
企业智能转型对AI技术的挑战及应对,答案是MLOps
企业智能转型对AI技术的挑战及应对,答案是MLOps
前言:笔者在参加12月20日举行的,由LF AI & Data基金会和OpenI启智社区联合举办的2021新一代人工智能院士高峰论坛上分享对于企业智能转型,以及AI技术面临的挑战和应对。
首先什么是企业智能转型?
笔者认为企业智能转型是企业数字化转型的一个较高的阶段,是AI在企业的大规模应用,不是单纯的人脸识别、OCR、语言识别等单个场景的落地,而是用AI来彻底改变企业的核心业务流。达到的效果是:或者彻底改变企业的商业模式,或者在核心效率上有巨大的提升,从而达到企业智能转型的目的。举个例子来说,对于一个连锁餐饮消费企业,它的核心业务流程包括选门店地址、选择商品品类、总店对分店进行铺货和补货、商品促销和线上推荐等,这条核心流程上的多个场景,都采用AI的技术进行优化和重整,从而在多个场景上都取得效率的较多或者较少的提升,累加起来就是效率的巨大提升,从而跟竞争对手相比建立起较大的竞争优势,达到了智能转型的目的。
第四范式在长期帮助多家企业进行智能转型的过程中,形成了自己独特的企业智能转型方法论—从量变到质变。
把企业的智能转型分成如下循环的四步:
- 识别企业当前的核心痛点
- 分析痛点相关的核心业务流程(包含多个场景)
- 在多个场景落地AI并不断提升效果
- 多个效果提升累计产生质变
然后再进行新的分析,痛点有可能变为另外一个,然后按照上述四步依次进行。
那么,企业智能转型对技术的需求是什么呢?
简单来说就是机器学习技术在企业在核心业务流相关的场景上“多、快、好、省”的落地:
- 多:围绕关键业务流程落地多个场景
- 快:每个场景落地时间短,迭代速度快
- 好:每个场景的效果都达到预期
- 省:每个场景落地成本比较节省,符合预期
但是AI在企业落地的实际情况是:
- 落地慢: 往往一个模型落地时间是实验室模型调优完成的数倍以上。一个AI科学家在一次分享会上感叹:”It took me 3 weeks
to develop the model. It has been >11 months, and it is still not
deployed.”事实上,根据某分析机构2018年的报告显示,89%以上的模型从来就没有完成线上部署,即没有产生实际效果。 - 效果不达预期:一些模型在线下训练的时候效果很好,各种指标都符合预期,但是当模型被部署到线上,对接真实的线上数据来提供预测服务的时候,发现效果大打折扣。
- 效果还会回退:一个模型上线后一段时间内效果还可以,但是随着时间推移,效果越来越差,最后导致该模型完全不可用。举个例子,随着新冠疫情发生,某国金融系统几乎所有的风控模型全部失效,因为新冠疫情导致人们的购物习惯发生了极大改变,很多不喜欢网络购物的人们都被逼进行网络购物,导致根据疫情前人们消费习惯进行建模的风控模型,完全不能体现当前规律,所以全面失效。
为什么? 因为在一个生产环境中运行的机器学习系统,机器学习模型相关的代码只占很小很小的部分,大约5%。

此图来自NIPS 2015一篇著名的论文 “Hidden Technical Debt in Machine Learning Systems“。Google的几位机器学习的专家在该论文阐述机器学习中的种种技术问题,ML Code只占整个系统极小的部分。
而我们都知道AI System = Code + Data. Data在机器学习中非常重要,但又是相当难的一个部分。“Data is the hardest part of ML and the most important piece to get right… Broken data is the most common cause of problems in production ML systems”.
—from Uber
这是Uber的机器学习工程师在一篇很有名的博客中提到的。
Data有如下问题和挑战,笔者简单列举了一些:
Scale: 海量的data for training
Low Latency:高QPS低延迟的serving
Data change cause model decay: World change
Time Travel:时序特征数据处理容易出问题
Training/Serving skew:训练和预测使用的数据不一致
还有,Live Data给这些问题提出了更多的挑战。
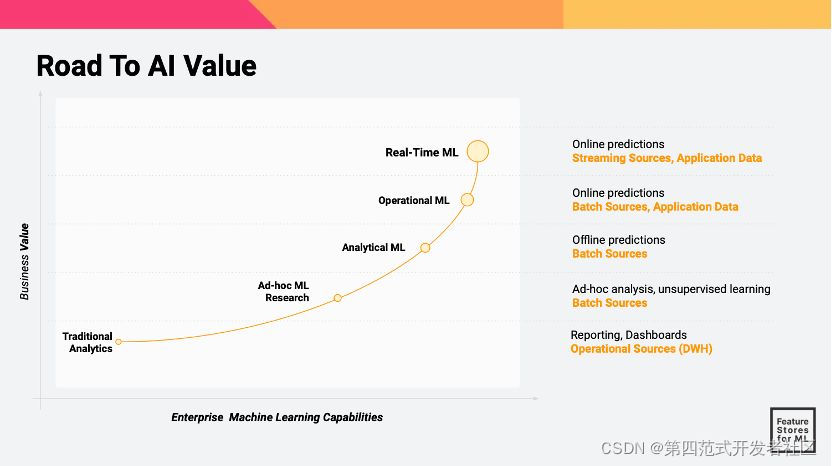
这个图是AI价值分析图,横轴是机器学习系统的技术能力,纵轴是系统的商业价值。从图上可以看出,Real-Time ML(实时的机器学习,即具备流式实时数据接入并进行在线预测能力的机器学习模型,价值最大。可以理解,现实世界中机器学习最产生商业价值的场景莫过于广告系统的CTR预估模型和电商系统的推荐模型,很显然,模型如果能得到用户的最近行为并进行训练,然后针对用户进行推荐,是最能提升预测精准度,并最终体现在商业效果的提升上的。
那么如何解决这些机器学习中的这些慢,效果不佳,效果甚至回退的问题呢?我们可以回顾一下当年我们是如何解决计算机软件或者线上系统的质量和效率问题的。我们用一种叫做DevOps的方法,来改进我们的研发模式和工具系统,在保证质量的前提下,更快的提高版本发布的速度,实现更多更快的部署。为此我们采用了大量的自动化,来进行流水线(俗称Pipeline)的自动化作业,即从代码提交开始,触发流水线进行自动化工作,完成代码静态检查、代码编译、代码动态检查、单元测试、自动化接口测试、自动化功能测试、小流量部署、蓝绿部署、全流量部署等。在容器成为计算机系统的主流后,还加上了达成docker镜像、把镜像部署到容器仓库等步骤。
借鉴DevOps领域内的成熟经验,业内发展了MLOps,即把机器学习开发和现代软件开发结合起来形成一整套的工具和平台以及研发流程。
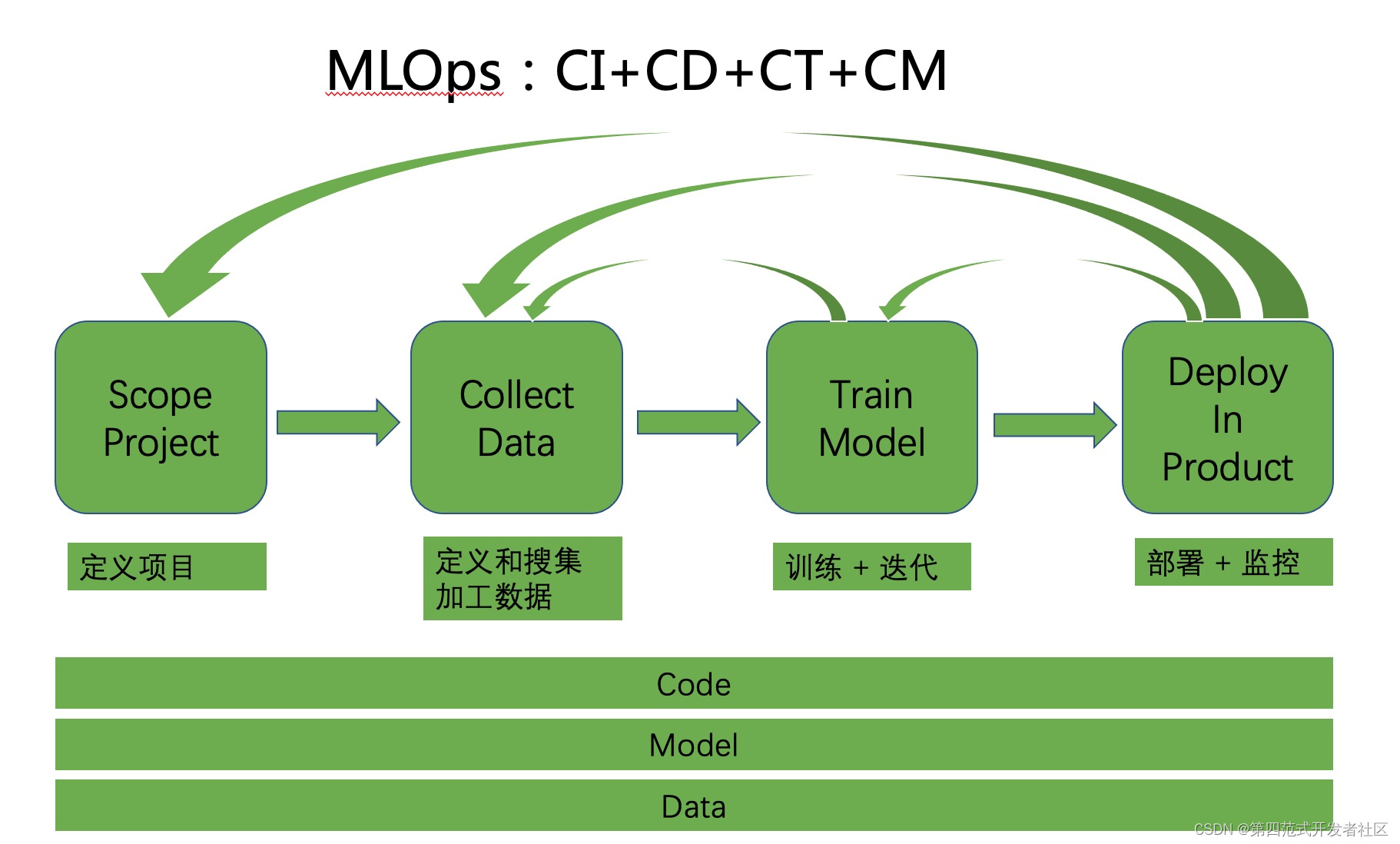
那么什么是MLOps?
用如下的图可以表示,即机器学习系统从第一步的定义项目,到第二步的特征数据加工,到第三步的模型训练和迭代,到第四步的模型部署和监控,也采用流水线的方式连续进行,其中有若干小循环,例如模型训练不理想,可能需要重新进行数据加工;模型监控下发现线上模型的效果有回退,需要重新训练等。简单来说就是实现Code、Model、Data这三者的CI(Continuous Integration)+ CD(Continuous Deploy)+ CT (Continuous Training)+CM(Continuous Monitoring)。
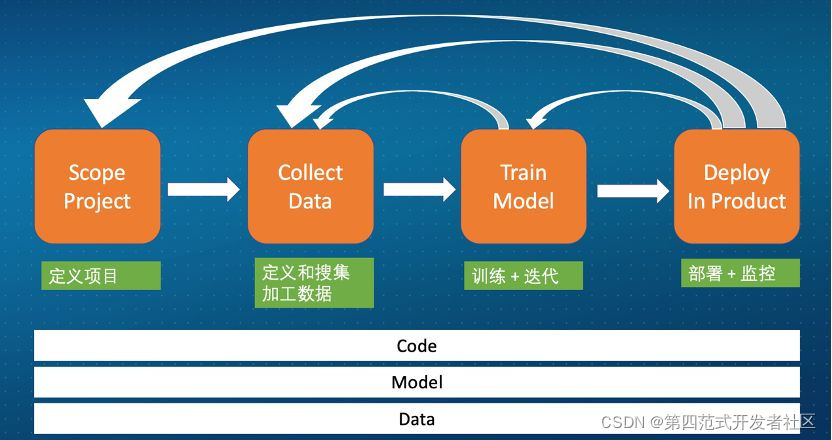
当然MLOps不只是流水线和自动化,还包含很多的工具和平台。在这里简单列举了一些,它们是:
- 存储平台:特征和模型的存储和读取
- 计算平台:流式、批处理用于特征和模型
- 消息队列:用于接收实时数据
- 调度工具:各种资源(计算/存储)的调度
- Feature Store:注册/发现/共享各种特征
- Model Store: 模型的注册/存储/版本等
- Evaluation Store:模型的监控/AB测试等
下面笔者将重点介绍第四范式开源的一个项目:OpenMLDB。
OpenMLDB是一个开源机器学习数据库,为企业提供全栈的FeatureOps解决方案。可能某些同学有点晕了,怎么又出了一个FeatureOps了。其实featureOps是MLOps的一部分,它专注于feature即特征相关的操作,包括抽取、变换、存储和计算等等。用下面的图可以很清楚的表示这两者之间的关系。
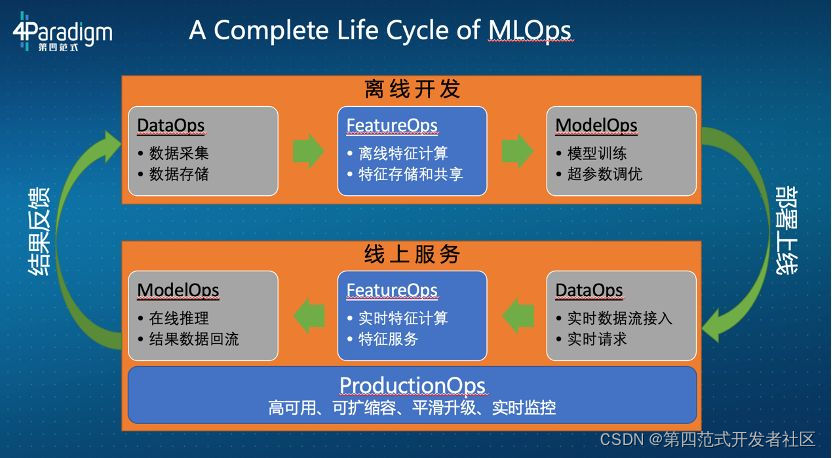
这是MLOps的完整的生命周期,它包含了离线部分的DataOps(内容主要是数据采集、数据的存储),FeatureOps(离线特征计算、存储和共享),ModelOps(模型的训练和调优);也包含了在线部分的DataOps(实时数据流的接入,和响应实时请求),FeatureOps(实时特征计算,特征服务),ModelOps(在线推理,结果数据回流等)。
对于FeatureOps(即特征操作),其中一个相当大的挑战是如何保证线下和线上的一致性,避免出现Training/Serving skew。我们来看下典型的AI科学家和AI工程师的工作流程。离线情况下,AI科学家从一个离线的数据仓库中拿到特征的原始数据,然后经过抽取/变换之后,喂给模型,然后进行训练;如果效果不满意,可能会增加新的数据作为特征,也可能把现有的特征进行更多的转化等,然后调整模型网络架构,调试各种学习超参数,再训练,直到获得较好的结果。这个过程,科学家往往使用python,在notebook中工作,训练生成模型后希望把模型部署到线上,承担真实流量,即面对真实的数据。这个时候,AI工程师需要部署模型并开发预测服务,需要从数据仓库中拿到模型所需要的原始数据,再把科学家训练时候对特征进行的ETL(Extract,Transform,Load)过程转换为线上预测服务相关的功能,因为科学家进行训练的时候是不太考虑线上服务的性能要求(比如并发、低延迟等),AI工程师是必须要考虑的,所以这个转化过程是非常耗时的,因为稍微有些不一致,就会导致训练和预测结果的差异,导致明明训练的结果很理想,上线之后效果就大打折扣从而达不到预期,所以需要AI工程师和AI科学家进行反复的沟通和调试,而这都是非常time-consuming的事情。
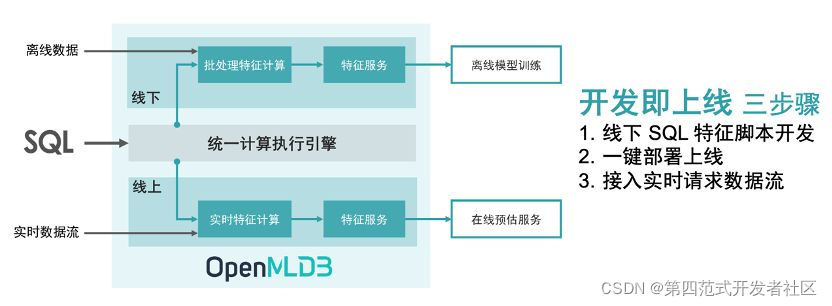
而OpenMLDB采用一种创新性的做法,让AI科学家和AI工程师都采用同一种非常普遍的语言即SQL来进行各自的工作。这样,AI科学家用一套SQL脚本构建出训练所需要的特征数据完成训练,同样这套SQL脚本可以被AI工程师原封不动的部署到线上,来用于预估服务。同一套SQL脚本被两种角色在训练和预测时候使用,从而创新性的解决了FeatureOps中最大的问题,即训练和预测不一致的问题。当然OpenMLDB还有其他的一些非常好的特性,例如内置一个高性能低延迟并对时序特征做特定优化的在线特征存储系统等。OpenMLDB今年6月已经在github上对外开源,采用的许可证是商业友好的Apache V2 License,它已经在第四范式的众多商业客户实际运行场景中运行,性能和质量得到广泛的验证。开源的地址是https://github.com/4paradigm/openmldb,欢迎大家关注此项目,或加入OpenMLDB技术交流群。

最后我来总结一下:
企业智能化转型需要多个AI场景落地
AI落地现状是很难,很慢,效果不佳而且会回退
借鉴DevOps经验实施MLOps是解决之道
OpenMLDB是MLOps中一个不错的工具
最后附上MLOps爱好者讨论群的二维码,欢迎各位对MLOps感兴趣的同学加入,我们一起来讨论相关的技术和项目。

Thanks。
关于作者:谭中意-第四范式架构师,开放原子基金会TOC副主席
相关文章
- AI中文版下载,Illustrator(Ai)各版本软件下载及安装教程ai干货
- 【倒计时3天】“CSIG企业行”走进合合信息,大咖解密智能文档处理背后的底层技术及AI未来展望
- 如何评估某活动带来的大盘增量 | 得物技术
- 爱了!Alibaba技术官甩出的SpringCloud笔记,GitHub已标星81.6k
- 基于AI+视频智能分析技术的SkeyeVSS建筑废弃物监管解决方案
- MySQL实现跨数据库操作的技术突破(mysql跨数据库操作)
- 隐私计算:数据隐私保护的技术退路
- Linux远程执行:探索技术的可能性(linuxrexec)
- OPPO内存拓展技术曝光:12GB秒变19GB 老用户有福了
- 极速解决:Redis缓存技术处理数组(redis缓存数组)
- MySQL分表技术实战:快速分割数据库表(mysql数据库分表实例)
- Oracle双活技术:保障同城企业高效可用(oracle同城双活)
- Oracle DAC技术探索。(oracledac)
- Linux的技术发展及其分支(linux的分支)
- MySQL大量记录插入的技术指南(mysql大量插入)
- 您值得关注的十家重要(但未必知名)技术企业
- 的优势利用Oracle PaaS云技术助力企业发展(oraclepaas云)
- 上海外滩大会,你不可不知的五大技术看点
- 今年的CJ 比起coser小姐姐 技术宅男竟更偏爱这位“隐形明星”
- 云技术为企业连接Oracle服务器提供无限可能(云连接oracle)
- =MSSQL读写分离技术:增强企业数据库性能的实现(mssql读写分离实现)
- 流畅使用Oracle 服务总线技术(oracle服务总线)
- Oracle定时同步技术提升企业效率(oracle 定时 同步)
- Oracle公司:革新影响世界的专业技术企业(oracle公司介绍)
- Oracle公有云让企业抓住云技术机遇(oracle公有云描述)
- Redis实现具有更高效率的限流技术(用redis做限速)
- CDH与Oracle技术深度定制企业大数据解决方案(cdh oracle)
- Redis缓存技术助力企业信息化提升(关于redis的作用)
- Oracle代理商为企业寻求安全可靠的技术保障(oracle代理资质)
- Oracle主组织提升技术驱动的企业绩效(oracle 主组织)
- 3探索新技术Oracle VM 43(oracle vm 4)
- Oracle Skima无缝接入复杂企业环境的技术解决方案(oracle skima)
- Oracle Delta领航新技术 改写企业未来(oracle delta)
- Oracle 02019新一代数据库技术助力企业数字化转型(oracle 02019)
- 预告:解析未来天线技术与5G移动通信 | 硬创公开课
- 饱受争议的 uBeam 第一次展示隔空充电技术