
【源码解读】BertLayer
源码 解读
2023-09-14 09:13:20 时间
总结
- 分析
BertLayer元的实现过程 - 此过程是
BERT源码分析的系列内容之一
1. 代码
先看一下整体的架构:
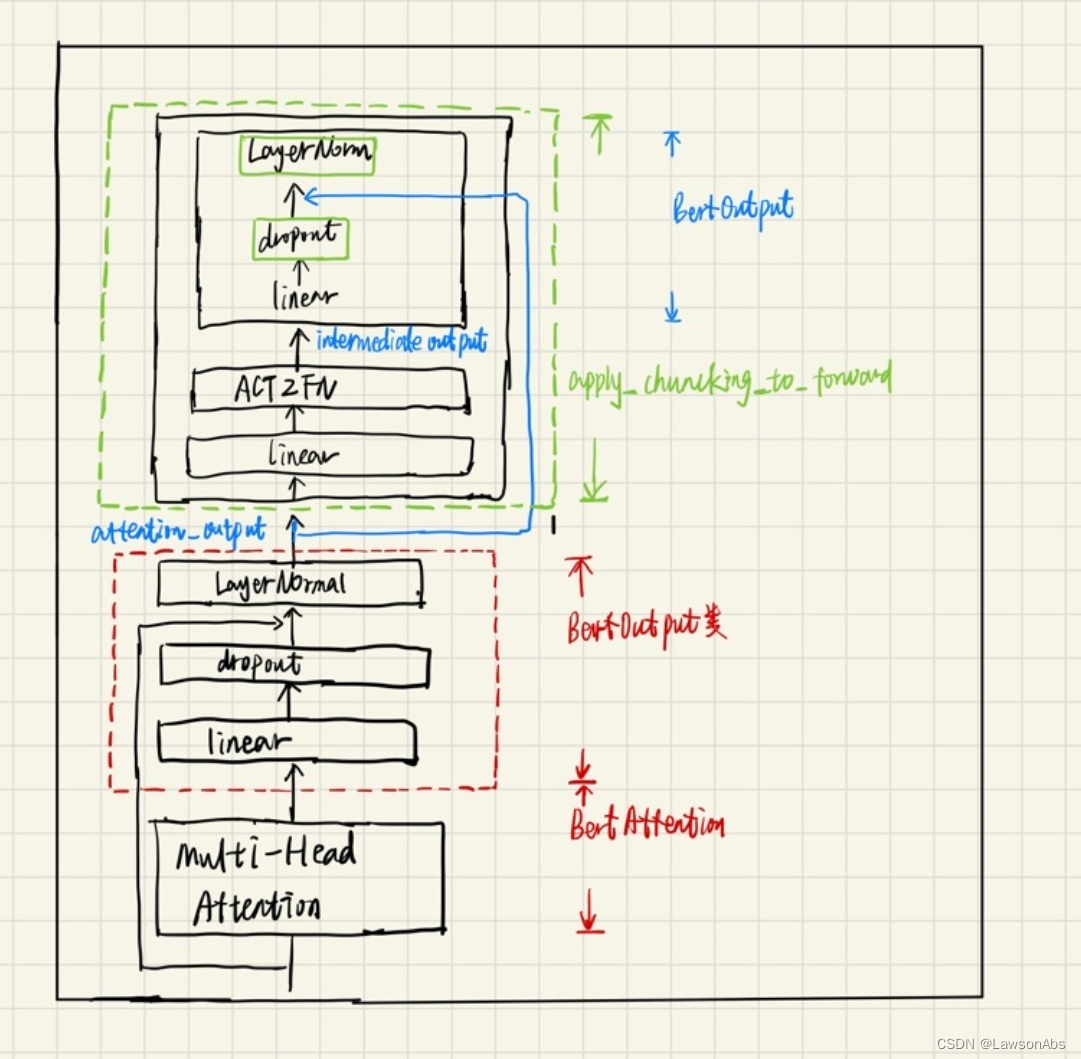
class BertLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = BertAttention(config) # 用于计算Attention 的部分
self.is_decoder = config.is_decoder # 判断是否是decoder
self.add_cross_attention = config.add_cross_attention # TODO?
if self.add_cross_attention:
assert self.is_decoder, f"{self} should be used as a decoder model if cross attention is added"
self.crossattention = BertAttention(config)
self.intermediate = BertIntermediate(config) # ?
self.output = BertOutput(config) # 对输出的处理
def forward(
self,
hidden_states, # 输入
attention_mask=None, # attention mask
head_mask=None, # ?
encoder_hidden_states=None, # ?
encoder_attention_mask=None, # ?
past_key_value=None, # ?
output_attentions=False, #是否输出 attention score 的值?
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None # ?
# 计算 attention 值
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0] # 得到了attention 后的输出
# 这个在仅用作编码器的时候用不着,暂不分析
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
# 其实这里的 self_attention_outputs[1:]是 attention score,所以这里的命名有点儿不合理~
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
# ... 不是decoder部分,直接忽略
# 对attention_output 做操作,后面详细解释一下这个操作是干嘛的
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
# 将最后的结果拼成一个tuple
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
# 返回
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
相关文章
- Netty源码解读(四)Netty与Reactor模式
- 【源码阅读】Mimikatz一键获取远程终端凭据与获取明文密码修改方法
- JUC回顾之-ConcurrentHashMap源码解读及原理理解
- 阿里 双11 同款,流量防卫兵 Sentinel go 源码解读
- Spring容器启动流程(源码解读)
- FIS源码解析-整体架构
- Twitter Storm中Bolt消息传递路径之源码解读
- 蚂蚁金服寒泉子:JVM源码分析之临门一脚的OutOfMemoryError完全解读
- MFC Windows 程序设计[291]之日志文件例程(附源码)
- MFC Windows 程序设计[145]之编辑框的样式(附源码)
- Opencv学习笔记 - imread源码解读
- SparkSubmit源码解读记录
- AQS源码
- Spring MVC注解Controller源码流程解析--映射建立
- spring-session源码解读-5
- android8.0 Launcher 源码---Launcher3的基础知识整体概述
- Android官方源码&&资料&&博客
- 第二人生的源码分析(七十六)判断程序运行多个实例
- 风格迁移0-07:stylegan-源码无死角解读(3)-generate网络框架总览
- BlockingQueue接口源码解读
- RCNN网络源码解读(Ⅲ) --- finetune训练过程
- ClickHouse管理工具—ckman教程(3)从ckman源码分析部署集群时的主要步骤
- tensordot 的源码解读