
【FPGA/数字IC】加法器总结
半加器
半加器的输入为两个1bit信号A,B,输出为它们的和S以及进位标志位C
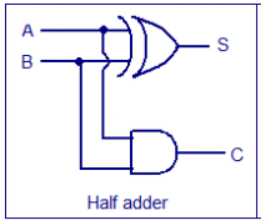
其真值表如下表所示
| A | B | S | C |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
由此可得其逻辑表达式为 S = A ⨁ B , C = A B S=A\bigoplus B,C=AB S=A⨁B,C=AB
全加器
全加器相比于半加器,输入多了一个进位信号。门电路图如下

真值表为
| A i A_i Ai | B i B_i Bi | C i − 1 C_{i-1} Ci−1 | S i S_i Si | C i C_i Ci |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
因此,可以得到全加器的逻辑表达式为
S
i
=
A
i
⨁
B
i
⨁
C
i
−
1
S_i=A_i\bigoplus B_i\bigoplus C_{i-1}
Si=Ai⨁Bi⨁Ci−1
C
i
=
A
i
B
i
+
C
i
−
1
(
A
i
+
B
i
)
C_i=A_iB_i+C_{i-1}(A_i+B_i)
Ci=AiBi+Ci−1(Ai+Bi)
等波纹进位加法器(Ripple carry adder circuit)
即将多个全加器串联起来形成的加法器(上一级的进位输出接下一级的进位输入),它可以计算多比特数据的加法运算。下图是一个4bit的等波纹进行加法器

可以看到,第i级全加器计算A的第i位和B的第i位的和,同时,第1级全加器的进位输入为0。尽管这种方法可以计算多比特数据的加法操作,但随着加法器位数的增加,其延迟也会不断增大。
进位选择加法器
以32位加法器为例,如果采用等波纹进位加法器,那么前16bit的进位输出需要接到后16bit的进位输入,这会造成较大的延迟。另一种方法如下所示:

我们同时计算低16bit的加法和高16bit的加法,高16bit的加法运算,我们一共设置了两个加法器,一个是假设进位输入为0,另一个假设进位输入为1,这两个加法器的和送入一个MUX多路选择器,而具体输入哪一位,则由低16bit加法器的进位输出决定,最后,MUX的输出和低16bit加法器的输出S进行位宽拼接,得到最终的结果。
这个方法有效降低了加法的延迟(接近2倍),代价是浪费了一些资源,这很好的体现了FPGA/IC设计中面积换速度的思想。
串行加法器
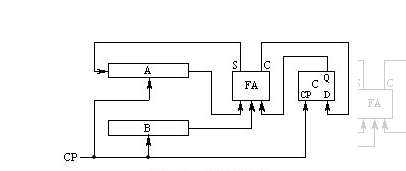
如图所示,串行加法器仅仅使用一个全加器即可完成任意位宽的加法运算。其具体的操作过程如下(FA为全加器):
第i个时钟周期,全加器的输入端分别输入A的第i位,B的第i位和上一个时钟周期的进位输出Cin,然后将输出S作为结果的第i位存储下来,同时进位输出信号Cout输入触发器,作为下一个时钟周期的进位输入。由此可见,一个N位的加法运算,需要N个时钟周期才能完成,该方法的优点是资源占用非常小,但延迟很大。
超前进位加法器(Carry-Lookahead Adder,简称CLA)
我们知道,等波纹进位加法器的延迟比较高,是因为它每一级加法器的进位输入必须等上一级的进位输出有效才行,解决这个依赖问题的方法就是CLA:
首先列出全加器的逻辑表达式

有了这个
C
i
+
1
和
C
i
C_{i+1}和C_i
Ci+1和Ci的递推关系,我们可以得到:

下图是CLA的一个电路图

可以看到,CLA在计算延迟上面十分有优势,但其缺点是随着加法器位宽的增加,电路将会变得非常复杂。
附录
相关文章
- 【002】数字IC笔面试常见题
- 【009】数字IC笔面试常见题
- 高抗干扰低功耗 LCD液晶显示驱动控制电路(IC)-VK2C21A/B/C/D 替代市面16C21,用于仪器仪表/机车/家电等抗干扰面板显示
- 腾讯美团内部反腐;无人驾驶范围将扩至500平方公里;中国台湾IC芯片出口连续七年增长丨每日大事件
- 深入了解IC内部结构(80页PPT)
- 2023届数字IC面经 | 双非机械秋招经验
- 2023届数字IC面经 | 双非科班如何斩获数字后端offer?
- IC面试:你很优秀,但是对不起
- 中国IC设计企业已达3243家:仅566家销售额过亿元!
- FS68001A是一款5W无线充发射IC方案
- 抗干扰LCD驱动芯片VK1621B-SSOP48-LQFP44液晶驱动IC资料
- 编辑软件IC软件下载 一键下载+安装教程 Adobe InCopy CC2022 Ic软件
- AP2403 DC-DC降压恒流IC 12-80V LED电动摩托车灯方案
- 富士康与国巨成立合资公司国瀚半导体 初期锁定2美元以下小IC
- 华为自研40nm OLED驱动IC芯片:或由中芯国际代工