
1932. 合并多棵二叉搜索树-哈希法+深度优先遍历
给你 n 个 二叉搜索树的根节点 ,存储在数组 trees 中(下标从 0 开始),对应 n 棵不同的二叉搜索树。trees 中的每棵二叉搜索树 最多有 3 个节点 ,且不存在值相同的两个根节点。在一步操作中,将会完成下述步骤:
选择两个 不同的 下标 i 和 j ,要求满足在 trees[i] 中的某个 叶节点 的值等于 trees[j] 的 根节点的值 。
用 trees[j] 替换 trees[i] 中的那个叶节点。
从 trees 中移除 trees[j] 。
如果在执行 n - 1 次操作后,能形成一棵有效的二叉搜索树,则返回结果二叉树的 根节点 ;如果无法构造一棵有效的二叉搜索树,返回 null 。
二叉搜索树是一种二叉树,且树中每个节点均满足下述属性:
任意节点的左子树中的值都 严格小于 此节点的值。
任意节点的右子树中的值都 严格大于 此节点的值。
叶节点是不含子节点的节点。
示例 1:
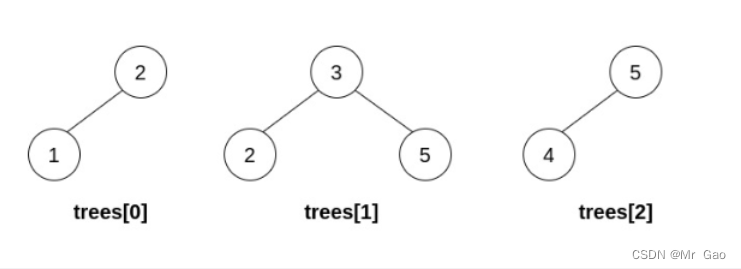
输入:trees = [[2,1],[3,2,5],[5,4]]
输出:[3,2,5,1,null,4]
解释:
第一步操作中,选出 i=1 和 j=0 ,并将 trees[0] 合并到 trees[1] 中。
删除 trees[0] ,trees = [[3,2,5,1],[5,4]] 。
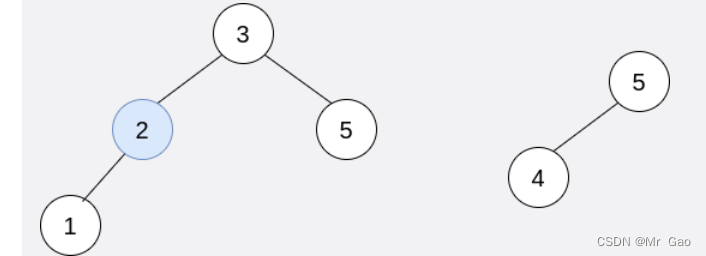
在第二步操作中,选出 i=0 和 j=1 ,将 trees[1] 合并到 trees[0] 中。
删除 trees[1] ,trees = [[3,2,5,1,null,4]] 。
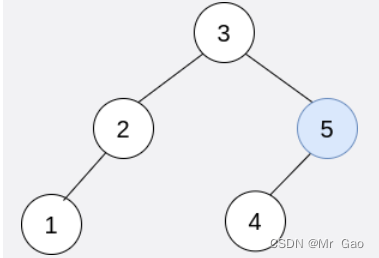
结果树如上图所示,为一棵有效的二叉搜索树,所以返回该树的根节点。
示例 2:
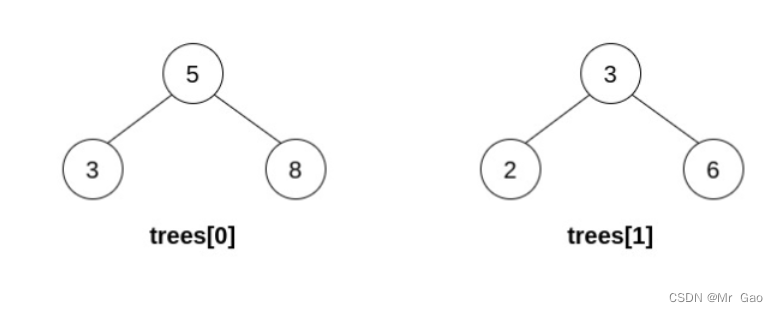
输入:trees = [[5,3,8],[3,2,6]]
输出:[]
解释:
选出 i=0 和 j=1 ,然后将 trees[1] 合并到 trees[0] 中。
删除 trees[1] ,trees = [[5,3,8,2,6]] 。

结果树如上图所示。仅能执行一次有效的操作,但结果树不是一棵有效的二叉搜索树,所以返回 null 。
示例 3:

输入:trees = [[5,4],[3]]
输出:[]
解释:无法执行任何操作。
这题就很复杂,我们需要做很多操作,很离谱,感兴趣可以学习一下,解题代码如下所示:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* };
*/
#define size 1777
int max,min;
struct hash{
struct hash *next;
struct TreeNode *node;
int val;
int index;
int max;
int min;
};
void add_hash(struct hash *h,struct TreeNode *node,int val,int index,int max,int min){
struct hash *p=(struct hash *)malloc(sizeof(struct hash));
p->node=node;
p->val=val;
p->next=h->next;
p->max=max;
p->min=min;
p->index=index;
h->next=p;
}
bool find(struct hash *h){
struct hash *p=h->next;
if(p){
return true;
}
return false;
}
void delete(struct hash *h,struct TreeNode **leaf_node,int *r,int direction,int pre_val){
struct hash *p=h->next;
struct hash *pre=h;
while(p){
if(direction==1&&p->val==(*leaf_node)->val&&p->max<pre_val){
pre->next=p->next;
*leaf_node=p->node;
r[p->index]=0;
}
else if(direction==0&&p->val==(*leaf_node)->val&&p->min>pre_val){
pre->next=p->next;
*leaf_node=p->node;
r[p->index]=0;
}
pre=p;
p=p->next;
}
}
void post_order(struct TreeNode **root,struct hash *h,int *r,int direction,int pre_val){
if((*root)){
post_order(&((*root)->left),h,r,1,(*root)->val);
post_order(&((*root)->right),h,r,0,(*root)->val);
if((*root)->left==NULL&&(*root)->right==NULL){
if(find(h+(*root)->val%size)){
printf("leaf_val %d ",(*root)->val);
delete(h+(*root)->val%size,root,r,direction,pre_val);
}
}
}
}
void post_order2(struct TreeNode **root){
if((*root)){
post_order2(&((*root)->left));
post_order2(&((*root)->right));
}
}
int inorder(struct TreeNode *root,int val){
if(root){
if(max<root->val){
max=root->val;
}
if(min>root->val){
min=root->val;
}
if(root->val>=val){
return 1;
}
return inorder(root->left,val)||inorder(root->left,val);
inorder(root->left,val);
inorder(root->right,val);
}
else{
return 0;
}
}
int inorder2(struct TreeNode *root,int val){
if(root){
if(max<root->val){
max=root->val;
}
if(min>root->val){
min=root->val;
}
if(root->val<=val){
return 1;
}
return inorder(root->left,val)||inorder(root->left,val);
inorder(root->left,val);
inorder(root->right,val);
}
else{
return 0;
}
}
int pre;
int pr;
void judege(struct TreeNode *root){
if(root&&pr){
judege(root->left);
if(pre>=root->val){
pr=0;
}
else{
pre=root->val;
}
judege(root->right);
}
}
struct TreeNode* canMerge(struct TreeNode** trees, int treesSize){
int *r=(int *)malloc(sizeof(int)*treesSize);
struct hash *h=(struct hash *)malloc(sizeof(struct hash)*size);
for(int i=0;i<size;i++){
(h+i)->next=NULL;
}
for(int i=0;i<treesSize;i++){
r[i]=1;
max=trees[i]->val;
min=trees[i]->val;
if(inorder(trees[i]->left,trees[i]->val)==0&&inorder2(trees[i]->right,trees[i]->val)==0){
// printf("max min %d %d ",max,min);
add_hash(h+(trees[i]->val)%size,trees[i],trees[i]->val,i,max,min);
}
}
for(int i=0;i<treesSize;i++){
post_order(&trees[i],h,r,-1,0);
}
int count=0;
struct TreeNode *re;
for(int i=0;i<treesSize;i++){
if(r[i]!=0){
post_order2(&trees[i]);
count++;
if(count>=2){
return NULL;
}
// printf("||%d ",trees[i]->val);
re=trees[i];
}
}
pre=-1;
if(count==1){
pr=1;
judege(re);
if(pr==0){
return NULL;
}
return re;
}
return NULL;
}
相关文章
- linux menuconfig搜索,linux系统menuconfig解析
- 【说站】python搜索模块如何查询
- php案例:(搜索文件)
- 如何使用Dismember扫描内存并搜索敏感信息
- 【数据结构与算法】图遍历算法 ( 深度优先搜索 DFS | 深度优先搜索和广度优先搜索 | 深度优先搜索基本思想 | 深度优先搜索算法步骤 | 深度优先搜索理论示例 )
- WordPress 文章查询教程11:如何使用搜索和评论相关参数
- RediSearch + RedisJSON 大于 Elasticsearch搜索存储引擎
- 算法-二叉搜索树的后序遍历序列详解编程语言
- 二叉搜索树的后序遍历序列算法详解编程语言
- Linux 通配符:强大的文件搜索利器(linux的通配符)
- 头条搜索虽然还没有正式推出和上线 但派出的爬虫已让很多网站痛苦不堪
- 搜索Linux源码路径探索之旅(linux源码路径)
- 文件Linux 中按名称搜索文件的方法(linux按名字查找)
- MySQL的全库查询:简洁、高效的搜索体验(mysql查询整个数据库)
- 利用 Oracle 与 Solr 构建强大的数据搜索体验(oraclesolr)
- Oracle数据库中的全局搜索技术(oracle全局查找)
- 搜索出更精彩发现类似Redis的软件(类似redis的软件)
- 基于Redis的热点搜索探索最新流行趋势(基于redis的热搜索)
- Oracle 数据库中用中文进行智能搜索(oracle 中文搜索)
- jquery搜索框效果实现方法
- C语言实现图的遍历之深度优先搜索实例