
HLS介绍 - 01 - FPGA的架构、结构以及硬件设计相关概念
写在前面
学习HLS,首先要了解关于软件和硬件的区别,本文参考是xilinx官方手册UG998的第二章和第三章,主要介绍了FPGA的架构、FPGA的并行结构,以及HLS需要知道的相关硬件概念。
FPGA架构
FPGA 的基本结构由以下元素组成:
-
查找表 (LUT):该元素执行逻辑运算。
-
触发器(FF):该寄存器元素存储LUT 的结果。
-
电线(wire):这些元素将元素相互连接。
-
输入/输出(I/O) :这些物理上可用的端口将数据输入和输出FPGA。
这些元素的组合产生了的基本 FPGA 架构。
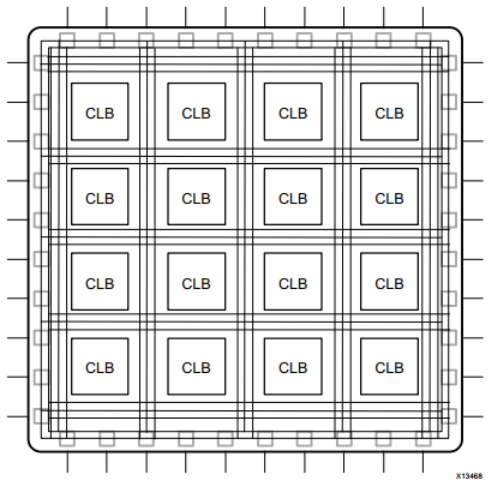
尽管这种结构对于任何算法的实现来说都足够了,但最终实现的效率在计算吞吐量、所需资源和可实现的时钟频率方面受到限制。
现代 FPGA 架构将基本元素与额外的计算和数据存储块结合在一起,从而提高了设备的计算密度和效率。
- 用于分布式数据存储的嵌入式存储器
- 用于以不同时钟速率驱动 FPGA 架构的锁相环 (PLL)
- 高速串行收发器
- 片外存储器控制器
- 乘法累加模块
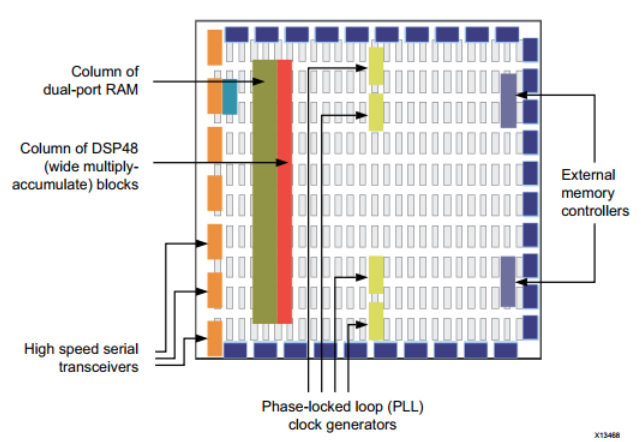
这些元素的组合为 FPGA 提供了实现处理器上运行的任何软件算法的灵活性。
LUT
LUT 是 FPGA 的基本构建块,能够实现 N 个布尔变量的任何逻辑功能。 本质上,这个元素是一个真值表,其中不同的输入组合实现不同的功能以产生输出值。 真值表的大小限制为 N,其中 N 表示 LUT 的输入数量。 对于一般的 N 输入 LUT,访问的内存位置数为:
2
N
2^N
2N
它允许查找表实现以下功能:
2
N
N
2^{N^N}
2NN
在FPGA中LUT的N值一般为6,也就是6输入查找表。
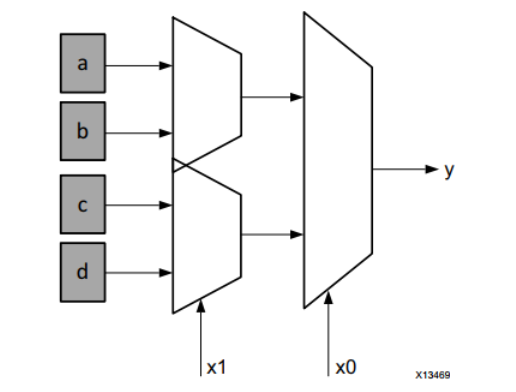
LUT 的硬件实现可以被认为是连接到一组多路复用器的一组存储单元。 LUT 的输入充当多路复用器上的选择器位,以选择给定分支点的结果。这种表示很重要,因为 LUT 既可以用作函数计算引擎,也可以用作数据存储元素。 下图展示了作为存储单元集合的 LUT 的功能表示。
Flip-Flop
触发器是 FPGA 架构中的基本存储单元。 该元素始终与 LUT 配对,以协助逻辑流水线和数据存储。 触发器的基本结构包括数据输入、时钟输入、时钟使能、复位和数据输出。 在正常操作期间,数据输入端口的任何值都被锁存并在时钟的每个脉冲上传递到输出。 时钟使能引脚的目的是允许触发器为多个时钟脉冲保持特定值。 只有当时钟和时钟使能都等于 1 时,新数据输入才会被锁存并传递到数据输出端口。
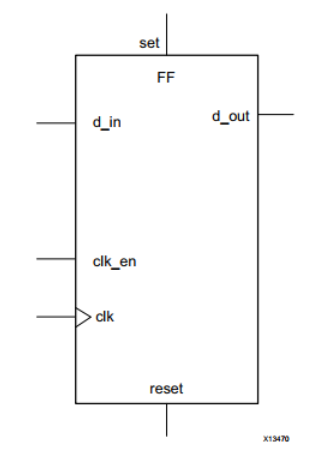
触发器的结构如上图所示。
DSP Block
Xilinx FPGA 中可用的最复杂的计算模块是 DSP 模块。
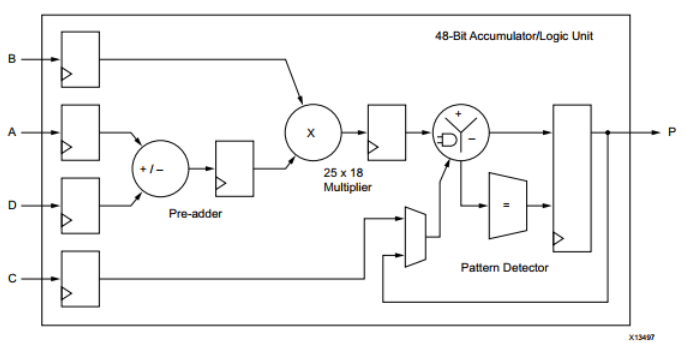
DSP 块是嵌入到 FPGA 结构中的算术逻辑单元 (ALU),它由三个不同块的链组成。 DSP 中的计算链由连接到乘法器的加/减单元组成,乘法器连接到最终的加/减/累加引擎。 该链允许单个 DSP 单元实现以下形式的功能:
p
=
a
×
(
b
+
d
)
+
c
p =a×(b+d)+ c
p=a×(b+d)+c
或者
p
+
=
a
×
(
b
+
d
)
p+=a×(b+d)
p+=a×(b+d)
Storage Elements
FPGA设备包括可用作随机存取存储器(RAM)、只读存储器(ROM)或移位寄存器的嵌入式存储器元件。这些元件是块RAM(BRAM)、超RAM块(URAM)、LUT和移位寄存器(SRL)。
BRAM是一个双端口RAM模块,实例化到FPGA结构中,为相对较大的数据集提供片上存储。设备中可用的两种类型的BRAM存储器可以容纳18K或36K位。这些可用存储器的数量是特定于设备的。这些存储器的双端口特性允许对不同位置进行并行、相同的时钟周期访问。
就数组在C/C++代码中的表示方式而言,BRAM可以实现RAM或ROM。唯一的区别是数据写入存储元素的时间。在RAM配置时,可以在电路运行期间的任何时间读取和写入数据。相反,在ROM配置中,只能在电路运行时读取数据。ROM的数据作为FPGA配置的一部分写入,不能以任何方式修改。
UltraRAM块是双端口、同步288 Kb RAM,具有4096位深和72位宽的固定配置。它们可在UltraScale+设备上使用,提供的存储容量是BRAM的8倍。
LUT是在设备配置期间写入真值表内容的小型存储器。由于Xilinx FPGA中LUT结构的灵活性,这些块可用作64位存储器,通常称为分布式存储器(distributed memories) 。这是FPGA设备上可用的最快的内存类型,因为它可以在结构的任何部分实例化,从而提高所实现电路的性能。
移位寄存器是相互连接的寄存器链。此结构的目的是提供沿计算路径的数据重用,例如使用过滤器。基本滤波器由一系列乘法器组成,这些乘法器将数据样本与一组系数相乘。通过使用移位寄存器存储输入数据,内置数据传输结构在每个时钟周期将数据样本移动到链中的下一个乘法器。下图显示了移位寄存器的示例。

FPGA并行性与处理器体系结构
在处理器上执行程序
无论什么类型的处理器,都以指令序列的形式执行程序,并将其转换为软件应用程序的有用计算。此指令序列由处理器编译器工具生成,如GNU编译器集合(GCC),它将以C/C++表示的算法转换为处理器本机的汇编语言结构。
这也就,即使是一个简单的操作,例如a+b的操作,也会产生多个汇编指令。每个指令的计算延迟在不同的指令类型中并不相等。例如,根据a和b的位置,LD操作需要不同数量的时钟周期来完成。如果这些值在处理器缓存中,这些加载操作将在几十个时钟周期内完成。
如果这些值位于主双数据速率(DDR)内存中,则操作需要数百到数千个时钟周期才能完成。如果这些值位于硬盘驱动器中,则加载操作需要更长的时间才能完成。这就是为什么具有缓存命中跟踪的软件工程师花费大量时间重新构造算法,以增加内存中数据的空间局部性,从而提高缓存命中率并减少每条指令花费的处理器时间。
FPGA上执行程序
FPGA是一种固有的并行处理结构,能够实现可在处理器上运行的任何逻辑和算术功能。主要区别在于用于将软件描述转换为RTL的Vivado HLS编译器不受缓存和统一内存空间的限制。
例如计算a+b=z,z 的计算由 Vivado HLS 编译成几个 LUT,以实现输出操作数的大小。 例如,假设在原始软件程序中,变量 a、b 和 z 是用短数据类型定义的。 这种定义了 16 位数据容器的类型由 Vivado HLS 实现为 16 个 LUT。用于计算z的LUT仅能进行进行计算z的功能实现。与所有计算共享同一ALU的处理器不同,FPGA实现为软件算法中的每个计算实例化独立的LUT集。
除了为每次计算分配唯一的LUT资源外,FPGA在内存结构和内存访问成本方面与处理器不同。在FPGA实现中,Vivado HLS编译器将内存安排到尽可能靠近操作中使用点的多个存储库中。这会产生瞬时内存带宽,远远超过处理器的能力。例如,Xilinx Kintex®-7 410T设备总共有1590个18 k位BRAM可用。在内存带宽方面,该设备的内存布局为软件工程师提供了寄存器级每秒0.5M位和BRAM级每秒23T位的容量。
关于计算吞吐量和内存带宽,Vivado HLS编译器通过调度、流水线和数据流过程来实现FPGA结构的功能。虽然对用户透明,但这些过程是软件编译过程中不可或缺的阶段,可以提取软件应用程序的最佳电路级实现。
Scheduling
调度是识别不同操作之间的数据和控制依赖关系的过程,以确定每个操作何时执行。在传统的FPGA设计中,这是一个手动过程,也称为硬件实现的软件算法并行化。
Vivado HLS分析相邻操作之间以及跨时间的依赖关系。这允许编译器将操作分组以在同一时钟周期内执行,并设置硬件以允许函数调用重叠。函数调用执行的重叠消除了处理器限制,处理器限制要求当前函数调用在同一组操作的下一个函数调用开始之前完全完成。这一过程称为流水线。
Pipelining
流水线是一种数字设计技术,它允许设计者在算法硬件实现中避免数据依赖并提高并行度。原始软件实现中的数据依赖性保留为功能等效,但所需的电路被划分为一系列独立的级。链中的所有级在相同的时钟周期上并行运行。唯一的区别是每个阶段的数据来源。计算中的每一级从前一级在前一时钟周期内计算的结果接收其数据值。例如,为了计算以下函数,Vivado HLS编译器实例化一个乘法器和两个加法器块:
y
=
(
a
×
x
)
+
b
+
c
y = (a ×x) + b+ c
y=(a×x)+b+c
下图显示了这种计算结构的无流水线和有流水线的效果。
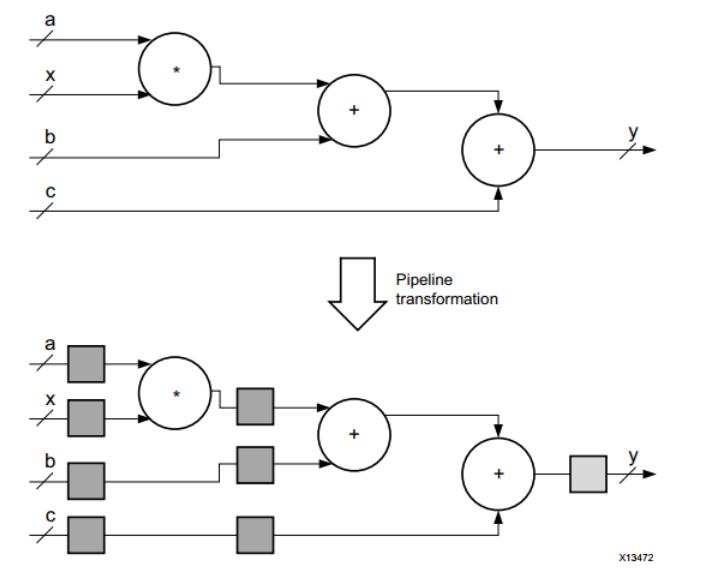
它显示了示例函数的两个实现。顶层实现是计算结果y所需的数据路径,无需流水线。此实现的行为类似于相应的C/C++函数,因为在计算开始时必须知道所有输入值,并且一次只能计算一个结果y。底部实现显示了同一电路的流水线版本。
数据路径中的方框表示由FPGA结构中的触发器块实现的寄存器。每个方框都可以算作一个时钟周期。因此,在流水线版本中,每个结果y的计算需要三个时钟周期。通过添加寄存器,每个块在时间上被隔离为单独的计算部分。这意味着带有乘法器的部分和带有两个加法器的部分可以并行运行,并减少函数的总体计算延迟。
Dataflow
数据流是另一种数字设计技术,在概念上类似于流水线。数据流的目标是在粗粒度级别上表示并行性。就软件执行而言,这种转换适用于单个程序中函数的并行执行。
Vivado HLS通过基于输入和输出评估程序不同功能之间的交互来提取这种级别的并行性。最简单的并行情况是函数在不同的数据集上工作并且彼此不通信。在这种情况下,Vivado HLS为每个函数分配FPGA逻辑资源,然后独立地运行模块。更复杂的情况是,一个函数为另一个函数提供结果,这是软件程序中的典型情况。这种情况称为消费者-生产者情景。
Vivado HLS支持消费者-生产者场景的两种使用模型。
在第一个使用模型中,生产者在消费者开始操作之前创建一个完整的数据集。并行性是通过实例化一对排列为内存库ping和pong的BRAM内存来实现的。在函数调用期间,每个函数只能访问一个内存库(ping或pong)。当新的函数调用开始时,HLS生成的电路切换生产者和消费者的内存连接。这种方法保证了函数的正确性,但限制了跨函数调用的可实现并行性水平。
在第二个使用模型中,使用者可以开始使用生产者的部分结果,并且可实现的并行级别被扩展到包括函数调用中的执行。Vivado HLS为这两个功能生成的模块通过使用先进先出(FIFO)内存电路连接。该存储器电路在软件编程中充当队列,提供模块之间的数据级同步。
在函数调用期间的任何时候,两个硬件模块都在执行其编程。唯一的例外是消费者模块在开始计算之前等待生产者提供一些数据。在Vivado HLS术语中,用户模块的等待时间称为间隔或启动间隔(II)。
硬件设计的基本概念
处理器和FPGA之间的关键区别之一是处理架构是否固定。这种差异直接影响每个目标的编译器的工作方式。性能是应用程序映射到处理器功能的程度以及正确执行所需的处理器指令数的函数。
相比之下,FPGA类似于一块有一盒构建块的白板。HLS编译器的工作是从最适合软件程序的构建块盒中创建处理架构。指导Vivado HLS编译器创建最佳处理体系结构的过程需要硬件设计概念的基础知识。
时钟频率
处理器时钟频率是确定特定算法的执行平台时要考虑的第一项之一。一个常用的准则是,高时钟频率转换为算法的更高性能执行率。
延迟和流水线
延迟和流水线是HLS中的重要概念,延迟表示执行完成一次运算或者任务需要的时间,是完成一条或一组指令以生成应用程序结果值所需的时钟周期数。应用程序延迟是FPGA和处理器的关键性能指标。在这两种情况下,延迟问题都是通过使用流水线 来解决的。在处理器中,流水线意味着下一条指令可以在当前指令完成之前启动执行。这允许指令集处理中所需的开销阶段重叠。处理器流水线的最佳情况结果如图所示。
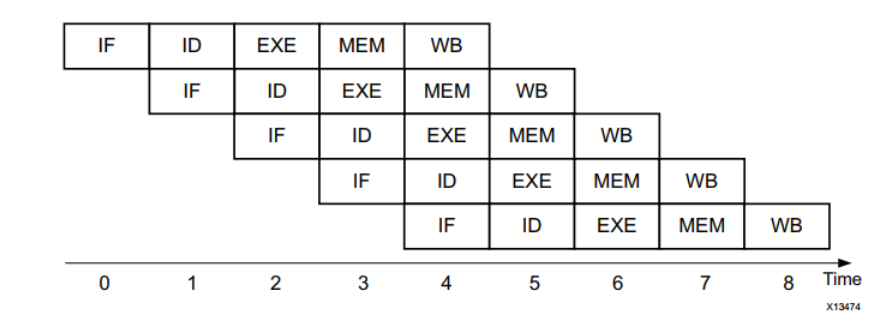
通过重叠指令的执行,处理器实现了五条指令应用程序九个时钟周期的延迟。
在FPGA中,不存在与指令处理相关的开销周期。但在FPGA中进行流水线处理的原因与在处理器中进行流水线处理的原因相同,为了提高应用程序性能。
FPGA中的流水线是插入更多寄存器以将大型计算块分解为较小段的过程。这种计算分区增加了绝对时钟周期数的延迟,但通过允许自定义电路以更高的时钟频率运行来提高性能。
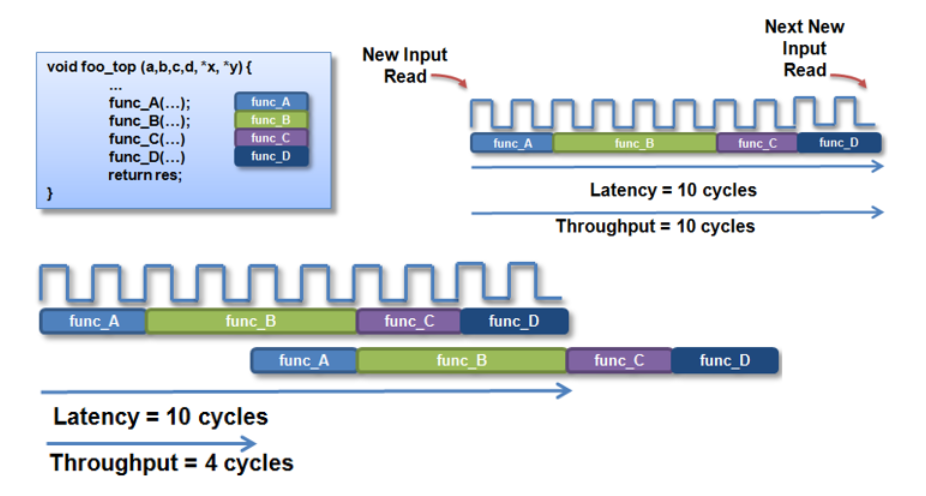
吞吐量
吞吐量也可以表示为输入(输出)延时,表示每两次输入或者输出之间的时间间隔。吞吐量是用于确定实现的总体性能的另一个指标。它是处理逻辑接受下一个输入数据样本所需的时钟周期数。
内存体系结构和布局
通用内存体系结构由基于将数据传输到处理器所需的时钟周期数的慢、中或快的内存组成。
| Memory Type | Definition |
|---|---|
| Slow | Mass storage devices, such as hard drives |
| Medium | DDR memories |
| Fast | On-chip cache memories of different sizes depending on the specific processor |
此表中显示的内存体系结构假设向用户提供单个大内存空间。 在这个内存空间内,用户分配和释放区域来存储程序数据。 在这种系统中,提高性能的唯一方法是尽可能多地重用缓存中的数据。
为实现这一目标,软件工程师必须花费大量时间查看缓存跟踪、重构软件算法以增加数据局部性,并管理内存分配以最小化程序的瞬时内存占用。尽管所有这些技术都可以跨处理器移植,但结果却并非如此。 软件程序必须针对它运行的每个处理器进行调整,以最大限度地提高性能。
凭借使用基于处理器的存储器的经验,软件工程师在处理 FPGA 中的存储器时遇到的第一个区别是缺乏固定的片上存储器架构。
基于 FPGA 的系统可以连接到慢速和中速存储器,但在可用的快速存储器方面表现出最大程度的差异。 也就是说,Vivado HLS 编译器不是重构软件以最好地利用现有缓存,而是构建了一个快速内存架构,以最适合算法中的数据布局 。 最终的 FPGA 实现可以有一个或多个不同大小的内部组,这些组可以相互独立地访问。
FPGA 代码缺乏动态内存分配。如果想进行内存分配必须把大小固定。Vivado HLS 编译器构建了一个为应用量身定制的内存架构。这种定制的内存架构是由程序中内存块的大小以及在整个程序执行过程中如何使用数据来塑造的。当前最先进的 FPGA 编译器(例如 Vivado HLS)要求在编译时完全可分析应用程序的内存需求。
静态内存分配的好处是 Vivado HLS 可以以不同的方式为数组 A 实现内存。 根据算法中的计算,Vivado HLS 编译器可以将 A 的内存实现为寄存器、移位寄存器、FIFO 或 BRAM。
寄存器
内存的寄存器实现是最快的内存结构。 在这种实现风格中,A 的每个条目都成为一个独立的实体。 每个独立实体都嵌入到计算中,无需处理逻辑或额外延迟即可使用。
移位寄存器
在处理器编程术语中,可以将移位寄存器视为队列的一种特殊情况。 在这个实现中,A 的每个元素在计算的不同部分被多次使用。 移位寄存器的关键特性是可以在每个时钟周期访问 A 的每个元素。 此外,将所有数据项移动到下一个相邻的存储容器只需要一个时钟周期。
许多 C 算法通过数组顺序移动数据。将一个新值添加到数组的开头,通过数组移位现有数据并删除最旧的数据。C语言中没有和移位寄存器完全吻合的语法元素。
SRL架构资源最有效地实现所需的移位寄存器。当在移位寄存器中间访问数据时,逻辑综合不能直接推断 SRL 。 但是逻辑综合可能使用触发器实现移位寄存器的电路。
移位寄存器,移位寄存器是一种存储器,存在里边的数据可以从低位向高位移动或从高位向低位移动。
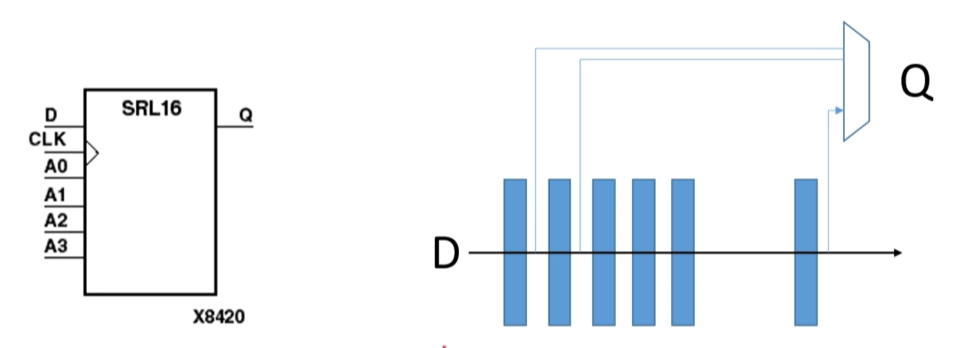
为了利用移位寄存器,HLS提供了ap_shift_reg 类,以便于进行使用移位寄存器资源。
FIFO
可以将 FIFO 视为具有单个入口点和单个出口点的队列。这种结构通常用于在程序循环或函数之间传输数据。不涉及寻址逻辑,实现细节完全由 Vivado HLS 编译器处理。
BRAM
BRAM是嵌入FPGA结构中的随机存取存储器。Xilinx FPGA设备包括许多这样的嵌入式存储器。存储器的确切数量取决于设备。在处理器编程术语中,这种内存可以被视为具有以下限制的缓存:
- 不实现通常在处理器缓存中发现的缓存一致性、冲突和缓存未命中跟踪逻辑。
- 仅在设备通电时保持其值。
- 支持对两个不同内存位置的并行同周期访问。
reference
- UG998
相关文章
- ICMP 概念
- arp 的基础概念
- MySQL数据库复制概念及数据库架构不断扩展方案
- [Spring学习笔记 4 ] AOP 概念原理以及java动态代理
- 重新整理操作系统概念系类——中断异常
- 视觉显著性检测(Visual saliency detection)相关概念
- Docker 核心概念:镜像、容器、仓库,架构核心设计理念
- 三级缓存/缓存行概念/缓存一致性协议/缓存对齐编程
- kafka架构组件概念详解:Broker、Topic、Partition、Leader/Follower、Consumer Group、zookeeper
- 通过一个实际例子,理解 SAP UI5 sap.ui.model.odata.v2.ODataModel API 中 BindingContext 绑定上下文的概念和用法试读版
- SAP Spartacus public API的概念 - index.ts
- 【译】Linux概念架构的理解
- Atitit 培训之道 attilax著 1. 概念 培训就是及教育1 1.1. 知识体系化2 1.2. 组织架构2 1.3. 人员架构 梯队化培训2 2. 培训目标,尽可能与项目相关技术点
- ML与math:机器学习与高等数学基础概念、代码实现、案例应用之详细攻略——基础篇
- 操作系统概念(第十一章) 文件系统实现
- 【人工智能简史】第一章 引言 —— 人工智能的概念与定义、发展背景及相关领域、意义与价值
- Kubernetes集群架构原理及各节点组件概念(一)
- 二进制方式搭建Kubernetes高可用集群(超丰富的组件概念理论总结)
- Ceph分布式存储核心概念以及架构原理(二)
- 阿里云ECS云服务器快照概念以及使用(六)