
【GPU】Nvidia CUDA 编程基础教程——使用 CUDA C/C++ 加速应用程序
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解
Nvidia CUDA编程基础教程

加速计算正在取代 CPU 计算,成为最佳计算做法。加速计算带来的层出不穷的突破性进展、对加速应用程序日益增长的需求、轻松编写加速计算的编程规范以及支持加速计算的硬件的不断改进,所有这一切都在推动计算方式必然会过渡到加速计算。
无论是从出色的性能还是易用性来看,CUDA 计算平台均是加速计算的制胜法宝。CUDA 提供一种可扩展 C、C++、Python 和 Fortran 等语言的编码范式,能够在世界上性能超强劲的并行处理器 NVIDIA GPU 上运行大量经加速的并行代码。CUDA 可以毫不费力地大幅加速应用程序,具有适用于 DNN、BLAS、图形分析 和 FFT 等的高度优化库生态系统,并且还附带功能强大的 命令行 和 可视化分析器。
CUDA 支持以下领域的许多(即便不是大多数)世界上性能超强劲的应用程序:计算流体动力学、分子动力学、量子化学、物理学 和高性能计算 (HPC)。
学习 CUDA 将能助您加速自己的应用程序。加速应用程序的执行速度远远超过 CPU 应用程序,并且可以执行 CPU 应用程序受限于其性能而无法执行的计算。在本实验中, 您将学习使用 CUDA C/C++ 为加速应用程序编程的入门知识,这些入门知识足以让您开始加速自己的 CPU 应用程序以获得性能提升并助您迈入全新的计算领域。
如何安装编译和运行环境,可以参考官方指导
GPU 加速应用程序与 CPU 应用程序对比
在 CPU 应用程序中,数据在 CPU 上进行分配,并且所有工作均在 CPU 上执行👇
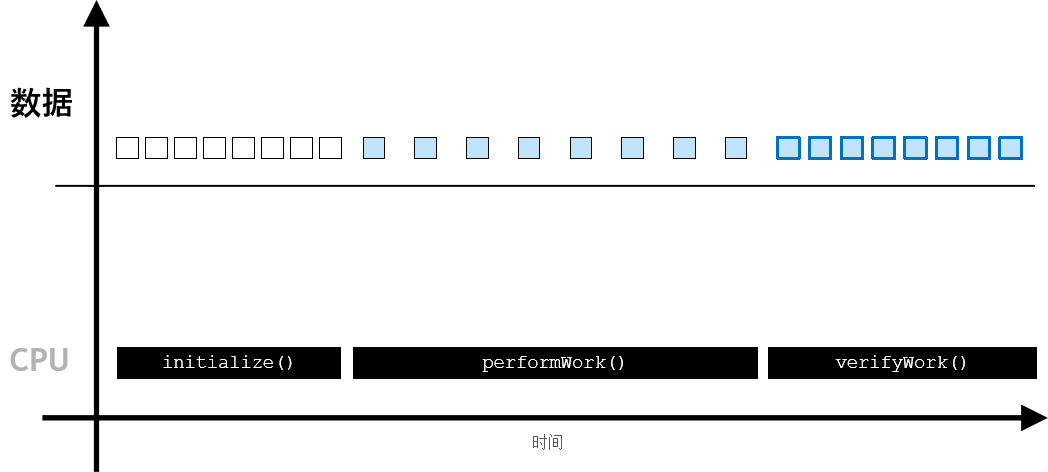
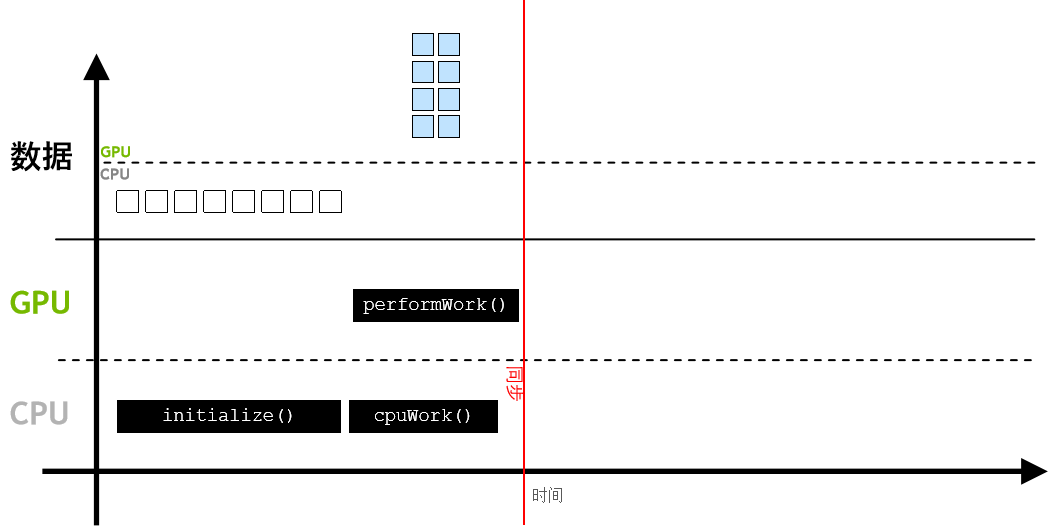
而在加速应用程序中,则可使用 cudaMallocManaged()分配数据,其数据可由 CPU 进行访问和处理,并能自动迁移至可执行并行工作的 GPU👇

GPU 异步执行工作,与此同时CPU可执行它的工作,通过 cudaDeviceSynchronize(),CPU 代码可与异步 GPU 工作实现同步,并等待后者完成👇
经 CPU 访问的数据将会自动迁移👇
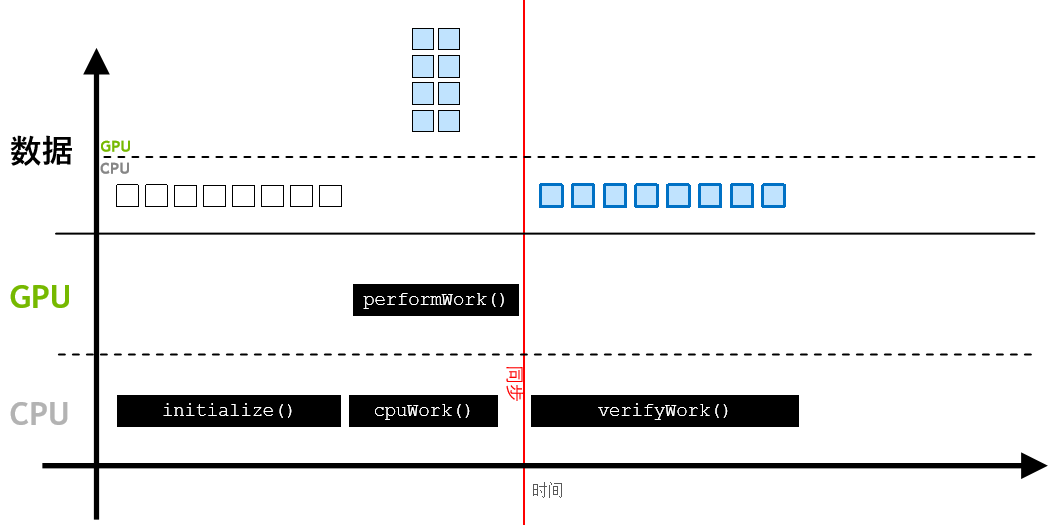
为GPU编写应用程序代码
CUDA 为许多常用编程语言提供扩展,例如 C、C++、Python 和 Fortran 等语言。CUDA 加速程序的文件扩展名是.cu。
以下是一个 .cu 文件。其中包含两个函数,第一个函数将在 CPU 上运行,第二个将在 GPU 上运行。
void CPUFunction()
{
printf("This function is defined to run on the CPU.\n");
}
__global__ void GPUFunction()
{
printf("This function is defined to run on the GPU.\n");
}
int main()
{
CPUFunction();
GPUFunction<<<1, 1>>>();
cudaDeviceSynchronize();
}
以下是一些需要特别注意的重要代码行,以及加速计算中使用的一些其他常用术语:
__global__ void GPUFunction()
- __global__ 关键字表明以下函数将在 GPU 上运行并可全局调用;
- 常,我们将在 CPU 上执行的代码称为主机代码,而将在 GPU 上运行的代码称为设备代码;
- 注意返回类型为 void。使用 __global__ 关键字定义的函数需要返回 void 类型。
GPUFunction<<<1, 1>>>();
- 通常,当调用要在 GPU 上运行的函数时,我们将此种函数称为已启动的核函数;
- 启动核函数时,我们必须提供执行配置,即在向核函数传递任何预期参数之前使用 <<< … >>> 语法完成的配置;
- 在宏观层面,程序员可通过执行配置为核函数启动指定线程层次结构,从而定义线程组(称为线程块)的数量,以及要在每个线程块中执行的线程数量。
cudaDeviceSynchronize();
- 与许多 C/C++ 代码不同,核函数启动方式为异步:CPU 代码将继续执行而无需等待核函数完成启动;
- 调用 CUDA 运行时提供的函数 cudaDeviceSynchronize 将导致主机 (CPU) 代码暂作等待,直至设备 (GPU) 代码执行完成,才能在 CPU 上恢复执行。
编译并运行加速后的CUDA代码
CUDA 平台附带 NVIDIA CUDA 编译器 nvcc,可以编译 CUDA 加速应用程序,其中包含主机和设备代码。就本实验而言,nvcc 的讨论范围将根据我们的迫切需求据实确定。完成本实验学习后,有意深究 nvcc 的所有用户均可从 文档 开始入手。
曾使用过 gcc 的用户会对 nvcc 感到非常熟悉。例如,编译 some-CUDA.cu 文件就很简单:
nvcc -arch=sm_70 -o out some-CUDA.cu -run 含义如下:
nvcc是使用 nvcc 编译器的命令行命令;- 将
some-CUDA.cu作为文件传递以进行编译; o标志用于指定编译程序的输出文件;arch标志表示该文件必须编译为哪个架构类型;run标志将执行已成功编译的二进制文件。
CUDA的线程层次结构
GPU 可并行执行工作,GPU 在线程中执行工作,多个线程并行运行,如下图👇

线程的集合称为块,块的数量很多,如下图👇
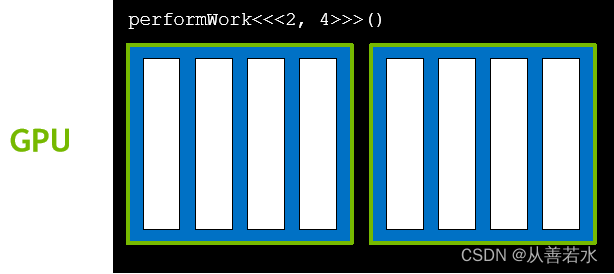
与给定核函数启动相关联的块的集合称为网格,如下图👇

GPU 函数称为核函数,核函数通过执行配置启动,执行配置定义了网格中的块数以及每个块中的线程数,网格中的每个块均包含相同数量的线程。
启动并行运行的核函数
程序员可通过执行配置指定有关如何启动核函数以在多个 GPU 线程中并行运行的详细信息。更准确地说,程序员可通过执行配置指定线程组(称为线程块或简称为块)数量以及其希望每个线程块所包含的线程数量。执行配置的语法如下:
<<< NUMBER_OF_BLOCKS, NUMBER_OF_THREADS_PER_BLOCK>>>
启动核函数时,核函数代码由每个已配置的线程块中的每个线程执行。
因此,如果假设已定义一个名为 someKernel 的核函数,则下列情况为真:
- someKernel<<<1, 1>>() 配置为在具有单线程的单个线程块中运行后,将只运行一次。
- someKernel<<<1, 10>>() 配置为在具有 10 线程的单个线程块中运行后,将运行 10 次。
- someKernel<<<10, 1>>() 配置为在 10 个线程块(每个均具有单线程)中运行后,将运行 10 次。
- someKernel<<<10, 10>>() 配置为在 10 个线程块(每个均具有 10 线程)中运行后,将运行 100 次。
CUDA提供的线程层次结构变量
在核函数定义中,CUDA 提供的变量描述了它所执行的线程、块和网格。
gridDim.x 是网格中的块数,在本例中为 2 👇

blockIdx.x 是网格中当前块的索引,在本例中为 0 👇
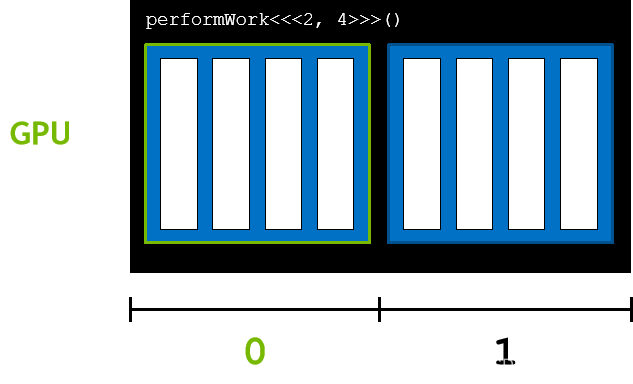
blockIdx.x 是网格中当前块的索引,在本例中为 1 👇
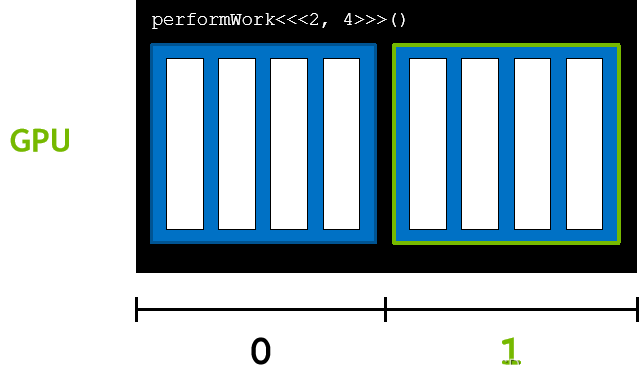
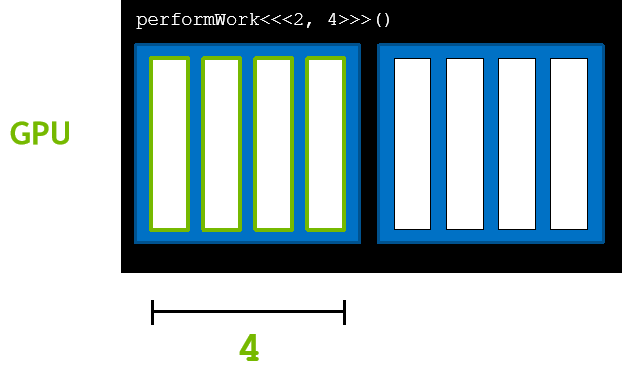
在核函数中,blockDim.x 描述了块中的线程数。在本例中为 4 👇
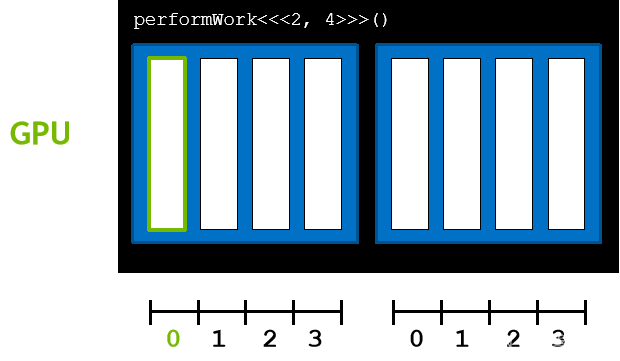
网格中的所有块均包含相同数量的线程,在核函数中,threadIdx.x 描述了块中所包含线程的索引。在本例中为 0 👇
线程和块的索引
每个线程在其线程块内部均会被分配一个索引,从 0 开始。此外,每个线程块也会被分配一个索引,并从 0 开始。正如线程组成线程块,线程块又会组成网格,而网格是 CUDA 线程层次结构中级别最高的实体。简言之,CUDA 核函数在由一个或多个线程块组成的网格中执行,且每个线程块中均包含相同数量的一个或多个线程。
CUDA 核函数可以访问能够识别如下两种索引的特殊变量:正在执行核函数的线程(位于线程块内)索引和线程所在的线程块(位于网格内)索引。这两种变量分别为 threadIdx.x 和 blockIdx.x。
协调并行线程
假设数据位于索引为 0 的向量中,由于某种未知原因,必须映射每个线程以处理向量中的元素,
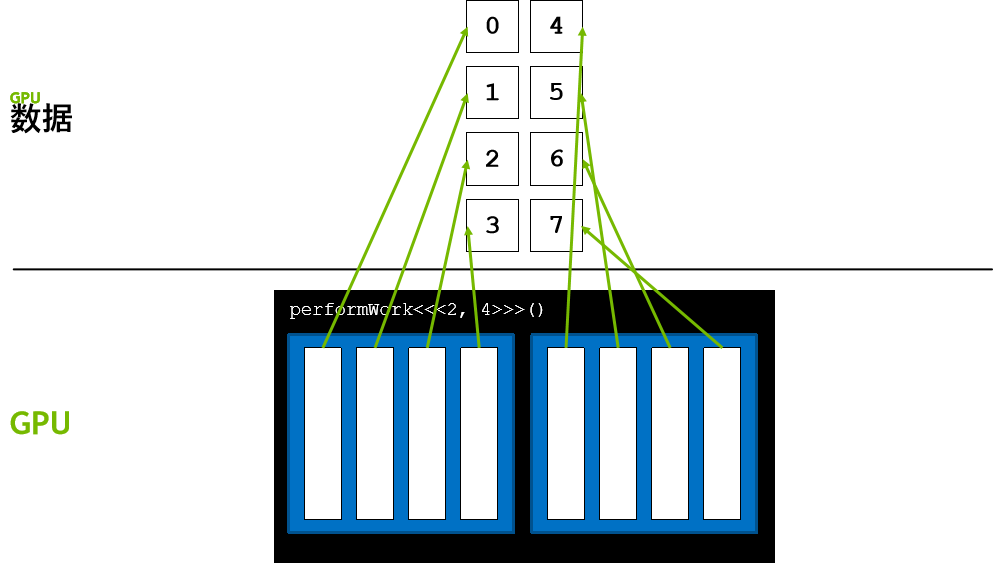
通过这些变量,公式 threadIdx.x + blockIdx.x * blockDim.x 可将每个线程映射到向量的元素中,
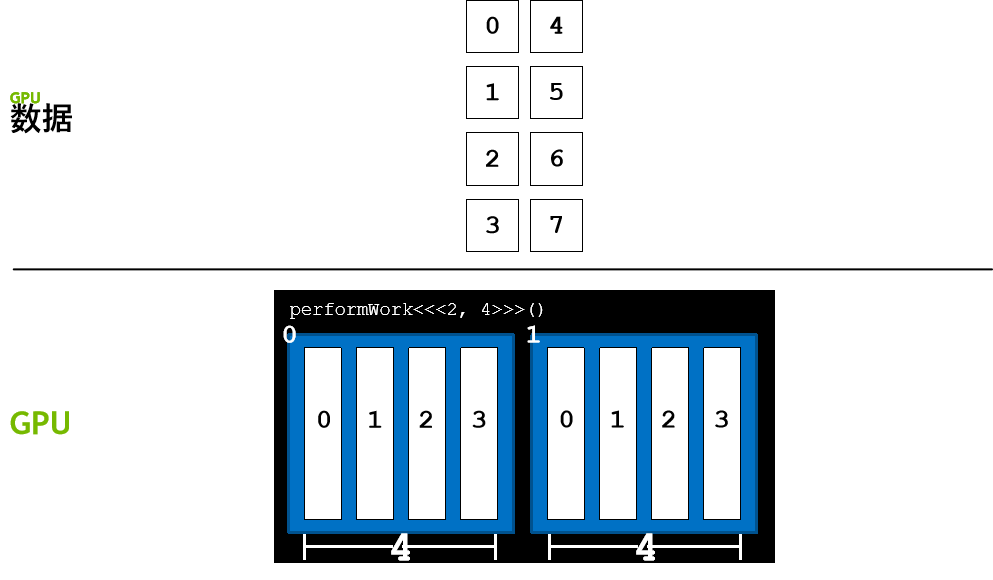
调整线程块的大小以实现更多的并行化
线程块包含的线程具有数量限制:确切地说是 1024 个。为增加加速应用程序中的并行量,我们必须要能在多个线程块之间进行协调。
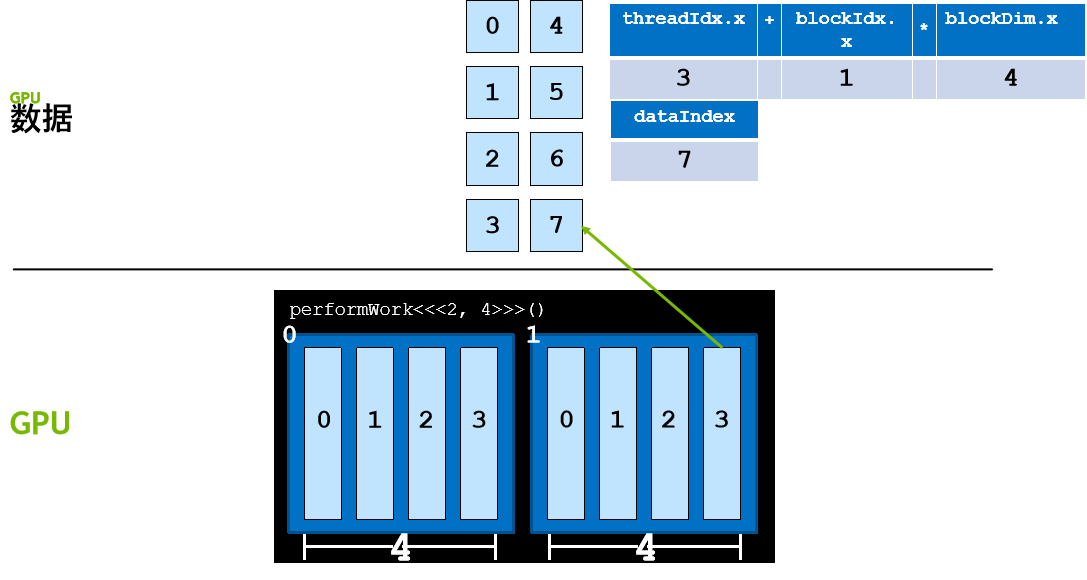
CUDA 核函数可以访问给出块中线程数的特殊变量:blockDim.x。通过将此变量与 blockIdx.x 和 threadIdx.x 变量结合使用,并借助惯用表达式 threadIdx.x + blockIdx.x * blockDim.x 在包含多个线程的多个线程块之间组织并行执行,并行性将得以提升。以下是详细示例。
执行配置 <<<10, 10>>> 将启动共计拥有 100 个线程的网格,这些线程均包含在由 10 个线程组成的 10 个线程块中。因此,我们希望每个线程(0 至 99 之间)都能计算该线程的某个唯一索引。
- 如果线程块 blockIdx.x 等于 0,则 blockIdx.x * blockDim.x 为 0。向 0 添加可能的 threadIdx.x 值(0 至 9),之后便可在包含 100 个线程的网格内生成索引 0 至 9;
- 如果线程块 blockIdx.x 等于 1,则 blockIdx.x * blockDim.x 为 10。向 10 添加可能的 threadIdx.x 值(0 至 9),之后便可在包含 100 个线程的网格内生成索引 10 至 19;
- 如果线程块 blockIdx.x 等于 5,则 blockIdx.x * blockDim.x 为 50。向 50 添加可能的 threadIdx.x 值(0 至 9),之后便可在包含 100 个线程的网格内生成索引 50 至 59;
- 如果线程块 blockIdx.x 等于 9,则 blockIdx.x * blockDim.x 为 90。向 90 添加可能的 threadIdx.x 值(0 至 9),之后便可在包含 100 个线程的网格内生成索引 90 至 99。
分配将要在GPU和CPU上访问的内存
CUDA 的最新版本(版本 6 和更高版本)已能轻松分配可用于 CPU 主机和任意数量 GPU 设备的内存。尽管现今有许多适用于内存管理并可支持加速应用程序中最优性能的中高级技术,但我们现在要介绍的基础 CUDA 内存管理技术不但能够支持远超 CPU 应用程序的卓越性能,而且几乎不会产生任何开发人员成本。
如要分配和释放内存,并获取可在主机和设备代码中引用的指针,请使用 cudaMallocManaged 和 cudaFree 取代对 malloc 和 free 的调用,如下例所示:
// CPU-only
int N = 2<<20;
size_t size = N * sizeof(int);
int *a;
a = (int *)malloc(size);
// Use `a` in CPU-only program.
free(a);
// Accelerated
int N = 2<<20;
size_t size = N * sizeof(int);
int *a;
// Note the address of `a` is passed as first argument.
cudaMallocManaged(&a, size);
// Use `a` on the CPU and/or on any GPU in the accelerated system.
cudaFree(a);
网格大小与工作量不匹配
在先前场景中,网络中的线程数与元素数量完全匹配,
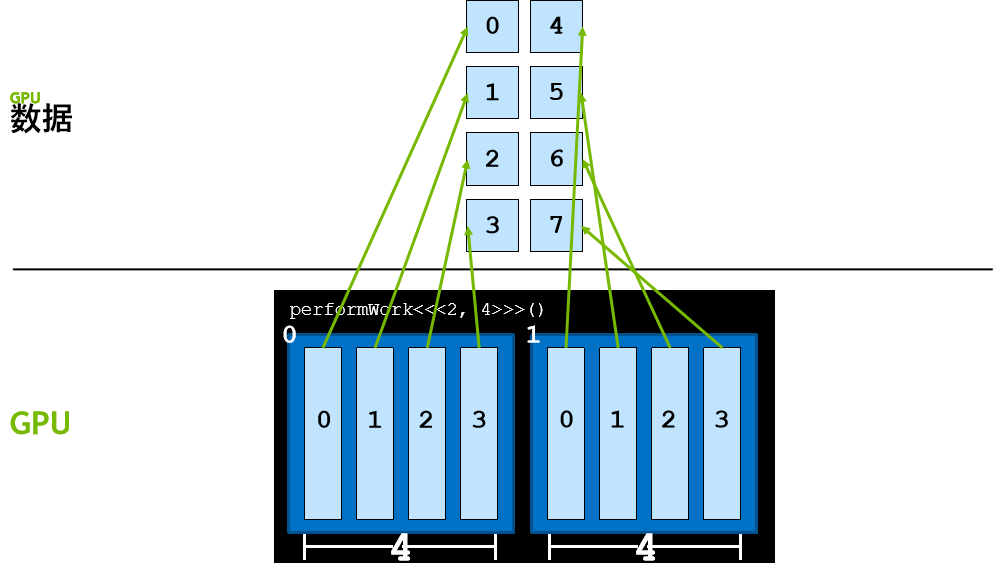
如果线程数超过要完成的工作量,该怎么办?尝试访问不存在的元素会导致运行时错误,
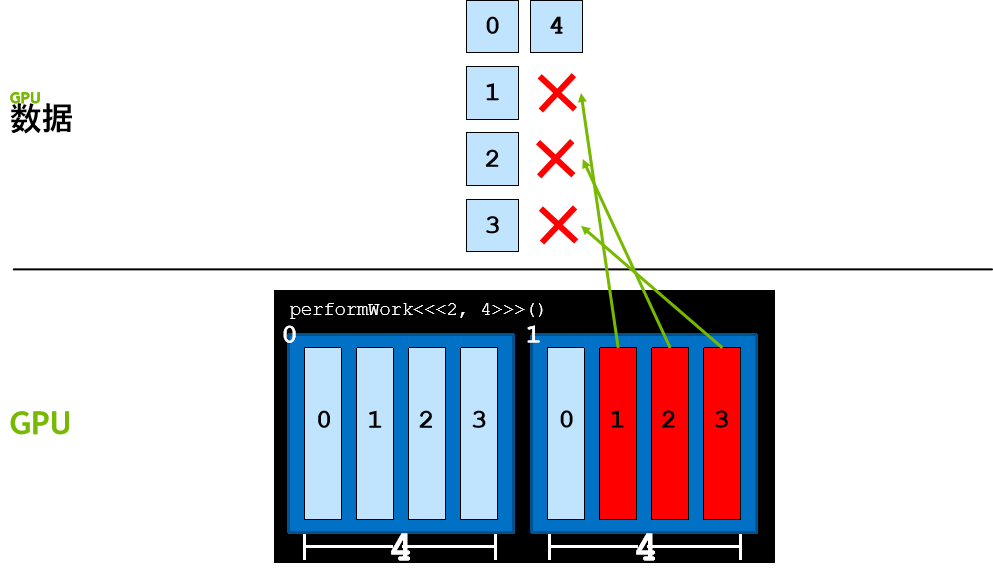
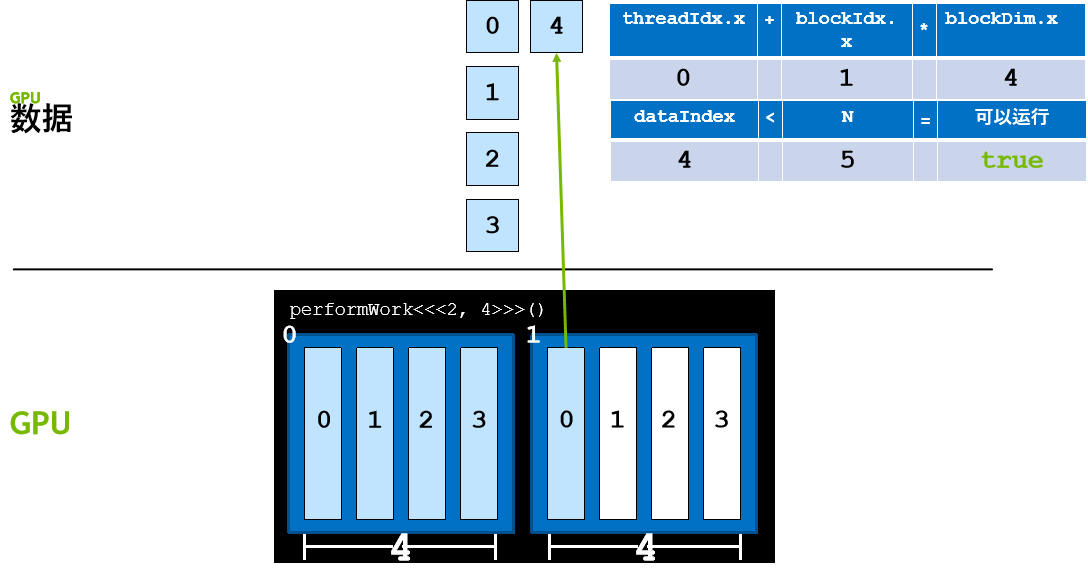
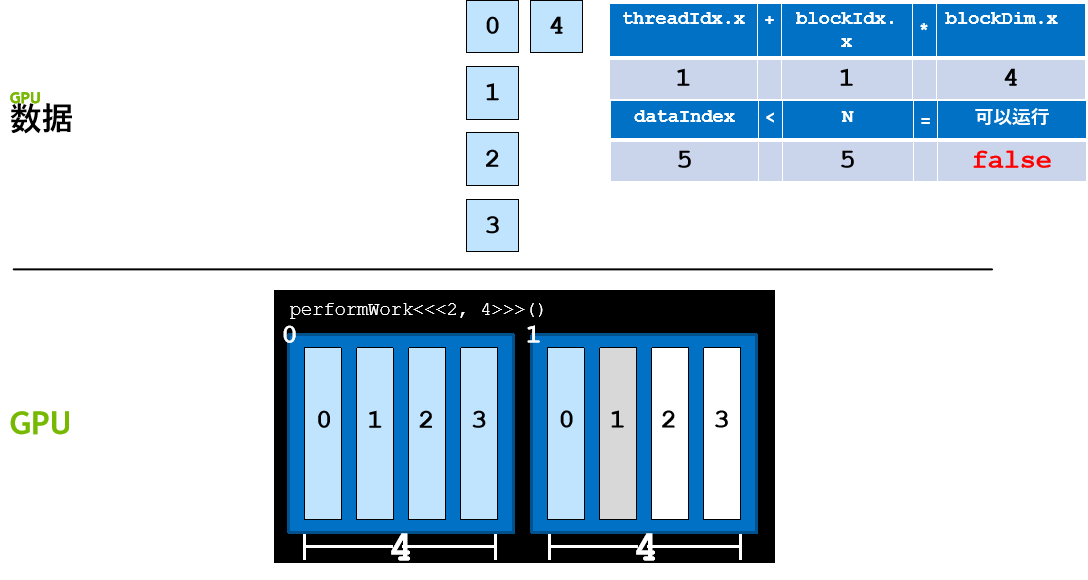
必须使用代码检查并确保经由公式 threadIdx.x + blockIdx.x * blockDim.x 计算出的 dataIndex 小于 N(数据元素数量)。
如何处理块配置与所需线程数不匹配
可能会出现这样的情况,执行配置所创建的线程数无法匹配为实现并行循环所需的线程数。
一个常见的例子与希望选择的最佳线程块大小有关。例如,鉴于 GPU 的硬件特性,所含线程的数量为 32 的倍数的线程块是最理想的选择,因其具备性能上的优势。假设我们要启动一些线程块且每个线程块中均包含 256 个线程(32 的倍数),并需运行 1000 个并行任务(此处使用极小的数量以便于说明),则任何数量的线程块均无法在网格中精确生成 1000 个总线程,因为没有任何整数值在乘以 32 后可以恰好等于 1000。
这个问题可以通过以下方式轻松地解决:
- 编写执行配置,使其创建的线程数超过执行分配工作所需的线程数;
- 将一个值作为参数传递到核函数 (N) 中,该值表示要处理的数据集总大小或完成工作所需的总线程数;
- 计算网格内的线程索引后(使用 threadIdx + blockIdx*blockDim),请检查该索引是否超过 N,并且只在不超过的情况下执行与核函数相关的工作。
以下是编写执行配置的惯用方法示例,适用于 N 和线程块中的线程数已知,但无法保证网格中的线程数和 N 之间完全匹配的情况。如此一来,便可确保网格中至少始终拥有 N 所需的线程数,且超出的线程数至多仅可相当于 1 个线程块的线程数量:
// Assume `N` is known
int N = 100000;
// Assume we have a desire to set `threads_per_block` exactly to `256`
size_t threads_per_block = 256;
// Ensure there are at least `N` threads in the grid, but only 1 block's worth extra
size_t number_of_blocks = (N + threads_per_block - 1) / threads_per_block;
some_kernel<<<number_of_blocks, threads_per_block>>>(N);
由于上述执行配置致使网格中的线程数超过 N,因此需要注意 some_kernel 定义中的内容,以确保 some_kernel 在由其中一个 ”额外的” 线程执行时不会尝试访问超出范围的数据元素:
__global__ some_kernel(int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) // Check to make sure `idx` maps to some value within `N`
{
// Only do work if it does
}
}
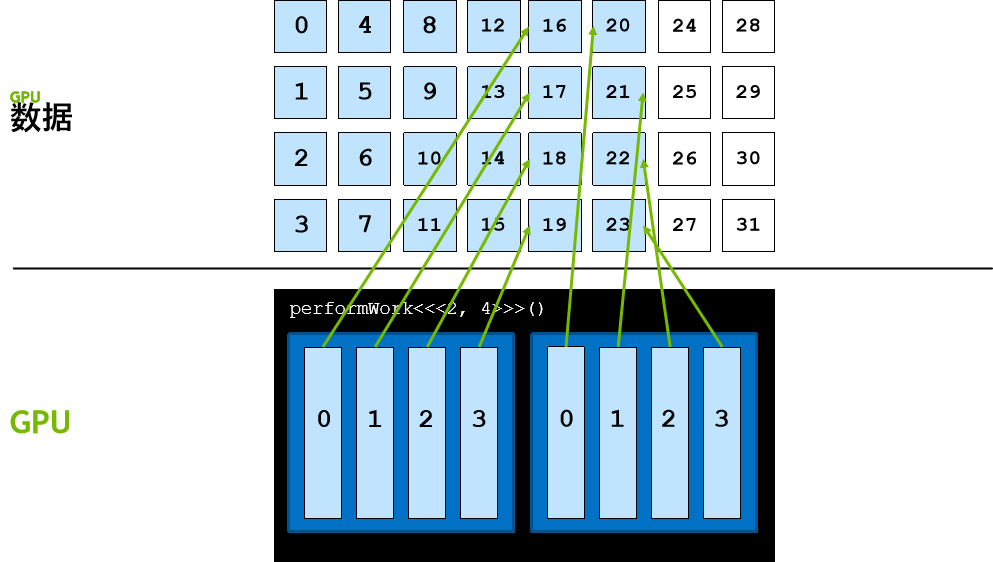
跨网格的循环
数据元素数量往往会大于网格中的线程数,在此类情况下,线程无法只处理一个元素,否则工作便无法完成。
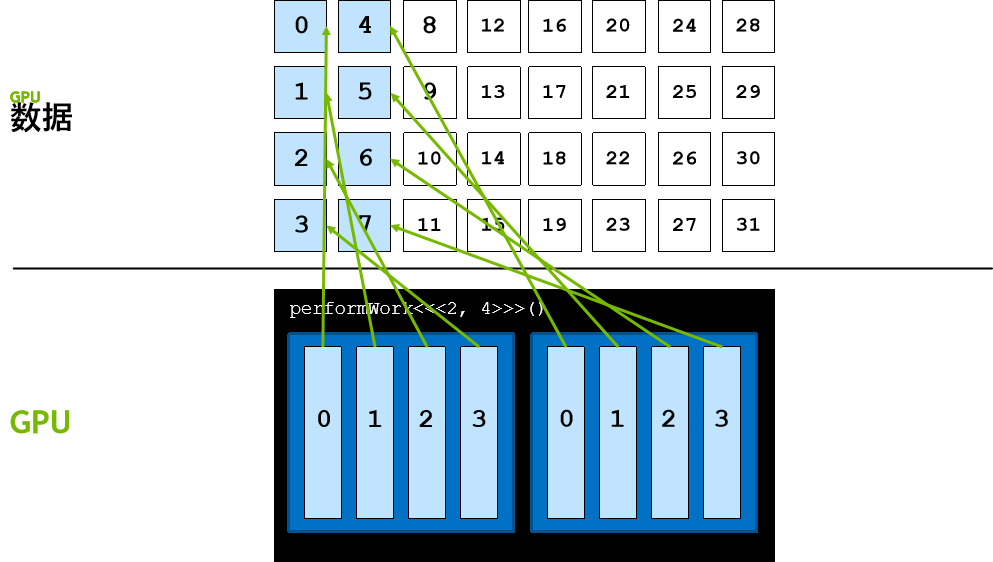
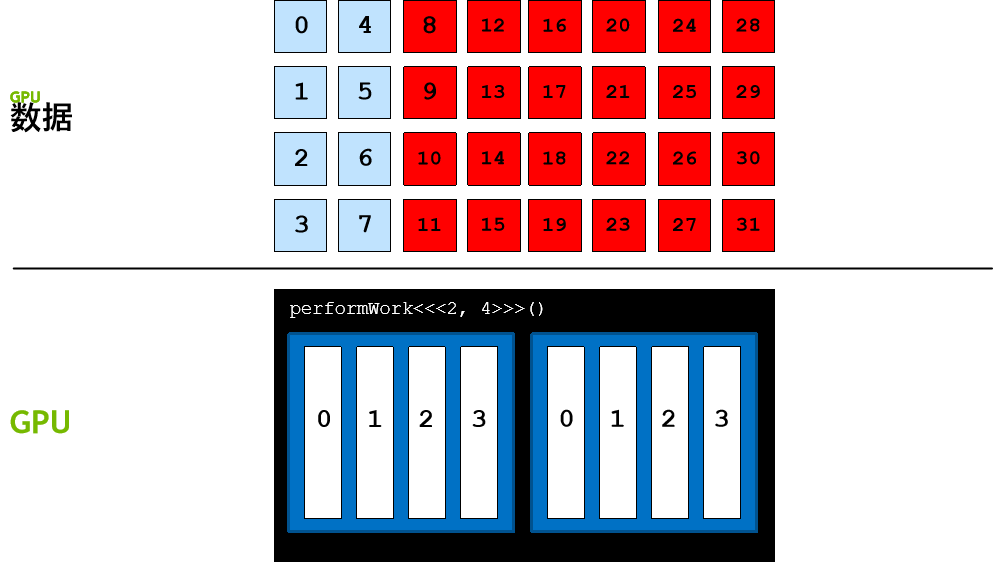
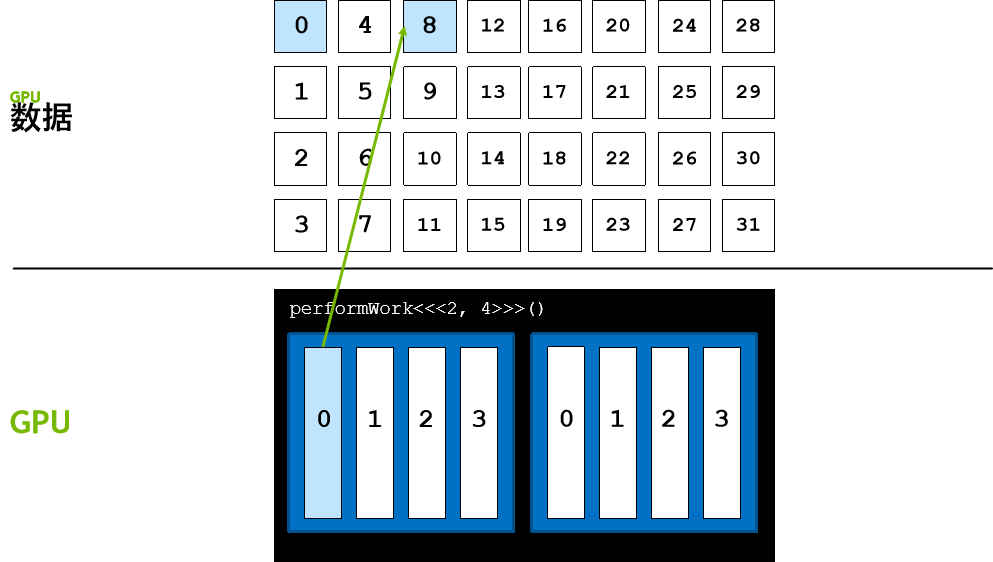
以编程方式解决此问题的其中一种方法是使用网格跨度循环,在网格跨度循环中,线程的第一个元素依旧使用 threadIdx.x + blockIdx.x * blockDim.x 计算得出。然后,线程会按网格中的线程数 (blockDim.x * gridDim.x) 向前迈进,在本例中线程数为 8。
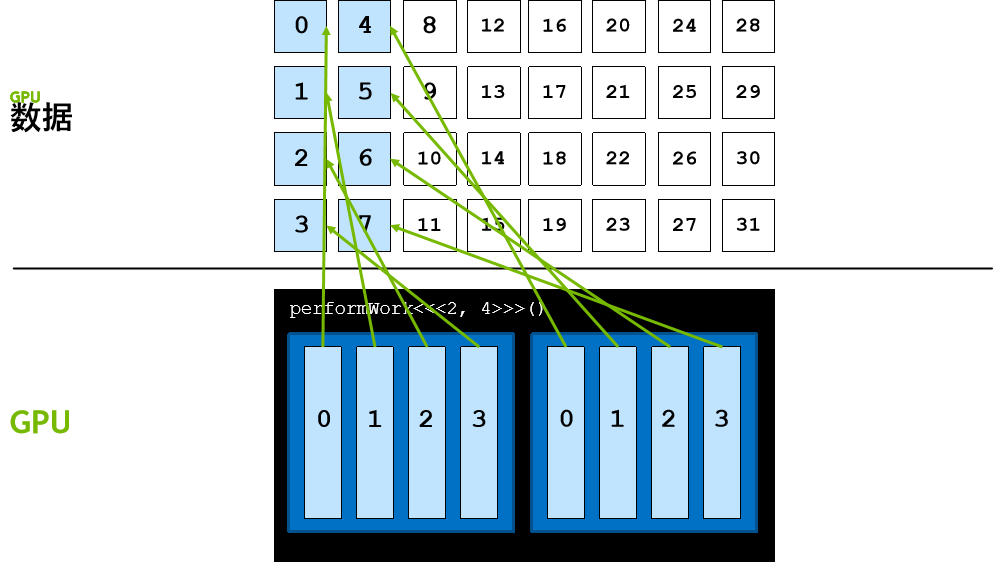
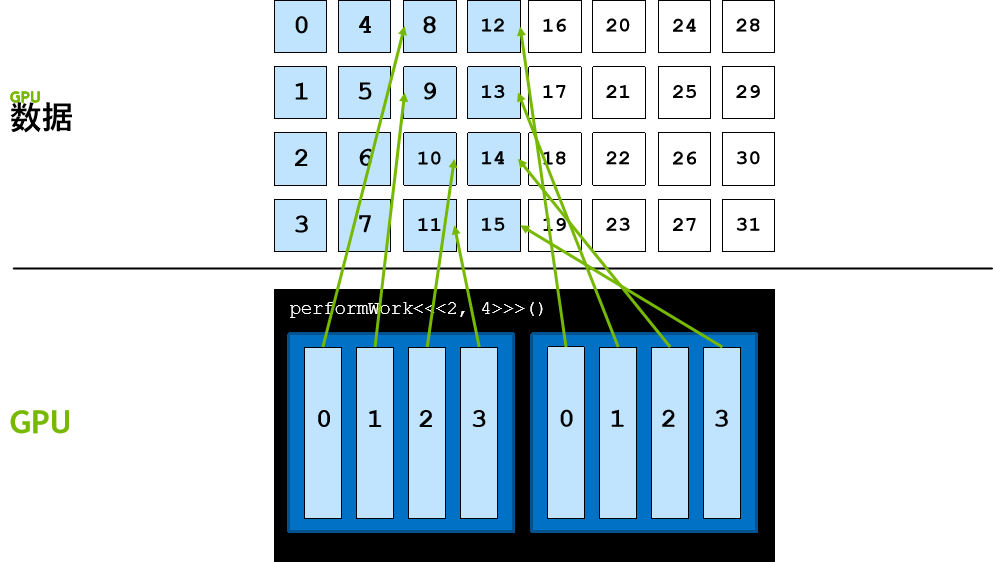
线程会继续向前迈进,直至其数据索引超出数据元素的数量,所有线程均按此种方式运作,如此便会涵盖所有元素。
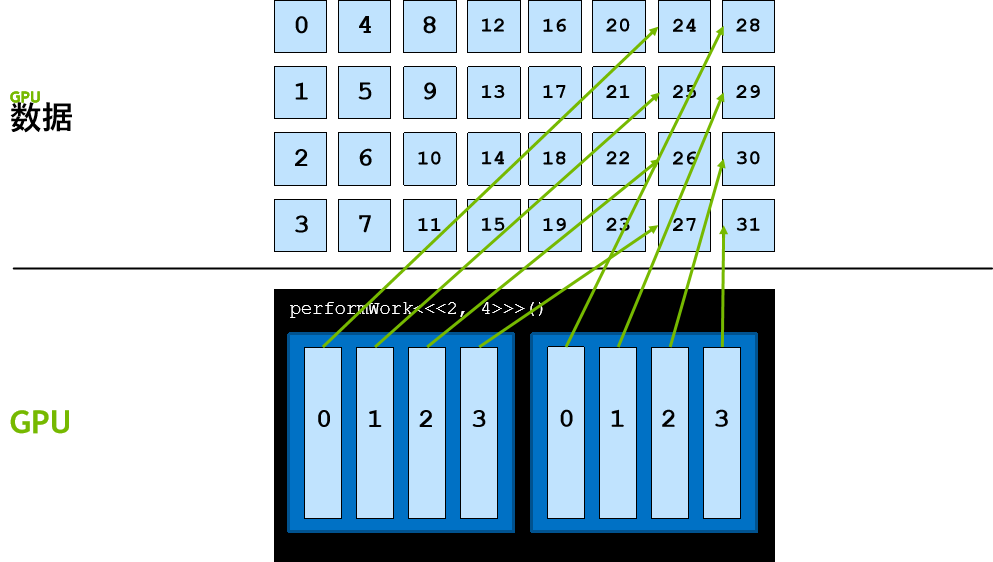
数据集比网格大
或出于选择,为了要创建具有超高性能的执行配置,或出于需要,一个网格中的线程数量可能会小于数据集的大小。请思考一下包含 1000 个元素的数组和包含 250 个线程的网格(此处使用极小的规模以便于说明)。此网格中的每个线程将需使用 4 次。如要实现此操作,一种常用方法便是在核函数中使用跨网格循环。
在跨网格循环中,每个线程将在网格内使用 threadIdx + blockIdx*blockDim 计算自身唯一的索引,并对数组内该索引的元素执行相应运算,然后将网格中的线程数添加到索引并重复此操作,直至超出数组范围。例如,对于包含 500 个元素的数组和包含 250 个线程的网格,网格中索引为 20 的线程将执行如下操作:
- 对包含 500 个元素的数组的元素 20 执行相应运算;
- 将其索引增加 250,使网格的大小达到 270;
- 对包含 500 个元素的数组的元素 270 执行相应运算;
- 将其索引增加 250,使网格的大小达到 520;
- 由于 520 现已超出数组范围,因此线程将停止工作。
CUDA 提供一个可给出网格中线程块数的特殊变量:gridDim.x。然后计算网格中的总线程数,即网格中的线程块数乘以每个线程块中的线程数:gridDim.x * blockDim.x 。带着这样的想法来看看以下核函数中网格跨度循环的详细示例:
__global void kernel(int *a, int N)
{
int indexWithinTheGrid = threadIdx.x + blockIdx.x * blockDim.x;
int gridStride = gridDim.x * blockDim.x;
for (int i = indexWithinTheGrid; i < N; i += gridStride)
{
// do work on a[i];
}
}
错误处理
与在任何应用程序中一样,加速 CUDA 代码中的错误处理同样至关重要。即便不是大多数,也有许多 CUDA 函数(例如,内存管理函数)会返回类型为 cudaError_t 的值,该值可用于检查调用函数时是否发生错误。以下是对调用 cudaMallocManaged 函数执行错误处理的示例:
cudaError_t err;
err = cudaMallocManaged(&a, N) // Assume the existence of `a` and `N`.
if (err != cudaSuccess) // `cudaSuccess` is provided by CUDA.
{
printf("Error: %s\n", cudaGetErrorString(err)); // `cudaGetErrorString` is provided by CUDA.
}
启动定义为返回 void 的核函数后,将不会返回类型为 cudaError_t 的值。为检查启动核函数时是否发生错误(例如,如果启动配置错误),CUDA 提供 cudaGetLastError 函数,该函数会返回类型为 cudaError_t 的值。
/*
* This launch should cause an error, but the kernel itself
* cannot return it.
*/
someKernel<<<1, -1>>>(); // -1 is not a valid number of threads.
cudaError_t err;
err = cudaGetLastError(); // `cudaGetLastError` will return the error from above.
if (err != cudaSuccess)
{
printf("Error: %s\n", cudaGetErrorString(err));
}
最后,为捕捉异步错误(例如,在异步核函数执行期间),请务必检查后续同步 CUDA 运行时 API 调用所返回的状态(例如 cudaDeviceSynchronize);如果之前启动的其中一个核函数失败,则将返回错误。
自定义一个CUDA错误处理宏
#include <stdio.h> #include <assert.h> inline cudaError_t checkCuda(cudaError_t result) { if (result != cudaSuccess) { fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result)); assert(result == cudaSuccess); } return result; } int main() { /* * The macro can be wrapped around any function returning * a value of type `cudaError_t`. */ checkCuda( cudaDeviceSynchronize() ) }

相关文章
- 【C/C++学院】0829-位容器multimapmutisetString/算法函数兰不达表达式以及类重载/GPU编程
- 【C/C++学院】(22)Mysql数据库编程--C语言操作数据库
- 【C/C++学院】(4)c++开篇/类和对象/命名空间/类型增强/三目运算符/const专题/引用专题/函数增强
- 鸡啄米:C++编程之十四学习之构造函数和析构函数
- C++多线程编程笔记
- Linux C++开发环境搭建
- C语言/C++常见习题问答集锦之移动的坦克
- LCP 06. 拿硬币(C++)
- 【QML与C++混合编程】在 QML 中使用 C++ 类和对象(二)
- 读刘未鹏老大《你应当怎样学习C++(以及编程)》
- VS中c++文件调用c 函数 ,fatal error C1853 预编译头文件来自编译器的早期版本号,或者预编译头为 C++ 而在 C 中使用它(或相反)
- 【面试攻略】C++面试-栈
- 【华为OD机试 2023】等和子数组最小和(C++ Java JavaScript Python)
- C++ map用法总结(整理)
- C++ string数组字符串排序 sort
- C、C++面试题:编程实现字符串中字串的查找
- C++之普通指针与智能指针相互转换(一百零六)
- 单链表的逆置-C++实现(五十四)
- Emacs之为c/c++函数生成调用图(八十)
- VC++ socket编程中设置socket选项的ioctlsocket、setsockopt和WSAIoctl函数的使用(附源码)
- VC++使用开源的zip.cpp和unzip.cpp实现压缩包的创建与解压(附源码)
- VC++调用libcurl开源库实现发送邮件的功能(附源码)
- C++中long long和long
- 【GPU】Nvidia CUDA 编程基础教程——异步流及 CUDA C/C++ 应用程序的可视化性能分析
- PAT 1117 C++版
- C++编程经验(11):std::function 和 bind绑定器
- C++编程经验(6):使用C++风格的类型转换