
统计基础篇之十二:怎么理解正态分布(一)
2023-09-14 09:12:34 时间
引用:https://zhuanlan.zhihu.com/p/24732117
一般正态分布的概率密度函数为:
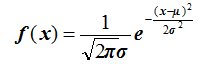
其中:μ、σ分别为均值和标准差
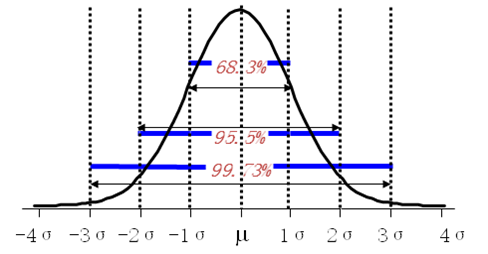
正态分布中,±1σ、±2σ、±3σ下的概率分别是68.3%、95.5%、99.73%,这3个数最好记住。
均值决定曲线的位置,标准差决定曲线的胖瘦。可以比较以下几种情况来理解正态分布。
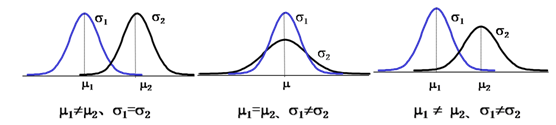
正态分布在实践中成功地被广泛应用,主要是因为正态分布在数学方面具有多种稳定性质,这些性质包括:
1.两个正态分布密度的乘积还是正态分布
2.两个正态分布密度的卷积还是正态分布,也就是两个正态分布的和还是正态分布
3.正态分布N(0,σ^2)的傅里叶变换还是正态分布
4.中心极限定理保证了多个随机变量的求和效应将导致正态分布
5.正态分布和其它分布具有相同方差的概率分布相比,具有最大熵
前上性质说明了正态分布一旦形成,就容易保持该形态的稳定。后两个性质则说你们,其它的概率分布在各种操作之下容易越来越靠近正态分布。
正是由于正态分布多种的稳定性质,使得它像一个黑洞一样处于一个中心的位置,其它概率分布形式在各种操作之下都逐渐向正态分布靠拢。
相关文章
- 机器学习笔记,统计模型觉得难,不妨来看点概念吧
- 5个时间序列预测的深度学习模型对比总结:从模拟统计模型到可以预训练的无监督模型(附代码)
- Excel函数与VBA多条件统计不重复出现的次数
- Power Query分组统计总人数合格人数优秀人数特优人数合计平均最高最低
- PostgreSQL 数据库基础 动态统计某一列的某一值出现的次数SQL
- 输入一行字符,分别统计出其中英文字母、空格、数字和其它字符的个数详解编程语言
- Linux文件数量统计(linux文件数目)
- 记录MySQL统计不重复记录的完美方案(mysql统计不重复)
- 用MSSQL技术进行每月统计分析(mssql 每月统计)
- 深入探究Oracle内存统计信息(oracle内存统计信息)
- Oracle中统计人口数量的技巧(oracle中统计人数)
- Redis实现访问统计简单有效的实践方法(redis 访问统计)