
python毕设案例教学: 基于数据挖掘在京东客户评价方面的研究与应用
2023-09-14 09:05:34 时间
前言
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章

完整源码、素材皆可点击文章下方名片获取此处跳转
开发环境:
-
Python 3.8
-
Pycharm

模块使用:
-
requests >>> pip install requests 第三方模块
-
csv>>> 内置模块,无需安装
安装模块:win + R 输入cmd 输入安装命令 pip install 模块名
如果出现爆红 可能是因为 网络连接超时 切换国内镜像源

基本思路:
一. 数据来源分析
-
明确需求:
-
明确采集网站
-
明确采集数据
商品评论相关的信息
-
-
分析 商品评论相关的信息 请求那个链接可以获取
浏览器自带工具: 开发者工具 <一定要分析清楚采集的数据在什么地方>
-
打开开发者工具: F12 / 右键点击检查选择network
-
点击第二页评论内容: 可以直接找到对应数据包
-

二. 代码实现步骤 --> 实现单页数据采集
-
发送请求, 模拟浏览器对于url地址发送请求
-
获取数据, 获取服务器返回响应数据 response
-
解析数据, 提取我们想要的数据内容 --> 评论信息
-
保存数据, 把评论信息保存表格文件里面
采集评论数据
导入模块
# 导入数据请求模块 --> 需要安装 pip install requests
import requests
# 导入格式化输出模块 --> 内置模块, 不需要安装
from pprint import pprint
# 导入csv模块
import csv
# 导入时间模块
import time
# 导入随机模块
import random
创建文件
f = open('口红20.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'昵称',
'商品',
'评分',
'购买时间',
'评论时间',
'plus会员',
'内容',
])
写入表头
csv_writer.writeheader()
多页采集
for page in range(0, 20):
print(f'正在采集第{page}页的数据内容')
延时操作 random.randint(1, 2) --> 随机生成 1或者2
time.sleep(random.randint(1, 2))
请求链接
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100011323932&score=0&sortType=5&page=3&pageSize=10&isShadowSku=0&rid=0&fold=1'
请求参数 --> 字典数据类型
data = {
'callback': 'fetchJSON_comment98',
'productId': '100011323932',
'score': '0',
'sortType': '5',
'page': page,
'pageSize': '10',
'isShadowSku': '0',
'rid': '0',
'fold': '1',
}
模拟浏览器 headers
headers = {
# user-agent 用户代理 表示浏览器基本上身份信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
发送请求
response = requests.get(url=url, params=data, headers=headers)
print(response.text)
break
# # for循环遍历, 一个一个提取列表里面元素
# for index in response.json()['comments']:
# if index['plusAvailable'] == 201:
# Vip = '是'
# else:
# Vip = '不是'
# dit = {
# '昵称': index['nickname'],
# '商品': index['productColor'],
# '评分': index['score'],
# '购买时间': index['referenceTime'],
# '评论时间': index['creationTime'],
# 'plus会员': Vip,
# '内容': index['content'].replace('\n', ''),
# }
# # 写入数据 字典方式进行保存
# csv_writer.writerow(dit)
# print(dit)

评论分析
import pandas as pd
df = pd.read_csv('data.csv', encoding='gbk')
df.head()

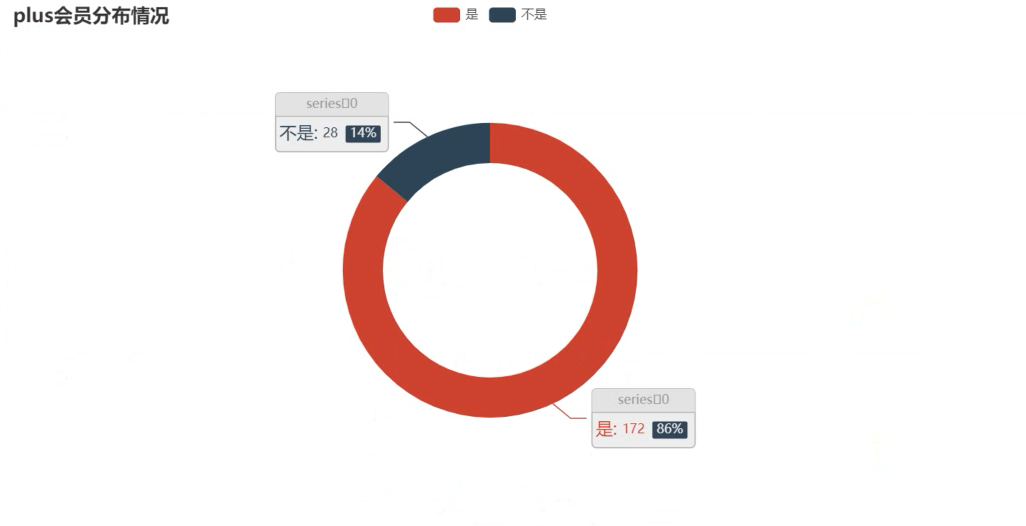
VipNum = df['plus会员'].value_counts().to_list()
VipType = df['plus会员'].value_counts().index.to_list()
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie()
.add(
"",
[list(z) for z in zip(VipType, VipNum)],
radius=["40%", "55%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_global_opts(title_opts=opts.TitleOpts(title="plus会员分布情况"))
# .render("pie_rich_label.html")
)
c.render_notebook()
d = (
Pie()
.add(
series_name="plus会员",
data_pair=[list(z) for z in zip(VipType, VipNum)],
radius=["50%", "70%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="legft", orient="vertical"))
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
# label_opts=opts.LabelOpts(formatter="{b}: {c}")
)
)
d.render_notebook()

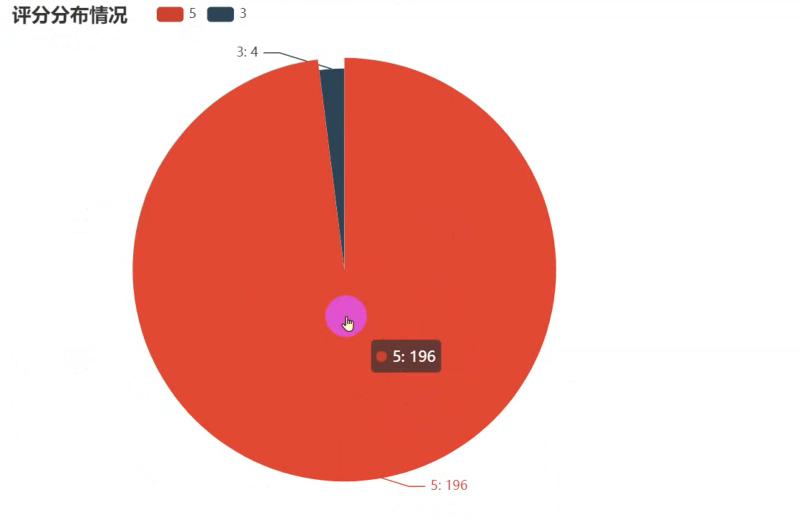
scoreNum = df['评分'].value_counts().to_list()
scoreType = df['评分'].value_counts().index.to_list()
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
score = (
Pie()
.add(
"",
[list(z) for z in zip(scoreType, scoreNum)],
center=["35%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="评分分布情况"),
legend_opts=opts.LegendOpts(pos_left="15%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
score.render_notebook()
# df['购买时间'] = df['购买时间'].str[:-6]
# BuyDateNum = df['购买时间'].value_counts().to_list()
# BuyDateType = df['购买时间'].value_counts().index.to_list()
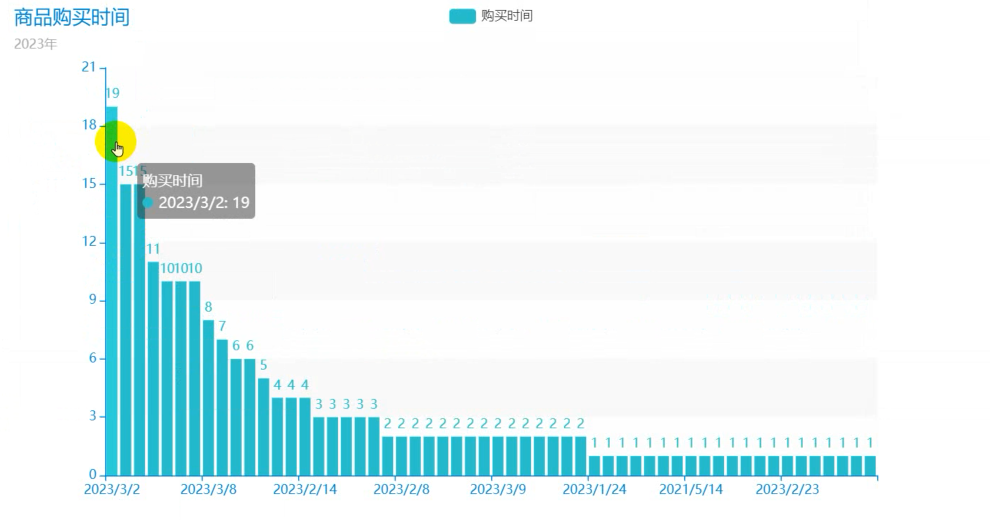
BuyDateNum = df['购买时间'].str[:-6].value_counts().to_list()
BuyDateType = df['购买时间'].str[:-6].value_counts().index.to_list()
from pyecharts.charts import Bar
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType
BuyDate = (
Bar({"theme": ThemeType.MACARONS})
.add_xaxis(BuyDateType)
.add_yaxis("购买时间", BuyDateNum)
.set_global_opts(
title_opts={"text": "商品购买时间", "subtext": "2023年"}
)
# .render("bar_base_dict_config.html")
)
BuyDate.render_notebook()
import jieba
string = ' '.join([i for i in df['评论']])
words = jieba.lcut(string)
# 统计词频
word_count = {}
for word in words:
if word not in word_count:
word_count[word] = 1
else:
word_count[word] += 1
word_list = list(zip(word_count.keys(),word_count.values()))
word_list
df['商品'] = df['商品'].replace(regex='【.*?】', value='')
ShopNum = df['商品'].value_counts().to_list()[:7]
ShopType = df['商品'].value_counts().index.to_list()[:7]
ShopType
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.commons.utils import JsCode
from pyecharts.faker import Faker
c = (
Bar()
.add_xaxis(ShopType)
.add_yaxis("商品", ShopNum, category_gap="60%")
.set_series_opts(
itemstyle_opts={
"normal": {
"color": JsCode(
"""new echarts.graphic.LinearGradient(0, 0, 0, 1, [{
offset: 0,
color: 'rgba(0, 244, 255, 1)'
}, {
offset: 1,
color: 'rgba(0, 77, 167, 1)'
}], false)"""
),
"barBorderRadius": [30, 30, 30, 30],
"shadowColor": "rgb(0, 160, 221)",
}
}
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="口红款式", subtitle="DIRO"),
)
)
c.render_notebook()

import pyecharts.options as opts
from pyecharts.charts import WordCloud
wc = (
WordCloud()
.add(series_name="词云分析", data_pair=word_list, word_size_range=[6, 66])
.set_global_opts(
title_opts=opts.TitleOpts(
title="词云分析", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
# .render("basic_wordcloud.html")
)
wc.render_notebook()

from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
c = (
WordCloud()
.add("", word_list, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="WordCloud-shape-diamond"))
# .render("wordcloud_diamond.html")
)
c.render_notebook()
尾语 💝
好了,今天的分享就差不多到这里了!
完整代码、更多资源、疑惑解答直接点击下方名片自取即可。
对下一篇大家想看什么,可在评论区留言哦!看到我会更新哒(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!

相关文章
- python装饰器的应用案例
- Python-装饰器-案例-获取文件列表
- Python语言学习:Python语言学习之程序打包发布(exe/msi等)&如何将自己的Python项目(自定义程序代码库)发布到PyPI全流程的简介、案例应用之详细攻略
- Python语言学习:Python语言学习之网络爬虫/反爬虫技术相关的简介、案例应用之详细攻略
- Python语言学习:Python语言学习之python包/库package的简介(模块的封装/模块路径搜索/模块导入方法/自定义导入模块实现华氏-摄氏温度转换案例应用)、使用方法、管理工具之详细攻略
- Python语言学习:Python语言学习之列表/元祖/字典/集合的简介、案例应用之详细攻略
- Python编程语言学习:python中与数字相关的函数(取整等)、案例应用之详细攻略
- Python:Python语言的简介(语言特点/pyc介绍/Python版本语言兼容问题(python2 VS Python3))、安装、学习路线(数据分析/机器学习/网页爬等编程案例分析)之详细攻略
- NLP之ASR:基于pyaudio利用python进行语音生成、语音识别总结及其案例详细攻略
- Python语言学习:Python语言学习之容器(列表&元组&字典&集合)简介、特点/意义/经验总结及容器魔法方法(定义可变&不可变容器的协议)的简介、案例应用之详细攻略
- Python语言学习:Python语言学习之python包/库package的简介(模块的封装/模块路径搜索/模块导入方法/自定义导入模块实现华氏-摄氏温度转换案例应用)、使用方法、管理工具之详细攻略
- Python语言学习:Python语言学习之列表/元祖/字典/集合的简介、案例应用之详细攻略
- Python语言学习:Python语言学习之数据类型/变量/字符串/操作符/转义符的简介、案例应用之详细攻略
- Python之matplotlib:利用matplotlib绘制八象空间三维图案例(知识点包括散点图、折线图、标注文字、图例、三维坐标)之详细攻略
- Python语言学习:复杂函数(yield/@property)使用方法、案例应用之详细攻略
- Python语言学习之图表可视化:python语言中可视化工具包的简介、安装、使用方法、经典案例之详细攻略
- Computer:字符编码(ASCII编码/GBK编码/BASE64编码/UTF-8编码)的简介、案例应用(python中的编码格式及常见编码问题详解)之详细攻略
- 〖Python接口自动化测试实战篇⑧〗- 小案例 - 使用python实现接口请求 [查询天行数据]
- python数据分析小案例:把招聘数据做可视化处理~
- 实战案例丨分布式系统中如何用python实现Paxos
- 超级实用案例,Python 提取 PDF 指定内容生成新PDF
- python面向对象编程: 搬家具案例
- Python开发入门之了解Python高阶函数
- python高级在线题目训练-第一套-主观题
- Python基础实践案例-学生信息管理系统