
基于Logistic混沌映射的麻雀搜索算法 -附代码
基于Logistic混沌映射的麻雀搜索算法
1.Logistic映射
Logistic 映射是混沌映射的典型代表,它的数学形式很简单。其表达式如下:
y
n
(
t
)
=
b
y
n
(
t
+
1
)
(
1
−
y
n
(
t
−
1
)
)
(1)
y_n(t) = by_n(t+1)(1-y_n(t-1))\tag{1}
yn(t)=byn(t+1)(1−yn(t−1))(1)
表达式中,
y
n
∈
[
0
,
1
]
y_n\in [0,1]
yn∈[0,1],括号中的
t
t
t 代表当前的迭代数,参数
b
b
b 一般的取值范围是:
1
≤
b
≤
4
1\leq b \leq 4
1≤b≤4,一般取 4,是一个控制参数。
b
b
b 决定了 Logistic 映射的演变过程。当参数
b
b
b增大时,映射序列的取值范围也增大,映射分布更加均匀。当
b
b
b 取值 4 时,系统处于完全混沌状态下,此时的映射分布均匀性达到巅峰。初始条件
y
0
y0
y0 在 Logistic 映射作用下产生的序列是非周期的、不收敛的,而在此范围之外,生成的序列必将收敛于某一个特定的值。
2.基于Logistic映射的麻雀搜索算法
基础麻雀算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/108830958
该改进主要是在初始化种群时,利用Logistic映射初始化种群
算法流程
Step1: 利用Logistic映射策略初始化种群,迭代次数,初始化捕食者和加入者比列。
Step2:计算适应度值,并排序。
Step3:麻雀更新捕食者位置。
Step4:麻雀更新加入者位置。
Step5:麻雀更新警戒者位置。
Step6:计算适应度值并更新麻雀位置。
Step7:是否满足停止条件,满足则退出,输出结果,否则,重复执行Step2-6;
3.算法结果:
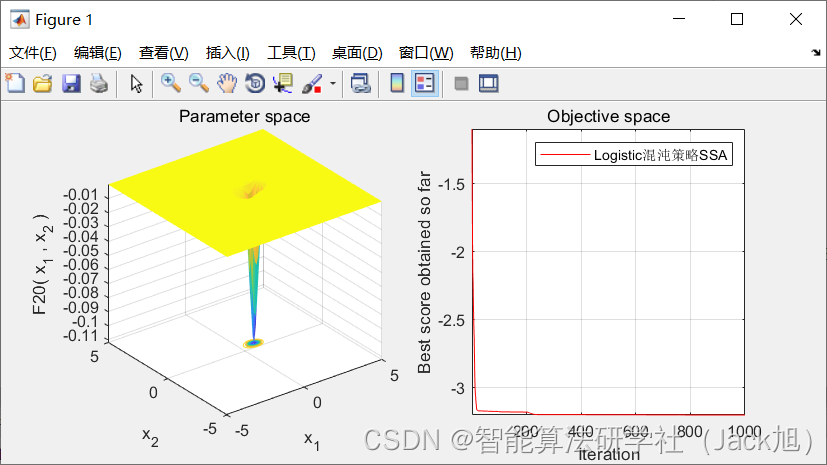
4.Matlab
5.Python
相关文章
- 数据上下文dbcontext添加数据与Database数据库的分库分表,表映射,切换表,使用到了IModelCacheKeyFactory代码如下:
- 如何设置映射网络驱动器的具体步骤和方法
- Mybatis+mysql动态分页查询数据案例——配置映射文件(HouseDaoMapper.xml)
- Pythoncookbook(数据结构与算法)在字典中将键映射到多个值上的方法
- Android版OpenCV图像处理技术亲自验证[四十一]之颜色映射彩色地球(附源码)
- ElasticSearch添加映射
- 解决逆向工程mapper映射文件不发布问题
- Windows 映射模式
- 另外我想问Java 环境下 怎么做域名映射到 Java环境的工程 ?配置网站映射IP和域名问题
- ML之FE:数据预处理中基于pandas实现类别型字段数据编码(包括自定义编码映射字典)、目标变量布尔类型化且同时输出raw_df和df数据之代码实现攻略
- Qt键盘-Android键盘映射
- python将内存映射为磁盘并从内存中将数据复制到磁盘
- 基于混沌映射与差分进化自适应教与学优化算法-附代码
- 嵌入Circle映射和逐维小孔成像反向学习的鲸鱼优化算法-附代码
- 基于Chebyshev混沌映射的麻雀搜索算法-附代码
- 基于Circle混沌映射的麻雀搜索算法-附代码
- 【Linux 内核 内存管理】内存管理系统调用 ④ ( 代码示例 | mmap 创建内存映射 | munmap 删除内存映射 )
- Go语言入门——数组、切片和映射(下)
- Spring MVC多解析器映射