
用Locust做性能测试是一种什么样的体验?
01、Locust介绍
Locust 一个开源性能测试工具,使用Python代码来定义用户行为,用它可以模拟百万计的并发用户访问你的系统。
性能工具对比:
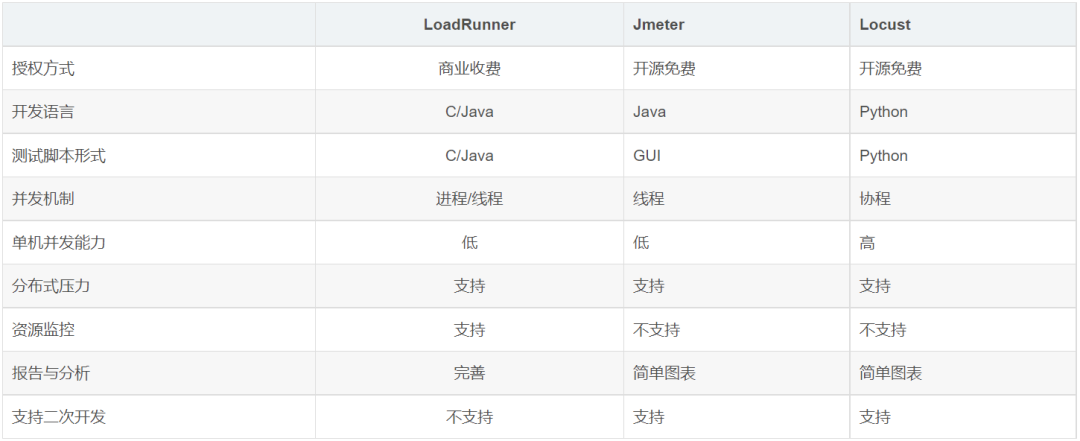
LoadRunner 是非常有名的商业性能测试工具,功能非常强大。使用也比较复杂,目前大多介绍性能测试的书籍都以该工具为基础,甚至有些书整本都在介绍 LoadRunner 的使用。
Jmeter 同样是非常有名的开源性能测试工具,功能也很完善,它可以作为接口测试工具的使用。但实际上,它是一个标准的性能测试工具
Locust 同样是性能测试工具,虽然官方这样来描述它 “An open source load testing tool.” ,但其它和前面两个工具有着较大的不同。相比前面两个工具,功能上要差上不少,但它也并非优点全无。
-
Locust 完全基于 Python 编程语言,采用 Pure Python 描述测试脚本,并且 HTTP 请求完全基于 Requests 库。除了 HTTP/HTTPS 协议,Locust 也可以测试其它协议的系统,只需要采用Python调用对应的库进行请求描述即可。
-
LoadRunner 和 Jmeter 这类采用进程和线程的测试工具,都很难在单机上模拟出较高的并发压力。Locust 的并发机制摒弃了进程和线程,采用协程(gevent)的机制。协程避免了系统级资源调度,由此可以大幅提高单机的并发能力。
02、Locust安装
pip安装
pip install locust源码安装
git clonehttps://github.com/locustio/locust/
cd locust
python setup.py install03、创建性能测试
01、编写简单脚本
from locust import HttpLocust, TaskSet, task
# 定义用户行为
class UserBehavior(TaskSet):
# 任一测试用例执行前均会执行一次
def on_start(self):
print('开始性能测试')
@task(1)
# 表示一个用户为行,访问百度首页。使用 @ task装饰该方法为一个事务。client.get()用于指请求的路径“ / ”,因为是百度首页,所以指定为根路径。
def index(self):
self.client.get("/")
@task(2) # task()参数用于指定该行为的执行权重。参数越大每次被虚拟用户执行的概率越高。如果不设置默认为1。
def index2(self):
self.client.get(
"/s?wd=locust&rsv_spt=1&rsv_iqid=0xbb8514200006b7d0&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=8&rsv_sug1=9&rsv_sug7=101&rsv_sug2=0&inputT=1458&rsv_sug4=1911&rsv_sug=2")
# 用于设置性能测试
class WebsiteUser(HttpLocust):
# 指向一个定义的用户行为类。
task_set = UserBehavior
# 执行事务之间用户等待时间的下界(单位:毫秒)。如果TaskSet类中有覆盖,以TaskSet 中的定义为准。
min_wait = 3000
# 执行事务之间用户等待时间的上界(单位:毫秒)。如果TaskSet类中有覆盖,以TaskSet中的定义为准。
max_wait= 6000
# 设置 Locust 多少秒后超时,如果为 None ,则不会超时。
stop_timeout = 5
# 一个Locust实例被挑选执行的权重,数值越大,执行频率越高。在一个 locustfile.py 文件中可以同时定义多个 HttpLocust 子类,然后分配他们的执行权重
weight = 3
# 脚本指定host执行测试时则不在需要指定
host = "https://www.baidu.com"02、执行测试
1、web执行
启动服务
locust -f test.py --host=https://www.baidu.com
locust -f test.py # 如果脚本中已经指定host,则不需要再次指定
-
-f:指定性能测试脚本文件
-
–host:指定被测试应用的URL的地址,注意访问百度使用的HTTPS协议
执行测试
通过浏览器访问:http://localhost:8089(Locust启动网络监控器,默认为端口号为: 8089)
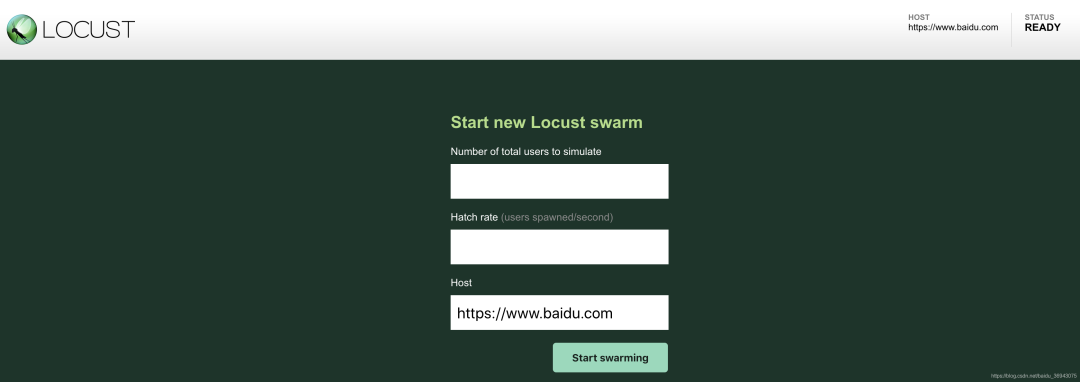
Number of users to simulate 设置模拟用户数
Hatch rate(users spawned/second) 每秒产生(启动)的虚拟用户数
点击 “Start swarming” 按钮,开始运行性能测试

结果说明
-
Type:请求的类型,例如GET/POST
-
Name:请求的路径。这里为百度首页,即:https://www.baidu.com/
-
request:当前请求的数量
-
fails:当前请求失败的数量
-
Median:中间值,单位毫秒,一半的服务器响应时间低于该值,而另一半高于该值
-
Average:平均值,单位毫秒,所有请求的平均响应时间
-
Min:请求的最小服务器响应时间,单位毫秒
-
Max:请求的最大服务器响应时间,单位毫秒
-
Content Size:单个请求的大小,单位字节
-
reqs/sec:是每秒钟请求的个数
2、no-web执行
locust -f test.py --host=https://www.baidu.com --no-web -c 10 -r 2 -t 1m
locust -f test.py --no-web -c 10 -r 2 -t 1m # 如果脚本中已经指定host,则不需要再次指定
-
–no-web:表示不使用Web界面运行测试
-
-c:设置虚拟用户数
-
-r:设置每秒启动虚拟用户数
-
-t:设置设置运行时间
关闭服务可直接Ctrl+C
03、分布式运行
一旦单台机器不够模拟足够多的用户时,Locust支持运行在多台机器中进行压力测试。
为了实现这个,你应该在 master 模式中使用–master标记来启用一个 Locust 实例。这个实例将会运行你启动测试的 Locust 交互网站并查看实时统计数据。master 节点的机器自身不会模拟任何用户。相反,你必须使用 --slave 标记启动一台到多台 Locustslave 机器节点,与标记 --master-host 一起使用(指出master机器的IP/hostname)。
常用的做法是在一台独立的机器中运行master,在slave机器中每个处理器内核运行一个slave实例。
注意:master 和每一台 slave 机器,在运行分布式测试时都必须要有 locust 的测试文件
在 master 模式下启动 Locust:
locust -f my_loucstfile.py --master
在每个 slave 中执行(192.168.0.14 替换为你 master 的IP):
locust -f my_locustfile.py --slave --master-host=192.168.0.14
参数说明
--master 设置 Locust 为 master 模式。网页交互会在这台节点机器中运行。
--slave 设置 Locust 为 slave 模式。
--master-host=X.X.X.X 可选项,与 --slave 一起结合使用,用于设置 master 模式下的 master 机器的IP/hostname(默认设置为127.0.0.1)
--master-port=5557 可选项,与 --slave 一起结合使用,用于设置 master 模式下的 master 机器中 Locust 的端口(默认为5557)。注意,locust 将会使用这个指定的端口号,同时指定端口+1的号也会被占用。因此,5557 会被使用,Locust将会使用 5557 和 5558。
--master-bind-host=X.X.X.X` 可选项,与 --master 一起结合使用。决定在 master 模式下将会绑定什么网络接口。默认设置为*(所有可用的接口)。
--master-bind-port=5557 可选项,与 --master 一起结合使用。决定哪个网络端口 master 模式将会监听。默认设置为 5557。注意 Locust 会使用指定的端口号,同时指定端口+1的号也会被占用。因此,5557 会被使用,Locust 将会使用 5557 和 5558。
--expect-slaves=X 在 no-web 模式下启动 master 时使用。master 将等待X连接节点在测试开始之前连接。
04、权重分配
Locust支持同一脚本中使用权重的方式达到用例被执行频率不同的问题(例如用户流失,浏览用户100人,注册只有50人),不同于Jmeter、LandRunner权重分配方式并不是标准的比例。
权重1 - task
# -*- coding: utf-8 -
from locust import HttpLocust, TaskSet, task
class TestLocust(TaskSet):
def on_start(self):
print('开始性能测试')
@task(1)
def test_demo_get1(self):
self.client.get(url="/mock_server/configs/info")
@task(2)
def test_demo_get2(self):
self.client.get("/mock_server/mock/show_lists")
class Query(HttpLocust):
task_set = TestLocust
min_wait = 1000
max_wait = 3000
host = http://localhost:5000
方法的参数用于指定该行为的执行权重。参数越大每次被虚拟用户执行的概率越高。如果不设置默认为1。
权重2 - weight
# -*- coding: utf-8 -
from locust import HttpLocust, TaskSet, task
class TestLocust(TaskSet):
def on_start(self):
print('开始性能测试')
@task
def test_demo_get(self):
self.runLocust(demoGet.demo_get())
class TestLocust2(TaskSet):
def on_start(self):
print('开始性能测试')
@task
def test_demo_post(self):
page_num, num = 10, 1
self.runLocust(demoPost.demo_post(page_num, num))
class QueryOne(HttpLocust):
task_set = TestLocust
min_wait = 1000
max_wait =3000
weight = 1
host = http://localhost:5000
class QueryTwo(HttpLocust):
task_set = TestLocust2
min_wait = 1000
max_wait = 3000
weight = 3
host = http://localhost:5000
执行语句不同
locust -f test.py QueryOne QueryTwo
weight
一个Locust实例被挑选执行的权重,数值越大,执行频率越高。在一个 locustfile.py 文件中可以同时定义多个 HttpLocust 子类,然后分配他们的执行权重
05、参数化
参数化首先需要清楚locust的执行逻辑,定义的用户行为下带有task装饰器的函数才会被协程不断的执行
from locust import HttpLocust, TaskSet, task
from random import randint
data1 = randint(1, 3)
# 定义用户行为
class UserBehavior(TaskSet):
def on_start(self):
print('开始性能测试')
@task(1)
def index(self):
print(data1)
self.client.get("/")
@task(2)
def index2(self):
data2 = randint(1, 3)
print(data2)
self.client.get(
"/s?wd=locust&rsv_spt=1&rsv_iqid=0xbb8514200006b7d0&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=8&rsv_sug1=9&rsv_sug7=101&rsv_sug2=0&inputT=1458&rsv_sug4=1911&rsv_sug=2")
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 3000
max_wait = 6000
stop_timeout = 5
weight = 3
host = "https://www.baidu.com"

根据打印的结果就可以看出,data1被设为了全局变量,无论怎么多次执行值都不会变;data2被设为函数变量,因为每次执行该函数(接口进行一次请求),该变量都会重新执行发生变化。
因此,如果接口需要参数不重复,将该参数的生成方法写在执行函数中即可;如果接口需要的参数保持不变,将该参数写为全局变量即可
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走

这些资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助…….关注下方我的微信公众号【程序员小濠】免费获取~
相关文章
- 【Pyhon】利用BurpSuite到SQLMap批量测试SQL注入
- PHP打印测试,PHP调试技巧
- [eMMC]eMMC读写性能测试
- 敏捷自动化测试(4)——围绕自动化测试开展持续集成(转)
- android CTS测试
- Testing - 软件测试知识梳理 - 软件性能测试
- vps性能测试脚本
- 自动化测试:behave
- paip.mysql 性能测试 报告 home right
- 性能测试 查看Android APP 帧数FPS的方法
- junit结合spring-test里的MockMvc来测试SpringMvc接口方法
- AXI VDMA回环测试
- 一次完整的性能测试,测试人员需要做什么?
- 测试小故事97:懒人法则
- Jmeter-什么是性能测试 负载测试 压力测试
- 接口测试与接口性能测试总结
- 自动化测试基础知识,你想要的这里都有
- 【软件测试】性能测试中,最常遇到的8个问题总结
- 阿里6年测试经验,4个步骤教你入门自动化测试(建议收藏)
- 要做接口并发性能测试,总得先学会分析吧!
- 接口测试之postman使用
- 一篇文章搞懂什么是测试,测试是干什么的?
- Jmeter性能测试 ——Jmeter使用中的一些问题
- 为什么我建议你一定要会性能测试?因为平均月薪16K!
- django gunicorn 各worker class简单性能测试
- 行人重识别02-09:fast-reid(BoT)-pytorch编程规范(fast-reid为例)6-模型测试评估-1
- TDengine 发布主流时序数据库对比分析报告,与 InfluxDB、TimescaleDB 展开全面对比测试
- 全国大学生软件测试大赛web性能测试
- ubuntu 搭建 DVWA web渗透测试系统
- Jmeter性能测试系列-性能测试需求评审
- 性能测试入门学习 ----- loadrunner常用函数大全及设置项