
【NLP】第15章 从 NLP 到与任务无关的 Transformer 模型
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
到目前为止,我们已经检查了具有编码器和解码器层的原始 Transformer 模型的变体,并且我们探索了具有仅编码器或仅解码器层堆栈的其他模型。此外,层和参数的大小也增加了。然而,Transformer 的基本架构保留了其具有相同层的原始结构和注意力头计算的并行化。
在本章中,我们将探索创新的 Transformer 模型,这些模型尊重原始 Transformer 的基本结构,但会做出一些重大改变。将出现许多变形金刚模型,就像一盒乐高©碎片提供的许多可能性一样。您可以通过数百种方式组装这些部件!Transformer 模型子层和层是 LEGO ©的高级 AI 部分。
我们将首先询问在众多产品中选择哪种变压器模型以及我们将在其中实施它们的生态系统。
然后我们将在改革者模型中发现局部敏感散列( LSH ) 桶和分块。然后,我们将了解 DeBERTa 模型中的解缠结是什么。DeBERTa 还引入了另一种在解码器中管理位置的方法。DeBERTA 的大功率变压器模型超过了人类基线。
我们的最后一步将是发现强大的计算机视觉转换器,例如 Vit、CLIP 和 DALL-E。我们可以将 CLIP 和 DALL-E 添加到 OpenAI GPT-3 和 Google BERT(由 Google 训练)到非常小的基础 模型组。
这些强大的基础模型证明了 Transformer 与任务无关。转换器学习序列。这些序列包括视觉、声音和表示为序列的任何类型的数据。
图像包含类似数据的语言序列。我们将运行 ViT、CLIP 和 DALL-E 模型来学习。我们将把视觉模型提升到创新水平。
在本章结束时,您将看到与任务无关的变形金刚的世界已经演变成一个充满想象力和创造力的世界。
本章涵盖以下主题:
- 选择Transformer型号
- 重整器Transformer模型
- 局部敏感散列( LSH )
- 桶和分块技术
- DeBERTA 变压器模型
- 解开注意力
- 绝对位置
- 带有 CLIP 的文本图像视觉转换器
- DALL-E,一个创意的文本图像视觉转换器
我们的第一步是看看如何选择模型和生态系统。
选择模型和生态系统
我们认为通过下载来测试变压器模型需要机器和人力资源。另外,你可能想过如果一个平台此时还没有在线沙箱,那么由于需要测试几个示例,因此走得更远是有风险的。
但是,Hugging Face 等网站会实时自动下载预训练模型,我们将在The Reformer和DeBERTa部分看到!那么,我们应该怎么做呢?多亏了这一点,我们可以在 Google Colab 中运行 Hugging Face 模型,而无需自己在机器上安装任何东西。我们还可以在线测试 Hugging Face 模型。
这个想法是在没有任何“安装”的情况下进行分析。2022 年的“无需安装”可能意味着:
- 在线运行变压器任务
- 在预装的 Google Colaboratory VM 上运行转换器,无缝下载任务的预训练模型,我们可以在几行内运行它
- 通过 API 运行转换器
“安装”的定义在过去几年中有所扩展。“在线”的定义扩大。我们可以考虑使用几行将 API 作为元在线测试运行的代码。
在本节中,我们将广义地提及“无需安装”和“在线”。图 15.1展示了我们应该如何“在线”测试模型:
图 15.1:在线测试变压器模型
这十年的测试变得灵活且富有成效,如下所示:
- Hugging Face 托管 API 模型,例如 DeBERTa 和其他一些模型。此外,Hugging Face 提供 AutoML 服务,用于在其生态系统中训练和部署 Transformer 模型。
- OpenAI 的 GPT-3 引擎在在线游乐场上运行并提供 API。OpenAI 提供了涵盖许多 NLP 任务的模型。这些模型不需要训练。GPT-3 的十亿参数零射击引擎令人印象深刻。它表明具有许多参数的变压器模型总体上会产生更好的结果。Microsoft Azure、Google Cloud AI、AllenNLP 和其他平台提供有趣的服务。
- 如果值得,可以通过阅读论文来完成在线模型分析。一个很好的例子是 Google 的Fedus等人 (2021) 发表的关于Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity 的文章。Google 增加了我们在第 8 章中研究的基于 T5 的模型的大小,将 Transformers 应用于法律和财务文档以进行 AI 文本摘要。这篇论文证实了 GTP-3 等大型在线模型的策略。
但是,最终,您是冒险选择一种解决方案而不是另一种解决方案的人。时间你花在探索平台上一旦您做出选择,模型将帮助您优化项目的实施。
您可以通过三种不同的方式托管您的选择,如图 15.2 所示:
- 在使用 API 的本地计算机上。OpenAI、Google Cloud AI、Microsoft Azure AI、Hugging Face 等提供了很好的 API。应用程序可以在本地机器上而不是在云平台上,但可以通过带有 API 的云服务。
- 在云端平台,例如Amazon Web Services ( AWS ) 或 Google Cloud。您可以在这些平台上训练、微调、测试和运行模型。在这种情况下,本地计算机上没有应用程序。一切都在云端。
- 从任何地方使用 API!在本地机器、数据中心虚拟机或任何地方。这意味着 API 将集成到物理系统中,例如风车、飞机、火箭或自动驾驶汽车。因此,该系统可以通过 API 与另一个系统永久连接。
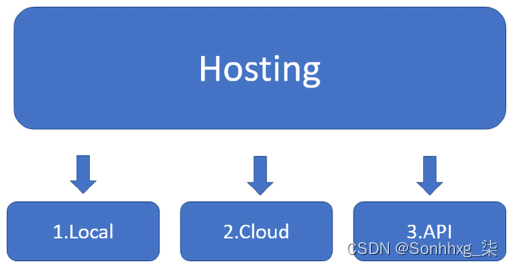
图 15.2:模型的实现选项
最后,它是由您决定。带上你的时间。测试、分析、计算成本,并作为一个团队倾听不同的观点。您对变压器的工作原理了解得越多,您做出的选择就会越好。
现在让我们探索一下重整器,它是原始 Transformer 模型的一种变体。
改革者(The Reformer)
基塔耶夫等人。(2020) 设计了 Reformer 来解决注意力和记忆问题,为原始 Transformer 模型增加了功能。
改革者首先解决了局部敏感散列( LSH ) 桶和分块的注意力问题。
LSH 搜索对于数据集中的最近邻居。散列函数确定如果数据点q接近p,则散列( q ) ==散列( p )。在这种情况下,数据点是变压器模型头部的关键。
LSH 函数在称为 LSH 分桶的过程中将键转换为 LSH桶(图 15.3中的B1到B4),就像我们将彼此相似的对象放入相同的排序桶中一样。
已排序的桶被分成块(图 15.3中的C1到C4)以进行并行化。最后,attention 只会应用在同一个bucket中的chunk和前一个chunk中:
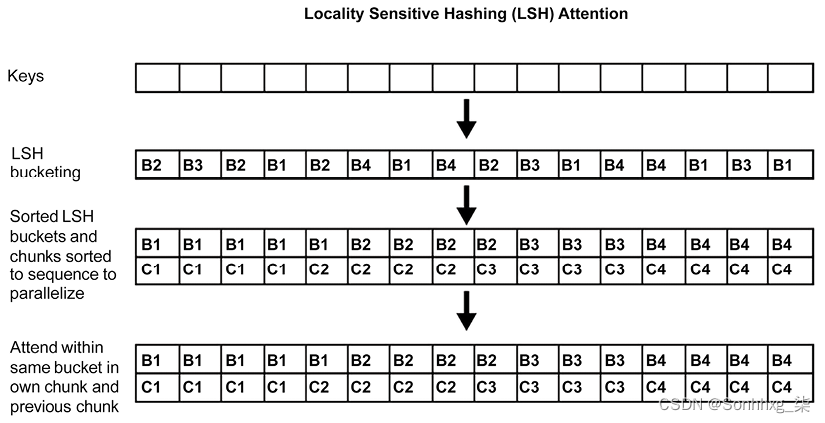 图 15.3:LSH 注意力头
图 15.3:LSH 注意力头
LSH 分桶并且分块大大降低了复杂度,从O ( L 2 ),关注所有单词对,到O ( L log L ),只关注每个桶的内容。
Reformer 还解决了重新计算每一层输入的内存问题,而不是存储多层模型的信息。重新计算是按需实现的,而不是为一些大型多层模型消耗 TB 的内存。
我们现在将使用在Fyodor Dostoevsky的Crime and Punishment的英文翻译上训练的改革者模型。
运行示例
让我们使用托管的推理 API 直接在线运行它。输入语句为:
The studentwas impoverished and did not know what to do.
在线界面的链接包含输入:
google/reformer-crime-and-punishment · Hugging Face
托管推理 API 与输入句子一起出现。点击compute获取推论,结果会出现在输入的正下方:

图 15.4:Reformer 的托管推理 API
由于算法是随机的,您可能会得到不同的响应。改革者接受了合理的训练,尽管不是像 OpenAI 的 GPT-3 那样拥有数十亿位信息的超级计算机。改革者的结果不是很令人印象深刻。需要更多的训练和微调才能获得更好的结果。
OpenAI 的 GPT-3 引擎为文本完成产生以下结果:
那个学生很穷,不知道该怎么办。他没有人可以求助,也找不到住处。他从包里拿出一个本子,开始写。他写了:
"My name is XXXXXXXXXX. I am a student at XXXXXXXXXX. I have no family, no friends, no money."
结果是更有说服力。注册后即可访问 OpenAI 的游乐场:https ://openai.com/
注意:OpenAI GPT-3 与其他变压器模型和大多数深度学习模型一样,基于随机算法。结果可能因人而异。
这表明,包含数十亿参数的训练有素的变压器模型可以胜过创新的变压器模型架构。
超级计算机驱动的云 AI 平台会逐渐超越本地尝试,甚至是功能更弱的云平台吗?在投资一种解决方案而不是另一种解决方案之前,您需要通过原型解决这些问题。
注意:变压器模型的随机性在运行它们时可能会产生不同的结果。此外,在线平台不断改变其界面。我们需要接受并适应。
DeBERTa 介绍了另一种创新架构,我们现在将对其进行探索。
DeBERTa
另一个新的可以通过解开找到变压器的方法。AI中的解缠结允许您分离表示特征,使训练过程更加灵活。Pengcheng He、Xiaodong Liu、 Jianfeng Gao和Weizhu Chen设计了 DeBERTa,一个解开的变压器版本,以及在一篇有趣的文章中描述了该模型:DeBERTa:Decoding-enhanced BERT with Disentangled Attention:https ://arxiv.org/abs/2006.03654
DeBERTa 中实现的两个主要思想是:
- 解开transformer模型中的内容和位置,分别训练两个向量
- 在解码器中使用绝对位置来预测预训练过程中的掩码标记
作者在 GitHub 上提供代码:https ://github.com/microsoft/DeBERTa
DeBERTa 在 SuperGLUE 排行榜上超过了人类基线:
 图 15.5:SuperGLUE 排行榜上的 DeBERTa
图 15.5:SuperGLUE 排行榜上的 DeBERTa
在 Hugging Face 的云平台上运行示例之前,删除所有空格。
运行示例
运行一个Hugging Face 的云平台示例,点击以下链接:
cross-encoder/nli-deberta-base · Hugging Face
托管推理 API 将显示一个示例和可能的类名输出:
 图 15.6:DeBERTa 的托管推理 API
图 15.6:DeBERTa 的托管推理 API
可能的类名是mobile、website、billing和account access。
结果很有趣。让我们将其与 GPT-3 关键字任务进行比较。首先,在https://openai.com/上注册
输入Text作为输入并Keywords要求引擎查找关键字:
文字:Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.
关键词:app, overheating, phone
可能的关键字是app、overheating和phone。
我们已经使用了 DeBERTa 和 GPT-3 变压器。我们现在将把转换器扩展到视觉模型。
从与任务无关的模型到视觉转换器
基础模型,正如我们在第 1 章中看到的,什么是变形金刚?, 有两个截然不同的独特性质:
- 出现——符合基础模型的变压器模型可以执行他们没有接受过培训的任务。它们是在超级计算机上训练的大型模型。他们没有像许多其他模型一样接受过学习特定任务的训练。基础模型学习如何理解序列。
- 同质化——相同的模型可以在许多领域使用相同的基础架构。基础模型可以比任何其他模型更快、更好地通过数据学习新技能。
GPT-3 和 Google BERT(仅限 Google 训练的 BERT 模型)是与任务无关的基础楷模。这些与任务无关的模型直接导致 ViT、CLIP 和 DALL-E 模型。变形金刚具有不可思议的序列分析能力。
Transformer 模型的抽象层次导致了多模态神经元:
图 15.7:图像可以被编码成类似单词的标记
在本节中,我们将介绍:
让我们从探索 ViT 开始,这是一种将图像处理为词块的视觉转换器。
ViT – 视觉变形金刚
多索维茨基等人。(2021) 总结了他们的视觉转换器架构的精髓在他们的论文标题中设计:图像值得 16x16 字:大规模图像识别的变形金刚。
图像可以转换为 16x16 字的补丁。
在查看代码之前,让我们先看看 ViT 的架构。
ViT的基本架构
视觉转换器可以将图像处理为词块。在本节中,我们将分三个步骤完成该过程:
- 将图像分割成补丁
- 补丁的线性投影
- 混合输入嵌入子层
第一步是将图像分割成大小相等的块。
第 1 步:将图像分割成补丁
图片被分成n 个块,如图 15.8所示。没有规定有多少个补丁,只要所有补丁具有相同的尺寸,例如 16x16:
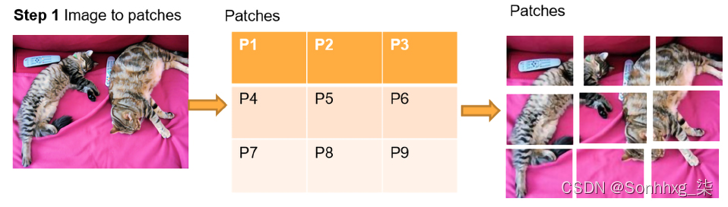 图 15.8:将图像分割成块
图 15.8:将图像分割成块
这相同维度的块现在代表我们序列的单词。如何处理这些补丁的问题仍然存在。我们将看到每种类型的视觉转换器都有自己的方法。
图片引用:本节和后续部分中使用的猫的图片由DocChewbacca拍摄:https ://www.flickr.com/photos/st3f4n/ ,于 2006 年。它在 Flickr 免费许可下,https:// creativecommons.org/licenses/by-sa/2.0/。更多详情,请参阅DocChewbacca在 Flickr 上的图片:https ://www.flickr.com/photos/st3f4n/210383891
在这种情况下,对于 ViT,步骤 2将是对扁平图像进行线性投影。
第 2 步:平面图像的线性投影
第 1 步将图像转换为相同大小的补丁。补丁的动机是避免逐像素处理图像。然而,问题仍然是找到一种处理补丁的方法。
Google Research 的团队决定设计一个扁平图像的线性投影,并使用通过分割图像获得的补丁,如图 15.9所示:

图 15.9:扁平图像的线性投影
这个想法是获得一系列类似工作的补丁。剩下的问题是嵌入平面图像序列。
第三步:混合输入嵌入子层
Google Research 决定使用混合输入模型来完成这项工作,如图 15.10所示:
- 添加卷积网络以嵌入补丁的线性投影
- 添加位置编码以保留原始图像的结构
- 然后使用标准的原始类 BERT 编码器处理嵌入的输入
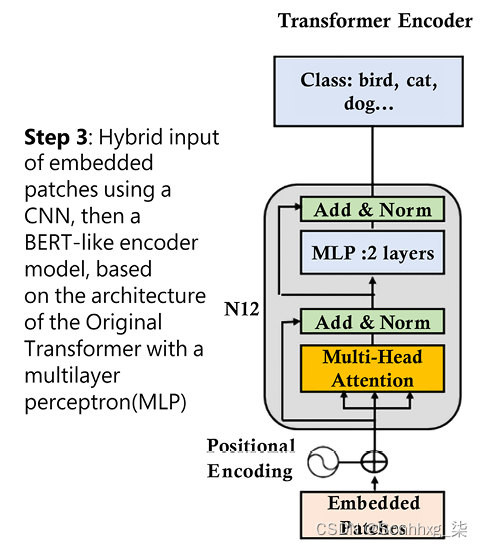
图 15.10:混合输入子层和标准编码器
Google Research 发现了一种将 NLP 转换器模型转换为视觉转换器的巧妙方法。
现在,让我们在代码中实现一个视觉转换器的 Hugging Face 示例。
代码中的视觉转换器
在这个部分,我们将重点关注与视觉转换器特定架构相关的主要代码区域。
Open Vision_Transformers.ipynb,位于本章的 GitHub 存储库中。
Google Colab VM 包含许多预安装的软件包,例如torch和torchvision. 您可以通过在笔记本的第一个单元格中取消注释命令来显示它们:
#Uncomment the following command to display the list of pre-installed modules
#!pip list -v 然后转到笔记本的Vision Transformer ( ViT ) 单元。笔记本首先安装 Hugging Face 转换器并导入必要的模块:
!pip install transformers
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests注意:在撰写本书时,Hugging Face 警告我们,由于不断的演变,代码可能会变得不稳定。这不应该阻止我们探索 ViT 模型。测试新领域是最前沿的全部内容!
然后我们从 COCO 数据集中下载图像。如果您想进一步试验,您可以在他们的网站上找到全面的数据集:https ://cocodataset.org/
让我们从 VAL2017 数据集下载。按照 COCO 数据集网站的说明通过程序获取这些图像或将数据集下载到本地。
VAL2017 包含 5,000 张图像,我们可以从中选择来测试这个 ViT 模型。您可以运行 5,000 个图像中的任何一个。
让我们用猫的图像测试笔记本。我们首先通过它们的 URL 检索猫的图像:
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)我们接下来下载谷歌的特征提取器和分类模型:
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')该模型在 224 x 244 分辨率的图像上进行了训练,但使用 16 x 16 的补丁进行特征提取和分类。笔记本运行模型并做出预测:
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:",predicted_class_idx,": ", model.config.id2label[predicted_class_idx])输出是:
Predicted class: 285 : Egyptian catmodel.config.id2label,它将列出类的标签。1000 个标签类别解释了为什么我们获得一个类别而不是详细的文本描述:{0: 'tench, Tinca tinca',1: 'goldfish, Carassius auratus', 2: 'great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias',3: 'tiger shark, Galeocerdo cuvieri',...,999: 'toilet tissue, toilet paper, bathroom tissue'}model,它将显示以混合使用卷积输入子层开始的模型架构:(embeddings): ViTEmbeddings( (patch_embeddings): PatchEmbeddings( (projection): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16)) )
在卷积输入嵌入子层之后,模型是一个类似 BERT 的编码器。
带上你的是时候探索这种从 NLP 变换器到图像变换器的创新转变了,这会很快导致所有事物的变换器。
现在,让我们看看另一个计算机视觉模型 CLIP。
CLIP
对比语言图像预训练( CLIP ) 遵循transformers的哲学。它插其转换器类型层中的数据序列。这一次,模型不发送文本对,而是发送文本-图像对。一旦数据被标记化、编码和嵌入,CLIP(一个与任务无关的模型)就可以像学习任何其他数据序列一样学习文本-图像对。
该方法是对比的,因为它寻找图像特征的对比。这是我们在一些杂志游戏中使用的方法,我们必须在其中找到两个图像之间的差异和对比。
在查看代码之前,让我们先看看 CLIP 的架构。
CLIP的基本架构
对比:图像受过训练,以了解他们如何通过他们的差异和相似之处组合在一起。图像和字幕通过(联合文本、图像)预训练找到彼此的方式。预训练后,CLIP 学习新任务。
CLIP 是可转移的,因为它们可以学习新的视觉概念,例如 GPT 模型,例如视频序列中的动作识别。字幕导致无穷无尽的应用。
ViT 将图像分割成类似单词的补丁。CLIP 联合训练文本和图像编码器的(标题、图像)对以最大化余弦相似度,如图 15.11所示:
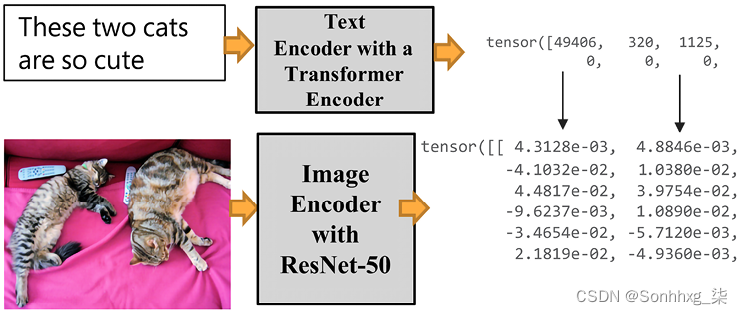 图 15.11:联合训练文本和图像
图 15.11:联合训练文本和图像
图 15.11显示了转换器如何为文本运行标准转换器编码器输入。它将为变压器结构中的图像运行 ResNet 50 层 CNN。ResNet 50 被修改为在具有多头 QKV 注意力头的注意力池机制中运行平均池层。
让我们看看 CLIP 如何学习文本图像序列来进行预测。
CLIP in code
Open Vision_Transformers.ipynb,位于 GitHub 上本章的存储库中。然后转到CLIP笔记本的单元格。
该程序首先安装 PyTorch 和 CLIP:
!pip install ftfy regex tqdm
!pip install git+https://github.com/openai/CLIP.git该程序还导入模块和 CIFAR-100 以访问图像:
import os
import clip
import torch
from torchvision.datasets import CIFAR100有 10,000 张图像可用,索引在 0 到 9,999 之间。下一步是选择我们要运行预测的图像:

图 15.12:选择图像索引
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)图片已下载:
# Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)输入准备:
# Prepare the inputs
image, class_id = cifar100[index]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)让我们在运行预测之前可视化我们选择的输入:
import matplotlib.pyplot as plt
from torchvision import transforms
plt.imshow(image)输出显示这index 15是一头狮子:
图 15.13:索引 15 的图像
本节中的图像来自于从小图像中学习多层特征,Alex Krizhevsky,2009:https ://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf 。它们是数据集 ( ) 的一部分:CIFAR-10https ://www.cs.toronto.edu/~kriz/cifar.htmlCIFAR-100toronto.edu
我们知道这是一头狮子,因为我们是人类。最初为 NLP 设计的转换器必须了解图像是什么。我们现在将看到它识别图像的能力。
这程序表明它在计算特征时通过将图像输入与文本输入分开来运行联合变换器模型:
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)现在 CLIP 进行预测并显示前五个预测:
# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)
# Print the result
print("\nTop predictions:\n")
for value, index in zip(values, indices):
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")topk(5)如果要获得更多或更少的预测,您可以进行修改。显示前五个预测:
Top predictions:
lion: 96.34%
tiger: 1.04%
camel: 0.28%
lawn_mower: 0.26%
leopard: 0.26%下一个单元格显示类:
cifar100.classes您可以浏览这些类,看到每个类只有一个标签,这是限制性的,CLIP 做得很好:
[...,'kangaroo','keyboard','lamp','lawn_mower','leopard','lion',
'lizard', ...]该笔记本包含其他几个描述您可以探索的 CLIP 架构和配置的单元格。
该model单元格特别有趣,因为您可以看到视觉编码器以像 ViT 模型一样的卷积嵌入开始,然后继续作为具有多头注意力的“标准”尺寸 768 转换器:
CLIP(
(visual): VisionTransformer(
(conv1): Conv2d(3, 768, kernel_size=(32, 32), stride=(32, 32), bias=False)
(ln_pre): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(transformer): Transformer(
(resblocks): Sequential(
(0): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)其他单元格的有趣方面model是查看与图像编码器联合运行的 size-512 文本编码器:
(transformer): Transformer(
(resblocks): Sequential(
(0): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)浏览描述架构、配置和参数的单元格,了解 CLIP 如何表示数据。
我们展示了与任务无关的转换器模型将图像-文本对处理为文本-文本对。我们可以将与任务无关的模型应用于音乐-文本、声音-文本、音乐-图像和任何类型的数据对。
我们现在将探索 DALL-E,这是另一个可以处理图像和文本的与任务无关的 Transformer 模型。
DALL-E
DALL-E 与 CLIP 一样,是一个与任务无关的模型。CLIP 处理的文本图像对。DALL-E 处理文本和图像标记不同。DALL-E 的输入是包含 1,280 个标记的单个文本和图像流。256 个标记用于文本,1,024 个标记用于图像。DALL-E 是类似于 CLIP 的基础模型。
DALL-E 以萨尔瓦多·达利和皮克斯的 WALL-E 命名。DALL-E 的用途是输入文本提示并生成图像。但是,DALL-E 必须首先学习如何生成带有文本的图像。
DALL-E 是 GPT-3 的 120 亿参数版本。
该转换器使用文本图像对的数据集从文本描述中生成图像。
DALL-E的基本架构
与 CLIP 不同,DALL-E将多达 256 个 BPE 编码的文本标记与 32×32 = 1,024 个图像标记连接起来,如图 15.14所示:
 图 15.14:DALL-E 连接文本和图像输入
图 15.14:DALL-E 连接文本和图像输入
图 15.14显示这一次,我们的猫图像与输入文本连接在一起。
DALL-E 有一个编码器和一个解码器堆栈,它是用在变压器模型中注入卷积函数的混合架构构建的。
让我们看看代码,看看模型是如何工作的。
代码中的 DALL-E
打开Vision_Transformers.ipynb. 然后转到DALL-E笔记本的单元格。笔记本首先安装OpenAI DALL-E:
!pip install DALL-E笔记本下载图像并处理图像:
import io
import os, sys
import requests
import PIL
import torch
import torchvision.transforms as T
import torchvision.transforms.functional as TF
from dall_e import map_pixels, unmap_pixels, load_model
from IPython.display import display, display_markdown
target_image_size = 256
def download_image(url):
resp = requests.get(url)
resp.raise_for_status()
return PIL.Image.open(io.BytesIO(resp.content))
def preprocess(img):
s = min(img.size)
if s < target_image_size:
raise ValueError(f'min dim for image {s} < {target_image_size}')
r = target_image_size / s
s = (round(r * img.size[1]), round(r * img.size[0]))
img = TF.resize(img, s, interpolation=PIL.Image.LANCZOS)
img = TF.center_crop(img, output_size=2 * [target_image_size])
img = torch.unsqueeze(T.ToTensor()(img), 0)
return map_pixels(img)该程序现在加载 OpenAI DALL-E 编码器和解码器:
# This can be changed to a GPU, e.g. 'cuda:0'.
dev = torch.device('cpu')
# For faster load times, download these files locally and use the local paths instead.
enc = load_model("https://cdn.openai.com/dall-e/encoder.pkl", dev)
dec = load_model("https://cdn.openai.com/dall-e/decoder.pkl", dev)我添加了enc和dec单元格,以便您可以查看编码器和解码器块以了解如何这种混合模型有效:转换器模型中的卷积功能以及文本和图像输入的连接。
本节中处理的图像是mycat.jpg(创建者:丹尼斯罗斯曼,保留所有权利,复制它需要书面许可)。该图像位于Chapter15本书存储库的目录中。它被下载并处理:
x=preprocess(download_image('https://github.com/Denis2054/AI_Educational/blob/master/mycat.jpg?raw=true'))最后,我们显示原始图像:
display_markdown('Original image:')
display(T.ToPILImage(mode='RGB')(x[0]))输出显示图像:

图 15.15:猫的图像
import torch.nn.functional as F
z_logits = enc(x)
z = torch.argmax(z_logits, axis=1)
z = F.one_hot(z, num_classes=enc.vocab_size).permute(0, 3, 1, 2).float()
x_stats = dec(z).float()
x_rec = unmap_pixels(torch.sigmoid(x_stats[:, :3]))
x_rec = T.ToPILImage(mode='RGB')(x_rec[0])
display_markdown('Reconstructed image:')
display(x_rec)重建后的图像看起来与原始图像极为相似:

图 15.16:DALL-E 重建猫的图像
结果令人印象深刻。DALL-E 学会了如何自己生成图像。
完整的DALL-E 源代码在本书写作时不可用,而且可能永远不会可用。用于从文本提示生成图像的 OpenAI API 尚未上线。但请睁大眼睛!
与此同时,我们可以在https://openai.com/blog/dall-e/继续在 OpenAI 上发现 DALL-E
到达该页面后,向下滚动到提供的示例。例如,我选择了一张旧金山阿拉莫广场的照片作为提示:
 图 15.17:旧金山阿拉莫广场的提示
图 15.17:旧金山阿拉莫广场的提示
然后我将“在晚上”修改为“在早上”:

图 15.18:修改提示
 图 15.19:从文本提示生成图像
图 15.19:从文本提示生成图像
我们已经实现了 ViT、CLIP 和 DALL-E,三个视觉转换器。在我们结束之前,让我们来看看一些最后的想法。
不断扩大的模型世界
几乎每周都会出现新的变压器模型,例如新的智能手机。其中一些模型对于项目经理来说既令人兴奋又具有挑战性:
- ERNIE是一个持续的预训练框架,为语言理解产生令人印象深刻的结果。
论文:https ://arxiv.org/abs/1907.12412
挑战:Hugging Face 提供了一个模型。它是一个成熟的模型吗?它是百度在 SuperGLUE 排行榜(2021 年 12 月)上训练超过人类基线的那一个:https ://super.gluebenchmark.com/leaderboard ?我们是否可以获得最好的模型或只是玩具模型?在如此小的模型版本上运行 AutoML 的目的是什么?我们会在百度平台或类似平台上访问它吗?它要花多少钱?
- SWITCH:万亿参数使用稀疏建模优化的模型。
论文:https ://arxiv.org/abs/2101.03961
挑战:这篇论文很棒。模型在哪里?我们是否可以访问真正经过全面训练的模型?它要花多少钱?
- XLNET是预训练的像 BERT,但作者认为它超过了 BERT 模型的性能。
论文:https ://proceedings.neurips.cc/paper/2019/file/dc6a7e655d7e5840e66733e9ee67cc69-Paper.pdf
挑战:XLNET 是否真的超过了 Google BERT 的性能,Google 用于他们的活动的版本?我们是否可以使用 Google BERT 或 XLNET 模型的最佳版本?
名单变得无穷无尽,而且还在不断增长!
除了前面提到的问题之外,对它们进行全部测试仍然是一个挑战。只有少数变压器模型有资格作为基础模型。基础模型必须是:
- 接受过全面培训以完成各种任务
- 能够执行未受过训练的任务,因为它已经达到了独特的 NLU 水平
- 足够大以保证相当准确的结果,例如 OpenAI GPT-3
许多网站提供的变压器被证明对教育目的有用,但不能被认为是经过充分培训和大到有资格进行基准测试。
最好的方法是尽可能加深对变压器模型的理解。在某一时刻,您将成为专家,在科技创新丛林中找到自己的出路就像选择智能手机一样简单!
概括
新的变压器型号不断出现在市场上。因此,通过阅读出版物和书籍并测试一些系统来跟上前沿研究是一种很好的做法。
这导致我们评估选择哪些变压器模型以及如何实现它们。我们不能花几个月的时间来探索市场上出现的每一个模型。如果项目正在生产中,我们不能每个月都更换模型。工业 4.0 正在转向无缝的 API 生态系统。
学习所有模型是不可能的。但是,通过加深我们对变压器模型的了解,可以快速理解一个新模型。
变压器模型的基本结构保持不变。编码器和/或解码器堆栈的层保持相同。注意力头可以并行化以优化计算速度。
Reformer 模型应用LSH存储桶和分块。它还重新计算每一层的输入而不是存储信息,从而优化内存问题。然而,像 GPT-3 这样的十亿参数模型对于相同的示例会产生可接受的结果。
DeBERTa 模型解开了内容和位置,使训练过程更加灵活。结果令人印象深刻。然而,像 GPT-3 这样的十亿参数模型可以等于 DeBERTa 的输出。
ViT、CLIP 和 DALL-E 将我们带入了任务无关的文本图像视觉转换器模型的迷人世界。结合语言和图像产生新的和富有成效的信息。
问题仍然在于,即用型人工智能和自动化系统能走多远。我们将在下一章关于超人类的兴起中尝试想象基于变压器的人工智能的未来。
相关文章
- 苹果发布新模型GAUDI:只用文字就能生成无限制3D模型!
- 直播丨零基础入门机器学习:线性回归模型
- 广义线性模型(GLM)及其应用
- 模型继承
- 支持向量机SVM模型
- 基于LSTM的股票预测模型_python实现_超详细
- Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
- 任务执行模型ACT-1,你的贴心小管家
- 微软研究院推出通用多模式基础模型“BEIT-3”,可在视觉和视觉语言任务上实现最先进的迁移性能
- 微信自研NLP大规模语言模型WeLM:零/少样本即可完成多种NLP任务
- NeurlPS 2022 | 全新大模型参数高效微调方法SSF:仅需训练0.3M的参数,效果卓越
- 组合优化(二):换手约束下的最优模型
- 【数据挖掘】数据挖掘算法 组件化思想 ( 模型或模式结构 | 数据挖掘任务 | 评分函数 | 搜索和优化算法 | 数据管理策略 )
- 【计算机网络】应用层 : 网络应用模型 ( 应用层概述 | 客户端 / 服务器 模型 | P2P 模型 )
- 9亿训练集、通用CV任务,微软打造Florence模型打破分类、检索等多项SOTA
- 横扫六大权威榜单后,达摩院把自家深度语言模型体系AliceMind开源了
- 【C 语言】字符串模型 ( 两头堵模型 )
- Linux设备驱动开发模型简介(linux驱动设备模型)
- Linux下的高效异步I/O模型:kqueue详解(linuxkqueue)