
【NLP】第 3 章:NLP 和 文本Embeddings
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
目录
在深度学习中有许多不同的方式来表示文本。虽然我们已经介绍了基本的词袋( BoW ) 表示,但不出所料,还有一种更复杂的表示文本数据的方法,称为嵌入。虽然 BoW 向量仅用作句子中单词的计数,但嵌入有助于以数字方式定义某些单词的实际含义。
在本章中,我们将探索文本嵌入并学习如何使用连续的 BoW 模型创建嵌入。然后我们将继续讨论 n-gram 以及如何在模型中使用它们。我们还将介绍标记、分块和标记化可用于将 NLP 拆分为其各个组成部分的各种方法。最后,我们将研究 TF-IDF 语言模型以及它们如何有助于我们的模型对不经常出现的单词进行加权。
本章将涵盖以下主题:
- 词嵌入
- 探索 CBOW
- 探索 n-gram
- 代币化
- 词性的标记和分块
- 特遣部队
技术要求
GLoVe 向量可以从GloVe: Global Vectors for Word Representation下载。建议使用glove.6B.50d.txt文件,因为它比其他文件小得多,处理速度也更快。本章后面的部分将需要 NLTK。
NLP 的嵌入
单词没有代表他们的自然方式意义。在图像中,我们已经有了丰富的向量表示(包含图像中每个像素的值),因此对单词进行类似的丰富向量表示显然是有益的。什么时候语言的一部分以高维向量格式表示,它们被称为嵌入。通过对一个词的语料库进行分析,通过确定哪些词经常一起出现,我们可以得到每个词的长度为n的向量,它可以更好地表示每个词与所有其他词的语义关系。我们之前看到,我们可以很容易地将单词表示为 one-hot 编码向量:
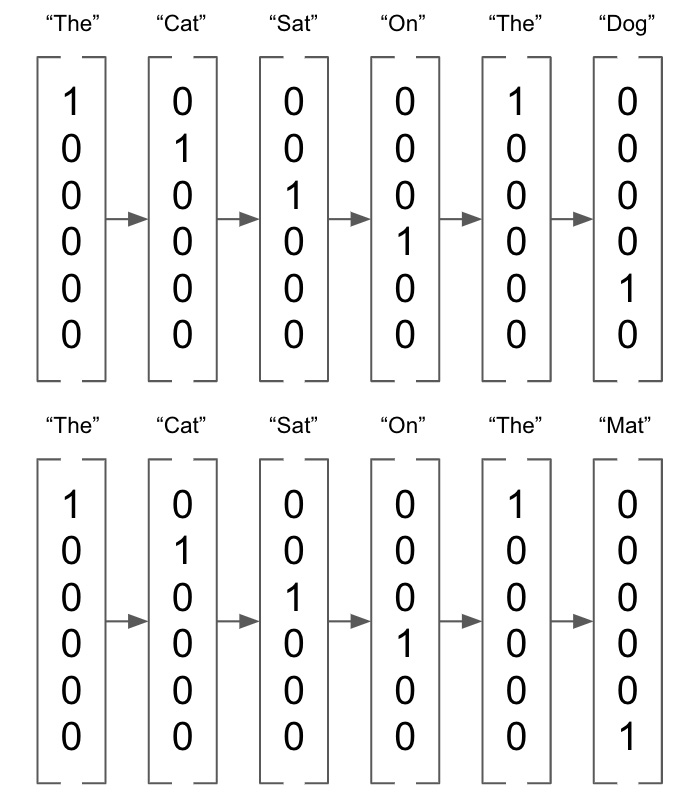
图 3.1 – One-hot 编码向量
另一方面,嵌入是长度为n的向量(在以下示例中,n = 3),可以取任何值: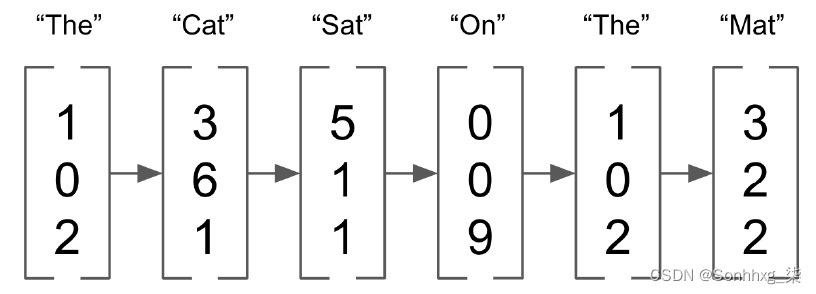
图 3.2 – n=3 的向量
这些嵌入表示n维空间中的单词向量(其中n是嵌入向量的长度),并且在该空间内具有相似向量的单词被认为在含义上更相似。虽然这些嵌入可以是任意大小,但它们的维数通常比 BoW 表示低得多。BOW 表示需要具有整个语料库长度的向量,当查看整个语言时,它可能会很快变得非常大。尽管嵌入具有足够高的维度来表示单个单词,但它们通常不会比几百维大多少。此外,BOW 向量通常非常稀疏,主要由零组成,而嵌入数据丰富,每个维度都有助于单词的整体表示。
GLoVe
我们可以下载一套预先计算的词嵌入来演示它们是如何工作的。为此,我们将使用全局向量进行词表示( GLoVe ) 嵌入,可从此处下载:https ://nlp.stanford.edu/projects/glove/ 。这些嵌入是在一个非常大的 NLP 数据语料库,并且是在单词共现矩阵上训练。这是基于这样的概念,即一起出现的单词更有可能具有相似的含义。例如,单词sun可能更频繁地出现在单词hot中,而不是单词cold,因此更可能认为sun和hot更相似。
我们可以通过检查各个 GLoVe 向量来验证这是真的:
- 我们首先创建一个简单的函数来从文本文件中加载 GLoVe 向量。这只是构建一个字典,其中索引是语料库中的每个单词,值是嵌入向量:
def loadGlove(path): file = open(path,'r') model = {} for l in file: line = l.split() word = line[0] value = np.array([float(val) for val in line[1:]]) model[word] = value return model glove = loadGlove('glove.6B.50d.txt') - 我们可以使用 Sklearn 中的 cosine_similarity() 函数在 Python中轻松计算。我们可以看到cat和dog有相似的向量,因为它们都是动物:
cosine_similarity(glove['cat'].reshape(1, -1), glove['dog'].reshape(1, -1))这将产生以下输出:
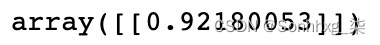
图 3.4 – 猫和狗的余弦相似度输出
- 但是,猫和钢琴是完全不同的,因为它们是两个看似无关的项目:
cosine_similarity(glove['cat'].reshape(1, -1), glove['piano'].reshape(1, -1))这将产生以下输出:

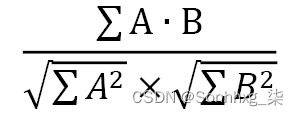
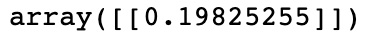
图 3.5 – 猫和钢琴的余弦相似度输出
Embedding 操作
由于嵌入是向量,我们可以对它们执行操作。例如,假设我们采用以下类型的嵌入并计算以下内容:
女皇+男
有了这个,我们可以近似king的嵌入。这实质上是用 Man 向量替换了来自Queen的Woman向量分量,以达到这个近似值。我们可以用图形来说明这一点: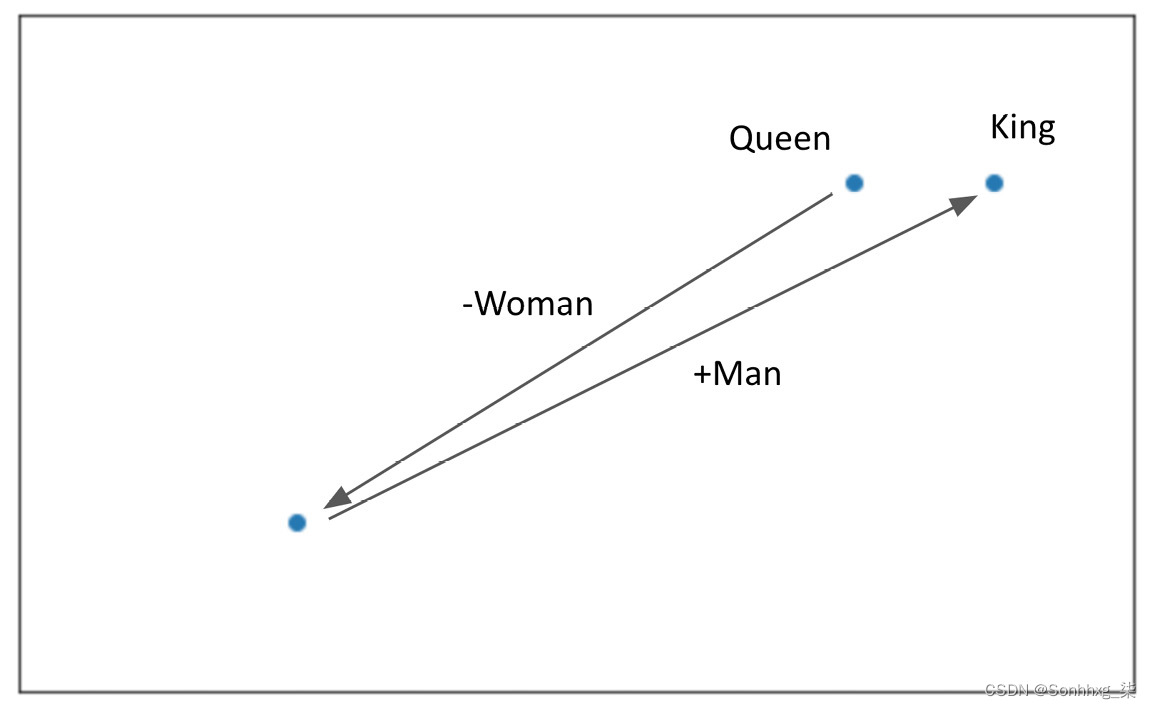
图 3.6 – 示例的图形表示
请注意,在此示例中,我们以二维图形方式说明了这一点。就我们的嵌入而言,这发生在 50 维空间中。虽然这并不准确,但我们可以验证我们计算的向量确实类似于King的 GLoVe 向量:
predicted_king_embedding = glove['queen'] - glove['woman'] + glove['man']
cosine_similarity(predicted_king_embedding.reshape(1, -1), glove['king'].reshape(1, -1))这将产生以下输出:![]()
图 3.7 – GLoVe 向量的输出
虽然 GLoVe 嵌入是非常有用的预计算嵌入,但我们实际上可以计算我们自己的嵌入。当我们分析一个特别独特的语料库时,这可能很有用。例如,Twitter 上使用的语言可能与 Wikipedia 上使用的语言不同,因此在一种语言上训练的嵌入可能对另一种语言没有用。我们现在将演示如何使用连续的词袋计算我们自己的嵌入。
探索 CBOW
连续的bag-of-words (CBOW)模型是 Word2Vec 的一部分,Word2Vec 是 Google 创建的一个模型,用于获取单词的向量表示。通过在一个非常大的语料库上运行这些模型,我们能够获得表示它们的语义和上下文相似性的单词的详细表示。Word2Vec 模型由两个主要组件组成:
由于这些模型执行类似的任务,我们现在只关注一个,特别是 CBOW。这个模型旨在预测一个词(目标词),给定它周围的其他词(称为上下文词)。一种解释上下文词的方法可能是简单到在句子中直接使用目标词之前的词来预测目标词,而更复杂的模型可以在目标词之前和之后使用多个词。考虑以下句子:
PyTorch 是一个深度学习框架
假设我们想要预测单词deep,给定上下文单词:
PyTorch 是一个 {target_word} 学习框架
我们可以从几个方面来看: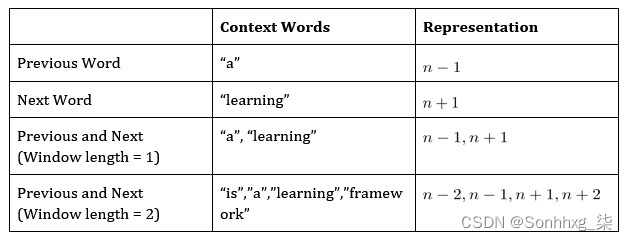
图 3.8 – 上下文和表示表
对于我们的 CBOW 模型,我们将使用长度为 2 的窗口,这意味着对于我们模型的 ( X, y ) 输入/输出对,我们使用([n-2, n-1, n+1, n+2, n ]),其中n是我们被预测的目标词。
使用这些作为我们的模型输入,我们将训练一个包含嵌入层的模型。这个嵌入层自动形成我们语料库中单词的n维表示。然而,首先,这一层是用随机权重初始化的。这些参数将使用我们的模型学习,以便在我们的模型完成训练后,可以使用这个嵌入层将我们的语料库编码为嵌入向量表示。
CBOW架构
我们现在将设计架构我们的模型以学习我们的嵌入。在这里,我们的模型接受四个词的输入(两个在我们的目标词之前,两个在我们的目标词之后)并针对输出(我们的目标词)对其进行训练。以下表示说明了它的外观: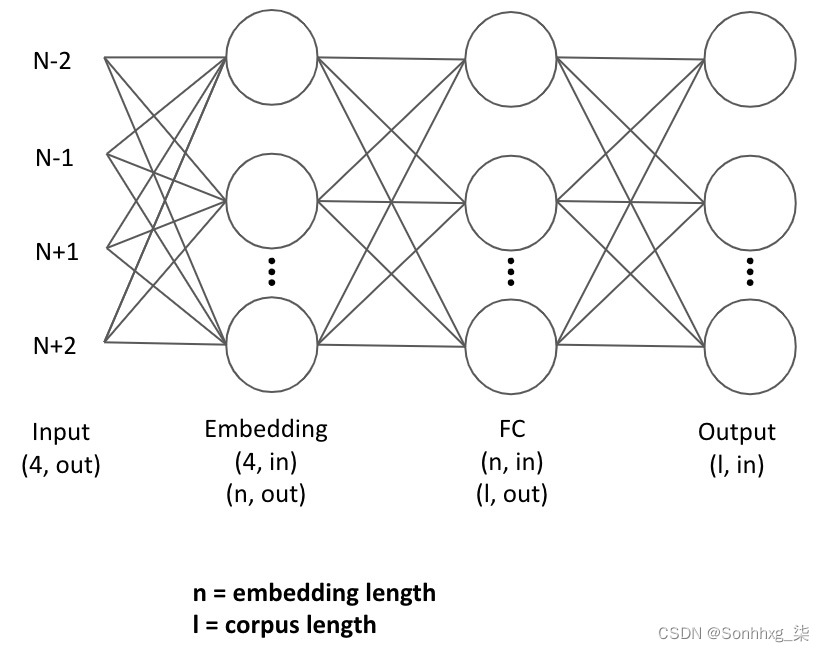
图 3.9 – CBOW 架构
我们的输入词首先通过嵌入层,表示为大小为 (n,l) 的张量,其中 n 是我们嵌入的指定长度,l 是我们语料库中的单词数。这是因为语料库中的每个单词都有自己独特的张量表示。
使用来自四个上下文词的组合(求和)嵌入,然后将其输入到一个完全连接的层中,以便根据我们对上下文词的嵌入表示来学习目标词的最终分类。请注意,我们的预测/目标词被编码为一个向量,该向量是我们语料库的长度。这是因为我们的模型有效地预测了语料库中每个词成为目标词的概率,最终分类是概率最高的那个。然后我们获得一个损失,通过我们的网络反向传播,并完全更新参数连接层,以及嵌入本身。
这种方法有效的原因是因为我们学习的嵌入表示语义相似性。假设我们在以下方面训练我们的模型:
X = ["is", "a", "learning", "framework"]; y = "deep"
我们的模型本质上学习的是目标词的组合嵌入表示在语义上与目标词相似。如果我们在足够大的词库中重复这一点,我们会发现我们的词嵌入开始类似于我们之前看到的 GLoVe 嵌入,其中语义相似的词在嵌入空间中彼此出现。
构建 CBOW
我们现在将运行从头开始构建一个 CBOW 模型,从而演示如何学习我们的嵌入向量:
- 我们首先定义一些文本并执行一些基本的文本清理,删除基本的标点符号并将其全部转换为小写:
text = text.replace(',','').replace('.','').lower().split() - 我们首先定义我们的语料库及其长度:
corpus = set(text) corpus_length = len(corpus) - 请注意,我们使用集合而不是列表,因为我们只关心文本中的唯一单词。然后我们建立我们的语料库索引和逆向语料库索引。我们的语料库索引将允许我们获得给定单词本身的单词的索引,这在对单词进行编码以进入我们的网络时很有用。我们的逆向语料库索引允许我们在给定索引值的情况下获得一个单词,该索引值将用于将我们的预测转换回单词:
word_dict = {} inverse_word_dict = {} for i, word in enumerate(corpus): word_dict[word] = i inverse_word_dict[i] = word - 接下来,我们对数据进行编码。我们遍历我们的语料库,对于每个目标词,我们捕获上下文词(之前的两个词和之后的两个词)。我们将其与目标词本身附加到我们的数据集中。请注意我们如何从语料库中的第三个单词(索引 = 2)开始这个过程,并在语料库结束前两步停止它。这是因为开头的两个词前面没有两个词,同样,结尾的两个词后面也没有两个词:
data = [] for i in range(2, len(text) - 2): sentence = [text[i-2], text[i-1], text[i+1], text[i+2]] target = text[i] data.append((sentence, target)) print(data[3])这将产生以下输出:

图 3.10 – 编码数据
- 然后我们定义长度我们的嵌入。虽然这在技术上可以是您希望的任何数字,但需要考虑一些权衡。虽然高维嵌入可以导致单词的更详细表示,但特征空间也变得更稀疏,这意味着高维嵌入仅适用于大型语料库。此外,更大的嵌入意味着要学习更多的参数,因此增加嵌入大小可以显着增加训练时间。我们只在一个非常小的数据集上进行训练,因此我们选择使用大小为20的嵌入:
embedding_length = 20接下来,我们在 PyTorch 中定义我们的CBOW模型。我们定义了我们的嵌入层,以便它接受一个语料库长度的向量并输出一个嵌入。我们将线性层定义为一个完全连接的层,它接受一个嵌入并输出一个64的向量。我们将最后一层定义为与文本语料库长度相同的分类层。
- 我们通过获取和求和所有输入上下文词的嵌入来定义我们的前向传递。然后通过具有 ReLU 激活函数的全连接层,最后进入分类层,分类层预测语料库中的哪个词最对应于上下文词的总嵌入:
class CBOW(torch.nn.Module): def __init__(self, corpus_length, embedding_dim): super(CBOW, self).__init__() self.embeddings = nn.Embedding(corpus_length,embedding_dim) self.linear1 = nn.Linear(embedding_dim, 64) self.linear2 = nn.Linear(64, corpus_length) self.activation_function1 = nn.ReLU() self.activation_function2 = nn.LogSoftmax(dim = -1) def forward(self, inputs): embeds = sum(self.embeddings(inputs)).view(1,-1) out = self.linear1(embeds) out = self.activation_function1(out) out = self.linear2(out) out = self.activation_function2(out) return out - 我们还可以定义一个get_word_embedding()函数,这将允许我们提取嵌入在我们的模型经过训练后给出的单词:
def get_word_emdedding(self, word): word = torch.LongTensor([word_dict[word]]) return self.embeddings(word).view(1,-1) - 现在,我们准备好训练我们的模型了。我们首先创建一个模型实例并定义损失函数和优化器:
model = CBOW(corpus_length, embedding_length) loss_function = nn.NLLLoss() optimizer = torch.optim.SGD(model.parameters(), lr=0.01) - 然后我们创建一个辅助函数,它获取我们输入的上下文词,获取每个词的索引,并将它们转换为长度为 4 的张量,形成我们的输入神经网络:
def make_sentence_vector(sentence, word_dict): idxs = [word_dict[w] for w in sentence] return torch.tensor(idxs, dtype=torch.long) print(make_sentence_vector(['stormy','nights','when','the'], word_dict))这将产生以下输出:
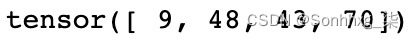
图 3.11 – 张量值
- 现在,我们训练我们的网络。我们循环遍历 100 个 epoch,每次遍历,我们遍历所有上下文词,即目标词对。对于这些对中的每一对,我们使用make_sentence_vector()加载上下文句子,并使用我们当前的模型状态来获得预测。我们根据我们的实际目标评估这些预测,以获得我们的损失。我们反向传播以计算梯度并逐步通过我们的优化器来更新权重。最后,我们将这一时期的所有损失相加并打印出来。在这里,我们可以看到我们的损失正在减少,表明我们的模型正在学习:
for epoch in range(100): epoch_loss = 0 for sentence, target in data: model.zero_grad() sentence_vector = make_sentence_vector(sentence, word_dict) log_probs = model(sentence_vector) loss = loss_function(log_probs, torch.tensor( [word_dict[target]], dtype=torch.long)) loss.backward() optimizer.step() epoch_loss += loss.data print('Epoch: '+str(epoch)+', Loss: ' + str(epoch_loss.item()))图 3.12 – 训练我们的网络
现在我们的模型已经训练好了,我们可以进行预测了。我们定义了几个函数来允许我们这样做。get_predicted_result()从预测数组中返回预测词,而我们的predict_sentence()函数根据上下文词进行预测。
- 我们把句子分成单个单词并将它们转换为输入向量。然后,我们通过将其输入模型来创建预测数组,并使用get_predicted_result()函数获得最终的预测词。我们还在预测的目标词之前和之后打印两个词作为上下文。我们可以运行几个预测来验证我们的模型是否正常工作:
def get_predicted_result(input, inverse_word_dict): index = np.argmax(input) return inverse_word_dict[index] def predict_sentence(sentence): sentence_split = sentence.replace('.','').lower().split() sentence_vector = make_sentence_vector(sentence_split, word_dict) prediction_array = model(sentence_vector).data.numpy() print('Preceding Words: {}\n'.format(sentence_split[:2])) print('Predicted Word: {}\n'.format(get_predicted_result(prediction_array[0], inverse_word_dict))) print('Following Words: {}\n'.format(sentence_split[2:])) predict_sentence('to see leap and')这将产生以下输出:

图 3.13 – 预测值
- 现在我们有一个训练好的模型,我们可以使用get_word_embedding()函数为了返回我们语料库中任何单词的 20 维词嵌入。如果我们需要我们的嵌入用于另一个 NLP 任务,我们实际上可以从整个嵌入层中提取权重并在我们的新模型中使用它:
print(model.get_word_emdedding('leap'))这将产生以下输出:


图 3.14 – 编辑模型后的张量值
在这里,我们展示了如何训练 CBOW 模型来创建词嵌入。实际上,要为语料库创建可靠的嵌入,我们需要一个非常大的数据集才能真正捕获所有单词之间的语义关系。因此,最好使用预先训练的嵌入,例如 GLoVe,它们已经过训练在非常大的数据语料库中,对于您的模型,但在某些情况下,最好从头开始训练一组全新的嵌入;例如,在分析与普通 NLP 不相似的数据语料库时(例如,用户可能使用简短的缩写词而不使用完整句子的 Twitter 数据)。
探索 n-gram
在我们的 CBOW 模型中,我们成功地表明单词的含义与周围单词的上下文有关。影响句子中单词含义的不仅是我们的上下文单词,还有这些单词的顺序。考虑以下句子:
The cat sat on the dog
The dog sat on the cat
如果将这两个句子转换为词袋表示,我们会发现它们是相同的。但是,通过阅读这些句子,我们知道它们具有完全不同的含义(实际上,它们是完全相反的!)。这清楚地表明,一个句子的意义不仅仅是它包含的单词,而是它们出现的顺序。尝试捕获句子中单词顺序的一种简单方法是使用 n-gram。
如果我们对我们的句子进行计数,而不是计算单个单词,我们现在计算不同的两个单词配对出现在句子中,这是称为使用二元组: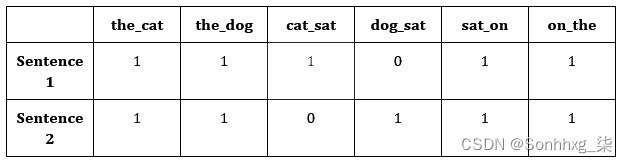
图 3.15 – 二元组的表格表示
我们可以这样表示:
The cat sat on the dog -> [1,1,1,0,1,1]
The dog sat on the cat -> [1,1,0,1,1,1]
这些单词对试图捕捉单词在句子中出现的顺序,而不仅仅是它们的频率。我们的第一句包含双元cat sat,而另一个包含dog sat。这些二元组显然有助于为我们的句子添加更多上下文,而不仅仅是使用原始字数。
我们不限于成对的单词。我们还可以查看不同的单词三元组,称为trigrams,或者实际上是任何字数不同。我们可以使用 n-gram 作为深度学习模型的输入,而不仅仅是单个单词,但是在使用 n-gram 模型时,值得注意的是,您的特征空间会很快变得非常大,并且可能会使机器学习变得非常缓慢。如果字典包含英语中的所有单词,那么包含所有不同单词对的字典将大几个数量级!
N-gram 语言建模
n-gram 帮助我们做的一件事是了解自然语言是如何形成的。如果我们认为一种语言是由较小的词对(bigrams)的一部分而不是单个词来表示的,我们可以开始将语言建模为一个概率模型,其中一个词出现在句子中的概率取决于之前出现过的词它。
在unigram模型中,我们假设根据语料库或文档中单词的分布,所有单词出现的概率是有限的。让我们来看一个由一句话组成的文档:
我的名字就是我的名字
基于这句话,我们可以生成单词的分布,其中每个单词根据其在文档中的频率具有给定的出现概率:
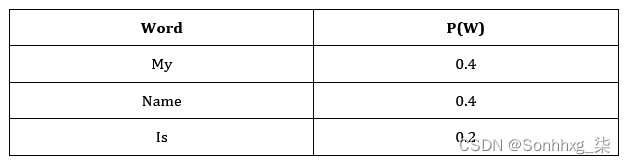
图 3.16 – 一元组的表格表示
然后我们可以从这个分布中随机抽取单词以生成新句子:
名字是我的名字
但正如我们所见,这句话没有任何意义,说明了使用一元模型的问题。因为每个单词出现的概率独立于所有其他单词句子中,没有考虑出现的单词的顺序或上下文。这就是 n-gram 模型有用的地方。
我们现在将考虑使用二元语言模型。给定出现在它之前的单词,此计算采用单词出现的概率:
这意味着在给定前一个单词的情况下,单词出现的概率是单词 n-gram 出现的概率除以前一个单词出现的概率。假设我们试图预测以下句子中的下一个单词:
我最喜欢的语言是___
除此之外,我们得到以下 n-gram 和单词概率:
图 3.17 – 概率的表格表示
有了这个,我们可以计算 Python 出现的概率,假设前一个单词出现的概率只有 20%,而英语出现的概率只有 10%。我们可以进一步扩展该模型以使用三元组或任何 n-gram 表示的单词作为我们认为合适。我们已经证明,n-gram 语言建模可用于将有关单词相互关系的更多信息引入我们的模型,而不是天真地假设单词是独立分布的。
Tokenization
接下来,我们将学习标记化对于 NLP,一种预处理文本以进入我们的模型的方法。标记化将我们的句子分成更小的部分。这可能涉及将一个句子拆分成单独的单词或将整个文档拆分成单独的句子。这是 NLP 的基本预处理步骤,可以在 Python 中相当简单地完成:
- 我们首先取一个基本句子并将其拆分使用NLTK中的单词标记器将单词分解为单个单词:
text = 'This is a single sentence.' tokens = word_tokenize(text) print(tokens)这将产生以下输出:

图 3.18 – 拆分句子
- 请注意句点 ( . ) 如何被视为因为它是自然语言的一部分。根据我们想要对文本做什么,我们可能希望保留或处理标点符号:
no_punctuation = [word.lower() for word in tokens if word.isalpha()] print(no_punctuation)这将产生以下输出:
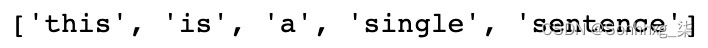
图 3.19 – 删除标点符号
- 我们还可以将文档标记为单个使用句子 标记器的句子:
text = "This is the first sentence. This is the second sentence. A document contains many sentences." print(sent_tokenize(text))这将产生以下输出:

图 3.20 – 将多个句子拆分为单个句子
- 或者,我们可以将两者组合成单独的单词句子:
print([word_tokenize(sentence) for sentence in sent_tokenize(text)])这将产生以下输出:

图 3.21 – 将多个句子拆分为单词
- 另一个可选步骤标记化过程,即去除停用词。停用词是非常常见的词,对句子的整体含义没有贡献。这些包括诸如a、I和or之类的词。我们可以使用以下代码从 NLTK 打印完整列表:
stop_words = stopwords.words('english') print(stop_words[:20])这将产生以下输出:

图 3.22 – 显示停用词
- 我们可以轻松删除这些使用基本列表理解从我们的单词中提取停用词:
text = 'This is a single sentence.' tokens = [token for token in word_tokenize(text) if token not in stop_words] print(tokens)这将产生以下输出:
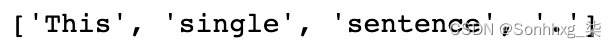
图 3.23 – 删除停用词
虽然某些 NLP 任务(例如预测句子中的下一个单词)需要停用词,但其他任务(例如判断电影评论的情绪)则不需要,因为停用词对文档的整体含义贡献不大。在这些情况下,删除停用词可能更可取,因为这些常用词的频率意味着它们可以不必要地增加我们的特征空间,这将增加我们的模型训练所需的时间。
词性的标记和分块
到目前为止,我们有涵盖了表示单词和句子的几种方法,包括词袋、嵌入和 n-gram。然而,这些表示无法捕捉任何给定句子的结构。在自然语言中,不同的词在一个句子中可以有不同的功能。考虑以下:
The big dog is sleeping on the bed
我们可以根据句子中每个单词的功能“标记”这段文本的各个单词。所以,前面的句子变成了这样:
The -> big -> dog -> is -> sleeping -> on -> the -> bed
Determiner -> Adjective -> Noun -> Verb -> Verb -> Preposition -> Determiner-> Noun
(限定词->形容词->名词->动词->动词->介词->限定词->名词)
这些词性包括但不限于以下内容: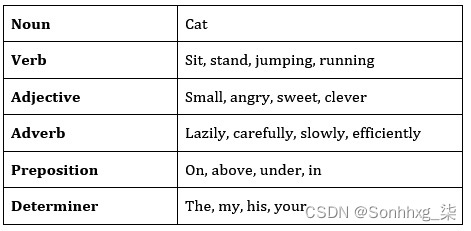
图 3.24 – 词类
这些不同词性可以用来更好地理解结构的句子。例如,形容词在英语中经常出现在名词之前。我们可以在模型中使用这些词性及其相互关系。例如,如果我们正在预测句子中的下一个词,而上下文词是形容词,我们知道下一个词是名词的概率很高。
标记(Tagging)
词性标注是将这些词性标签分配给各种单词句内。幸运的是,NTLK 有一个内置的标记功能,所以我们不需要训练我们自己的分类器来做到这一点:
sentence = "The big dog is sleeping on the bed"
token = nltk.word_tokenize(sentence)
nltk.pos_tag(token)这将产生以下输出:

图 3.25 – 词类分类
在这里,我们简单地标记化我们的文本并调用pos_tag()函数来标记句子中的每个单词。这将返回每个单词的标签句子。我们可以通过在代码上调用upenn_tagset()来解码这个标签的含义。在这种情况下,我们可以看到“ VBG ”对应一个动词:
nltk.help.upenn_tagset("VBG")这将产生以下输出:
图 3.26 – VBG 说明
使用预先训练的词性标注器是有益的,因为它们不仅充当查找句子中单个单词的字典,还充当字典。他们还使用句子中单词的上下文来分配其含义。考虑以下句子:
He drinks the water
I will buy us some drinks
这个词在这些里面喝句子代表两个不同的词性。在里面第一句,drinks指动词;喝酒的现在时。在第二句中,drinks指的是名词;单数饮料的复数形式。我们预先训练的标注器能够确定这些单个单词的上下文并执行准确的词性标注。
分块
分块扩展在我们最初的词性标记上,旨在将我们的句子构造成小块,其中这些块中的每一个都代表一小部分语音。
我们不妨分开我们的文本变成了实体,其中每个实体都是一个单独的对象或事物。例如,红皮书不是指三个独立的实体,而是指由三个词描述的单个实体。我们可以再次使用 NLTK 轻松实现分块。我们必须首先定义一个语法模式以使用正则表达式进行匹配。中的图案问题查找名词短语(NP),其中一个名词短语定义为限定词( DT ),后跟可选形容词( JJ ),后跟名词( NN ):
expression = ('NP: {<DT>?<JJ>*<NN>}')使用RegexpParser()函数,我们可以匹配该表达式的出现并将它们标记为名词短语。然后我们可以打印结果树,显示标记的短语。在我们的例句,我们可以看到大狗和床被标记为两个独立的名词短语。我们能够匹配任何文本块我们使用我们认为合适的正则表达式来定义:
tagged = nltk.pos_tag(token)
REchunkParser = nltk.RegexpParser(expression)
tree = REchunkParser.parse(tagged)
print(tree)这将产生以下输出:

图 3.27 – 树表示
特遣部队
TF-IDF是我们的另一种技术可以学习更好地表示自然语言。它通常用于文本挖掘和信息检索中,根据搜索词匹配文档,但也可以与嵌入结合使用,以更好地以嵌入形式表示句子。让我们使用以下短语:
This is a small giraffe
假设我们想要一个嵌入来表示这句话的含义。我们可以做的一件事是简单地平均这句话中五个单词中每个单词的单个嵌入: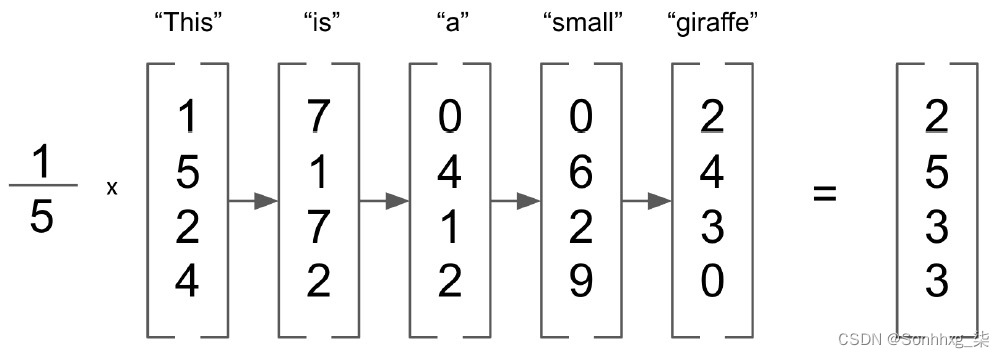
图 3.28 – 词嵌入
然而,这种方法分配与句子中所有单词的权重相等。你认为所有的词都对句子的意义有同样的贡献吗?this和a在英语中是很常见的词,但giraffe很少见。因此,我们可能希望为稀有词分配更多权重。这种方法称为词频 - 逆文档频率( TD-IDF )。我们现在将演示如何计算文档的 TF-IDF 权重。
计算 TF-IDF
顾名思义,TF-IDF 由两个单独的部分:词频和逆文档频率。词频是特定于文档的度量,用于计算正在分析的文档中给定单词的频率:
请注意,我们将此度量除以文档中的单词总数,因为较长的文档更有可能包含任何给定的单词。如果一个词在文档中出现多次,它将获得更高的词频。然而,这与我们希望我们的 TF-IDF 加权所做的相反,因为我们希望对文档中出现的稀有词给予更高的权重。这就是 IDF 发挥作用的地方。
文档频率衡量文档的数量在正在分析单词的整个文档语料库中,逆文档频率计算总文档与文档频率的比率: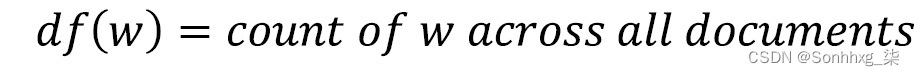
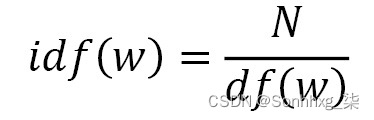
如果我们有一个包含 100 个文档的语料库,并且我们的单词在它们中出现了 5 次,那么我们的逆文档频率将是 20。这意味着在所有文档中出现频率较低的单词会被赋予更高的权重。现在,考虑一个包含 100,000 个文档的语料库。如果一个词只出现一次,它的 IDF 为 100,000,而出现两次的词的 IDF 为 50,000。这些非常大且易变的 IDF 并不适合我们的计算,因此我们必须首先使用日志对它们进行归一化。请注意,如果我们为未出现在我们的语料库中的单词计算 TF-IDF,我们如何在计算中添加 1 以防止除以 0: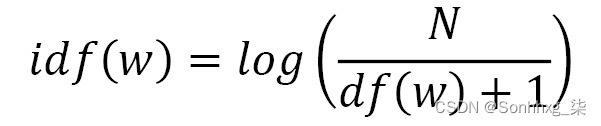
这使得我们最终的 TF-IDF 方程如下所示:
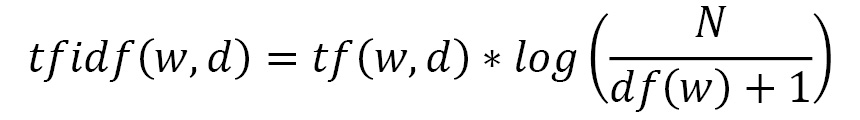
我们现在可以演示如何在 Python 中实现这一点并将 TF-IDF 权重应用于我们的嵌入。
实施 TF-IDF
在这里,我们将使用来自 NLTK 数据集的 Emma 语料库在数据集上实现 TF-IDF。这个数据集由 Jane Austen 的《 Emma》一书中的句子组成,我们希望为这些句子中的每一个计算嵌入向量表示:
- 我们首先导入我们的数据集并遍历每个句子,删除任何标点符号和非字母数字字符(例如星号)。我们选择在我们的数据集中保留停用词,以展示 TF-IDF 如何解释这些词,因为这些词出现在许多文档中,因此 IDF 非常低。我们在我们的语料库中创建一个已解析句子的列表和一组不同的单词:
emma = nltk.corpus.gutenberg.sents('austen-emma.txt') emma_sentences = [] emma_word_set = [] for sentence in emma: emma_sentences.append([word.lower() for word in sentence if word.isalpha()]) for word in sentence: if word.isalpha(): emma_word_set.append(word.lower()) emma_word_set = set(emma_word_set) - 接下来,我们创建一个函数将返回给定文档中给定单词的词频。我们取文档的长度来给我们单词的数量,并在返回比率之前计算该单词在文档中的出现次数。在这里,我们可以看到单词ago在句子中出现了一次,句子有 41 个单词,给我们一个 0.024 的词频:
def TermFreq(document, word): doc_length = len(document) occurances = len([w for w in document if w == word]) return occurances / doc_length TermFreq(emma_sentences[5], 'ago')这将产生以下输出:
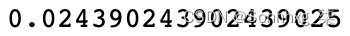
图 3.29 – TF-IDF 分数
- 接下来,我们计算我们的文档频率。为了有效地做到这一点,我们首先需要预先计算一个文档频率字典。这会遍历所有数据并计算我们语料库中每个单词出现的文档数量。我们预先计算它,这样我们就不必在每次希望计算给定单词的文档频率时都执行此循环:
def build_DF_dict(): output = {} for word in emma_word_set: output[word] = 0 for doc in emma_sentences: if word in doc: output[word] += 1 return output df_dict = build_DF_dict() df_dict['ago'] - 在这里,我们可以看到单词ago在我们的文档中出现了 32 次。使用这本字典,我们可以很容易地计算出我们的逆文档频率,方法是用文档总数除以我们的文档频率,然后取这个值的对数。请注意,当单词未出现在语料库中时,我们如何将 1 添加到文档频率以避免除以零错误:
def InverseDocumentFrequency(word): N = len(emma_sentences) try: df = df_dict[word] + 1 except: df = 1 return np.log(N/df) InverseDocumentFrequency('ago') - 最后,我们简单的结合词频和逆文档频率来获得每个单词/文档对的 TF-IDF 权重:
def TFIDF(doc, word): tf = TF(doc, word) idf = InverseDocumentFrequency(word) return tf*idf print('ago - ' + str(TFIDF(emma_sentences[5],'ago'))) print('indistinct - ' + str(TFIDF(emma_sentences[5],'indistinct')))这将产生以下输出:

图 3.30 – 之前和模糊的 TF-IDF 分数
在这里,我们可以看到尽管单词ago和indistinct在给定文档中只出现一次,但indistinct在整个语料库中出现的频率较低,这意味着它获得了更高的 TF-IDF 权重。
计算 TF-IDF 加权嵌入
接下来,我们可以展示这些 TF-IDF 权重如何应用于嵌入:
- 我们首先加载我们预先计算的 GLoVe 嵌入,以提供我们语料库中单词的初始嵌入表示:
def loadGlove(path): file = open(path,'r') model = {} for l in file: line = l.split() word = line[0] value = np.array([float(val) for val in line[1:]]) model[word] = value return model glove = loadGlove('glove.6B.50d.txt') - 然后,我们计算文档中所有单个嵌入的未加权平均平均值,以获得整个句子的向量表示。我们简单地遍历我们文档中的所有单词,从 GLoVe 字典中提取嵌入,并计算所有这些向量的平均值:
embeddings = [] for word in emma_sentences[5]: embeddings.append(glove[word]) mean_embedding = np.mean(embeddings, axis = 0).reshape(1, -1) print(mean_embedding)这将产生以下输出:

图 3.31 – 平均嵌入
- 我们重复这个过程来计算我们的 TF-IDF 加权文档向量,但是这一次,我们在我们平均之前将我们的向量乘以它们的 TF-IDF 权重:
embeddings = [] for word in emma_sentences[5]: tfidf = TFIDF(emma_sentences[5], word) embeddings.append(glove[word]* tfidf) tfidf_weighted_embedding = np.mean(embeddings, axis = 0).reshape(1, -1) print(tfidf_weighted_embedding)这将产生以下输出:
图 3.32 – TF-IDF 嵌入
- 然后,我们可以将 TF-IDF 加权嵌入与我们的平均嵌入进行比较,看看如何他们是相似的。我们可以使用余弦相似度来做到这一点,如下所示:
cosine_similarity(mean_embedding, tfidf_weighted_embedding)这将产生以下输出:
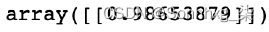
图 3.33 – TF-IDF 和平均嵌入之间的余弦相似度
在这里,我们可以看到我们的两种不同的表示非常相似。因此,虽然使用 TF-IDF 可能不会显着改变我们对给定句子或文档的表示,但它可能会权衡它有利于感兴趣的单词,从而提供更有用的表示。
总结
在本章中,我们深入探讨了词嵌入及其应用。我们已经展示了如何使用连续词袋模型训练它们,以及我们如何结合 n-gram 语言建模来更好地理解句子中单词之间的关系。然后,我们研究了将文档拆分为单独的标记以便于处理,以及如何使用标记和分块来识别词性。最后,我们展示了如何使用 TF-IDF 权重更好地以嵌入形式表示文档。
在下一章中,我们将看到如何使用 NLP 进行文本预处理、词干提取和词形还原。
相关文章
- 加上Web UI,文本-图像模型Stable Diffusion变身绘图工具,生成艺术大片
- idea替换文本快捷键_idea 替换整个项目某个单词
- 文本相似度计算_文本相似度分析算法
- 自然语言处理NLP:主题LDA、情感分析疫情下的新闻文本数据|附代码数据
- 英伟达「一句话生成3D模型」碾压谷歌:分辨率清晰8倍,速度快2倍,编辑文本还可直接修改
- Meta AI 更新的 Data2vec 2.0 | 实现更快、更高效的视觉、语音和文本的自监督学习
- VUE 前端文本输出为超文本
- NLP自然语言处理—主题模型LDA案例:挖掘人民网留言板文本数据|附代码数据
- 【Android 应用开发】Canvas 精准绘制文字 ( 测量文本真实边界 | 将文本中心点与给定中心点对齐 )
- NLP自然语言处理—主题模型LDA案例:挖掘人民网留言板文本数据|附代码数据
- 文件Linux下修改文本文件的操作技巧(linux修改文本)
- text长文本存储MySQL中Longtext长文本的稳定可靠存储方式(mysql中long)
- MySQL中存储大量文本数据的解决方案(mysql长文本类型)
- 文件的文本打开方式和二进制打开方式有什么区别?
- 利用AWK在Linux中进行文本分割: 25字技巧(awklinux分割)
- SQL Server中用TextBox读取文本信息(sqlserver文本框)
- 《安娜卡列尼娜》文本生成——利用 TensorFlow 构建 LSTM 模型
- AJAX实时读取输入文本(php)