
Spark常见优化原则
一、参数调优:
提交任务参数请参考这篇文章(包括优化建议):Spark部署模式、任务提交 - GoAl
• 第二块:task通过shuffle过程拉取上一个stage的task的输出后,进行聚合等操作时默认也是占Executor总内存的20%,使用Task的执行速度和每个executor进程的CPU Core数量有直接关系,一个CPU Core同一时间只能执行一个线程,每个executor进程上分配到的多个task,都是以task一条线程的方式,多线程并发运行的。如果CPU Core数量比较充足,而且分配到的task数量比较合理,那么可以比较快速和高效地执行完这些task线程
• 第三块:让RDD持久化时使用,默认占executor总内存的60%
二、开发调优
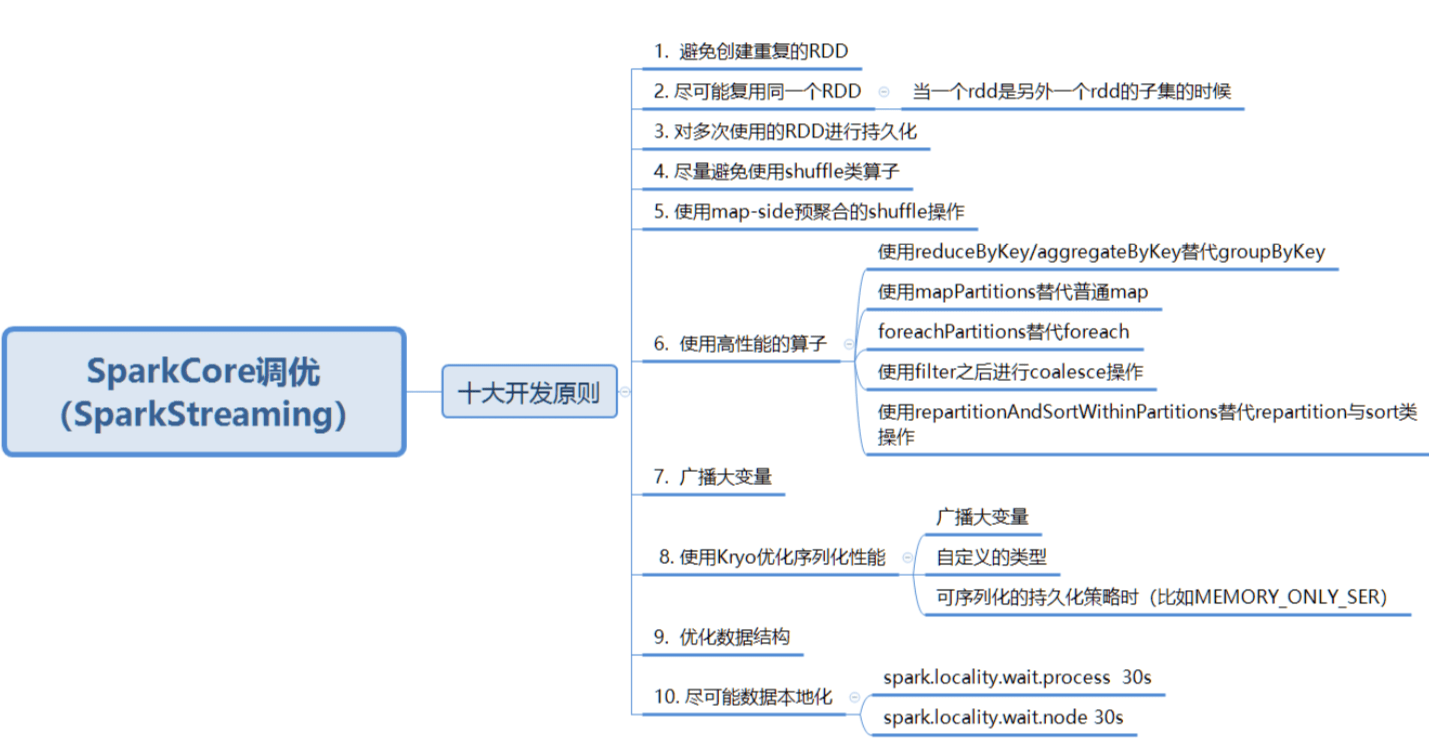
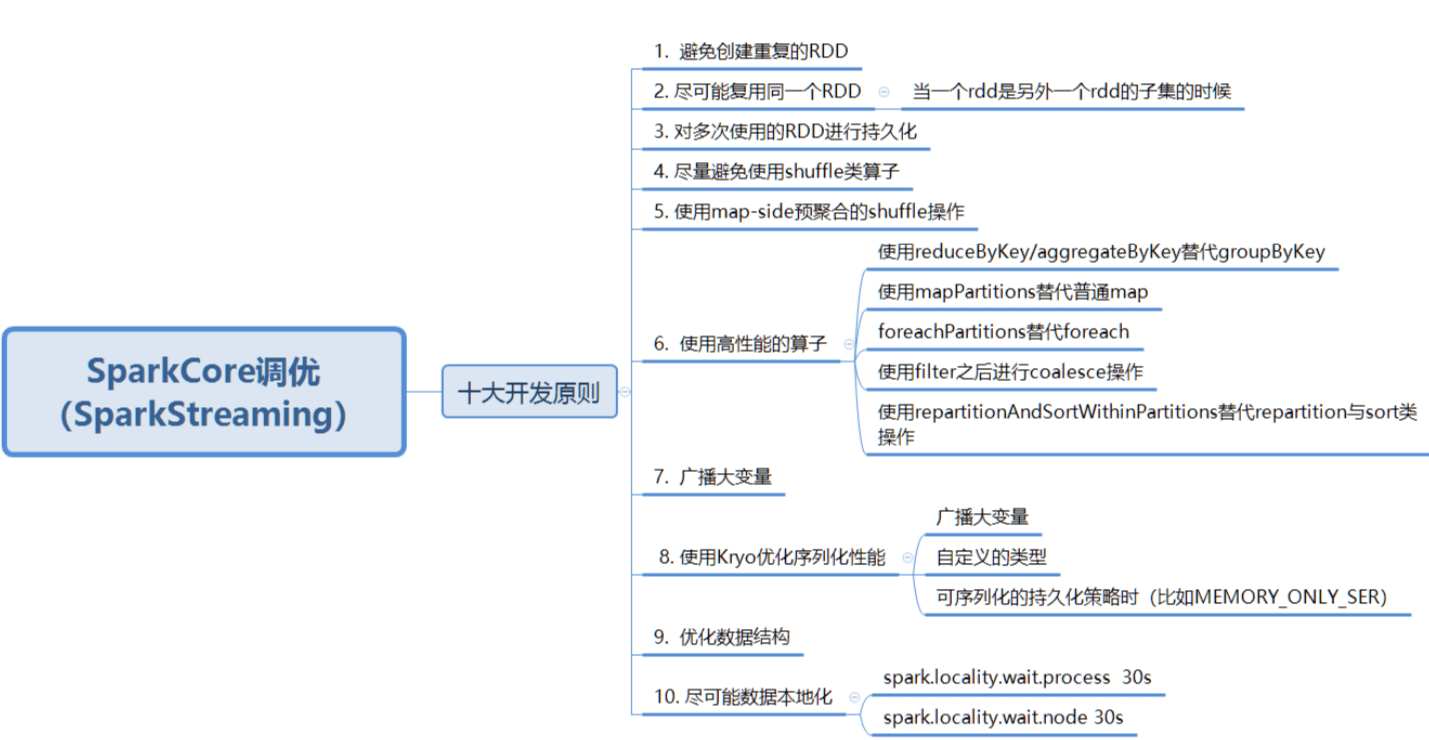
原则一:避免创建重复的RDD
– 对同一份数据,只应该创建一个RDD,不能创建多个RDD来代表同一份数据
– 极大浪费内存


原则二:尽可能复用同一个RDD
– 比如:一个RDD数据格式是key-value,另一个是单独value类型,这两个RDD的value部分完
全一样,这样可以复用达到减少算子执行次数


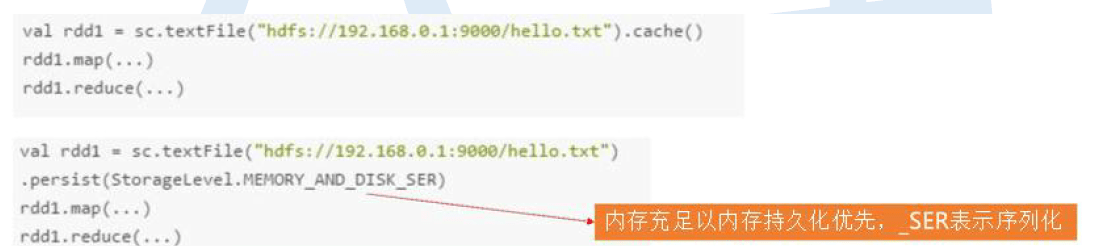
原则三:对多次使用的RDD进行持久化处理
– 每次对一个RDD执行一个算子操作时,都会重新从源头处理计算一遍,计算出那个RDD出来,然后进一步操作,这种方式性能很差
– 对多次使用的RDD进行持久化,将RDD的数据保存在内存或磁盘中,避免重复劳动
– 借助cache()和persist()方法



原则四:避免使用shuffle类算子
– 在spark作业运行过程中,最消耗性能的地方就是shuffle过程
– 将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合和join处理,比如
groupByKey(下图一)、reduceByKey、join(下图二)等算子,都会触发shuffle
![]()


原则五:使用map-side预聚合的shuffle操作
– 一定要使用shuffle的,无法用map类算子替代的,那么尽量使用map-site预聚合的算子
– 思想类似MapReduce中的Combiner
– 可能的情况下使用reduceByKey或aggregateByKey算子替代groupByKey算子,因为
reduceByKey或aggregateByKey算子会使用用户自定义的函数对每个节点本地相同的key进行
预聚合,而groupByKey算子不会预聚合


原则六:使用Kryo优化序列化性能
– Kryo是一个序列化类库,来优化序列化和反序列化性能
– Spark默认使用Java序列化机制(ObjectOutputStream/ ObjectInputStream API)进行序列
化和反序列化
– Spark支持使用Kryo序列化库,性能比Java序列化库高很多,10倍左右


相关文章
- Spark本地模式运行
- hive on spark VS SparkSQL VS hive on tez
- Spark-Join优化之Broadcast
- Spark与Pandas中DataFrame对比
- 大数据基础之Spark(7)spark读取文件split过程(即RDD分区数量)
- 大叔问题定位分享(19)spark task在executors上分布不均
- 大数据基础之Spark(4)RDD原理及代码解析
- Spark Streaming 数据接收优化
- SparkSQL(Spark-1.4.0)实战系列(二)——DataFrames进阶
- Spark性能优化
- Spark on K8S 的最佳实践和需要注意的坑
- 【msb】spark基于yarn的集群搭建、配置、资源调度参数、优化jars
- spark-jobserver介绍: 提供了一个 RESTful 接口来提交和管理 spark 的 jobs、jars 和 job contexts
- Spark CountVectorizer
- Spark 开源新特性:Catalyst 优化流程裁剪
- Spark的Streaming和Spark的SQL简单入门学习
- Presto——本质上是和spark内存计算框架一样 但不负责数据存储
- Spark性能优化指南——高级篇
- spark Bisecting k-means(二分K均值算法)
- Spark性能优化指南——基础篇
- Spark实战(七)spark streaming +kafka(Python版)
- Spark实战(六)spark SQL + hive(Python版)
- Spark实战(四)spark+python快速入门实战小例子(PySpark)
- 【Spark NLP】第 17 章:支持多种语言
- 【Apache Spark 】第 7 章优化和调优 Spark 应用程序
- Spark(2):Spark快速上手