
Python基于词袋模型特征和TFIDF特征进行支持向量机模型中文邮件分类项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

1.项目背景
随着互联网的发展,越来越多的用户通过互联网来交流,电子邮件成为人们日常生活交流的重要工具。用户每星期可能收到成百上千的电子邮件,但是大部分是垃圾邮件。据时代杂志估计,1994年人们发送了7760亿封电子邮件,1997年则是26000亿封,2000年更是达到了66000亿封。电子邮件特别是垃圾邮件的泛滥已经严重影响电子商务活动的正常开展。人们通常要花费很多时间对电子邮件进行处理,但效果却不明显,严重影响了正常的商务活动。对邮件进行合理的分类,为用户挑选出有意义的电子邮件是所有用户的迫切要求。
目前的邮件分类方法大多是将邮件分为垃圾邮件与非垃圾邮件,从而实现对邮件的自动过滤。本项目基于词袋模型特征和TFIDF特征进行支持向量机模型中文邮件分类,邮件类别分为正常邮件和垃圾邮件。
2.数据采集
本次建模数据来源于网络,数据项统计如下:
数据详情如下(部分展示):
正常邮件:
垃圾邮件:
每一行代表一封邮件。
3.数据预处理
3.1查看数据
print("总的数据量:", len(labels)) corpus, labels = remove_empty_docs(corpus, labels) # 移除空行 print('样本之一:', corpus[10]) print('样本的label:', labels[10]) label_name_map = ["垃圾邮件", "正常邮件"] print('实际类型:', label_name_map[int(labels[10])])结果如图所示:
4.特征工程
4.1数据集拆分
把数据集分为70%训练集和30%测试集。
4.2加载停用词
停用词列表如下,部分展示:
4.3分词
import jieba tokens = jieba.lcut(text) tokens = [token.strip() for token in tokens]结果如图所示:
训练集分词展示:
测试集分词展示:
4.4移除特殊字符
pattern = re.compile('[{}]'.format(re.escape(string.punctuation))) # re.escape就能自动处理所有的特殊符号 # string.punctuation返回所有标点符号 filtered_tokens = filter(None, [pattern.sub('', token) for token in tokens]) filtered_text = ' '.join(filtered_tokens)4.5去停用词
4.6归整化
结果如图所示:
归整化后的训练集:
归整化后的测试集:
4.7词袋模型特征提取
# min_df:在构建词汇表时,忽略那些文档频率严格低于给定阈值的术语。 # ngram_range的(1,1)表示仅使用单字符 vectorizer = CountVectorizer(min_df=1, ngram_range=ngram_range) features = vectorizer.fit_transform(corpus) # 学习词汇表字典并返回文档术语矩阵结果如图所示:
4.8 TFIDF特征提取
结果如图所示:
5.构建支持向量机分类模型
5.1基于词袋模型特征的支持向量机
5.2基于TFIDF特征的支持向量机
# 基于tfidf的支持向量机模型 print("基于tfidf的支持向量机模型") svm_tfidf_predictions = train_predict_evaluate_model(classifier=svm, train_features=tfidf_train_features, train_labels=train_labels, test_features=tfidf_test_features, test_labels=test_labels)6.模型评估
6.1评估指标及结果
评估指标主要包括准确率、查准率、查全率(召回率)、F1分值等等。
通过上表可以看到,两种特征提取的模型的准确率均为97%,F1分值均为0.97,说明模型效果良好。
6.2分类报告
结果如图所示:
基于词袋模型特征的分类报告:
类型为垃圾邮件的F1分值为0.97;类型为正常邮件的F1分值为0.97。
基于TFIDF特征的分类报告:
类型为垃圾邮件的F1分值为0.97;类型为正常邮件的F1分值为0.97。
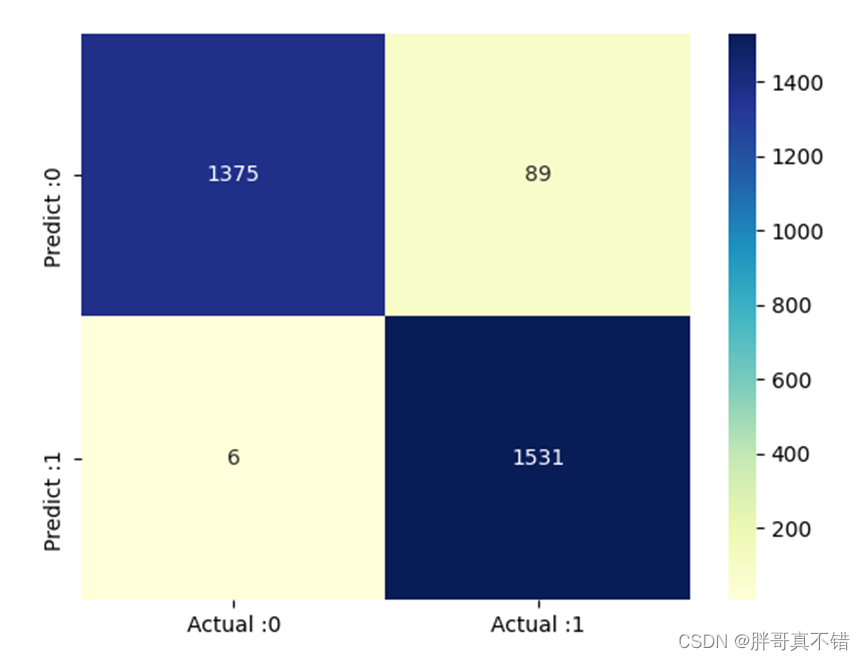
6.3混淆矩阵
# 构建数据框 cm_matrix = pd.DataFrame(data=cm, columns=['Actual :0', 'Actual :1'], index=['Predict :0', 'Predict :1']) sns.heatmap(cm_matrix, annot=True, fmt='d', cmap='YlGnBu') # 热力图展示 plt.show() # 展示图片结果如图所示:
基于词袋模型特征的分类报告:
从上图可以看到,预测为垃圾邮件 实际为正常邮件的有91封;预测为正常邮件 实际为垃圾邮件的有5封。
基于TFIDF特征的分类报告:
从上图可以看到,预测为垃圾邮件 实际为正常邮件的有89封;预测为正常邮件 实际为垃圾邮件的有6封。
7.模型预测展示
显示正确分类的邮件:
显示错误分类的邮件:
8.总结展望
本项目应用应用两种特征提取方法进行支持向量机模型中文邮件分类研究,通过数据预处理、特征工程、模型构建、模型评估等工作,最终模型的F1分值达到0.97,这在文本分类领域,是非常棒的效果,可以应用于实际工作中。























本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取码:bcbp
网盘如果失效,可以添加博主微信:zy10178083
相关文章
- Python项目目录结构
- Python解决中文乱码问题
- 为什么数据科学家们选择了Python语言?
- Python爬虫实战(三):爬网易新闻
- 更新setuptools和pip时报错Command "python setup.py egg_info" failed with error code 1 in
- Python查询Mysql时返回字典结构的代码
- Python 爬取淘宝商品数据挖掘分析实战
- python两个 list 交集,并集,差集的方法+两个tuple比较操作+两个set的交集,并集,差集操作+两个dict的比较操作
- paip.输入法编程--英文ati化By音标原理与中文atiEn处理流程 python 代码为例
- paip. 解决php 以及 python 连接access无效的参数量。参数不足,期待是 1”的错误
- Python入门教程完整版(懂中文就能学会)
- Py之jieba:Python包之jieba包(中文分词最好的组件)简介、安装、使用方法之详细攻略
- Python之tkinter:动态演示调用python库的tkinter带你进入GUI世界(Button展示图片事件)
- 【华为机试真题 Python实现】在字符串中找单词
- Python编程:Python2和Python3环境下re正则匹配中文
- Python 3 自动化运维之IPy 网络地址管理2
- python中的lambda表达
- python 2 3 读写中文文件 使用codecs最方便
- python基础===获取知乎标题时候,文件编码失败的总结
- 用 Python 写一个多进程兼容的 TimedRotatingFileHandler
- Python数字转中文
- 解决Python中文注释报错