
Python 高级编程之IO模型与协程(四)
文章目录
一、概述
接着上篇文章继续,这篇文章主要讲解IO模型和协程,这两块内容也是非常非常重要的。
Python的I/O模型分为**同步(sync)和异步(async)**两种:
-
同步I/O模型是指,当一个线程在等待I/O操作完成时,它不能执行其他任务,需要一直等待I/O操作完成,直到接收到I/O操作的完成通知后才继续执行。
-
异步I/O模型是指,当一个线程发起一个I/O操作后,不会等待I/O操作完成,而是直接执行其他任务,当I/O操作完成后,再通过回调或事件通知来处理I/O操作的结果。
Python 中的协程:
- 协程是一种轻量级的用户级线程,它在单线程内执行,不会阻塞主线程,可以在多个任务间轻松地切换,因此可以用于实现异步I/O操作。协程的实现方式与生成器非常相似,通过使用
yield语句来暂停和恢复执行。 - 协程可以与
asyncio库配合使用,来实现异步I/O操作。这种方式可以极大地提高程序的效率,因为程序不必等待I/O操作完成,可以在等待I/O操作期间执行其他任务。
二、IO模型
上面已经对IO模型大致描述了一下,其实细分可以分为五种模型:
- 同步阻塞IO(Blocking IO):即传统的IO模型。
- 同步非阻塞IO(Non-blocking IO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。
- IO多路复用(IO MulTIplexing):即经典的Reactor设计模式,有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。
- 异步IO(Asynchronous IO):即经典的Proactor设计模式,也称为异步非阻塞IO。
- signal driven IO:信号驱动IO , 在实际中并不常用,所以只剩下四种IO Model。
1)IO 模型准备
IO模型讲解之前,先了解一些概念:
- 用户空间和内核空间
- 进程切换
- 进程的阻塞
- 文件描述符
- 缓存 I/O
1、用户空间和内核空间
用户空间和内核空间是操作系统的两个重要概念。
-
用户空间是一个独立的内存空间,其中存储着用户进程(包括应用程序)运行时使用的数据和代码。用户空间是安全的,因为进程之间相互独立,不能直接访问对方的内存空间。
-
内核空间是操作系统内核代码和数据结构所使用的内存空间。内核空间是不安全的,因为内核代码运行时有最高的权限,可以访问系统的所有资源,并且可以直接控制其他所有进程。
-
用户空间和内核空间之间的分界线是很重要的,因为它保护了操作系统的安全和稳定。例如,如果一个用户进程的代码出现问题,它可能会崩溃,但是它不会影响整个系统的稳定性。
2、进程切换
进程切换是操作系统的一个基本概念,指的是操作系统在不同的进程之间进行切换,以便实现多任务处理。
进程切换的过程包括如下步骤:
-
保存当前进程的状态:在进程切换前,操作系统需要保存当前进程的执行状态,包括 CPU 寄存器的值、栈的内容等。
-
选择下一个要运行的进程:操作系统根据调度算法选择下一个要运行的进程,例如先来先服务(FCFS)、最短进程优先(SPN)等。
-
载入下一个进程的状态:操作系统从存储器中读取下一个进程的状态,并载入到 CPU 寄存器中。
-
恢复下一个进程的执行:操作系统将 CPU 控制权交给下一个进程,让它继续执行。
进程切换是一个高代价的操作,需要大量的时间和系统资源。因此,操作系统需要合理地调度进程,以最小化进程切换的次数。
3、进程的阻塞
进程阻塞是指一个进程因为等待某个事件的发生而暂时停止执行。这个事件可以是等待 I/O 操作完成、等待资源的分配、等待信号的到达等。当事件发生时,该进程再恢复执行。
-
进程阻塞是一种常见的进程状态,与其他进程状态(例如就绪状态、运行状态)不同。当一个进程阻塞时,它不再需要 CPU 的执行,因此操作系统可以切换到其他进程上,以利用 CPU 资源。
-
进程阻塞可以减少 CPU 的空闲时间,并有助于有效地管理系统资源,但是需要消耗大量的系统资源来维护阻塞队列和状态信息。因此,操作系统需要合理地管理进程阻塞,以保证系统的高效运行。
4、文件描述符fd
文件描述符(file descriptor)是一个非负整数,用于指代一个打开的文件或其他 I/O 设备(例如管道、套接字等)。它为程序提供了一种用于访问文件或 I/O 设备的抽象方法,而不需要知道底层的实现细节。
- 每个进程都有一个文件描述符表,该表包含了每个打开的文件或 I/O 设备的信息。当程序打开一个文件或 I/O 设备时,操作系统会分配一个文件描述符,并将其存储在该进程的文件描述符表中。之后,程序可以使用该文件描述符来读写文件或控制 I/O 设备。
- 文件描述符是系统资源,需要恰当地使用和管理。当一个进程结束时,该进程的所有打开的文件和 I/O 设备都将关闭,相应的文件描述符也将被释放。因此,程序必须确保在不再使用文件描述符时关闭它。
5、缓存 I/O
- 缓存 I/O 指的是使用缓存(即临时存储区)来保存经常访问的数据。在计算机技术中,这可以指的是将数据缓存在系统的内存或存储设备中,或者使用网络中的缓存(如网页浏览器缓存或代理缓存)来减少需要通过网络传输的数据量。
- 缓存可以通过减少执行的 I/O(输入/输出)操作来提高系统的性能,因为数据可以从缓存中快速获取,而不是每次都从原始来源中获取。这可以导致更快的访问时间和减少的延迟,从而提高整体系统性能。
2)IO 模型详解
1、同步阻塞IO(Blocking IO)
Python 中的同步阻塞 I/O 是一种 I/O 操作,在这种情况下,程序的执行会被阻塞,直到 I/O 操作完成。换句话说,程序将等待 I/O 操作完成,才能继续执行下一个任务。这种类型的 I/O 被称为“阻塞”,因为它阻塞了程序的执行,并且被称为“同步”,因为它以同步的方式发生,程序等待 I/O 操作完成后再继续。
-
例如,当使用 Python 中的 read 方法从文件读取时,程序将等待整个文件读取完毕,才能继续执行下一个任务。这是同步阻塞 I/O 的一个例子。
-
当 I/O 操作相对较短且程序可以等待其完成后才继续执行下一个任务时,通常会使用同步阻塞 I/O。然而,当 I/O 操作比较长时,程序可能会被阻塞很长一段时间,从而导致性能下降。在这种情况下,通常更好使用异步 I/O。
-
在
linux中,默认情况下所有的socket都是阻塞IO,一个典型的读操作流程大概是这样:
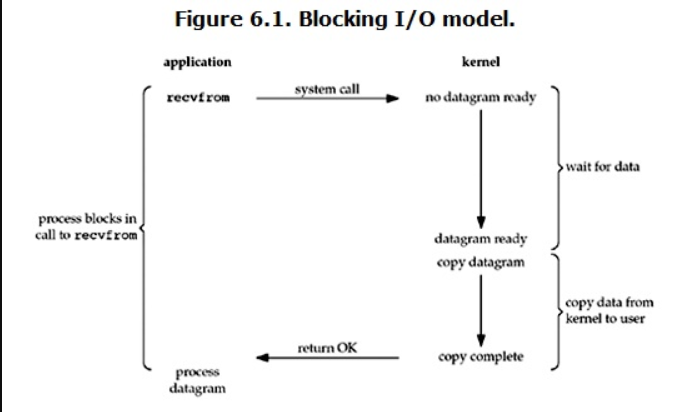
我们之前写的都是阻塞IO模型(协程除外)
在服务端开设多进程或者多线程 进程池线程池 其实还是没有解决IO问题 该等的地方还是得等 没有规避 只不过多个人等待彼此互不干扰。示例如下:
服务端:
import socket
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
conn, addr = server.accept()
while True:
try:
data = conn.recv(1024)
if len(data) == 0:break
print(data)
conn.send(data.upper())
except ConnectionResetError as e:
break
conn.close()
客户端:
import socket
client = socket.socket()
client.connect(('127.0.0.1',8081))
while True:
client.send(b'hello world')
data = client.recv(1024)
print(data)
2、同步非阻塞IO(Non-blocking IO)
Python 中的同步非阻塞 I/O 是一种程序不必等待 I/O 操作完成就可以继续执行下一个任务的 I/O 操作。相反,程序在 I/O 操作正在进行时继续执行下一个任务。这种类型的 I/O 被称为“非阻塞”,因为它不会阻塞程序的执行,并且被称为“同步”,因为它仍以同步的方式操作,程序会定期检查 I/O 操作的状态。
-
例如,在 Python 中实现同步非阻塞 I/O,可以使用 select 模块,该模块提供了对操作系统底层 I/O 多路复用功能的访问,允许您同时监视多个 I/O 操作,而不会阻塞。
-
当 I/O 操作预计需要很长时间才能完成,且程序需要在此期间继续处理其他任务时,通常使用同步非阻塞 I/O。这可以提高程序的性能和响应性。
-
python下,可以通过设置socket使其变为non-blocking(
server.setblocking(False))。当对一个non-blocking socket执行读操作时,流程是这个样子:
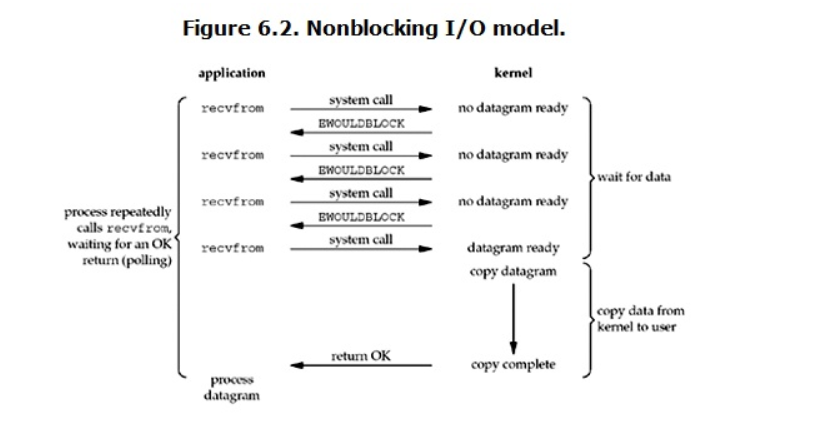
示例如下:
服务端:
import socket
import time
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen(5)
server.setblocking(False)
# 将所有的网络阻塞变为非阻塞
r_list = []
del_list = []
while True:
try:
conn, addr = server.accept()
r_list.append(conn)
except BlockingIOError:
for conn in r_list:
try:
data = conn.recv(1024) # 没有消息 报错
if len(data) == 0: # 客户端断开链接
conn.close() # 关闭conn
# 将无用的conn从r_list删除
del_list.append(conn)
continue
conn.send(data.upper())
except BlockingIOError:
continue
except ConnectionResetError:
conn.close()
del_list.append(conn)
# 挥手无用的链接
for conn in del_list:
r_list.remove(conn)
del_list.clear()
客户端:
import socket
client = socket.socket()
client.connect(('127.0.0.1',8081))
while True:
client.send(b'hello world')
data = client.recv(1024)
print(data)
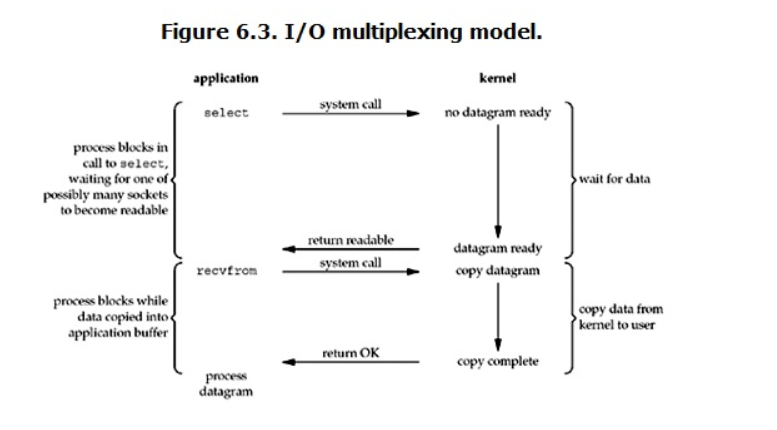
3、IO多路复用(IO MulTIplexing)
“IO 多路复用” 是一种用于监听多个网络连接的技术,以提高网络程序的性能和效率。常用的 IO 多路复用技术有
select、poll、epoll。
在 Python 中,可以使用 select 模块来实现 IO 多路复用。select 模块提供了三个函数:select、poll、epoll,可以在不同的平台上使用不同的函数来实现 IO 多路复用。它们都是用来监听多个文件描述符(socket)的读写情况,以实现对多个socket的高效管理。
-
select:select 是最早的 I/O 多路复用 API 之一,并在大多数 Unix 类系统上广泛支持。select 可以监视大量的文件描述符,但它有许多限制,例如具有固定的最大文件描述符数量(1024),以及当正在监视的文件描述符列表更改时受到竞争条件的影响。 -
poll:poll 是为了解决 select 中的一些限制而引入的,在大多数 Unix 类系统上广泛支持。poll 可以监视比 select 更多的文件描述符(无限制),并且它还提供了关于每个文件描述符状态的更多信息。 -
epoll:epoll 被引入为 poll 和 select 的更有效替代品,并可在 Linux 系统上使用。epoll 具有许多比 poll 和 select 更有效的性能优势,例如更快更可扩展的设计,以及能够以较低开销监视大量文件描述符的能力。
select、poll、epoll之间的区别:
| select | poll | epoll | |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | 回调 |
| 底层实现 | 数组 | 链表 | 哈希表 |
| IO效率 | 每次调用都进行线性遍历,时间复杂度为O(n) | 每次调用都进行线性遍历,时间复杂度为O(n) | 事件通知方式,每当fd就绪,系统注册的回调函数就会被调用,将就绪fd放到rdllist里面。时间复杂度O(1) |
| 最大连接数 | 1024(x86)或 2048(x64) | 无上限 | 无上限 |
| fd拷贝 | 每次调用select,都需要把fd集合从用户态拷贝到内核态 | 每次调用poll,都需要把fd集合从用户态拷贝到内核态 | 调用epoll_ctl时拷贝进内核并保存,之后每次epoll_wait不拷贝 |
它的流程如图:
- 管的对象只有一个的时候 其实IO多路复用连阻塞IO都比不上!!!但是IO多路复用可以一次性监管很多个对象
- 监管机制是操作系统本身就有的 如果你想要用该监管机制(select)需要,
- 你导入对应的select模块
示例如下:
import socket
import select
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
server.setblocking(False)
read_list = [server]
while True:
r_list, w_list, x_list = select.select(read_list, [], [])
"""
帮你监管
一旦有人来了 立刻给你返回对应的监管对象
"""
# print(res) # ([<socket.socket fd=3, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 8080)>], [], [])
# print(server)
# print(r_list)
for i in r_list: #
"""针对不同的对象做不同的处理"""
if i is server:
conn, addr = i.accept()
# 也应该添加到监管的队列中
read_list.append(conn)
else:
res = i.recv(1024)
if len(res) == 0:
i.close()
# 将无效的监管对象 移除
read_list.remove(i)
continue
print(res)
i.send(b'hello python')
# 客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8080))
while True:
client.send(b'hello world')
data = client.recv(1024)
print(data)
4、异步IO(Asynchronous IO)
异步IO模型是所有模型中效率最高的 也是使用最广泛的 。先看一下它的流程:
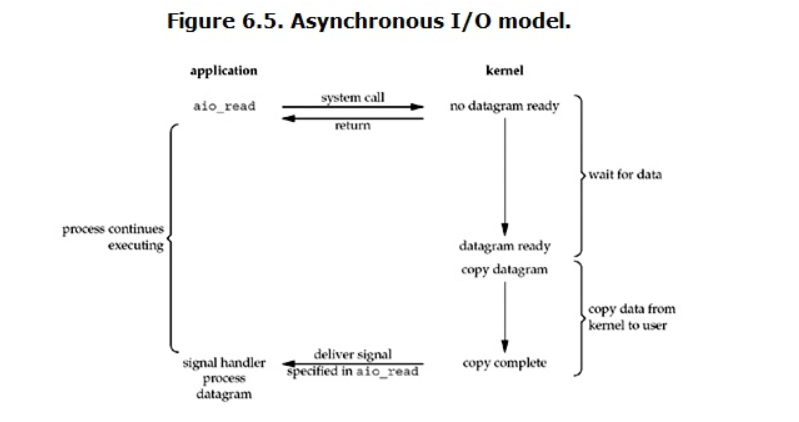
"""
异步IO模型是所有模型中效率最高的 也是使用最广泛的
相关的模块和框架
模块: asyncio模块
异步框架:sanic tronado twisted
速度快!!!
"""
import threading
import asyncio
@asyncio.coroutine
def hello():
print('hello world %s'%threading.current_thread())
yield from asyncio.sleep(1) # 换成真正的IO操作
print('hello world %s' % threading.current_thread())
loop = asyncio.get_event_loop()
tasks = [hello(),hello()]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
三、Python 协程介绍
"协程"是一种在单线程内实现多任务的机制,它的目的是让程序员可以方便地实现异步 I/O 操作,这是通过在单线程中进行切换任务完成的。
-
在 Python 中,协程是通过生成器实现的。它们与普通生成器有所不同,因为它们需要使用
async/await语法以及asyncio库来工作。 -
使用协程可以简化异步编程,因为您可以使用类似同步代码的方式来编写异步代码。它们也可以在单线程中有效地利用 CPU 时间,因为它们可以在没有阻塞的情况下等待 I/O 操作的完成。
-
举个例子,假设您有一个网络服务器,需要同时处理多个客户端请求。使用协程,您可以在单线程中为每个客户端创建一个协程,并在客户端请求完成后从协程中恢复,从而接受其他客户端的请求。
-
总的来说,协程是一种高效且简洁的异步编程方法,为您的 Python 程序提供了更多的并发性和效率。
以下是一个简单的 Python 协程示例代码:
import asyncio
async def coroutine_example():
print("This is a coroutine example")
await asyncio.sleep(1)
print("Coroutine example is done!")
async def main():
task = asyncio.create_task(coroutine_example())
await task
asyncio.run(main())
该代码定义了一个名为 coroutine_example 的协程,该协程打印一条消息,然后使用 asyncio.sleep 函数暂停 1 秒。随后,代码定义了一个名为 main 的函数,该函数创建了一个任务,并使用 await task 等待该任务完成。最后,代码使用 asyncio.run 函数运行 main 函数,并启动协程。
运行该代码后,您将看到以下输出:
This is a coroutine example
Coroutine example is done!
四、进程、线程与协程的关系与区别
进程、线程和协程是操作系统中用来管理程序执行的三种不同的技术。
-
进程:进程是操作系统中最基本的资源分配单元,是程序的实体。它是系统进行资源分配和调度的独立单位。每个进程都有独立的内存空间,因此在一个进程中出现故障不会影响其他进程。
-
线程:线程是进程的一个执行单元,是操作系统分配资源的最小单元。多线程可以共享进程的资源,因此线程间的通信和协作比进程间更加方便。不幸的是,线程之间存在竞争关系,并且当一个线程出现故障时,整个进程都会受到影响。
-
协程:协程是一种在单线程中执行多任务的机制,是线程的一种特殊形式。它不同于多线程,因为它不会独立分配资源,而是在一个线程中共享资源。因此,协程的实现比线程更加轻量,可以提高程序的效率。不过,协程的实现也比线程更加复杂,因为需要编写更多的代码来协调任务的。
这里只是简单的讲了一下协程的一些概念和简单示例,下篇文章会重点讲解使用生成器实现协程,IO模型和协程是python非常重要的两个知识点,也是提升python代码执行效率的最有校方法和思路。小伙伴可以关注我的公众号【大数据与原生技术分享】进行深入技术交流~
相关文章
- Python 编程 | 连载 02 - 数字与字符串
- python类的初始化方法_python初始化列表
- python编程是什么-Python编程
- Python入门系列(三)基础数据类型
- Python入门系列(十)一篇学会python文件处理
- Python&R语言-python和r相遇
- python udp编程_Python核心编程
- [1169]python编程WSGI服务器wsgiref模块
- pytest测试框架和unittest_python列表生成式
- python做微信回复机器人_Python自动化脚本
- Python 进阶指南(编程轻松进阶):五、发现代码异味
- python-异步IO编程
- python-异步IO编程-异步HTTP请求的实现
- python-异步IO编程-异步文件读写的实现
- Python的socket编程详解编程语言
- Python 的socke编程示例详解编程语言
- Linux下安装Python的指南(linux下安装python)
- 使用Python编程连接MySQL数据库(python连mysql)
- 掌握Linux环境下的Python编程(linux执行python)
- 少有人知的 Python “重试机制”
- 使用Python连接SQL Server数据库(python连接sqlserver)
- 用Python仿写MSSQL 编程体验更有趣(python仿mssql)
- Python编程连接MySQL:从零开始(python与mysql)
- 零基础写python爬虫之使用urllib2组件抓取网页内容