
用户体验第一的现代C++ JSON库 支持中文
转自:
用户体验第一的现代C++ JSON库
// 最简单的方式创建一个json对象
json obj = {
{ "null", nullptr },
{ "number", 1 },
{ "float", 1.3 },
{ "boolean", false },
{ "string", "中文测试" },
{ "array", { 1, 2, true, 1.4 } },
{ "object", { "key", "value" } }
};
有没有觉得单看这段代码都有种js内味了(误)。但是没错,上面这段代码是C++ !
如果这引起了你的些许兴趣,那就说明这个轮子成功了。
故事在前
造轮子的初衷是在两年前,我记得那天空中都是圆圆的轮状云,突然想给自己的游戏做一个json格式的配置文件。当我百度一下C++ json库时,被一张图震惊了
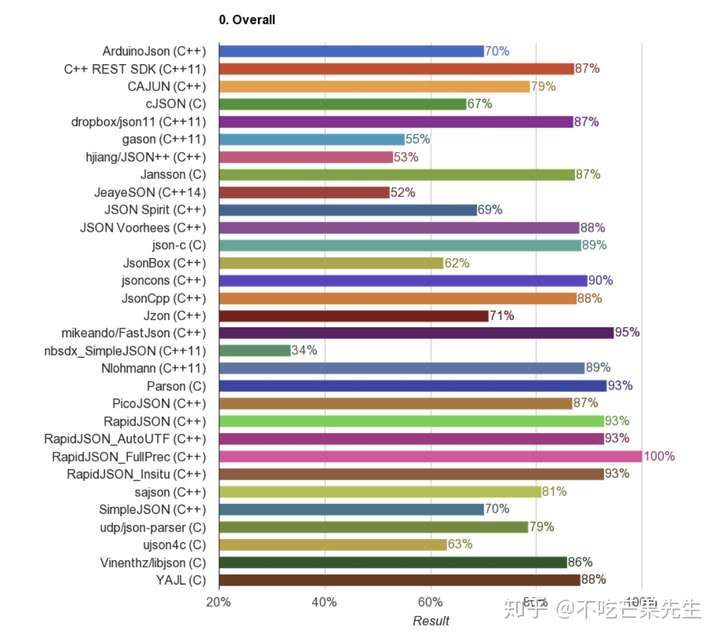 28个C/C++开源JSON库性能对比
28个C/C++开源JSON库性能对比
当然震惊我的不是这些库的性能,而是竟然足足有28个比较火的库在互相对比。。还有哪个语言可以做到让这么多人乐此不疲的为了一个小功能写那些重复的逻辑和代码呢?
然后我选了几个比较热门的库看看usage,看的越多,震惊越多。
每一个库的接口设计都无法获得我在审美上的认同,甚至有些demo代码又长又臭,这时候真的是想感叹一句:我爱Golang!(误)
于是那天的云彩显得越发的圆润。直到那天我才知道,原来C++的设计美学从底子里就是圆形的。
所以各位手下留情,这个库的存在并不是提升了多少性能,或者支持了多少json标准,而仅仅是为了美才诞生的。
这个库的slogan也很简单:
愿天堂没有C++
好了,认真介绍一下这个库:
JSONXX
一个为 C++ 量身打造的轻量级 JSON 通用工具,轻松完成 JSON 解析和序列化功能,并和 C++ 输入输出流交互。
Nomango/jsonxxgithub.com
使用介绍
- 引入 jsonxx 头文件
#include "jsonxx/json.hpp"
using namespace jsonxx;
- 使用 C++ 的方式的创建 JSON 对象
使用 operator[] 为 JSON 对象赋值
json j;
j["number"] = 1;
j["float"] = 1.5;
j["string"] = "this is a string";
j["boolean"] = true;
j["user"]["id"] = 10;
j["user"]["name"] = "Nomango";
使用 std::initializer_list 为 JSON 对象赋值
// 使用初始化列表构造数组
json arr = { 1, 2, 3 };
// 使用初始化列表构造对象
json obj = {
{
"user", {
{ "id", 10 },
{ "name", "Nomango" }
}
}
};
// 第二个对象
json obj2 = {
{ "nul", nullptr },
{ "number", 1 },
{ "float", 1.3 },
{ "boolean", false },
{ "string", "中文测试" },
{ "array", { 1, 2, true, 1.4 } },
{ "object", { "key", "value" } }
};
使用辅助方法构造数组或对象
json arr = json::array({ 1 });
json obj = json::object({ "user", { { "id", 1 }, { "name", "Nomango" } } });
- 判断 JSON 对象的值类型
// 判断 JSON 值类型
bool is_null();
bool is_boolean();
bool is_integer();
bool is_float();
bool is_array();
bool is_object();
- 将 JSON 对象进行显式或隐式转换
// 显示转换
auto b = j["boolean"].as_boolean(); // bool
auto i = j["number"].as_integer(); // int32_t
auto f = j["float"].as_float(); // float
const auto& arr = j["array"].as_array(); // arr 实际是 std::vector<json> 类型
const auto& obj = j["user"].as_object(); // obj 实际是 std::map<std::string, json> 类型
// 隐式转换
bool b = j["boolean"];
int i = j["number"]; // int32_t 自动转换为 int
double d = j["float"]; // float 自动转换成 double
std::vector<json> arr = j["array"];
std::map<std::string, json> obj = j["user"];
若 JSON 值类型与待转换类型不相同也不协变,会引发 json_type_error 异常
- 取值的同时判断类型
int n;
bool ret = j["boolean"].get_value(&n); // 若取值成功,ret 为 true
- JSON 对象类型和数组类型的遍历
// 增强 for 循环
for (auto& j : obj) {
std::cout << j << std::endl;
}
// 使用迭代器遍历
for (auto iter = obj.begin(); iter != obj.end(); iter++) {
std::cout << iter.key() << ":" << iter.value() << std::endl;
}
- JSON 解析
// 解析字符串
json j = json::parse("{ \"happy\": true, \"pi\": 3.141 }");
// 从文件读取 JSON
std::ifstream ifs("sample.json");
json j;
ifs >> j;
// 从标准输入流读取 JSON
json j;
std::cin >> j;
- JSON 序列化
// 序列化为字符串
std::string json_str = j.dump();
// 美化输出,使用 4 个空格对输出进行格式化
std::string pretty_str = j.dump(4, ' ');
// 将 JSON 内容输出到文件
std::ofstream ofs("output.json");
ofs << j << std::endl;
// 将 JSON 内容输出到文件,并美化
std::ofstream ofs("pretty.json");
ofs << std::setw(4) << j << std::endl;
// 将 JSON 内容输出到标准输出流
json j;
std::cout << j; // 可以使用 std::setw(4) 对输出内容美化
更多
若你需要将 JSON 解析和序列化应用到非 std::basic_stream 流中,可以通过创建自定义 output_adapter 和 input_adapter 的方式实现。
实际上 json::parse() 和 json::dump() 函数也是通过自定义的 string_output_adapter 和 string_input_adapter 实现对字符串内容的输入和输出。
详细内容请参考 json_parser.hpp 和 json_serializer.hpp。
写在最后
很多朋友提到这个库的风格和 nlohmann/json 很像,确实是的,当初看到这个库的时候我感叹一句“果然你能想到的别人都实现过了”,然后顺手“借鉴”了一些功能补充进来(误)
所以我也很推荐这个库,nlohmann也许是JSON for modern C++ 的最佳实践了吧!
对于中文,直接在vs2019下 gbk编码文件,赋值中文后
j["happy"] = "中文";
然后取出 j["happy"].as_string().c_str(), 发现字符是按照gbk编码存放:D6D0 CEC4.
而windows中,存放中文:
LPCWSTR cn = L"中文"; //看到它是放的unicode编码。
调用windows的 ::MessageBox(NULL, (LPCWSTR)( j["happy"].as_string().c_str()), cn, MB_OK); 会显示乱码。
利用下面的转换一下就好了,就会将gbk转成unicode的 2d 4e 87 65
CString str = CString(c_char);
USES_CONVERSION;
LPCWSTR wszClassName = A2CW(W2A(str));
用这个网站观察编码,很不错:http://www.mytju.com/classcode/tools/encode_gb2312.asp
如果本身字符是Unicode,存储时转成多字节,变成了gbk。读取时再由c的char单字节str转回多字节:
json obj;
obj[key]= wstring2string(title);
作为了string存储。因为jsonxx不支持wstring。
读取时 string2wstring(obj[key]) 返回了wstring;.c_str() 返回了wchar_t*.
#include <Windows.h> //将string转换成wstring wstring string2wstring(string str) { wstring result; //获取缓冲区大小,并申请空间,缓冲区大小按字符计算 int len = MultiByteToWideChar(CP_ACP, 0, str.c_str(), str.size(), NULL, 0); TCHAR* buffer = new TCHAR[len + 1]; //多字节编码转换成宽字节编码 MultiByteToWideChar(CP_ACP, 0, str.c_str(), str.size(), buffer, len); buffer[len] = '\0'; //添加字符串结尾 //删除缓冲区并返回值 result.append(buffer); delete[] buffer; return result; } //将wstring转换成string string wstring2string(wstring wstr) { string result; //获取缓冲区大小,并申请空间,缓冲区大小事按字节计算的 int len = WideCharToMultiByte(CP_ACP, 0, wstr.c_str(), wstr.size(), NULL, 0, NULL, NULL); char* buffer = new char[len + 1]; //宽字节编码转换成多字节编码 WideCharToMultiByte(CP_ACP, 0, wstr.c_str(), wstr.size(), buffer, len, NULL, NULL); buffer[len] = '\0'; //删除缓冲区并返回值 result.append(buffer); delete[] buffer; return result; }
前言
大家在学习或者使用Windows编程中,经常会碰到字符串之间的转换,char*转LPCWSTR也是其中一个比较常见的转换。下面就列出几种比较常用的转换方法。大家可以根据自己的需求选择相对应的方法,下面来一起学习学习吧。
1、通过MultiByteToWideChar函数转换
MultiByteToWideChar函数是将多字节转换为宽字节的一个API函数,它的原型如下:
|
1
2
3
4
5
6
7
8
|
int MultiByteToWideChar( UINT CodePage, // code page DWORD dwFlags, // character-type options LPCSTR lpMultiByteStr, // string to map int cbMultiByte, // number of bytes in string LPWSTR lpWideCharStr, // wide-character buffer int cchWideChar // size of buffer ); |
LPCWSTR实际上也是CONST WCHAR *类型
|
1
2
3
4
5
|
char* szStr = "测试字符串"; WCHAR wszClassName[256]; memset(wszClassName,0,sizeof(wszClassName)); MultiByteToWideChar(CP_ACP,0,szStr,strlen(szStr)+1,wszClassName, sizeof(wszClassName)/sizeof(wszClassName[0])); |
2、通过T2W转换宏
|
1
2
3
4
5
6
|
char* szStr = "测试字符串"; CString str = CString(szStr); USES_CONVERSION; LPCWSTR wszClassName = new WCHAR[str.GetLength()+1]; wcscpy((LPTSTR)wszClassName,T2W((LPTSTR)str.GetBuffer(NULL))); str.ReleaseBuffer(); |
3、通过A2CW转换
|
1
2
3
4
5
|
char* szStr = "测试字符串"; CString str = CString(szStr); USES_CONVERSION; LPCWSTR wszClassName = A2CW(W2A(str)); str.ReleaseBuffer(); |
上述方法都是UniCode环境下测试的。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流。
网上看到的,好像最新是不是已经解决了。没碰到这问题。

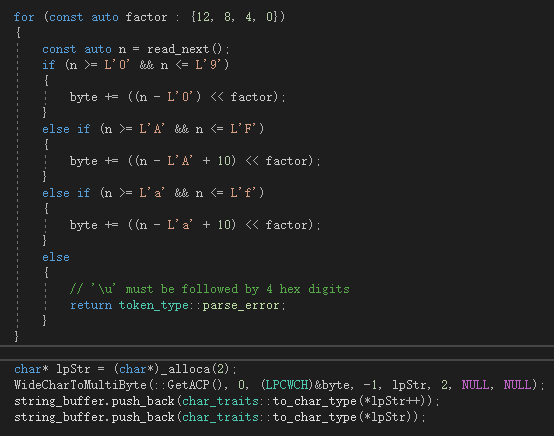 就可以完美解决解析unicode中文了。
就可以完美解决解析unicode中文了。相关文章
- [C++]VisualAssistX中文注释提示错误 解决办法
- C/C++ 头文件以及库的搜索路径
- 蓝桥杯官网 试题 PREV-255 历届真题 蓝肽子序列【第十一届】【决赛】【研究生组】【C++】【Java】【Python】三种解法
- 中文在C/C++中的处理和汉字乱码问题(wchar_t)
- 【华为OD机试 2023最新 】优雅子数组(C++ 100%)
- 【华为OD机试 2023最新 】最多等和不相交连续子序列(C++)
- c++ 操作注冊表
- 问题解决:C++ 读取MySQL数据库中文乱码问题
- Windows C++中__declspec(dllexport)的使用
- cocos2dx c++ 在mac下写的中文凝视,在win32下编译时不通过
- 闭关多日,整理一份C++中那些重要又容易忽视的细节
- 【C++要笑着学】搜索二叉树 (SBTree) | K 模型 | KV 模型
- C++实现中文大写与阿拉伯数字的相互转换(类封装)