
yarn架构——本质上是在做解耦 将资源分配和应用程序状态监控两个功能职责分离为RM和AM
Hadoop YARN架构解读
原Mapreduce架构
原理
架构图如下:

原 MapReduce 程序的流程:
首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job
Tracker 中,Job Tracker需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有
job 失败、重启等操作。
TaskTracker 是 Map-reduce
集群中每台机器都有的一个部分,它的职责有两个:一是监视自己所在机器的资源情况,二是监视当前机器的 tasks 运行状况。TaskTracker
需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job
分配运行在哪些机器上。上图虚线箭头就是表示消息的发送 - 接收的过程。
存在的问题
- JobTracker单点故障。
- JobTracker的管理负荷过大,业界普遍认可的并行节点上限是4000。
- TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现资源枯竭。
其他问题摘抄如下:
在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
从 操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应 用程序是不是适用新的 Hadoop 版本而浪费大量时间。
一句话总结:JobTracker干的事儿太多了。
YARN架构
架构图如下:

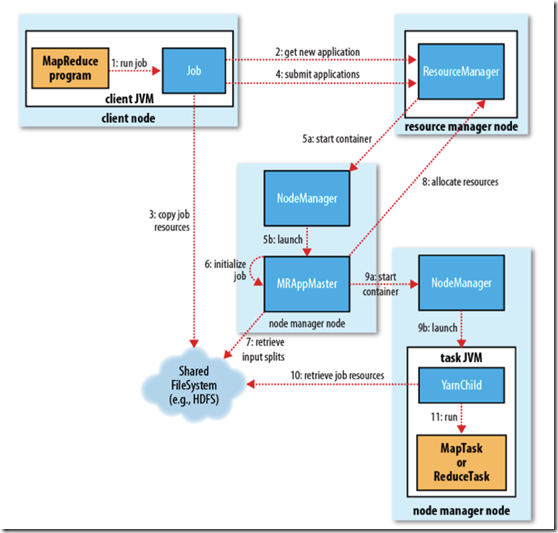
基本思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。
ResourceManager
管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的
MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager
和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。NodeManager
是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
架构变化的总结
原来的JobTracker和TaskTracker是从物理节点的角度来设置,但每个
节点内部还包括资源监控、任务调度的功能。改版之后,从逻辑上进行功能模块设计,ResourceManager专门负责管理和分配资
源,NodeManager是RM在各节点上的代理,每个应用有一个ApplicationMaster,但不放在RM节点上,而是分布式存放,用来管理
应用在各节点上的运行、向RM申请资源。这样,原来JobTracker被分解为两个功能模块,并且不在同一个节点上运行,自然降低了RM节点(原
JobTracker节点)的管理负荷。
摘自:http://www.jianshu.com/p/3b9179534127
相关文章
- 使用篇丨链路追踪(Tracing)很简单:链路实时分析、监控与告警
- url拨测,url访问检测,监控网站url是否正常
- centos8平台使用mpstat监控cpu
- 监控系统设计思路
- 通过JMX监控Spring Boot应用
- 一个简单的小技巧,监控网页所有动态标签创建的调用处
- ML:MLOps系列讲解之《MLOps原则之监控/“机器学习成绩”系统/可再现性/松散耦合架构(模块化)/基于ML的软件交付指标/MLOps原则和实践的总结》解读
- 【架构实践】业务全链路实时质量监控平台的落地与实践
- 【架构实践】怎样具体实现一个实时业务质量监控平台?
- y73.第四章 Prometheus大厂监控体系及实战 -- blackbox exporter安装和grafana安装(四)
- zabbix 添加你需要监控的主机
- Zabbix监控系统架构原理(一)
- 打造云原生大型分布式监控系统(二): Thanos 架构详解
- 打造云原生大型分布式监控系统(一): 大规模场景下 Prometheus 的优化手段
- 16个Linux服务器监控命令