
关于范数【转载】
转自:https://blog.csdn.net/zouxy09/article/details/24971995
从这一篇中了解了:
-》机器学习的目的就是为了拟合数据,不仅是训练数据集,更是测试集,使拟合误差最小,但可能出现过拟合,所以需要正则化;
-》 正则化其中一条是使优化过程变得稳定快速,矩阵条件数(应该是输入矩阵X)对w的求解有较大影响。
-》L1范数与L2范数的差别。L1被称为Lasso,L2被称为Ridge。
-》使用L1是对特征进行选择,会产生较多0值,但是L2更多只是对特征进行。
L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
-》低秩矩阵的应用,强健PCA,A=低秩+噪声矩阵
-》PCA就是使用另一组基重新描述数据,并且能够尽可能揭示原有数据的关系。
——
这篇文章讲的真的相当好。
2020-5-10周日更新——————
再来看上面讲的,有点搞不懂了,好理论化,理解不了了,先不理解了。
1.范数公式
https://www.jianshu.com/p/6cf5d60db634
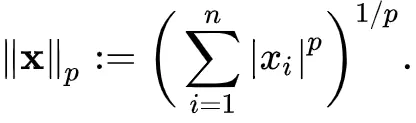
L1即曼哈顿距离,L2即欧几里得距离。
但是我们常用的MSE是L2的平方,MSE是没有根号的,要不然反向传播计算梯度也太麻烦了。
2.L1对应的损失函数
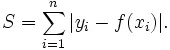
least absolute deviation (LAD,最小绝对偏差)
2020-6-21更新——————
1.L1范数的作用
L1范数是指向量中各个元素绝对值之和,也叫“稀疏规则算子”(Lasso regularization)。
为什么想要特征稀疏?
在特征量很多的情况下,稀疏就可以自动地进行特征选择,被选择的特征权重不为0,选择了特征之后就可以使模型的可解释性增强。
2.L1为什么使特征稀疏?
https://www.zhihu.com/question/37096933,其中一个回答的很好,有三个角度来看:
l1 相比于 l2 为什么容易获得稀疏解? - ser jamie的回答 - 知乎 https://www.zhihu.com/question/37096933/answer/475278057
从优化的角度:

从梯度的角度来看:

从概率角度来看:
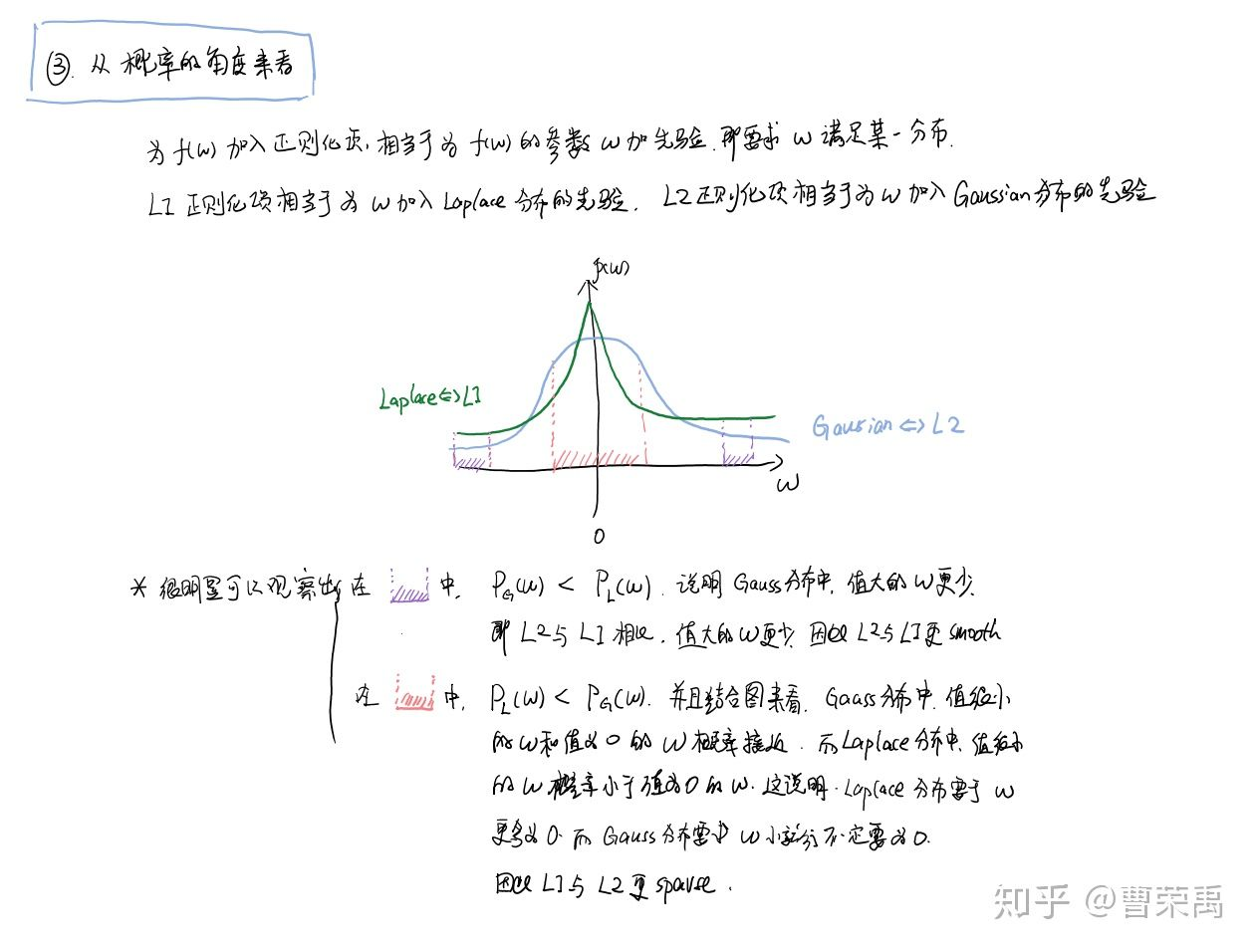
(但是这个我不清楚为什么分别就是拉普拉斯和高斯分布了?)
3.L2范数的作用
在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦。(我看了Ng的课程里提到的,是因为如果使得系数变小的话,那么输入进激活函数的就比较小,如果使用tanh这样的激活函数的话,就接近于线性,降低了模型的复杂度。)
- 从学习理论的角度来说,L2范数可以防止过拟合,提升模型的泛化能力。
- 从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题。
对condition number来个一句话总结:conditionnumber是一个矩阵(或者它所描述的线性系统)的稳定性或者敏感度的度量,如果一个矩阵的condition number在1附近,那么它就是well-conditioned的,如果远大于1,那么它就是ill-conditioned的,如果一个系统是ill-conditioned的,它的输出结果就不要太相信了。(输出结果就会十分不稳定)
4.L1和L2的区别
下降速度不同,在0的部分L1更快,还有一个空间的理解:
(我觉得实在是抽象,为什么L1就是菱形了?L2就是圆形了?)

在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解。
L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交,相较于坐标轴上。注意到在角的位置就会产生稀疏性。
(这里ball是什么意思啊?)而且菱形/圆形/等高线,这都代表什么???(这张图确实是很经典,但是具体怎么理解呢?)
这个讲的不错,对图有了更加清晰的说明:
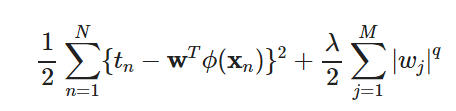



那么下图中蓝色的线表示,没有正则化项限制的损失函数寻找最优值,随着w不断迭代的变化情况,用等高线来表示。黄色区域是对w解的限制。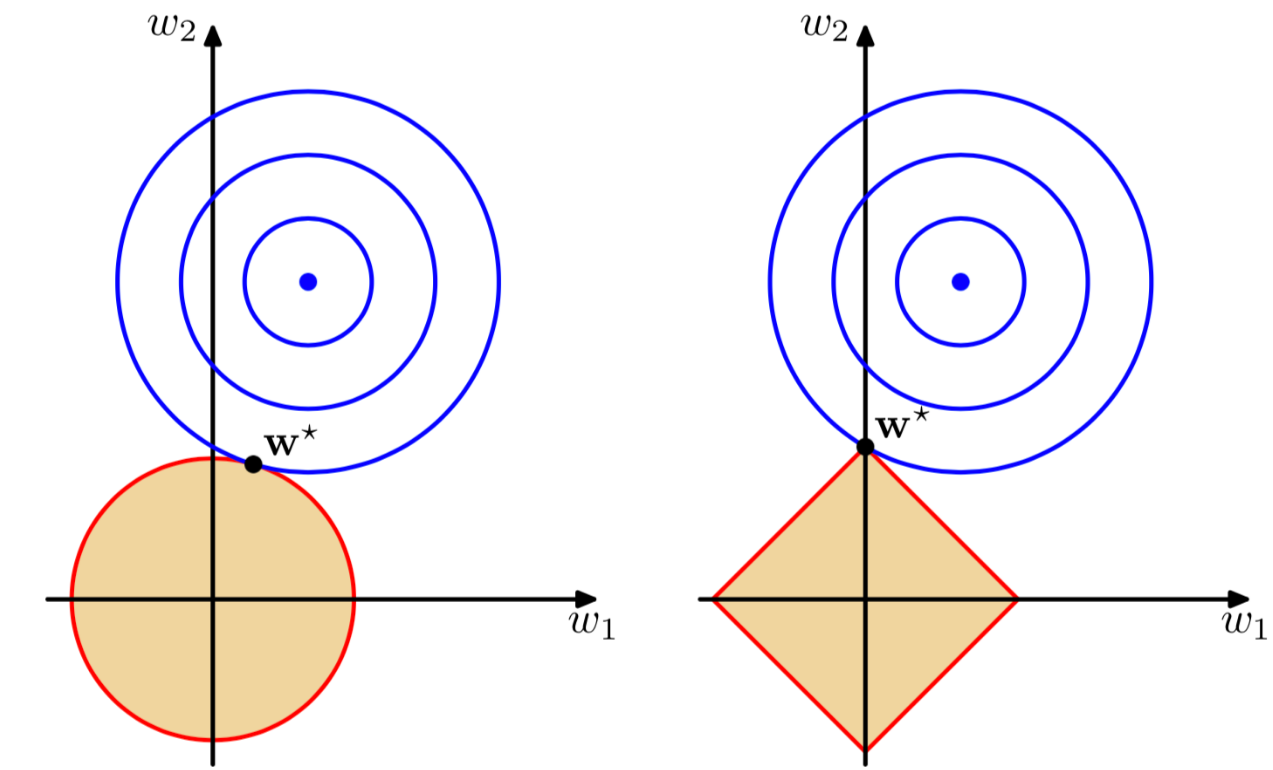
蓝色的线表示损失,那么应该使越往外围损失越大的,所以最好是两者相切。我们的目标函数(误差函数)就是求蓝圈+红圈的和的最小值(回想等高线的概念并参照3式),而这个值通在很多情况下是两个曲面相交的地方。
L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
相关文章
- 关于对自动化测试的理解:目的与本质!(新手必看)
- Apache配置虚拟主机,关于403问题的解决
- 关于 SAP UI5 Device API 的使用介绍
- 关于博客评论插件的讨论
- Python 工匠:一个关于模块的小故事
- 关于伪静态的实现方法
- vue2.0中关于active-class
- 关于Linux挂载 /etc/fstab 和 systemd.mount 使用场景的一些笔记
- 关于M3U8应该知道的一切
- Linux 时钟同步服务关于服务端器和客户端的设置
- SAP中关于用户IP信息的获取(转载)详解编程语言
- 关于微软停止移植 Android 应用的几点思考
- Oracle对DML语句的全面洞察(oracle关于dml)
- 关于《精通css》之几个不错的注意事项
- 关于C#基础知识回顾--反射(二)