
python爬虫 --- 简书评论
2023-09-14 09:12:15 时间
某些网站的一些数据是通过js加载的 ,所以爬取下来的数据拿不到,
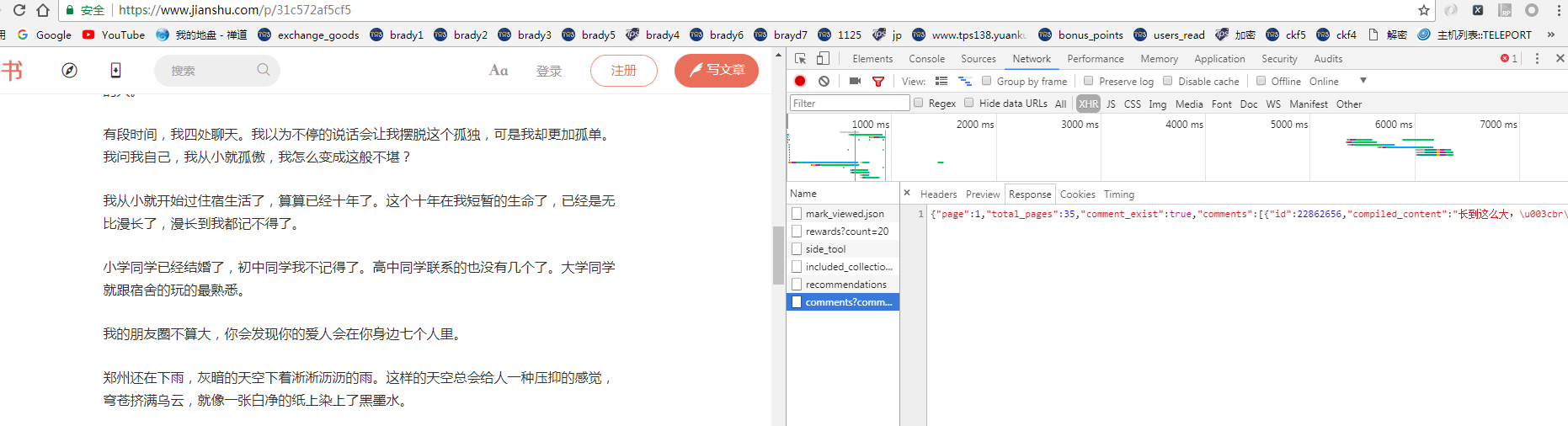
找到评论的地址 .进行请求获取评论数据
#coding=utf-8
import json
import requests
def requests_view(response):
import webbrowser
requests_url = response.url
base_url = '<head><base href="%s">' %(requests_url)
base_url = base_url.encode('utf-8')
content = response.content.replace(b"<head>",base_url)
tem_html = open('tmp.html','wb')
tem_html.write(content)
tem_html.close()
webbrowser.open_new_tab("tmp.html")
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
response = requests.get("https://www.jianshu.com/notes/26504955/comments?comment_id=&author_only=false&since_id=0&max_id=1586510606000&order_by=likes_count&page=1",headers=headers)
comments = json.loads(response.content)
if comments['comment_exist'] == True:
for item in comments['comments']:
print(item['user']['nickname'],item['compiled_content'])
相关文章
- python实现简单爬虫功能
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
- 【学习总结】GirlsInAI ML-diary day-2-Python版本选取与Anaconda中环境配置与下载
- Python 重解零基础100题(10)
- Python暴力破解受密码保护的zip/rar文件
- Python爬虫开发:cookie的使用案例
- Python语言学习:python语言代码调试—异常处理之详细攻略
- 成功解决File &quot;f:program filespythonpython36libre.py&quot;, line 142, in &lt;modul
- Python:利用python代码编程实现将视频的avi格式转换为MP4格式
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- 【python实战】以最快速度抢到回家的火车票!(附资源)
- Python文件操作:读取、打开、写入、关闭、按行读取、文件指针(附零基础学习资料)
- 数学建模学习(52):python图像亚元素最邻近插值,双线性插值,双三次插值
- 几种不同压缩与解压缩格式,Python都可轻松实现
- python性能测试值timeit的使用示例
- 【Python 八股文】- Nginx基础
- compute the su procedure time with python
- 雅虎财经数据python 网络爬虫stock股票 用 Python 通过雅虎财经获取股票数据
- python登录接口测试问题记录与解决 ( 干 货 )
- 【Leetcode刷题Python】134. 加油站
- Python解决爬虫中文返回乱码问题
- 【异常】前端ERR! stack Error: Can‘t find Python executable “python“, you can set the PYTHON env variable.
- 【python】Python实现网络爬虫demo实例
- 【Python 实战】---- 使用 RemoveBg 实现一键批量抠图
- Python爬虫编写乱码问题、验证码登录问题和IP代理问题解决