
Lucene 分页搜索实现
搜索 实现 分页 Lucene
2023-09-14 09:07:45 时间
Lucene中有两种分页查询方式
1、一次查询出大量数据,然后根据页码定位是哪个文档,其实就是暴力获取了
2、通过调用searchAfter来实现
我们都知道collect是lucene中对搜索到的文档进行收集和排序过程,searchAfter也是通过一个收集器来控制的,叫PagingTopScoreDocCollector

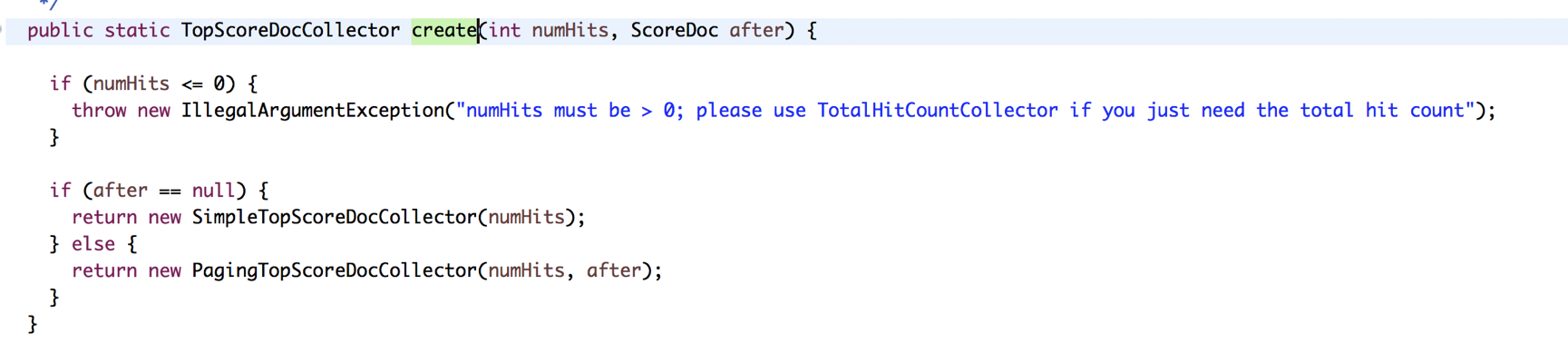
PagingTopScoreDocCollector中最主要的方法是getLeafCollector()判断分页查询的代码为,collect中包含了判断视为当前页的结果还有结果排序,排序方法是pq.updateTop();

updateTop中就执行两部操作,在查询到结果中找到最小的,然后返回heap[1],i默认从1开始所以head【0】为空,所以返回heap[1],每次都会和heap[1]对比把最小的放在前面
这是一个弄了一个二叉堆,具体分析的可以看http://quweiprotoss.blog.163.com/blog/static/408828832011523114133876/这个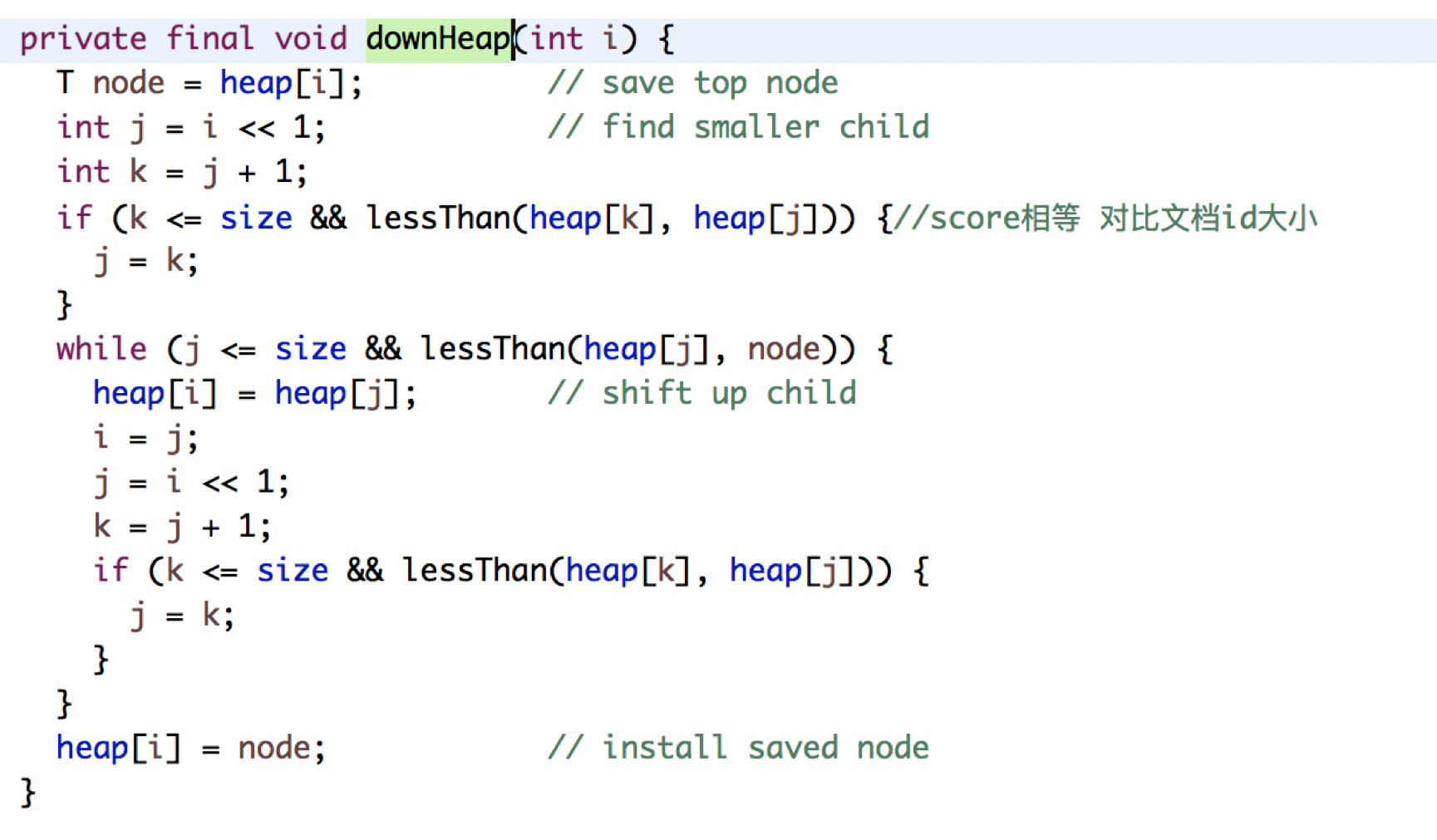
当score分数一样的时候会对比文档大小,最后是按照文档id的大小进行排列的
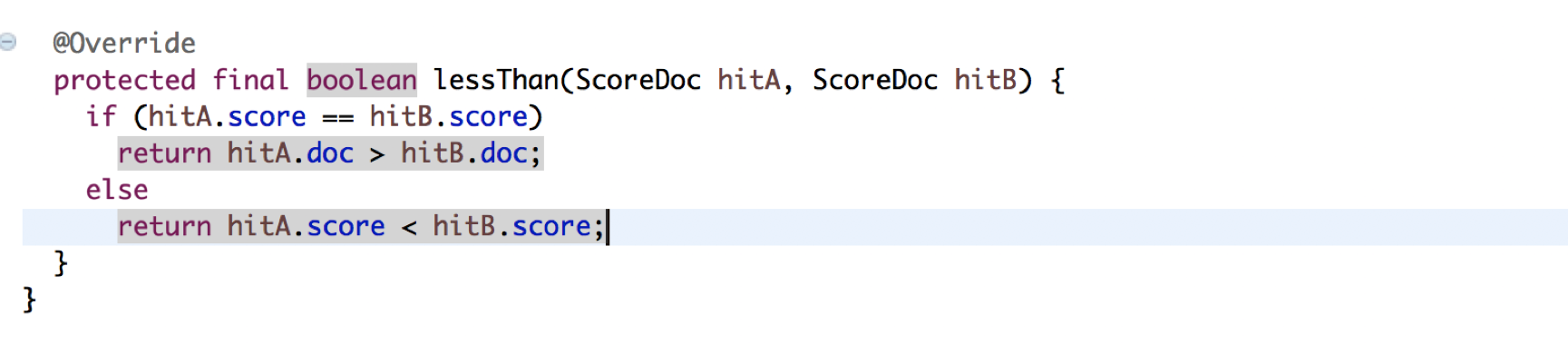
说白了searchAfter也是全部搜索了一遍只不过在collect过程中添加了一个上一页最后doc和当前返回的doc对比,这个过程时间复杂度为o(n),而用普通的查询这个过程会没有从某种程度上来说兴许速度还会由于searchAfter
相关文章
- Java实现 LeetCode 700 二叉搜索树中的搜索(遍历树)
- Java实现 LeetCode 530 二叉搜索树的最小绝对差(遍历树)
- Java实现 LeetCode 240 搜索二维矩阵 II(二)
- Java实现 LeetCode 235 二叉搜索树的最近公共祖先
- Java实现 LeetCode 211 添加与搜索单词 - 数据结构设计
- Java实现 LeetCode 95 不同的二叉搜索树 II(二)
- Java实现 LeetCode 33 搜索旋转排序数组
- Java实现 LeetCode 240 搜索二维矩阵 II
- 每日一道 LeetCode (10):搜索插入位置
- Python 和 Elasticsearch 构建简易搜索
- django中实现组合搜索
- S/4HANA和CRM Fiori应用的搜索分页实现
- CRM呼叫中心异步搜索实现的调试截图
- SAP应用搜索分页的实现原理
- S/4HANA和CRM Fiori应用的搜索分页实现
- 利用微搭低代码实现搜索功能
- ZZNUOJ_用C语言编写程序实现1154:二分搜索(附完整源码)
- ML之PySpark:基于PySpark框架针对adult人口普查收入数据集结合Pipeline利用LoR/DT/RF算法(网格搜索+交叉验证评估+特征重要性)实现二分类预测(年收入是否超50k)案例
- 基于禁忌搜索的TSP问题求解仿真输出路线规划图和收敛曲线
- Python实现直方图梯度提升分类模型(HistGradientBoostingClassifier算法)并基于网格搜索进行优化同时绘制PDP依赖图项目实战
- QtreeWidget实现模糊搜索功能
- google 高级搜索
- SDUT 2893-B(DP || 记忆化搜索)
- B-树和B+树的应用:数据搜索和数据库索引
- 【LeetCode】79. 单词搜索