
停止使用 CSV 进行存储,这种文件格式快 150 倍
欢迎关注 ,专注Python、数据分析、数据挖掘、好玩工具!
CSV 不是唯一的数据存储格式。事实上,这可能是你应该考虑的最后一个。如果你不打算手动编辑保存的数据,那么坚持下去就是在浪费时间和金钱。
如果你没有对文件格式进行太多研究,收集大量数据并将它们存储在云中并选择了 CSV 进行保存,我相信你的开支将会很大!我们只需一个简单的调整可以将它们减少一半,甚至更多,这个调整是选择不同的文件格式。
今天,我将分享 Feather 数据格式的来龙去脉,它是一种用于存储数据帧的快速轻量级的二进制格式。
Feather 究竟是什么?
简而言之,它是一种用于存储数据帧的数据格式,它围绕一个简单的前提而设计:尽可能高效地将数据帧推入和推出内存,它最初是为 Python 和 R 之间的快速通信而设计的,但你不仅限于此用例。
你需要安装 feather-format 才能继续 Feather。
# Pip
pip install feather-format
# Anaconda
conda install -c conda-forge feather-format
如何在Python中使用Feather?
让我们从导入库并创建一个相对较大的数据集开始。
import feather
import numpy as np
import pandas as pd
np.random.seed = 42
df_size = 10_000_000
df = pd.DataFrame({
'a': np.random.rand(df_size),
'b': np.random.rand(df_size),
'c': np.random.rand(df_size),
'd': np.random.rand(df_size),
'e': np.random.rand(df_size)
})
df.head()

接下来我们将其保存在本地。 你可以使用以下命令将 DataFrame 保存为 Pandas 的 Feather 格式:
df.to_feather('1M.feather')
以下是对 Feather 库执行相同操作的方法:
feather.write_dataframe(df, '1M.feather')
没有太大区别。这两个文件现在都保存在本地。你可以使用 Pandas 或专用库阅读它们。
首先是 Pandas 的语法:
df = pd.read_feather('1M.feather')
如果你使用 Feather 库,请将其更改为以下内容:
df =feather.read_dataframe('1M.feather')
CSV 与 Feather,你应该使用哪一个?
如果你不需要动态更改数据,答案很简单,应该使用 Feather 而不是 CSV。让我们做一些测试。
下图显示了本地保存上一节中的 DataFrame 所需的时间:
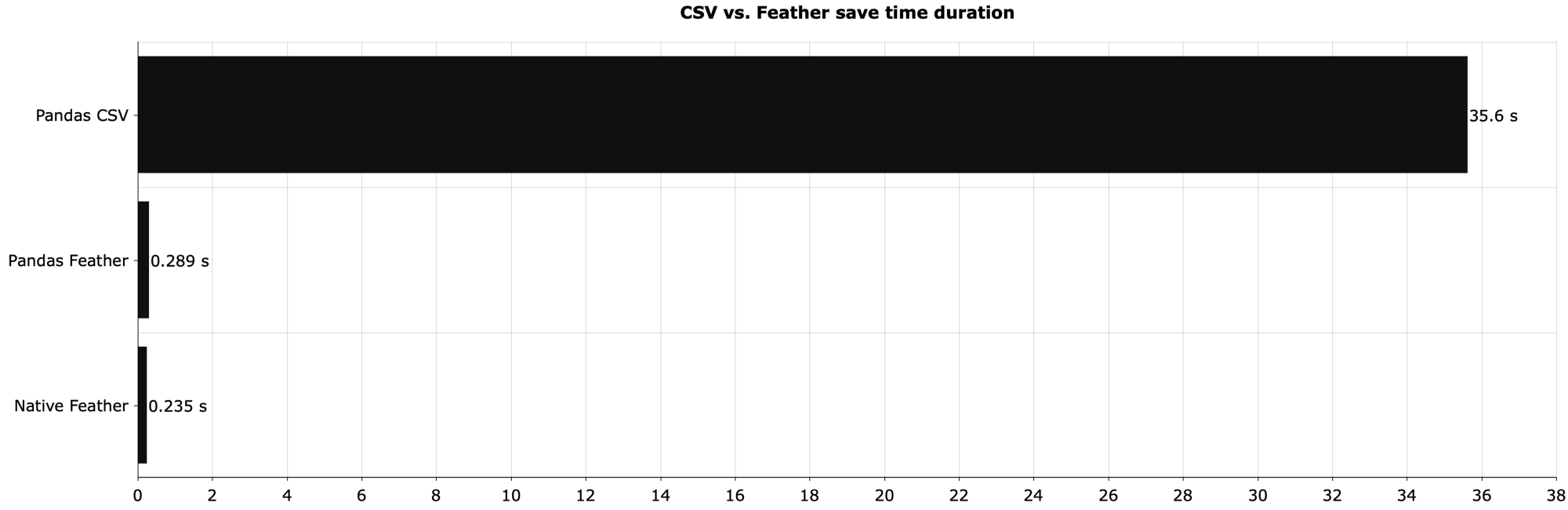
原生 Feather 比 CSV 快 150 倍左右。如果你使用 Pandas 来处理 Feather 文件并没有太大关系,但是与 CSV 相比,速度的提高是显着的。
接下来,让我们比较读取不同格式的相同数据集需要多长时间

CSV 的读取速度要慢得多。存储消耗呢?

如你所见,CSV 文件占用的空间是 Feather 文件占用的空间的两倍多。
小结
如果你每天存储千兆的数据,那么选择正确的文件格式至关重要。 Feather 在这方面摧毁了 CSV。如果你需要更多压缩,应该尝试 Parquet。 我发现它是最好的格式。总而言之,Feather 可以为你节省大量时间和磁盘空间。
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、发送如下图片至微信,长按识别,后台回复:加群;
方式②、添加微信号:pythoner666,备注:来自CSDN
方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

相关文章
- [答疑]存储分系统把处理完的结果提交给深加工系统进行进一步加工
- 存储资源盘活系统助力信创:自主可控的存储控制器
- Polardb 核心存储 polarfs 是怎么进行数据存储的(1)--译
- Polardb 核心存储 polarfs 是怎么进行数据存储的之核心构造(4)--译
- 长江存储、寒武纪等36家企业被列入美「实体清单」,自研芯片顶得住么?
- 使用Oracle XML类型进行数据存储与管理(oraclexml类型)
- 字符串MySQL如何使用字符串进行数据存储(mysql怎么存储)
- MySQL退出及其存储过程管理(mysql退出存储过程)
- Oracle中存储图片的方法(oracle存图片)
- 极速存储:Redis 数据库(redis数据存储)
- 使用LMDB和Redis进行数据存储(lmdbredis)
- MySQL中使用BLOB字段存储大文件(mysqlblob字段)
- 启动Redis,让你拥有超快速数据存储服务(redisstart)
- 使用Rails开发Web应用时如何利用MySQL进行数据存储?(mysqlrails)
- 探究Oracle索引存储:高效数据检索的秘诀(oracle索引存储)
- 华为网盘运行Linux:深度开拓云存储路径(linux 华为网盘)
- 简单步骤实现Oracle存储过程的调用(调用oracle存储过程)
- MySQL中的文本存储方式(text mysql)
- CSV文件导入MySQL从数据结构到存储实现(csv文件存入mysql)
- 基于Redis的百亿级数据存储架构设计(百亿大数据存储redis)
- 查看Redis系统中的所有存储值(查看redis所有值)
- 储存使用Redis来进行数据存储(用redis)
- 一万字之中,用Redis存储中文(一万字子中文存redis)
- MySQL数据库如何使用XML文件进行数据存储与交换(mysql xml文件)
- 安全高效用SSHRedis进行数据存储(ssh结合redis)
- redis存储必须要进行序列化吗(存redis要序列化吗)
- MySQL上机分析总结数据存储优化与索引更好方式(mysql上机分析总结)
- Redis离线落地给数据存储带来可靠保障(redis 落地文件)
- 使用Redis实现持久化的存储(redis进行持久话)
- asp下将数据库中的信息存储至XML文件中
- executesql存储过程
- 高性能Javascript笔记数据的存储与访问性能优化
- android中使用SharedPreferences进行数据存储的操作方法