
KaliLinux-利用theHarvester进行信息收集
利用 进行 信息 收集 kalilinux
2023-09-14 09:05:18 时间
theHarvester简介
theHarvester是Kali自带的一款社会工程学工具,其工作原理是利用网络爬虫技术通过不同公开源中(如baidu、google等搜索引擎,PGP服务器、Shodan数据库等)收集e-mail、用户名、主机名、子域名、雇员、开放端口和Banner等信息。
附:国内无法使用google搜索引擎,你懂的。
theHarvester的目的是帮助渗透测试人员在渗透测试的早期阶段对目标进行互联网资料采集,同时也帮助人们了解自己的个人信息在互联网公开的情况。
软件使用起来简单,且效果显著。
启动页面,见下图:

theHarvester 参数详解
-h, --help show this help message and exit 显示帮助信息并退出
-d, --domain DOMAIN Company name or domain to search. 要搜索的公司名称或域名
-l, --limit LIMIT Limit the number of search results, default=500. 采集特定数量的结果,不指定情况下,默认为500
-S, --start START Start with result number X, default=0. 从采集到的信息编号“X”处开始执行采集,默认从0开始
-g, --google-dork Use Google Dorks for Google search. 使用google Dorks进行google搜索。 (一般情况下不用,你懂的)
-p, --proxies Use proxies for requests, enter proxies in proxies.yaml. 对信息采集的请求使用代理
-s, --shodan Use Shodan to query discovered hosts. 使用shodan查询发现的主机
--screenshot Take screenshots of resolved domains specify output directory: 对解析域的页面进行截图,需指定截图文件存放目录
--screenshot output_directory 截图保存目录
-v, --virtual-host Verify host name via DNS resolution and search for virtual hosts. 通过DNS解析主机名并搜索虚拟主机(没搞懂)
-e, --dns-server DNS_SERVER DNS server to use for lookup. 指定DNS解析服务器
-t, --dns-tld DNS_TLD Perform a DNS TLD expansion discovery, default False. 执行DNS TLD扩展发现,默认为False状态
-r, --take-over Check for takeovers. 检查接管???(我估计可能是设置一个指定的标地信息,当采集到该标地信息的时候停止采集进程,也不晓得对不对,哪位小伙伴知道的话欢迎留言)
-n, --dns-lookup Enable DNS server lookup, default False. 启用DNS服务器查找,默认为False状态
-c, --dns-brute Perform a DNS brute force on the domain. 进行DNS域解析暴力破解???
-f, --filename Save the results to an HTML and/or XML file. 指定输出文件名,格式支持HTML和XML
-b SOURCE, --source SOURCE
baidu, bing, bingapi, bufferoverun, certspotter, crtsh, dnsdumpster, duckduckgo, exalead, github-code, google, hackertarget, hunter, intelx,
linkedin, linkedin_links, netcraft, otx, pentesttools, projectdiscovery, qwant, rapiddns, securityTrails, spyse, sublist3r, threatcrowd, threatminer,
trello, twitter, urlscan, virustotal, yahoo 指定采集信息的源(如百度,必应,必应API,github-code,谷歌,推特等)
常用参数
-d:指定搜索的域名或网址
-b:指定采集信息的源(如baidu,biying,google)
-l:指定采集信息的返回数量,默认500
-f:输出文件名并保存采集结果,可以保存为HTML或XML格式;如果不指定,采集信息仅作屏幕显示
使用案例
theHarvester -d pinduoduo.com -l 400 -b baidu -f /usr/local/pinduoduo.html
命令行输出结果如下:

XML文件输出结果如下:
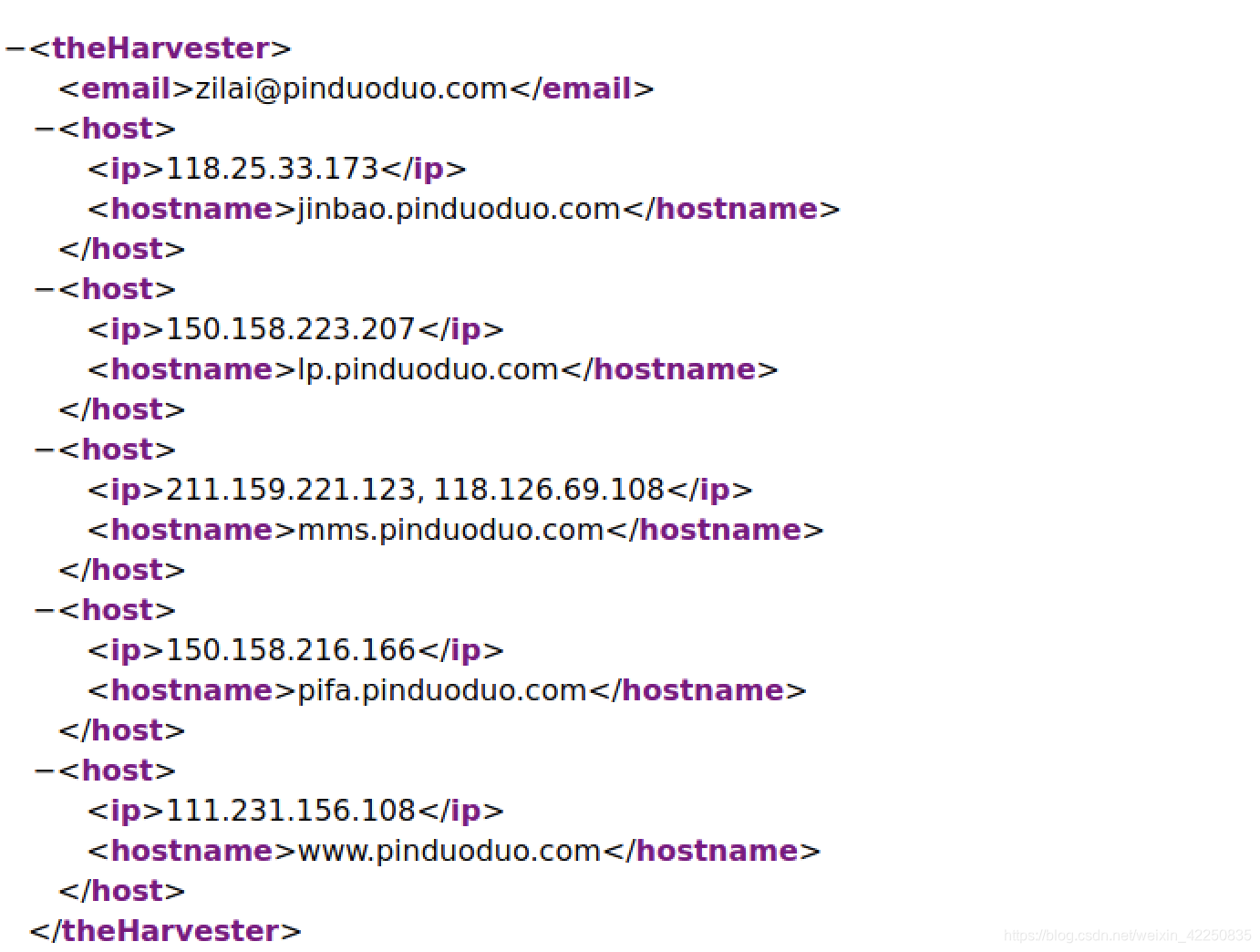
HTML输出结果如下:

相关文章
- 案例实操 | 利用Lambda函数来进行特征工程,超方便的!!
- 利用飞桨技术引领废钢判级行业新格局
- IJCAI2022: 利用随机游走进行聚合的图神经网络
- JAVA利用HttpClient进行HTTPS接口调用详解编程语言
- 利用Oracle 11g建立数据表(oracle11g建表)
- 报告利用Linux MTR报告进行网络质量分析(linuxmtr)
- 如何有效利用Oracle小时?(oracle小时)
- 利用SQL Server锁定机制进行性能优化分析(sqlserver锁分析)
- 编辑利用Linux Awk实现高效的行编辑操作(linux awk 行)
- 如何利用MYSQL进行空间扩展?一些简单的方法可以有效地将MYSQL的空间利用最大化。本文探讨了关于MYSQL空间扩展的重要方面。(mysql空间扩展)
- Linux如何利用刷新指令快速更新系统(Linux刷新指令)
- 利用Oracle从数据库导出CSV文件(oracle 写入csv)
- 利用MySQL中的Using进行优化查询(mysql 中using)
- 利用Redis轻松去重(用redis实现去重)
- 保障系统安全利用Redis进行灾备(灾备redis)
- 利用Oracle临时表快速写入数据(oracle临时表写数据)
- 利用Oracle会话计算能力加速业务处理(oracle会话计算机)
- 利用Redis进行阻塞队列设置(redis阻塞队列设置)
- 优化利用Redis设置服务命令进行优化(redis 设置服务命令)
- 利用JS获取IE客户端IP及MAC的实现好象不可以