
【Transformer】18、ACMix:On the Integration of Self-Attention and Convolution
On The and of 18 transformer self ATTENTION
2023-09-14 09:13:56 时间

一、背景和动机
卷积核自注意机制是两个很有效的特征提取方法,但这两个方法通常被认为是两种不同机制的方法。
卷积方法是对局部进行特征抽取,全局特征共享,自注意力方法是全局像素的权重提取。
本文作者认为这两者有很强的底层关系,所以从大范围上来说,这两者的计算机制是类似的。
之前也有一些工作将这两者进行结合,如:
- SENet,CBAM 等则说明了自注意机制可以对卷积网络模型起到帮助。
- SAN,BoTNet 等使用自注意模型来代替卷积操作
- AA-ResNet,Container 等将两者进行了结合,但两个模块分别使用了不同的 path,所以本质上还是分别使用了两种机制。
所以,两者之间的底层联系其实还没有被完全探索
基于此,作者开始了探索两者之间的关系
分解两者之后,作者认为他们都是依赖于 1x1 卷积的,所以作者提出了一个混合模型——ACMix,将两者结合在一起。
二、方法
1、将输入特征使用 1x1 卷积映射为中间特征
2、将该中间特征分别使用自注意和卷积进行处理
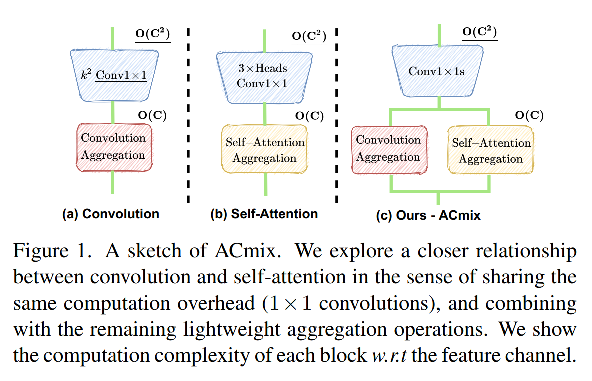
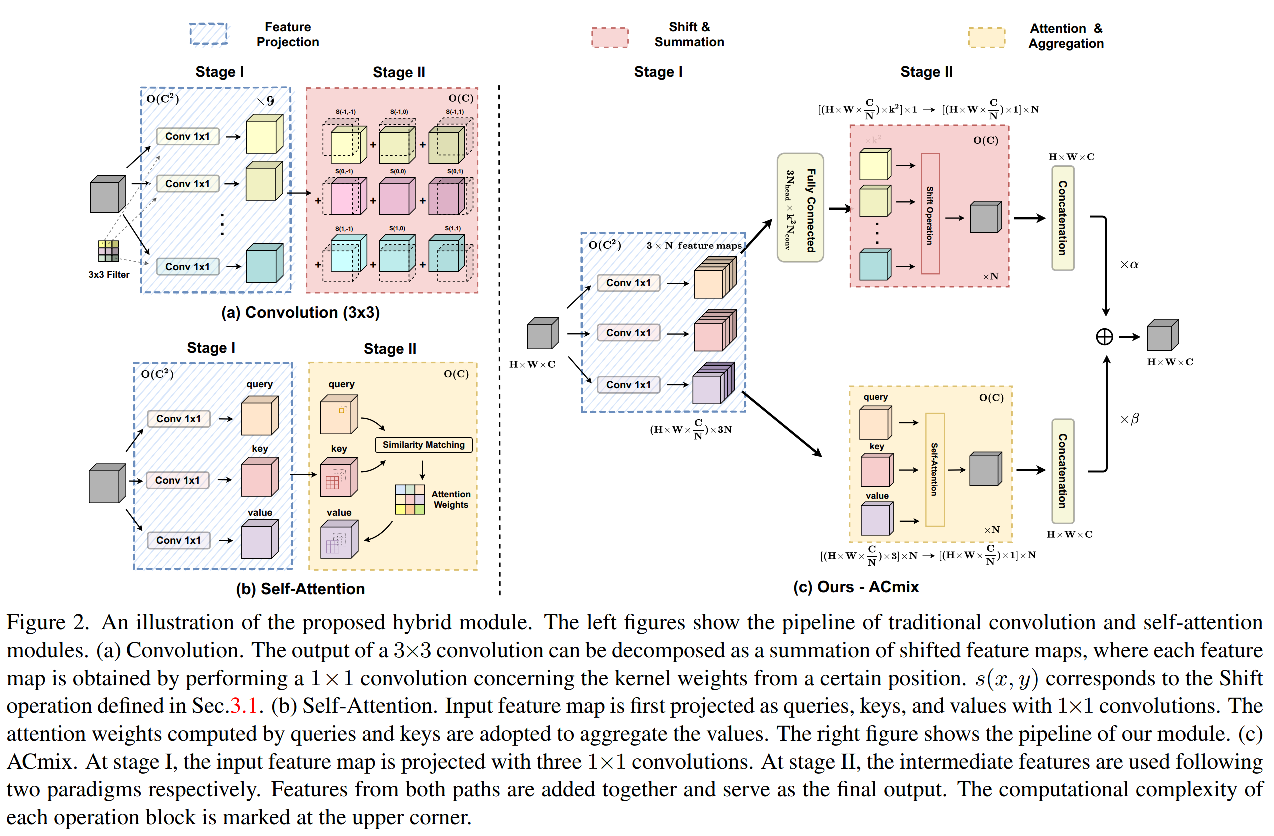
ACMix 的过程如图2c所示:
Stage 1:使用 3 个 1x1 卷积,将输入映射为 3 种不同的特征,并将没种特征切分为 N pieces,此时就得到了 3xN 个中间特征
Stage 2:对 Stage 1 得到的中间特征分别处理
- self-attention path:将中间特征聚合为 N 个组,每个组中包含了 3 个 pieces,每个 pieces 都来自于不同的 1x1 卷积产生的特征。然后将这 3 个 pieces 的特征用作 q、k、v,输入多头自注意模块中。
- convolution path:使用全连接层产生 k 2 k^2 k2 个特征图,然后通过平移和聚合,产生和卷积相同的效果。
最后,使用如下方法聚合两者:
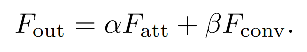
三、效果

相关文章
- HTTP Status 500 - The absolute uri: http://java.sun.com/jsp/jstl/core cannot be resolved in either web.xml or the jar files deployed with this application
- Performs the analysis process on a text and return the tokens breakdown of the text
- [Javascript] Gradient Fills on the HTML5 Canvas
- [RxJS 6] The Catch and Rethrow RxJs Error Handling Strategy and the finalize Operator
- [Angular2 Router] Optional Route Query Parameters - The queryParams Directive and the Query Parameters Observable
- [Angular 2] More on *ngFor, @ContentChildren & QueryList<>
- [RxJS] Reactive Programming - Rendering on the DOM with RxJS
- spark on yarn相关脚本整理20210524
- Unexpected XML declaration. The XML declaration must be the first node in the document and no white
- 如何处理Eclipse错误消息 The declared package does not match the expected package
- 【Codeforces 1083A】The Fair Nut and the Best Path
- 【习题 8-10 UVA - 1614】Hell on the Markets
- Paper:LSTM之父眼中的深度学习十年简史《The 2010s: Our Decade of Deep Learning / Outlook on the 2020s》的解读
- 企业服务的3种模式:On-Premise、SaaS、Mixed,该选哪种?--创业邦
- Maven项目Run As无Run On Server的解决方法
- 魔戒 (The Lord of the Rings,又译《指环王》)
- 论文解读一代GCN《Spectral Networks and Locally Connected Networks on Graphs》
- 问题解决:The connection to the server xxxxx:6443 was refused - did you specify the right host or port?
- 解决办法:错误异常The superclass "javax.servlet.http.HttpServlet" was not found on the Java Build Path
- Codeforces Round #403 (Div. 2, based on Technocup 2017 Finals)
- Install the .NET SDK or the .NET Runtime on Ubuntu
- Linux|错误集锦|prometheus Error on ingesting samples that are too old or are too far into the future的解决
- 深入理解Conditional Diffusion Models:解读《On Conditioning the Input Noise for Controlled Image Generation》