
Hive数仓基本概念介绍

select
word, count(*) AS cnt
from
(select
explode(split(sentence,' ')) word
from badou.article_as
) t
group by word
UDF,UDAF,UDTF
UDF: 直接应用于select语句,常见的大小写转换,就是一个一对一关系,一进一出
tmp_a tmp_b
数据调研:user_id(大小写) user_id(大小写)
select a.user_id
from tmp_a a
inner join tmp_b b
on lower( cast (a.user_id as string) )=lower( cast(b.user_id as string) )
limit 1000 => 不能得到结果
select from tmp_a
select from tmp_b
UDAF:多对一的情况,常见于wordcount, group by阶段
UDTF:一对多的情况
读时模式和写时模式 json: {key:value,key1:value1,key3:value....}
读时模式:只有hive读取的时候才会检查,字段的解析和schema(数据结构的表达)
优点:加载数据非常迅速,在写得过程中不需要解析数据
写时模式:优点:读取数据的时候得到优化
缺点:写得慢,建立索引,压缩,数据一致性,字段检查等等
sql场景:实时查询的业务(粗粒度)设计hive场景:进行数据挖掘 或者是数据仓库涉及
hive数据类型
针对存储资源而言:
数值类型:枚举值 0,1 表示男 女 tinyint, int, integer,bigint(长整型)
浮点类型:float,double ,decimal(涉及到金额,保证精度不丢失)
时间类型:timestamp ,date (字段命名时:timestamp, 一般不建议使用关键字作为字段名称)
字符串类型: string(工作中常见)
复杂类型:maps, structs,union (常见于前端埋点的流量日志)
其他类型:boolean
hive四种数据模型: 内部表,外部表,分区表,桶Hive 内部表和外部表
CREATE TABLE article_as(sentence string)
load data local inpath '/usr/local/src/badou_code/mr/mr_wc/The_Man_of_Property.txt' overwrite into table article_as;
Hive 内部表和外部表区别?:
(1)是否直接通过external
(2)删除外部表,元数据得到删除,但是数据不会真正删除,针对内部表,元数据和数据都被删除
(3)在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而内部表则不一样
内部表和外部表场景:
内部表:逻辑处理的中间过程生成的中间表,或者一些临时表,直接删除即可
外部表:可以用户存储一些日志信息,数据不会被删除
hive建表1.直接建表法
create table movies (uid string,iid string,score string , ts string)
ROW FORMAT DELIMITED FIELDS
TERMINATED BY '\t' LINES TERMINATED BY '\n'
场景:直接进行 字段类型,字段备注,数据存储格式的自定义
2.抽取(as)建表
create table article_as as select * from article;
场景:中间逻辑处理的时候,进行建表,直接复制表的数据和结构
3.like建表
create table article_like like article ;
场景:只关注表结构,不需要数据
12、Hive 表执行顺序
13、分区
100亿条数据
select * from orders where order_id='1010100'
分区作用:减少查询的数据量,提高查询效率
业界常用: d 或者 dt 字段 表示分区, 一般讲今天作为T,分区数据一般是T-1
建表过程:
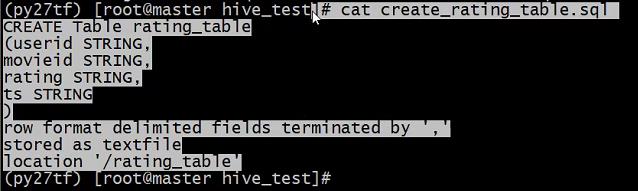
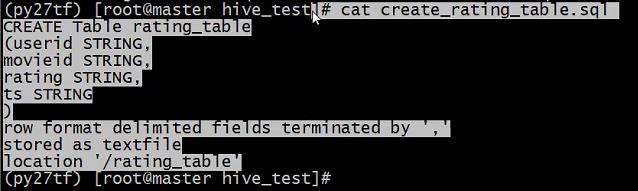
CREATE TABLE udata_partition(user_id string,item_id string,rating int)
PARTITIONED BY (dt string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
-- 查看表结构
show create table udata_partition ;
desc udata_partition ;-- 查看分区表分区
show partitions udata_partition ;
Hive 静态分区和动态分区
1.静态分区:每个分区写一个load data,缺点:load data 效率低下,非常繁琐
insert overwrite table udata_partition partition (dt='2020-12-19')
select user_id, item_id, rating from udata where user_id='305'
insert overwrite table udata_partition partition (dt='2020-12-18')
select user_id, item_id, rating from udata where user_id='298'
select count(*) cnt
from udata_partition
where dt='2020-12-19'
select count(*) from udata where user_id='305'
应用场景:数据量不大,同时要知道分区的数据类型
2.动态分区:
注意:以下设置,只在当前的会话窗口有效
1.打开动态分区模式:
set hive.exec.dynamic.partition=true;
2.设置分区模式为非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table udata_partition partition (dt)
select
user_id, item_id, rating
, to_date(from_unixtime(cast(timestamp as bigint), 'yyyy-MM-dd HH:mm:ss')) as res
from udata
where user_id='244';
应用场景:不确定分区数量,数据量也不是很大,使用动态分区
实际工作中趋向于使用动态分区!!!
时间段进行分区: 针对前端日志埋点,我们会采取小时段作为分区
dt='2020-12-19'/hour='01'
dt='2020-12-19'/hour='02'
......
3.分桶:
作用:进一步缩小查询范围,提高查询效率
分桶计算: hive 计算桶列的hash值再除以桶的个数取模,得到某条记录到底属于哪个桶
定义桶数: 3个 0 1 2
user_id order_id gender
196 12010200 1
186 19201000 0
22 12891999 1
244 19192908 0
196%3 = 1
186%3 = 0
22%3 = 1
Hive 分桶应用场景
(1)数据抽样
(2)map-side join : 如果join的两列,都有有分桶,是不是关联获取十分快速
(3)数据倾斜
参数设置: set hive.enforce.bucketing = true;
得到bucket的个数和reduce个数是一致的
number of mappers: 1; number of reducers: 4
create table badou.bucket_user (
id int
)
clustered by (id) into 4 buckets;
数据导入:
insert overwrite table badou.bucket_user select cast(user_id as int) from udata;
hadoop fs -ls /user/hive/warehouse/badou.db/bucket_user 得到4个文件
select * from bucket_user tablesample(bucket 1 out of 16 on id) limit 10;
-- 抽样 抽取的数据量差不多是1/16
select count(*) from bucket_user tablesample(bucket 1 out of 16 on id) limit 10;
5742
总结: 什么时候使用分区? 什么时候使用分桶?
数据量比较大,为了快速查询使用分区
更加细粒度的查询,数据抽样,数据倾斜使用分桶
如何快速知道表的特性?
a.show create table table_name; 直接看是否是分区表,内外部表,分桶
b.desc table_name;
show partitions table_name; 分区的枚举值,帮我妈快速定位问题
经验:如何快速知道订单号时候重复?
方式一:
select
count(*) cnt, count(distinct order_id) order_cnt
from orders
结果:
cnt order_cnt
3421083 3421083
方式二:
select
order_id, count(distinct order_id) order_cnt
from orders
group by order_id
having order_cnt > 1
方式三:
select *
from
(select
order_id, count(distinct order_id) order_cnt
from orders
group by order_id
) t
where order_cnt > 1如何判断数据是增量分区, 还是全量分区 (保存数据是T-1的全量, 通常保存近一个月的数据为T-1的全量)
增量形式: 不包含历史所有的数据,只是当天的数据 where dt between 'T-7' and 'T-1'
2020-12-19 1000000
2020-12-18 1200000
2020-12-17 1009000
全量形式: where dt='T-1' 多表关联
2020-12-19 1000000
2020-12-18 9900000
2020-12-17 9800000
......
工作中常用 全量分区:进一步可以保证数据不丢失,业内 7天全量分区30天全量分区
相关文章
- C# List用法 List 实列介绍
- Hive修改字段类型_hive表添加字段sql
- hive etl 通过 ETL engine 读取 Hive 中的数据
- 人工智能:图像数字化相关的知识介绍
- hive介绍详解大数据
- 从Oracle到Hive:数据导入指南(oracle导入hive)
- 一周 GNOME 之旅:品味它和 KDE 的是是非非(第一节 介绍)
- Hive安装MySQL:权限控制的改变(hive安装mysql)
- 比较Hive与MySQL的区别与联系(hive与mysql)
- 使用Linux访问Hive:简单易懂的指南(linux访问hive)
- 使用Hive将数据导入MySQL(hive数据导入mysql)
- MySQL中如何保证事务的安全性简单介绍事务表的作用和原理(mysql中事务安全表)
- MySQL表格字段相乘的操作简要介绍(mysql两表字段相乘)
- Hive转换Oracle平台构建可靠数据迁移方案(hive转换oracle)
- 使用Hive访问Oracle,数据科学可以更加轻松(hive访问Oracle)
- Hive表数据迁移至Oracle(hive表转oracle)
- Hive表数据导入到Oracle中的实现(hive表写oracle)
- Hive与Oracle数据库的对接之路(hive对接oracle)
- 使用Hive实现Oracle数据同步(hive同步oracle)
- 从Hive到Oracle的数据库迁移(hive-oracle)
- Redis教程快速入门指南(教程redis介绍)
- Hive的数据存储与管理MySQL与Hive结合的最佳实践(mysql下hive)
- php适配器模式介绍
- OracleTableDemo语句应用介绍
- C#线程池用法详细介绍
- Thinkphp中import的几个用法详细介绍
- js模式窗口(模式对话框和非模式对话框)的使用介绍
- freetds简介、安装、配置及使用介绍