
python中request请求库与BeautifulSoup解析库的用法
Python 解析 用法 请求 request BeautifulSoup
2023-09-14 09:14:25 时间
python中request请求库与BeautifulSoup解析库的用法
request
安装
打开cmd窗口,检查python环境,需要python3.7版本及以上
然后输入,下载requests库
pip install requests -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
创建项目
创建python文件,最好不要含有中文字符
测试代码

# 1.导入模块
# 1.导入模块
import requests
# 2. 发送请求,获取响应
response = requests.get("http://www.baidu.com")
print(response) # 这里打印的结果是响应码
# 3. 获取响应数据
# print(response.encoding) # ISO-8859-1
# response.encoding = 'utf-8' # 设置编码格式
# print(response.text)
# 上面两句话等于下面一句话
print(response.content.decode())
运行结果:

小案例(请求疫情首页)
案例代码:
# 1. 导入模块
import requests
# 2. 发送请求,获取响应
response = requests.get("https://ncov.dxy.cn/ncovh5/view/pneumonia")
# 3. 从响应中获取数据
print(response.content.decode())
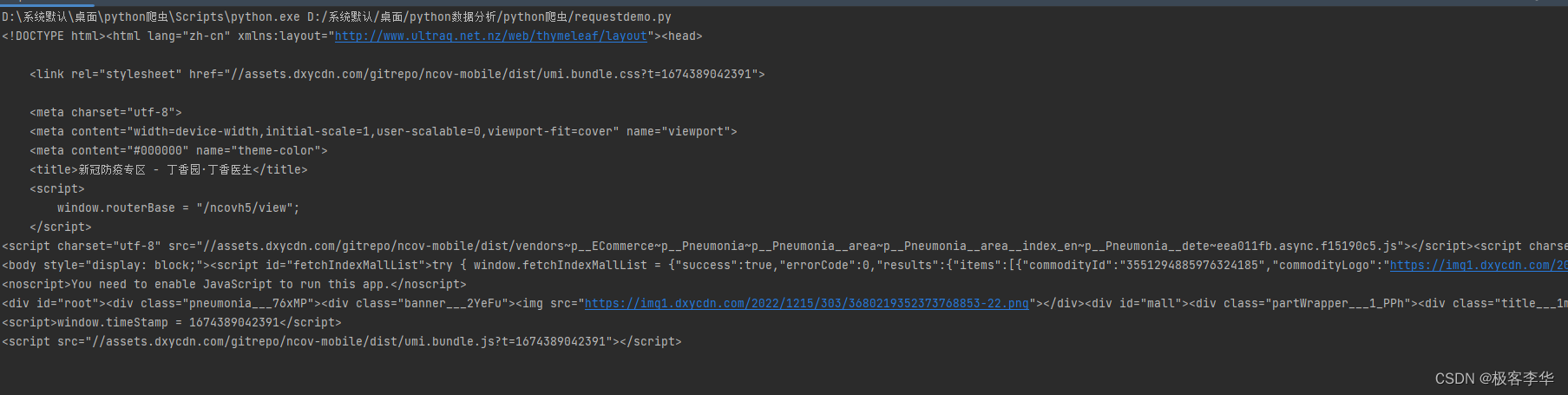
运行结果:
BeautifulSoup
简介

Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
安装
运行下面两行命令,或者pycharm可以自动安装。
pip install bs4
pip install lxml
学习代码
# 1. 导入模块
from bs4 import BeautifulSoup
# 2. 创建BeautifulSoup对象
soup = BeautifulSoup('<html>data</html>', 'lxml')
print(soup)
运行结果
find方法
简介

案例(根据标签名查找)

案例代码:
# 1.导入模块
from bs4 import BeautifulSoup
# 2.准备文本字符串
html = '''
<title>The Dormouse's story</title>
</head>
<body>
<p class="title">
<b>The Dormouse's story</b>
</p>
<p class="story">Once Upon a time three were three little sister;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</body>
</html>
'''
# 3.创建BeautifulSoup对象
soup = BeautifulSoup(html,'lxml')
# 4.查找title标签
title = soup.find('title')
print(title)
# 5.查找a标签
a = soup.find('a')
print(a)
#查找所有a标签
a_s = soup.find_all('a')
print(a_s)
运行结果:

案例(根据属性查找)

案例代码
# 1.导入模块
from bs4 import BeautifulSoup
# 2.准备文本字符串
html = '''
<title>The Dormouse's story</title>
</head>
<body>
<p class="title">
<b>The Dormouse's story</b>
</p>
<p class="story">Once Upon a time three were three little sister;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</body>
</html>
'''
# 3.创建BeautifulSoup对象
soup = BeautifulSoup(html,'lxml')
# 二、根据属性查找
#查找 id 为 link1 的标签
#方法一:通过命名参数进行查找
a = soup.find(id = 'link1')
print(a)
#方法二:使用attrs来指定属性字典,进行查找
a = soup.find(attrs={'id':'link1'})
print(a)
运行结果

案例(根据文本查找)
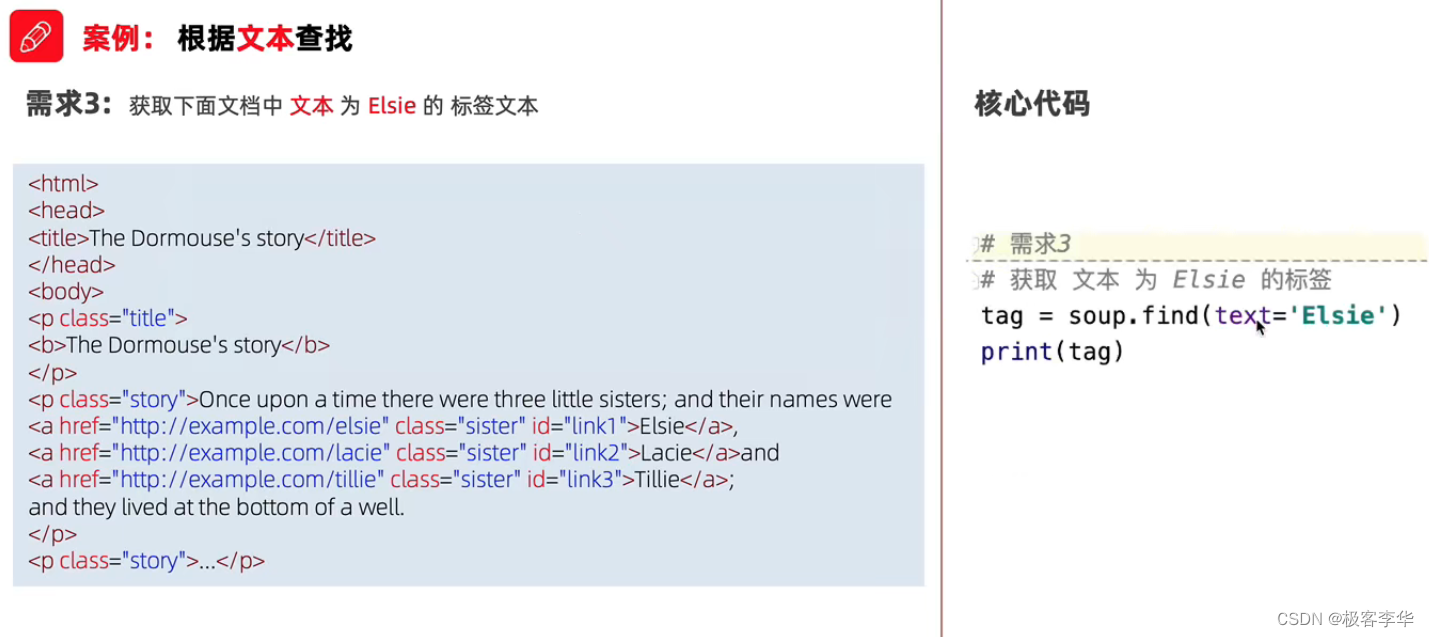
案例代码
# 1.导入模块
from bs4 import BeautifulSoup
# 2.准备文本字符串
html = '''
<title>The Dormouse's story</title>
</head>
<body>
<p class="title">
<b>The Dormouse's story</b>
</p>
<p class="story">Once Upon a time three were three little sister;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</body>
</html>
'''
# 3.创建BeautifulSoup对象
soup = BeautifulSoup(html,'lxml')
#三、根据文本查找
# 获取下面文档中文本为 Elsie 的标签文本
text = soup.find(text='Elsie')
print(text)
运行结果
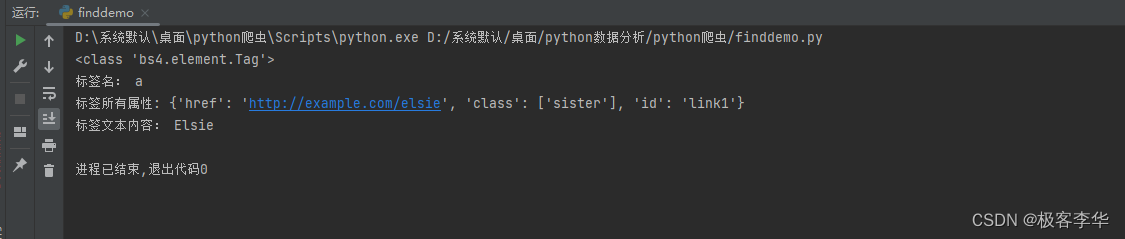
案例(Tag属性使用)

案例代码
# 1.导入模块
from bs4 import BeautifulSoup
# 2.准备文本字符串
html = '''
<title>The Dormouse's story</title>
</head>
<body>
<p class="title">
<b>The Dormouse's story</b>
</p>
<p class="story">Once Upon a time three were three little sister;and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</body>
</html>
'''
# 3.创建BeautifulSoup对象
soup = BeautifulSoup(html,'lxml')
a = soup.find(attrs={'id':'link1'})
#Tag对象
print(type(a)) #<class 'bs4.element.Tag'>
print('标签名:',a.name)
print('标签所有属性:',a.attrs) #输出的class是一个列表,class 一个属性中可以有多个值
print('标签文本内容:',a.text)
运行结果
案例(从疫情首页提取各国最新的疫情数据)
ctrl+f查找某个类型元素的区域,然后,需找到对应标签的id,然后根据id的值来通过find方法获取文本内容。

案例代码:
# 1.导入相关模块
import requests
from bs4 import BeautifulSoup
# 2.发送请求,获取疫情首页内容
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia')
home_page = response.content.decode()
#print(home_page)
# 3.使用 BeautifulSoup 获取疫情数据
soup = BeautifulSoup(home_page, 'lxml')
script = soup.find(id='getAreaStat')
text = script.text
print(text)
运行结果:

相关文章
- python命令行参数解析OptionParser类用法实例
- Python入门教程 超详细1小时学会Python
- 【Python五篇慢慢弹(5)】类的继承案例解析,python相关知识延伸
- Python 进阶(一)函数式编程
- Algorithm:C++/python语言实现之求旋转数组最小值、求零子数组、求最长公共子序列和最长公共子串、求LCS与字符串编辑距离
- Python语言学习:Python语言学习之python包/库package的简介(模块的封装/模块路径搜索/模块导入方法/自定义导入模块实现华氏-摄氏温度转换案例应用)、使用方法、管理工具之详细攻略
- python语言编程:itertools.product的简介、使用方法(求笛卡尔积等)之详细攻略
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- 【python代码】:能在手机上敲 Python 代码几款App
- 〖Python WEB 自动化测试实战篇③〗- python-selenium环境配置搭建
- 〖Python自动化办公篇⑲〗 - python实现邮件自动化 - 邮件发送
- python文件流习题解析
- 【Python成长之路】python并发学习:多进程与多线程的用法及场景介绍
- Python编程:BeautifulSoup和Selector解析网页示例
- Python标准库:内置函数dict(iterable, **kwarg)
- python基础===Python 迭代器模块 itertools 简介
- Python twisted框架使用解析
- aes加密算法python版本
- Python的学习心得和知识总结(五)|Python函数