
【Transformer】5、CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows

论文:https://arxiv.org/pdf/2107.00652.pdf
代码:https://github.com/microsoft/CSWin-Transformer
文章目录
一、背景
目前,基于transformer的方法在 CV 领域基本实现了和CNN相当的效果,其好的效果来源于内部多头自注意力机制对远距离依赖的建模能力,这对以高分辨率数据作为输入的下游方法(检测、分割等)都很有帮助。但另外,由于 Transormer 结构是全注意力结构,计算量很大。
其他 transformer 的问题所在:
- 基于 global attention 的 transformer 效果虽然好但是计算量太大了。
- 基于 local attention 的 transformer 会限制每个 token 的感受野的交互,减缓感受野的增长。
本文 CSwin:
- 提出了 Cross-Shaped Window self-attention 机制,可以并行计算水平和竖直方向的 self-attention,可以在更小的计算量条件下获得更好的效果。
- 提出了 Locally-enhanced Positional Encoding(LePE), 可以更好的处理局部位置信息,并且支持任意形状的输入。
CSwin 和 Swin 的不同:
- patch 划分方式:Swin 采用大小为 4x4(stride=4)的不重叠卷积来划分 patch,CSwin 采用大小为 7x7(stride=4)的重叠卷积来划分 patch
- windows 划分方式:Swin 采用正方形 windows 划分方式,CSwin 采用横向和纵向的矩形 windows 划分方式,一定程度上提高了感受野
- patch merging 的方式:从 Swin 的 merge patch(间隔提取元素,然后 concat) 替换成了大小为 3x3(stride=2)的卷积
CSwin 和 Swin 的相同:
- 都是在 windows 内部进行 self-attention,能够降低计算量
二、动机
为了提高速度,一个典型的方法是限制 attention 计算的区域,也就是进行 local/windowed attention,为了建立不同 window 之间的联系,一些作者使用转移window的方法来实现。但是这些方法随着深度的增加,感受野的大小提升的很慢,并且需要堆叠更多的 blocks 来实现全局的attention。但是,下游的任务往往都需要足够大的感受野,所以,如果在获得大的感受野的同时来保证计算量较低是很重要的。
三、方法

本文作者提出了一种名叫 Cross-Shaped Window (CSwin) self-attention,作者并行的进行垂直和水平两个方向的 self-attention 计算。 如图1所示。
3.1 总体结构
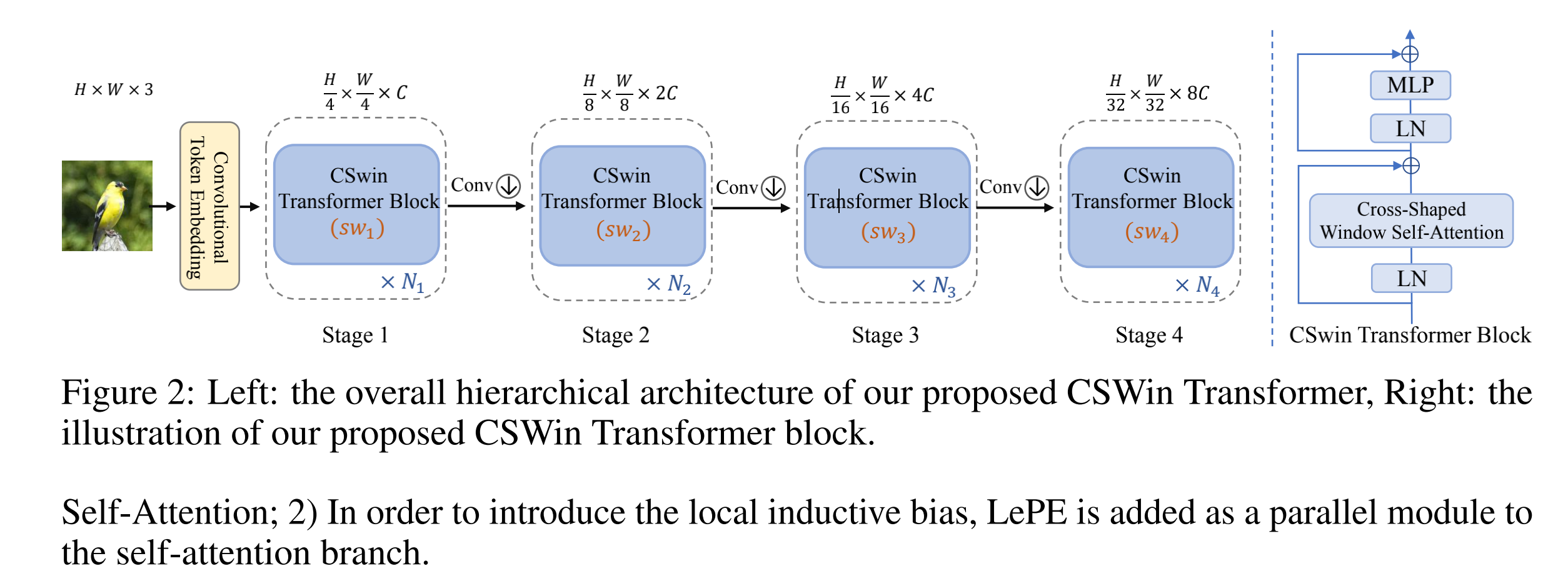
CSwin 的结构如图2所示:
- 输入: H × W × 3 H \times W \times 3 H×W×3
- patch tocken 的获得:使用大小为 7 × 7 7\times7 7×7 步长为 4 的卷积来获得大小为 H 4 × W 4 \frac{H}{4} \times \frac{W}{4} 4H×4W 的 patch tokens,每个 token 的维度是 C C C。
- 产生层级表达:作者使用了 4 个 stage 来产生不同的层级表达,两个相邻层级之间使用卷积层( 3 × 3 , s t r i d e s = 2 3 \times 3, strides=2 3×3,strides=2) 来降低token的数量,并将 channel 扩充为2倍。
- 每个 stage 的 token 数量: H 2 i + 1 × W 2 i + 1 \frac{H}{2^{i+1}} \times \frac{W}{2^{i+1}} 2i+1H×2i+1W
- 每个 stage i i i 包含 N i N_i Ni 个顺序的 CSWin Transformer Blocks
CSWin Transformer Block 和其他基于多头 self-attention 的 transformer 结构的不同:
- CSWin 使用 cross-shaped window attention
- LePE 被作为一个并行模块加入 self-attention 分支,来引入局部归纳偏置
3.2 Cross-Shaped Window Self-Attention
本文作者提出了一种名叫 Cross-Shaped Window (CSwin) self-attention,作者并行的进行垂直和水平两个方向的 self-attention 计算。 如图1所示。
如何得到stripe:通过把输入特征切成等宽的stripes来得到
stripe 的宽度非常重要:因为该宽度决定了本文算法的模型建模能力和计算速度的平衡
作者如果确定切分的宽度:通过网络的宽度来确定,即浅层的宽度小,深层的宽度大。
- 大宽度能够保证元素之间的 long-range 关联的保留
- 更好的保证网络的容量
- 较少的提高计算复杂度
如何并行进行水平和垂直的 attention 计算:
作者将多头注意力分成并行的 groups,并且对不同的 group 使用不同的 self-attention 操作方式。
这种并行的机制没有引入额外的计算量,并且能够提高参与self-attention计算的面积。
Horizontal and Vertical Stripes:
对于水平 stripe self-attention,输入 X 被均分成无重叠的水平 stripe,宽度都为 s w sw sw,每个 stripes 包含 s w × W sw \times W sw×W 个 token,此处 s w sw sw 为 stripe 的宽度,且可以用来平衡模型学习效果和计算复杂度。
假设第 k 个 head 的 q/k/v 维度都为 d k d_k dk,则第 k 个 head 的水平 stripes self-attention 的输出为:
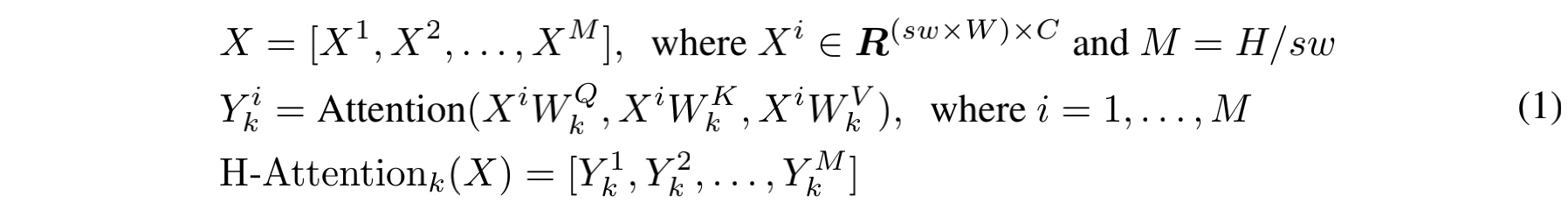
- W Q , W K , W V ∈ R C × d k W^Q, W^K, W^V \in R^{C\times d_k} WQ,WK,WV∈RC×dk 分别为 q/k/v 的投影矩阵, d k d_k dk 为 C / K C/K C/K
- 竖直 stripe self-attention 计算方式类似,第 k 个head的输出定义为 V − A t t e n t i o n k ( X ) V-Attention_k(X) V−Attentionk(X)
假设图像没有带方向的偏置,作者将 K 个 heads 分成两个 group,每个 group 有 K / 2 K/2 K/2 个heads,第一个 group 进行水平 stripe self-attention,第二个 group 进行垂直 stripe self-attention,最后将两者的输出进行 concat。

- W O ∈ R C × C W^O \in R^{C \times C} WO∈RC×C 是影射矩阵,负责将 self-attention 的输出影射为目标输出维度
计算复杂度分析:
CSWin 的计算复杂度如下:
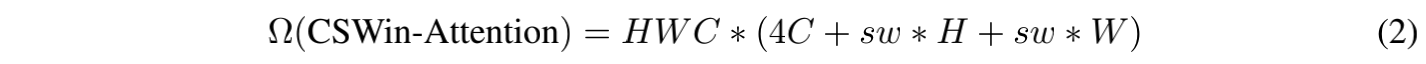
- 对于大分辨率输入, H 、W 一般在浅层会大于 C,在深层会小于 C
- 作者在浅层选择较小的 s w sw sw,在深层选择较大的 s w sw sw,也就是说调整 s w sw sw 能够灵活高效的在深层扩大每个token的 attention 面积。为了中间的特征图能够被 s w sw sw整除(输入为 224),对于 4 个stage, s w sw sw 分别为 1, 2, 7, 7。
Locally-Enhanced Positional Encoding
由于 self-attention 是对排列方式不敏感的,会忽略 2D 图像的位置信息。
现有的很多方法都为了把位置信息加回来而做了很多工作:
- APE[57] 和 CPE[13] 在输入每个 Transformer block之前,把位置信息加到了每个 token 上
- RPE[47] 和本文的 LePE 在每个 Transformer block 内融合了位置信息
- 但不同于 RPE 把位置信息加到 attention 计算时, LePE 使用了更直接的方式,并且利用了线性映射 value 之上的位置信息
假设不同 value
v
i
v_i
vi 和
v
j
v_j
vj 之间的边缘可以用向量
e
i
j
v
∈
E
e_{ij}^v \in E
eijv∈E 来表示,则:
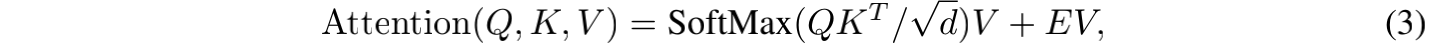
如果计算 E 中的所有关联信息,则计算量很大,作者假设对应特定的元素,最重要的位置信息来源于其周围的邻域,所以作者提出了一种 locally-enhanced positional encoding(LePE),并且联合深度可分离卷积来作用于 value
V
V
V:
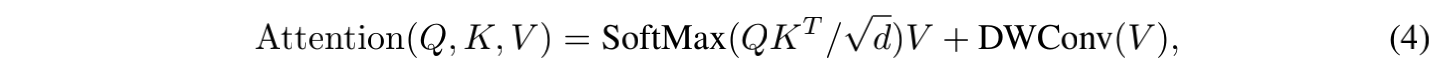
3.3 CSWin Transformer Block
由上述的 self-attention 机制和 position embedding 机制组成的 CSWin Transformer block 的形式如下:
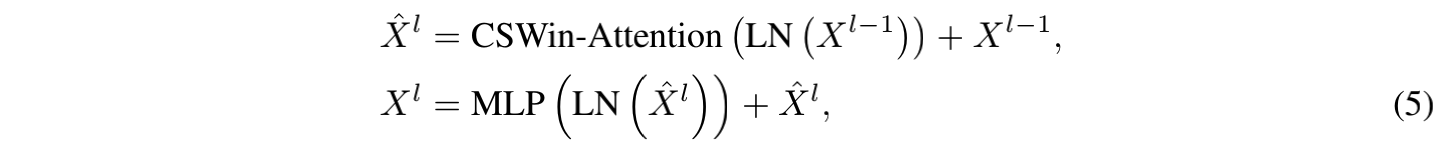
3.4 变体
为了更好的和其他 Transformer baseline 进行对比,作者建立了 CSWin 的不同变体,这些变体的不同在于改变了base channel 的通道数和 transformer block 的个数,如表 1 所示:
- CSWin-T (Tiny)
- CSWin-S (Small)
- CSWin-B (Base)
- CSWin-L (Large)

在所有变体中,每个 MLP 的 expansion ratio 都为4
前三个变体的 4 个stage 的 head 个数都为 2,4,8,16,最后一个变体的 head 数为 6,12,24,48。
四、效果
作者在 ImageNet,COCO,ADE20K上分别做了分类,检测,分割的实验。






相关文章
- Windows下Nginx的启动、停止等命令&Nginx 配置多域名&windows下设置Nginx开机自动启动
- Windows 由于无法验证发布者,windows阻止控件安装怎么办
- [Python] Indexing An Array With Another Array with numpy
- golang程序在windows上,注册为服务
- libEasyPlayer RTSP windows播放器SDK API接口设计说明
- [Python] Indexing An Array With Another Array with numpy
- MFC Windows 程序设计[254]之椭圆形按钮集合(附源码)
- MFC Windows 程序设计[224]之双列表拾取器(附源码)
- How to debug .NET Core RC2 app with Visual Studio Code on Windows?
- open the same code side by side with two splited windows at the same time
- windows server 2008 安装Microsoft ActiveSync 6.1提示缺少一个Windows Mobile设备中心所须要的Windows组件
- 【错误记录】Windows 控制台程序编译报错 ( WINDOWS.H already included. MFC apps must not #include <Windows.h> )
- chromium在windows上的编译 构建 Checking out and Building Chromium for Windows
- MySQL 5.6 for Windows 解压缩版配置安装
- Charles 安装教程,包含MAC和windows
- C# 编写Windows Service(windows服务程序)
- QEMU安装Windows 10的完整过程