
如何使用参数化查询提高Cypher查询的性能
本文分享自华为云社区《使用参数化查询提高Cypher查询的性能:以华为云图引擎GES为例》,作者: 蜉蝣与海。
在DBMS中,参数化查询被视为一种有效预防SQL注入攻击的手段。华为云图引擎GES提供对gremlin和cypher查询语言的参数化查询支持,使用参数化查询不仅可以防止前端用户随意输入恶意指令影响语句执行,还可以有效利用查询编译缓存,提高查询性能。
参数化查询(Parameterized Query),Wiki中的解释是:客户端在向数据服务端发送和请求查询语句时,在需要填入数值或者用户输入的字符串数据的地方,使用一个变量名来替代,并在请求体中解释每个变量名所指代的内容。在这种情况下,由于变量名指代的内容不会参与SQL语言的查询编译,即使用户输入数据中包含一些破坏性的指令,也不会被数据库运行。
举例说明,使用Cypher-JDBC-Driver访问华为云图引擎,可以进行对应的参数设置:
public static void main(String[] args) throws ClassNotFoundException {
Class.forName("com.huawei.ges.jdbc.Driver");
String url = "jdbc:ges:http://{{graph_ip}}:{{graph_port}}/ges/v1.0/{{project_id}}/graphs/{{graph_name}}/action?action_id=execute-cypher-query";
url = url.replace("{{graph_ip}}", ip).replace("{{graph_port}}",port + "").replace("{{project_id}}", projectId).replace("{{graph_name}}", graphName);
Properties prop = new Properties();
prop.setProperty("X-Auth-Token", token);
try(Connection conn = DriverManager.getConnection(url,prop)){
String query = "match (n:movie) where n.genres=? return n.title";
try(PreparedStatement stmt = conn.prepareStatement(query)){
stmt.setString(1, "Comedy");
try(ResultSet rs = stmt.executeQuery()){
while(rs.next()) {
System.out.println(rs.getString("n.title"));
}
}
}
} catch (SQLException e) {
// do something for e.
}
}
其中查询语句中的问号即是JDBC风格的参数化查询变量,后面代码中通过setString方法为其设置一个值“Comedy”。此外,图引擎也支持restful api风格的参数化查询,详见官网文档。
同时,参数化查询可以使得不同的用户输入使用同一条参数化查询语句执行,可以高效利用数据库查询缓存,节省了查询编译时间,从而提升了查询性能。例如,下图是使用Freebase数据集构造的若干2跳3跳查询,在华为云图引擎GES中运行, 参数化查询前后QPS的变化。可以看到使用参数化查询,qps获得了2-8倍的提升。

为什么参数化查询可以提高查询qps?首先要简单介绍下数据服务在收到查询语句后都做了什么。在数据管理领域,数据服务接收到查询语句,往往会进行下列步骤: 词法&语法解析,查询计划生成,查询计划执行,如图。
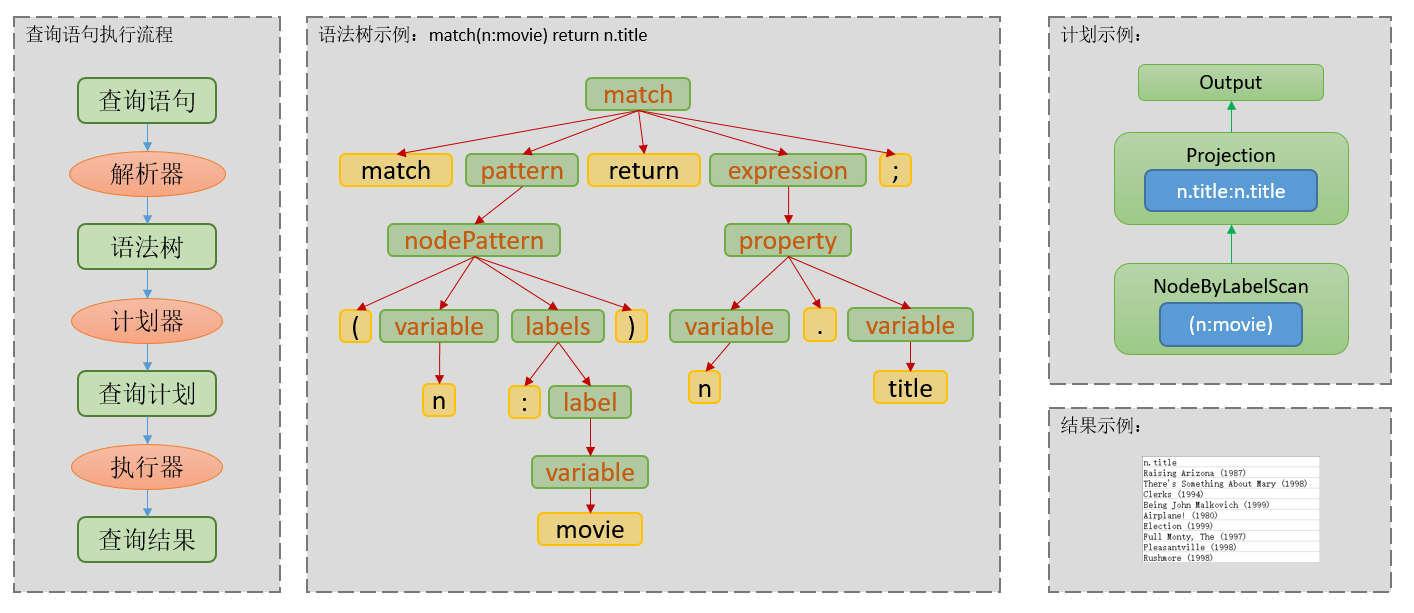
这里简单说一下查询计划生成。现在大多数查询计划的生成策略,要么是基于代价的查询计划生成,要么是基于规则的查询计划生成,或者二者组合使用。而不管是哪种查询计划生成,都是偏向计算密集型的任务,比较耗费服务器的计算资源,同一时间系统只能并行处理有限数目的查询计划生成任务。在计划生成器内部,大多数数据库都会内置查询缓存,即在一定的时间范围内,同一条查询语句输入计划器,计划器优先从查询缓存中检查有无可用计划,如果缓存中生成的计划时间太长或者无可用计划,才会真正执行计划生成的过程。
因此使用参数化查询时,由于使用不同参数的查询语句语句体相同,在查询编译阶段更容易被认为是同一条查询语句, 从而实现“多次查询,一次编译”的效果,也就提高了查询编译效率。
附录:
Freebase数据集属性图格式规模:
| 点数目 | 61440292 |
| 边数目 | 136253874 |
| label数目 | 5417 |
查询语句:
2hop_Q1: match (n1)-[r]->(m1)-->(p1) where id(n1)=$vertex return id(p1) limit 100
2hop_Q2: match (n1)-[r]->(m1)-->(p1) where id(n1)=$vertex return p1.name limit 100
2hop_Q3: match(n)-[r]->(m)-->(p) where id(n)=$vertex and m.games > 10 and p.name contains 'NBA' return p
3hop_Q1: match (n1)-[r1]-(m1)-[r2]-(p1)--(p2) where id(n1)=$vertex and m1.game > 0 return id(p2) limit 100
3hop_Q2: match (n1)-[r1]-(m1) match (m1)-[r2]-(p1) match (p1)--(p2) where id(n1)=$vertex and m1.games > 0 return id(p2)
相关参考:
[1]参数化查询_百度百科:https://baike.baidu.com/item/%E5%8F%82%E6%95%B0%E5%8C%96%E6%9F%A5%E8%AF%A2/4841802?fr=aladdin
[2]GES cypher API: Cypher操作API(2.2.16)_图引擎服务 GES_API参考_业务面API_华为云
[3]Github - opencypher:https://github.com/opencypher/openCypher
相关文章
- java quartz 性能_[译]如何优化Quartz调度器性能
- 京东购物车如何提升30%性能
- java中的toString方法性能如何详解编程语言
- 优化MySQL配置,助你提升性能(mysql如何优化配置)
- 龙芯3A5000性能如何?看齐AMD一代锐龙
- 增强缓存效率Redis: 如何提升缓存性能(redis方法)
- 使用Oracle系统构建强大的开发性能(oracle系统开发)
- 使用Oracle索引优化数据库性能(oracle索引如何使用)
- 如何搭建独立的MySQL数据库来优化网站性能?(独立mysql数据库)
- 如何优化MySQL的性能(mysql很卡)
- 使用Oracle优化查询性能: 如何建立有效的函数索引(oracle建函数索引)
- 如何优化Oracle子查询的性能?(oracle子查询性能)
- 以ETL手段提升Oracle数据库系统性能(etl oracle)
- 深入探讨Linux XMX的性能优化(linux xmx)
- MySQL中如何使用nowait关键字,提高查询性能和并发能力(mysqlnowait)
- 优化如何优化MSSQL语句的性能(mssql语句性能)
- linux最大的优势:强大的性能表现(linux 性能)
- 提高Redis性能实践经验与技巧(如何提升redis性能)
- Oracle如何调整内存以最优化性能(oracle修改占用内存)
- MySQL 查询上千万表如何优化数据库性能(mysql 上千万表查询)
- Redis读取性能优化如何正确设置读取时间(redis读取时间设置)
- JQueryeach()函数如何优化循环DOM结构的性能