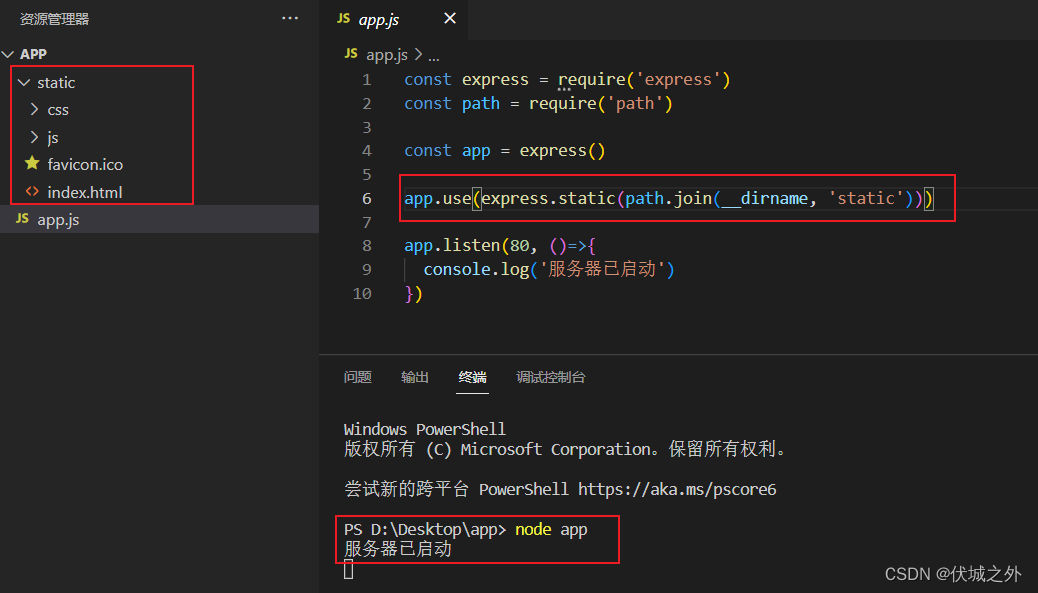
如上图,我们利用node+express创建一个静态资源托管的服务器,并将SPA项目部署到了服务器静态资源目录,之后启动了服务器。

可以发现,如果我们按照SPA单页面中定义好的导航进行跳转,则没有任何问题。但是当我们刷新网页时,或者通过浏览器地址栏访问某SPA路由时,SPA应用就出错了。
原因很简单,由于是history模式,所以此时前端路由的URL,和后端路由的URL没有任何区别,当我们刷新网页时,或者通过浏览器地址访问某SPA路由时,会触发两种行为:
- 前端路由:路由器监听到URL的变化,开始准备对应组件渲染到展示区
- 后端路由:浏览器监听到地址栏URL的变化,开始发送HTTP GET请求到服务器获取对应资源
其中后端路由会失败,因为虽然此时地址栏URL本质还是前端路由,在服务器上并没有对应路由的接口。
比如:localhost/home/news?id=001
当我们刷新网页时,浏览器就会发送一个HTTP GET请求到服务器获取对应资源
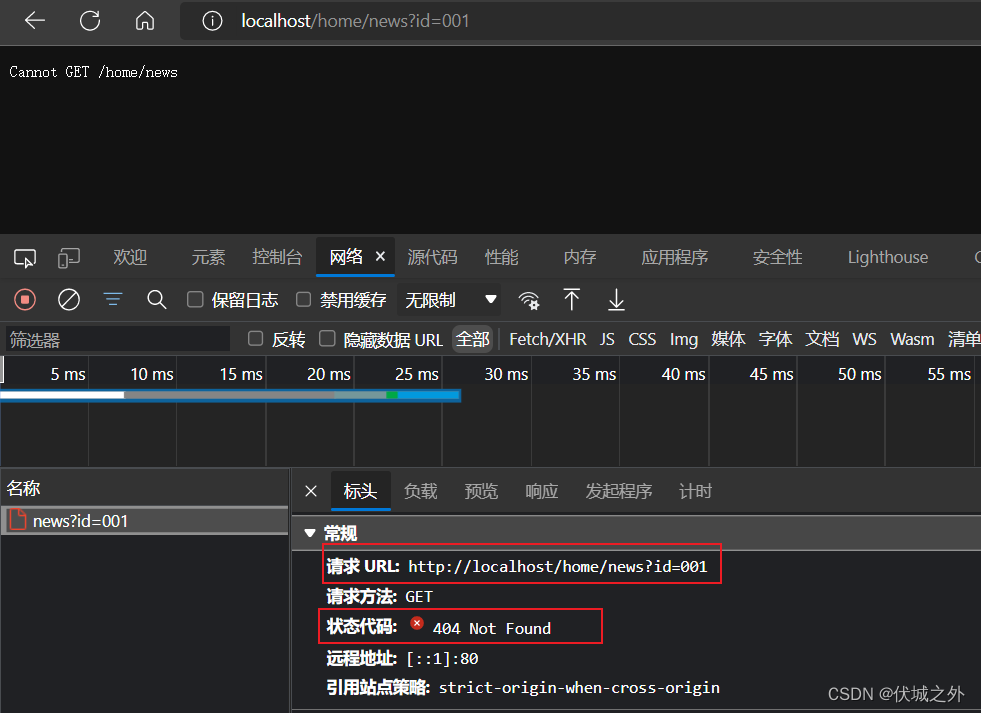
此时的解决方案是,让服务器定制对应的前端路由URL对应的接口,然后响应200给前端,让前端不会报错即可。
而express有一个第三方中间件connect-history-api-fallback - npm (npmjs.com)
就可以帮助后端express服务器自动处理这些前端路由URL。
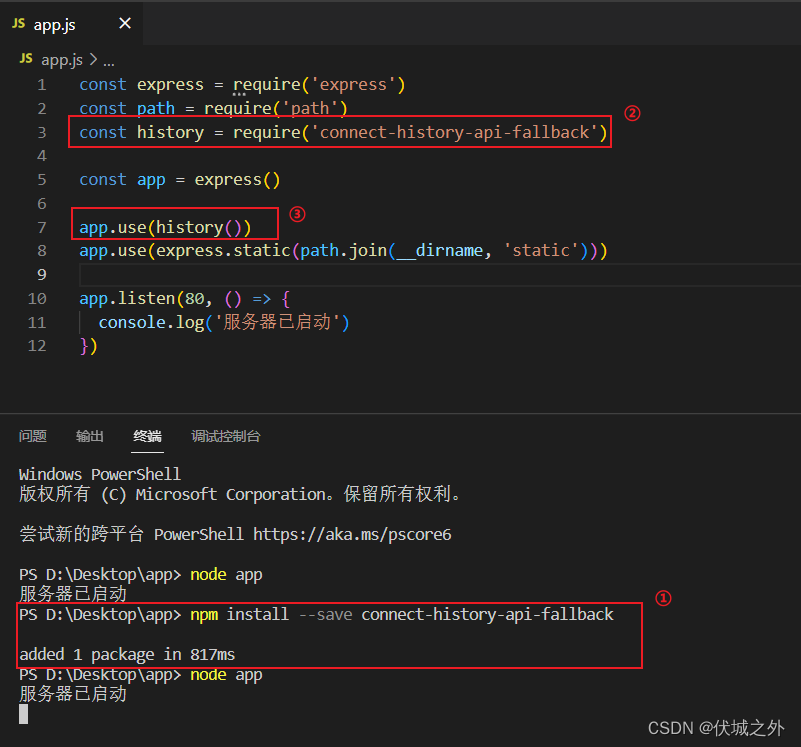

最终代码案例
GitHub - qwx427219/Vue_SPA_Router![]() https://github.com/qwx427219/Vue_SPA_Router.git
https://github.com/qwx427219/Vue_SPA_Router.git
相关文章
- Vue笔记:bin-code-editor使用
- vue axios的使用
- vue中router-link的使用
- [Vue @Component] Switch Between Vue Components with Dynamic Components
- [Angular2 Router] Index router
- vue.js3: 多张图片合并(vue@3.2.37)
- vue-router新手指南
- [Vue + TS] Create Type-Safe Vue Directives in TypeScript
- [Vue] Get up and running with vue-router
- vue.js3: 安装使用vue-router(vue-router@4.0.16 / vue@3.2.37)
- vue指令:v-text和v-html
- vue-router路由示例
- vue中,选中多个选项,并且使其高亮
- Vue新窗口打开this.$router
- vue-router(路由嵌套)
- Springboot+Vue实现将图片和表单一起提交到后端,同时将图片地址保存到数据库、再次将存储的图片展示到前端vue页面
- Vue-router路由判断页面未登录跳转到登录页面
- vue知识点
- vue-tour快速入门:VUE项目中如何使用vue-tour新手引导指引插件?怎样使用?包含具体实例
- vue路由传递参数的几种方式详解
- 为什么要学Vue,Vue.js是什么,开始学Vue,Vue的基础指令,自定义指令