
bert预训练代码
2023-09-14 09:11:22 时间
1.输入emb层
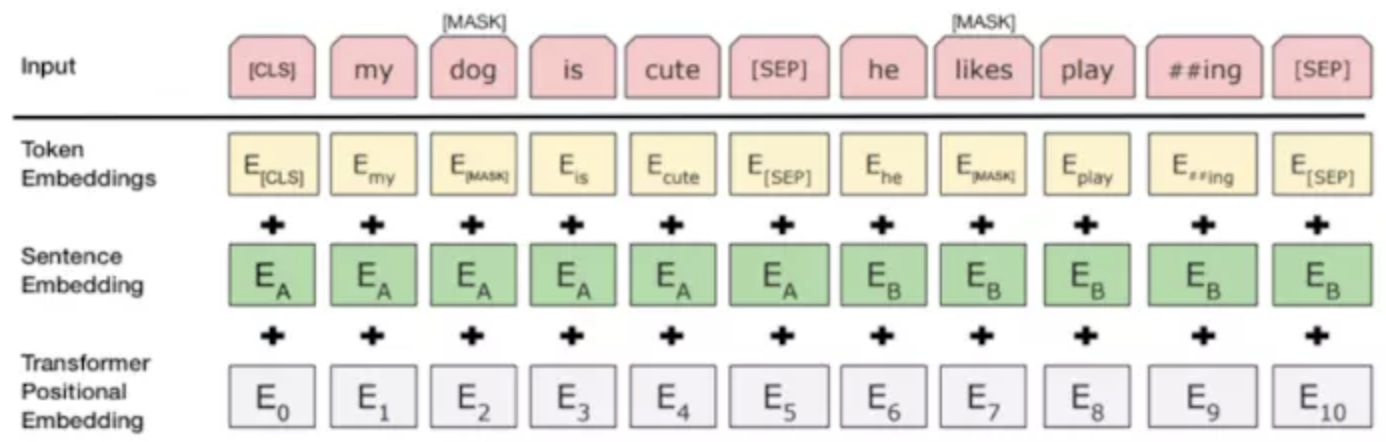
在modeling.py文件中,首先对token进行emb词向量查询

然后进行emb后处理,获取sentence emb/位置emb:
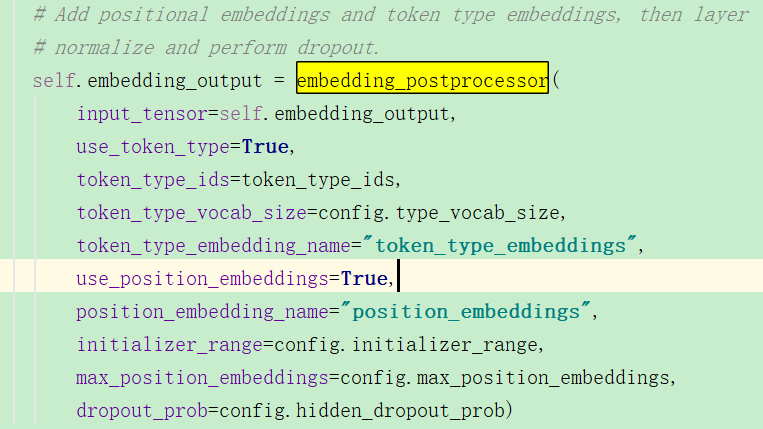
sentence emb也就是segment emb,即不同句子的初始化嵌入向量:

下面是pos emb:
https://blog.csdn.net/Kaiyuan_sjtu/article/details/90265473
注意,在Transformer论文中的position embedding是由sin/cos函数生成的固定的值,而在这里代码实现中是跟普通word embedding一样随机生成的,可以训练的。作者这里这样选择的原因可能是BERT训练的数据比Transformer那篇大很多,完全可以让模型自己去学习。
https://blog.csdn.net/Kaiyuan_sjtu/article/details/90288178,关于处理输入的部分。
https://blog.csdn.net/Kaiyuan_sjtu/article/details/90298807,任务训练的目标函数
3.2个任务
get_masked_lm_output:
#就是每一个word在encoder之后都会有一个输出,根据这个和那些mask掉的做标记,经过softmax计算损失,其实这个还蛮好理解的。
get_next_sentence_output:
#输入为BertModel的最后一层pooled_output输出([batch_size, hidden_size]),
# 因为该任务属于二分类问题,所以只需要每个序列的第一个token【CLS】即可。
0表示是next 句子,1 表示是随机选择的句子。
相关文章
- Java实现 蓝桥杯 算法训练VIP 报数(暴力+数学)约瑟夫环问题
- Java实现蓝桥杯VIP 算法训练 阶乘末尾
- java实现 蓝桥杯 算法训练 操作格子
- Java实现 蓝桥杯VIP 算法训练 一元三次方程
- Java实现 蓝桥杯VIP 算法训练 完数
- Java实现 蓝桥杯 算法训练 约数个数
- Java实现 蓝桥杯 算法训练 前缀表达式
- 机器学习笔记 - 学习使用dlib训练自定义特征预测器
- ML之R:回归预测任务之模型训练部分代码案例—单个模型推理并输出、各个模型基于单个参数训练调优、选择几个最佳模型再进行交叉训练确保模型稳定性实习代码
- ML之FE:数据处理—特征工程之数据集划分成训练集、验证集、测试集三部分简介、代码实现、案例应用之详细攻略
- ML之R:回归预测任务之模型训练部分代码案例—单个模型推理并输出、各个模型基于单个参数训练调优、选择几个最佳模型再进行交叉训练确保模型稳定性实习代码
- ML之xgboost&GBM:基于xgboost&GBM算法对HiggsBoson数据集(Kaggle竞赛)训练(两模型性能PK)实现二分类预测
- 云上人替代方案训练代码
- 遗传和基因突变对神经网络训练的好处
- 若使用numba.cuda.jit加速pytorch训练代码会怎样
- pytorch训练模型代码的关机几步
- MMDetection实战:MMDetection训练与测试
- 训练千亿参数模型的法宝,昇腾CANN异构计算架构来了~
- 代码实战带你了解深度学习中的混合精度训练
- 【回答问题】ChatGPT上线了!写出coco数据集的图像分类训练和预测函数代码?
- RL之SARSA:利用强化学习之SARSA实现走迷宫—训练智能体走到迷宫(复杂陷阱迷宫)的宝藏位置
- 〖产品思维训练白宝书 - 产品思维认知篇⑧〗- 产品经理 日常面临的问题有哪些?
- pytorch 多卡训练,模型保存的一些问题
- 阿里巴巴开源大规模稀疏模型训练/预测引擎DeepRec