
批量标准化BN方法简介【避免了梯度消失和梯度爆炸、加速网络的收敛、优化网络结构】
一. 本文的内容包括:
1. Batch Normalization,其论文:https://arxiv.org/pdf/1502.03167.pdf
2. Layer Normalizaiton,其论文:https://arxiv.org/pdf/1607.06450v1.pdf
3. Instance Normalization,其论文:https://arxiv.org/pdf/1607.08022.pdf
4. Group Normalization,其论文:https://arxiv.org/pdf/1803.08494.pdf
5. Switchable Normalization,其论文:https://arxiv.org/pdf/1806.10779.pdf
二. 介绍
在介绍各个算法之前,我们先引进一个问题:为什么要做归一化处理?
神经网络学习过程的本质就是为了学习数据分布,如果我们没有做归一化处理,那么每一批次训练数据的分布不一样,从大的方向上看,神经网络则需要在这多个分布中找到平衡点,从小的方向上看,由于每层网络输入数据分布在不断变化,这也会导致每层网络在找平衡点,显然,神经网络就很难收敛了。当然,如果我们只是对输入的数据进行归一化处理(比如将输入的图像除以255,将其归到0到1之间),只能保证输入层数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以也需要在神经网络的中间层加入归一化处理。
BN、LN、IN和GN这四个归一化的计算流程几乎是一样的,可以分为四步:
- 计算出均值
- 计算出方差
- 归一化处理到均值为0,方差为1
- 变化重构,恢复出这一层网络所要学到的分布
a、协变量偏移问题
- 我们知道,在统计机器学习中算法中,一个常见的问题是协变量偏移(Covariate Shift),协变量可以看作是 输入变量。一般的深度神经网络都要求输入变量在训练数据和测试数据上的分布是相似的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。
- 传统的深度神经网络在训练时,随着参数的不算更新,中间每一层输入的数据分布往往会和参数更新之前有较大的差异,导致网络要去不断的适应新的数据分布,进而使得训练变得异常困难,我们只能使用一个很小的学习速率和精调的初始化参数来解决这个问题。而且这个中间层的深度越大时,这种现象就越明显。由于是对层间数据的分析,也即是内部(internal),因此这种现象叫做内部协变量偏移(internal Covariate Shift)。
b、解决方法
为了解决这个问题,在2015年首次提出了批量标准化(Batch Normalization,BN)的想法。该想法是:不仅仅对输入层做标准化处理,还要对 每一中间层的输入(激活函数前) 做标准化处理,使得输出服从均值为 0,方差为 1 的正态分布,从而避免内部协变量偏移的问题。之所以称之为 批 标准化:是因为在训练期间,我们仅通过计算 当前层一小批数据的均值和方差来标准化每一层的输入。
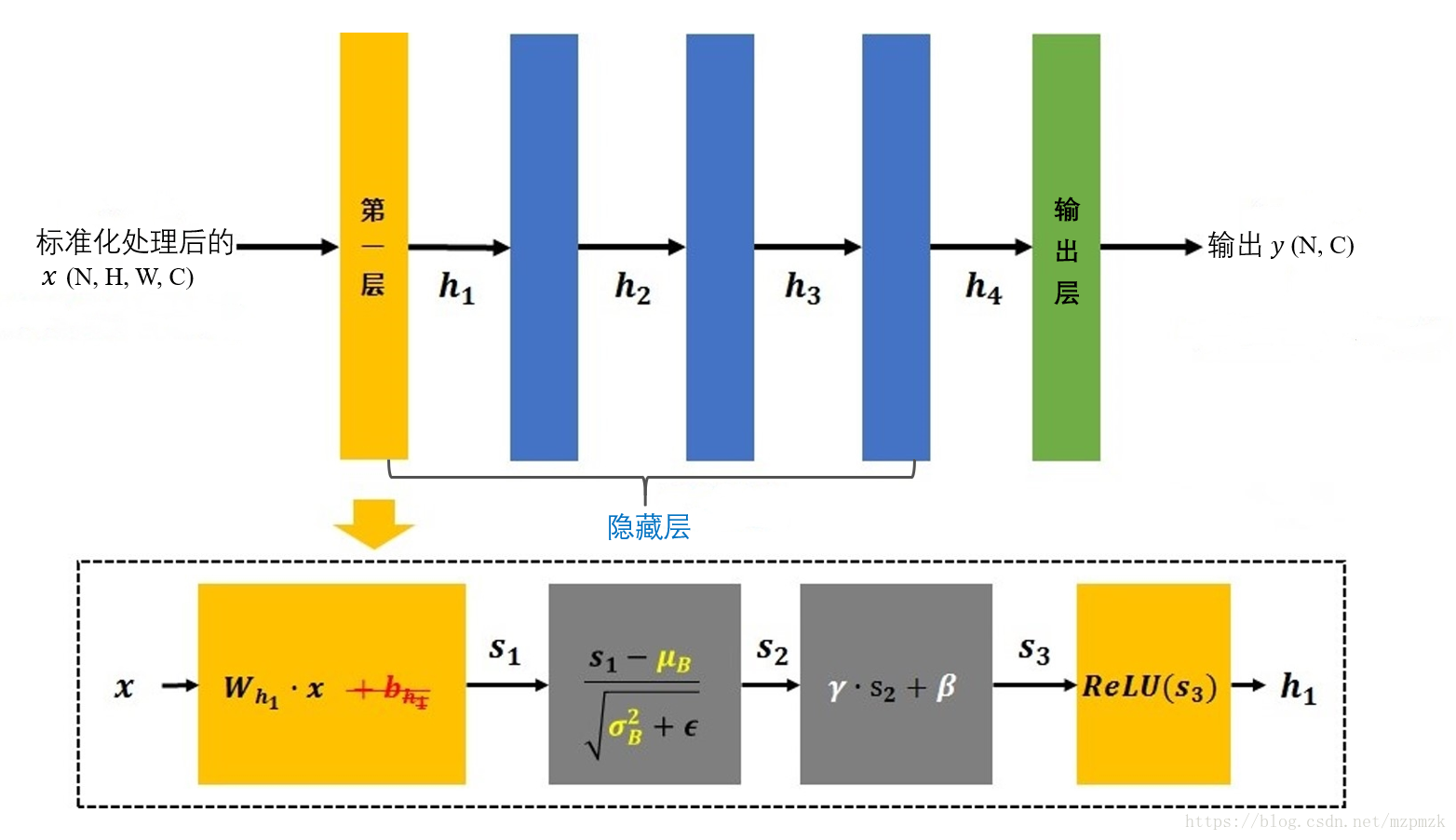
BN 的具体流程如下图所示:
- 首先,它将隐藏层的输出结果(如,第一层:Wh1 *x ,状态值)在 batch 上进行标准化;
- 然后,经过缩放(scale)和平移(shift)处理,
- 最后经过 RELU 激活函数得到h1 送入下一层(就像我们在数据预处理中将 x 进行标准化后送入神经网络的第一层一样)。

2、BN 的优点
现在几乎所有的卷积神经网络都会使用批量标准化操作,它可以为我们的网络训练带来一系列的好处。具体如下:
- 首先,通过对输入和中间网络层的输出进行标准化处理后,减少了内部神经元分布的改变,使降低了不同样本间值域的差异性,得大部分的数据都其处在非饱和区域,从而保证了梯度能够很好的回传,避免了梯度消失和梯度爆炸
- 其次,通过减少梯度对参数或其初始值尺度的依赖性,使得我们可以使用较大的学习速率对网络进行训练,从而加速网络的收敛
- 最后,由于在训练的过程中批量标准化所用到的均值和方差是在一小批样本(mini-batch)上计算的,而不是在整个数据集上,所以均值和方差会有一些小噪声产生,同时缩放过程由于用到了含噪声的标准化后的值,所以也会有一点噪声产生,这迫使后面的神经元单元不过分依赖前面的神经元单元。所以,它也可以看作是一种正则化手段,提高了网络的泛化能力,使得我们可以减少或者取消 Dropout,优化网络结构
3、BN 的使用注意事项
- BN 通常应用于输入层或任意中间层,且最好在激活函数前使用
- 使用 BN 的层不需要加 bias 项了,因为减去batch 个数据的均值 μB后, 偏置项 b 的作用会被抵消掉,其平移的功能将由 β来代替
- BN 的训练阶段均值和方差的求法:
- 全连接层:对每个节点(node) 对应的 batch 个数据(所有像素)分别求均值和方差
- 二维卷积层:对每一个 channel 所对应的 batch 个特征图(所有像素)求均值和方差,输出 C 维
- BN 层参数:mean(C 维)、variance(C 维)、moving average factor(1 维,caffe 中默认为 0.999)
- BN 的测试阶段均值和方差的求法:
测试时,使用的是 训练集 的每一个 BN 层累积下来的 均值和方差(C 维);
训练阶段使用 指数衰减滑动平均(EMA) 将每个 batch 的均值和方差不断的累积下来,从而近似得到整个样本集的均值和方差 - 指数衰减滑动平均(EMA)介绍见:指数加权移动平均(Exponential Weighted Moving Average),均值的计算公式如下(标准差的计算同理)

相关文章
- snmp协议的trap操作采用基于_maven批量导入jar包
- 【目标检测】小脚本:批量png转jpg
- Mastodon自定义表情批量导入方法
- 社会工程学 | cobalstrike批量发送钓鱼邮件方法
- 【Groovy】MOP 元对象协议与元编程 ( 方法委托 | 批量方法委托 )
- 详解提升PostgreSQL批量导数据入性能的多种方法
- Linux 批量建立目录的快捷方法(linux批量建目录)
- 处理利用Oracle处理批量数据的方法(oracle分批)
- 多条记录MySQL:批量更新多条记录(mysql同时更新)
- Linux系统中快速批量重命名文件(批量重命名linux)
- Linux 批量重命名:简便快捷的技术(批量重命名linux)
- 【Linux下批量重命名文件快速攻略】(批量重命名linux)
- Linux下批量重命名实现方法(批量重命名linux)
- 让Linux快速批量重命名的方法(批量重命名linux)
- Linux中的批量文件重命名方法(批量重命名linux)
- 快速重命名文件:Linux批量重命名的简便方法(批量重命名linux)
- Linux下批量重命名文件的有效方法(批量重命名linux)
- Linux文件批量添加后缀名的方法(linux批量加后缀名)
- 一键安装:快速搭建Linux系统集群.(批量安装linux系统)
- 快速高效!Oracle批量删除多个表的方法指南(oracle删除多个表)
- 一键批量存储快速将数据存入Redis中(批量往redis中存数据)
- 批量查询Redis一键获取所需信息(批量查询redis)
- 基于Redis的远程批量删除技术(redis远程批量删除)
- 网站被黑后处理方法及删除批量恶意代码的方法步骤
- SQLServer2005批量查询自定义对象脚本
- jscss样式操作代码(批量操作)
- ASP.NET对无序列表批量操作的三种方法小结
- python批量下载图片的三种方法
- mysql批量更新与批量更新多条记录的不同值实现方法