
C++QT开发——多线程
多线程
1. 线程概念的起源
1.1 单核 CPU
在早期的单核 CPU 时代还没有线程的概念,只有进程。操作系统作为一个大的“软件”,协调着各个硬件(如CPU、内存,硬盘、网卡等)有序的工作着。在双核 CPU 诞生以前,我们用的 Windows 操作系统依然可以一边用 word 写文档一边听着音乐,作为整个系统唯一可以完成计算任务的 CPU 是如何保证两个进程“同时进行”的呢?时间片轮转调度!
注意这个关键字「轮转」。每个进程会被操作系统分配一个时间片,即每次被 CPU 选中来执行当前进程所用的时间。时间一到,无论进程是否运行结束,操作系统都会强制将 CPU 这个资源转到另一个进程去执行。为什么要这样做呢?因为只有一个单核 CPU,假如没有这种轮转调度机制,那它该去处理写文档的进程还是该去处理听音乐的进程?无论执行哪个进程,另一个进程肯定是不被执行,程序自然就是无运行的状态。如果 CPU 一会儿处理 word 进程一会儿处理听音乐的进程,起初看起来好像会觉得两个进程都很卡,但是 CPU 的执行速度已经快到让人们感觉不到这种切换的顿挫感,就真的好像两个进程在“并行运行”。

如上图所示,每一个小方格就是一个时间片,大约100ms。假设现在我同时开着 Word、QQ、网易云音乐三个软件,CPU 首先去处理 Word 进程,100ms时间一到 CPU 就会被强制切换到 QQ 进程,处理100ms后又切换到网易云音乐进程上,100ms后又去处理 Word 进程,如此往复不断地切换。我们将其中的 Word 单独拿出来看,如果时间片足够小,那么以人类的反应速度看就好比最后一个处理过程,看上去就会有“CPU 只处理 Word 进程”的幻觉。随着芯片技术的发展,CPU 的处理速度越来越快,在保证流畅运行的情况下可以同时运行的进程越来越多。
本文福利,莬费领取Qt开发学习资料包、技术视频,内容包括(C++语言基础,Qt编程入门,QT信号与槽机制,QT界面开发-图像绘制,QT网络,QT数据库编程,QT项目实战,QT嵌入式开发,Quick模块等等)↓↓↓↓↓↓见下面↓↓文章底部点击莬费领取↓↓
1.2 多核 CPU
随着运行的进程越来越多,人们发现进程的创建、撤销与切换存在着较大的时空开销,因此业界急需一种轻型的进程技术来减少开销。于是上世纪80年代出现了一种叫 SMP(Symmetrical Multi-Processing)的对称多处理技术,就是我们所知的线程概念。线程切换的开销要小很多,这是因为每个进程都有属于自己的一个完整虚拟地址空间,而线程隶属于某一个进程,与进程内的其他线程一起共享这片地址空间,基本上就可以利用进程所拥有的资源而无需调用新的资源,故对它的调度所付出的开销就会小很多。
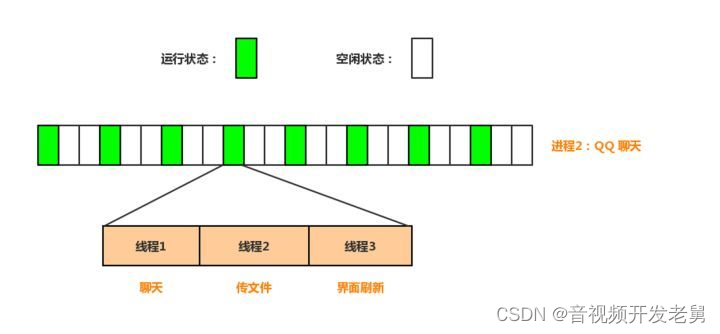
以 QQ 聊天软件为例,上文我们一直都在说不同进程如何流畅的运行,此刻我们只关注一个进程的运行情况。如果没有线程技术的出现,当 QQ 这个进程被 CPU “临幸”时,我是该处理聊天呢还是处理界面刷新呢?如果只处理聊天,那么界面就不会刷新,看起来就是界面卡死了。有了线程技术后,每次 CPU 执行100ms,其中30ms用于处理聊天,40ms用于处理传文件,剩余的30ms用于处理界面刷新,这样就可以使得各个组件可以“并行”的运行了。于是乎我们可以提炼出两点关于多线程的适用场景:
- 通过使用多核 CPU 提高处理速度。
- 保证 GUI 界面流畅运行的同时可以执行其他计算任务。
2. Qt线程操作
Qt的线程类为QThread,是独立于平台的线程操作类。
基本操作函数
//获取当前线程对象地址
[static] QThread *QThread::currentThread()
//获取可在系统上运行的理想线程数。 这是通过查询系统中实际的和逻辑的处理器核数来完成的。 如果无法检测到处理器核数,则该函数返回1。
[static] int QThread::idealThreadCount()
//强制当前线程休眠n毫秒。
[static] void QThread::msleep(unsigned long msecs)
//强制当前线程休眠n秒
[static] void QThread::sleep(unsigned long secs)
//强制当前线程休眠n微秒
[static] void QThread::usleep(unsigned long usecs)
//放弃执行当前线程, 把机会让给别的线程,注意,操作系统决定切换到哪个线程。
[static] void QThread::yieldCurrentThread() 使用线程
Qt 多线程有三种方式
第一种:静态函数
QThread有两个静态成员函数create,创建一个新的QThread对象,它将使用参数args执行函数f。(必须在C++17及以上才可以使用)
[static] QThread *QThread::create(Function &&f, Args &&... args) //C++17
[static] QThread *QThread::create(Function &&f)新线程没有启动——它必须通过显式调用start()来启动。 这允许您连接到它的信号,将QObjects移动到线程,选择新线程的优先级,等等。 函数f将在新线程中被调用。
注意:不要对返回的QThread实例多次调用start(); 这样做将导致未定义的行为。
全局、类的静态、非静态函数做入口函数
void print()
{
for(int i = 0;i<5;i++)
qInfo()<<"hello global print";
}
class MainWindow:public QWidget
{
Q_OBJECT
public:
MainWindow(QWidget*parent = nullptr):QWidget(parent)
{
qInfo()<<"end";
}
static void print1()
{
for(int i = 0;i<5;i++)
qInfo()<<"hello static print1";
}
void print2()
{
for(int i = 0;i<5;i++)
qInfo()<<"hello print2";
}
};- QThread::create使用全局函数作为入口函数。
auto* thr = QThread::create(print);
thr->start();- QThread::create使用类的静态函数作为入口函数。
auto* thr1 = QThread::create(&MainWindow::print1);
thr1->start();- QThread::create使用类的非静态函数作为入口函数。
auto* thr2 = QThread::create(&MainWindow::print2,&w);
thr2->start();- QThread::create使用lambda表达式作为入口函数。
auto* thr3 = QThread::create([](){qInfo()<<"hello lambda";});
thr3->start();给入口函数传参
void print(const QString& str)
{
for(int i = 0;i<5;i++)
qInfo()<<"hello global print"<<str;
}
auto* thr = QThread::create(print,"I Like Qt");
thr->start();信号
[signal] void QThread::started()线程开始执行
[signal] void QThread::finished()信号执行完毕,该信号可以连接到QObject::deleteLater(),以释放该线程中的对象。
void fun()
{
for(int i =0;i<100;i++)
{
QThread::msleep(20);
qDebug()<<"i:"<<i;
}
}
QThread *thr = QThread::create(fun);
QObject::connect(thr,&QThread::started,[](){qDebug()<<"start";});
QObject::connect(thr,&QThread::finished,[=](){thr->deleteLater();qDebug()<<"finished";});
thr->start();第二种:继承QThread
QThread类中有一个virtual函数QThread::run(),要创建一个新的线程,我们只需定义一个MyThread类,让其继承QThread,然后重新实现QThread::run()。
run函数是线程的起始点。 在调用start()之后,新创建的线程调用这个函数。 默认实现只是调用exec()。
MyThread.h
#include <QThread>
class MyThread : public QThread
{
Q_OBJECT
public:
explicit MyThread(QObject *parent = nullptr);
~MyThread();
protected:
void run() override;
signals:
};本文福利,莬费领取Qt开发学习资料包、技术视频,内容包括(C++语言基础,Qt编程入门,QT信号与槽机制,QT界面开发-图像绘制,QT网络,QT数据库编程,QT项目实战,QT嵌入式开发,Quick模块等等)↓↓↓↓↓↓见下面↓↓文章底部点击莬费领取↓↓
MyThread.cpp
#include "mythread.h"
#include<QDebug>
MyThread::MyThread(QObject *parent)
: QThread(parent)
{}
MyThread::~MyThread()
{
qDebug()<< "MyThread::~MyThread()";
}
void MyThread::run()
{
int i= 0;
while(i<200)
{
QThread::msleep(20);
if(i==150)
break;
qDebug()<<"i"<<i++;
}
}Widget.cpp
#include "widget.h"
#include<QDebug>
#include<QThread>
Widget::Widget(QWidget *parent)
: QWidget(parent)
, ui(new Ui::Widget)
{
ui->setupUi(this);
thr = new MyThread(this);
connect(thr,&QThread::started,this,[](){qDebug()<<"start";});
connect(thr,&QThread::finished,this,[](){qDebug()<<"finished";});
thr->start();
}
Widget::~Widget()
{
thr->quit();
delete thr;
delete ui;
}第三种:移动到线程
QThread是被设计来作为一个操作系统线程的接口和控制点,而不是用来写入你想在线程里执行的代码的地方。我们(面向对象程序员)编写子类,是因为我们想扩充或者特化基类中的功能。我唯一想到的继承QThread类的合理原因,是添加QThread中不包含的功能,比如,也许可以提供一个内存指针来作为线程的堆栈,或者可以添加实时的接口和支持。用于下载文件、查询数据库,或者做任何其他操作的代码都不应该被加入到QThread的子类中;它应该被封装在它自己的对象中。
你可以简单地把类从继承QThread改为继承QObject。为了让你的代码实际运行在新线程的作用域中,你需要实例化一个QThread对象,并且使用moveToThread()函数将你的对象分配给它。你同过moveToThread()来告诉Qt将你的代码运行在特定线程的作用域中,让线程接口和代码对象分离。
暂时不考虑多线程,先思考这样一个问题:想想我们平时会把耗时操作代码放在哪里?一个类中。那么有了多线程后,难道我们要把这段代码从类中剥离出来单独放到某个地方吗?显然这是很糟糕的做法。QObject 中的 moveToThread() 函数可以在不破坏类结构的前提下依然可以在新线程中运行。
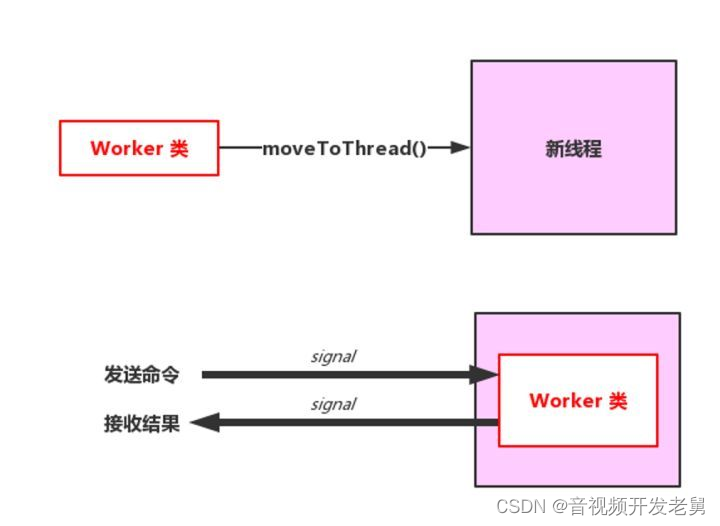
移动线程步骤
- 首先创建一个工作对象,需要注意不能指定父对象。 Worket *worker = new Worker;
- 创建一个Qthread子线程对象 QThread *thread = new QThread(this);
- 把我们的自定义线程类,加入到子线程(若是worker 指定了父对象,此处就会出错。) worker ->moveToThread(thread);
- 启动子线程,只是把线程开启了,并没有启动线程处理函数 thread.start();
- 启动线程处理函数,必须通过signal - slot的方式。
class Worker : public QObject
{
Q_OBJECT
public slots:
void doWork(const QString ¶meter) {
QString result;
/* ... here is the expensive or blocking operation ... */
emit resultReady(result);
}
signals:
void resultReady(const QString &result);
};
class Controller : public QObject
{
Q_OBJECT
QThread workerThread;
public:
Controller() {
Worker *worker = new Worker;
worker->moveToThread(&workerThread);
connect(&workerThread, &QThread::finished, worker, &QObject::deleteLater);
connect(this, &Controller::operate, worker, &Worker::doWork);
connect(worker, &Worker::resultReady, this, &Controller::handleResults);
workerThread.start();
}
~Controller() {
workerThread.quit();
workerThread.wait();
}
public slots:
void handleResults(const QString &);
signals:
void operate(const QString &);
};再谈 moveToThread()
“移动到新线程”是一个很形象的描述,作为入门的认知是可以的,但是它的本质是改变线程亲和性(也叫关联性)。为什么要强调这一点?这是因为如果你天真的认为 Worker 类对象整体都移动到新线程中去了,那么你就会本能的认为 Worker 类对象的控制权是由新线程所属,然而事实并不是如此。「在哪创建就属于哪」这句话放在任何地方都是适用的。比如上一节的例子中,Worker 类对象是在 Controller 类中创建并初始化,因此该对象是属于主线程的。而 moveToThread() 函数的作用是将槽函数在指定的线程中被调用。当然,在新线程中调用函数的前提是该线程已经启动处于就绪状态,所以在上一节的 Controller 构造函数中,我们把各种信号槽连接起来后就可以启动新线程了。
使用 moveToThread() 有一些需要注意的地方,首先就是类对象不能有父对象,否则无法将该对象“移动”到新线程。如果类对象保存在栈上,自然销毁由操作系统自动完成;如果是保存在堆上,没有父对象的指针要想正常销毁,需要将线程的 finished() 信号关联到 QObject 的 deleteLater() 让其在正确的时机被销毁。其次是该对象一旦“移动”到新线程,那么该对象中的计时器(如果有 QTimer 等计时器成员变量)将重新启动。不是所有的场景都会遇到这两种情况,但是记住这两个行为特征可以避免踩坑。
3. 启动线程前的准备工作
3.1 开多少个线程比较合适?
说“开线程”其实是不准确的,这种事儿只有操作系统才能做,我们所能做的是管理其中一个线程。无论是 QThread thread 还是 QThread *thread,创建出来的对象仅仅是作为操作系统线程的接口,用这个接口可以对线程进行一些操作。虽然这样说不准确,但下文我们仍以“开线程”的说法,只是为了表述方便。
我们来思考这样一个问题:“线程数是不是越大越好”?显然不是,“开”一千个线程是没有意义的。线程的切换是要消耗系统资源的,频繁的切换线程会使性能降低。线程太少的话又不能完全发挥 CPU 的性能。一般后端服务器都会设置最大工作线程数,不同的架构师有着不同的经验,有些业务设置为 CPU 逻辑核心数的4倍,有的甚至达到32倍。
在 Venkat Subramaniam 博士的《Programming Concurrency on the JVM》这本书中提到关于最优线程数的计算,即线程数量 = 可用核心数/(1 - 阻塞系数)。可用核心数就是所有逻辑 CPU 的总数,这可以用 QThread::idealThreadCount() 静态函数获取,比如双核四线程的 CPU 的返回值就是4。但是阻塞系数比较难计算,这需要用一些性能分析工具来辅助计算。如果只是粗浅的计算下线程数,最简单的办法就是 CPU 核心数 * 2 + 2。更为精细的找到最优线程数需要不断的调整线程数量来观察系统的负载情况。
3.2 设置栈大小
每个线程都有自己的栈,彼此独立,由编译器分配。一般在 Windows 的栈大小为2M,在 Linux 下是8M。
Qt 提供了获取以及设置栈空间大小的函数:stackSize()、setStackSize(uint stackSize)。其中 stackSize() 函数不是返回当前所在线程的栈大小,而是获取用 stackSize() 函数手动设置的栈大小。如果是用编译器默认的栈大小,该函数返回0,这一点需要注意。为什么要设置栈的大小?这是因为有时候我们的局部变量很大(常见于数组),当超过编译器默认大小时程序就会因为栈溢出而报错,这时候就需要手动设置栈大小了。
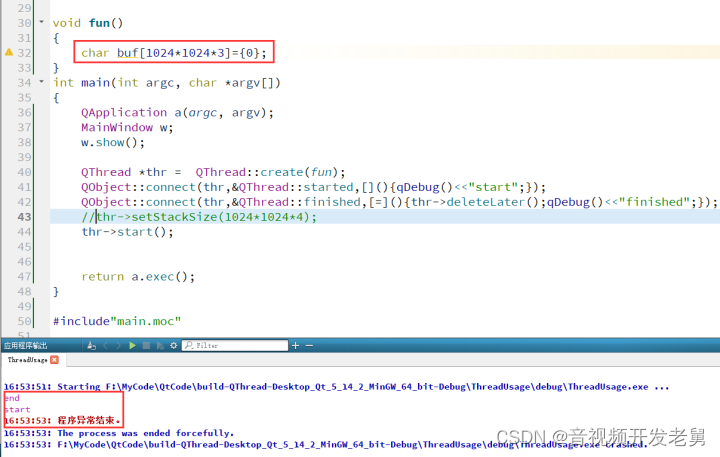
本文福利,莬费领取Qt开发学习资料包、技术视频,内容包括(C++语言基础,Qt编程入门,QT信号与槽机制,QT界面开发-图像绘制,QT网络,QT数据库编程,QT项目实战,QT嵌入式开发,Quick模块等等)↓↓↓↓↓↓见下面↓↓文章底部点击莬费领取↓↓
在 Windows操作系统环境下,假如我们在线程入口函数fun()中添加一个3M大小的数组 array,可以看出在程序运行时会由于栈溢出而导致异常退出,因为 Windows默认的栈空间仅为2M。
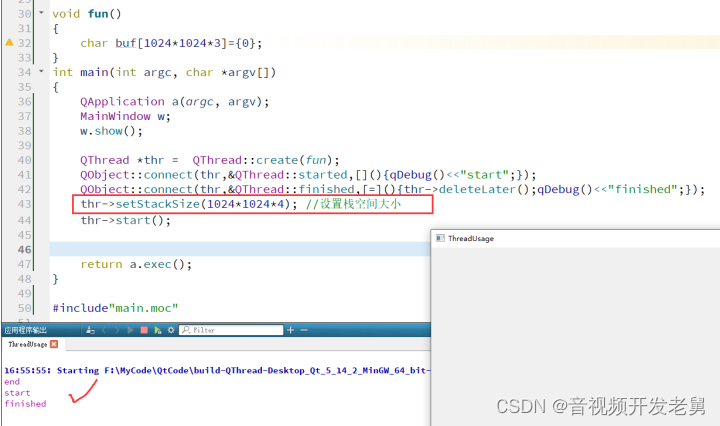
如果我们设置了栈大小为4M,那么程序会正常运行,不会出现栈溢出的问题。
4. 启动线程/退出线程
4.1 启动线程
调用 start() 函数就可以启动函数在新线程中运行,运行后会发出 started() 信号。
在上面的使用线程中我们知道将耗时函数放入新线程有QThread::create()、 moveToThread() 和继承 QThread 且重新实现 run() 函数三种方式。有这么一种情况:此时我有 fun1() 和 fun2() 两个耗时函数,将 fun1() 中的代码放入 run() 函数,而将 fun2() 以 moveToThread() 的方式也放到这个线程中。那新线程该运行哪个函数呢?其实调用 start() 函数后,新线程会优先执行 run() 中的代码,即先执行 fun1() 函数,其次才会运行 fun2() 函数。这种情况不常见,但了解这种先后顺序有助于我们理解 start() 函数。
说到 run() 函数就不得不提 exec() 函数。这是个 protected 函数,因此只能在类内使用。默认 run() 函数会调用 exec() 函数,即启用一个局部的不占 CPU 的事件循环。为什么要默认启动个事件循环呢?这是因为没有事件循环的话,耗时代码只要执行完线程就会退出,频繁的开销线程显然很浪费资源。因此,如果使用上述第二种“开线程”的方式,别忘了在 run() 函数中调用 exec() 函数。
4.2 优雅的退出线程
退出线程可是个技术活,不是随随便便就可以退出。比如我们关闭主进程的同时,里面的线程可能还处在运行状态,尤其线程上跑着耗时操作。这时候你可以用 terminate() 函数强制终止线程,调用该函数后所有处于等待状态的线程都会被唤醒。该函数是异步的,也就是说调用该函数后虽然获得了返回值,但此时线程依然可能在运行。因此,一般是在后面跟上 wait() 函数来保证线程已退出。当然强制是很暴力的行为,有可能会造成局部变量得不到清理,或者无法解锁互斥关系,种种行为都是很危险的,除非必要时才会使用该函数。
在上面我们说到默认 run() 函数会调用 exec() 函数,耗时操作代码执行完后,线程由于启动了事件循环是不退出的。所以,正常的退出线程其实质是退出事件循环,即执行 exit(int returnCode = 0) 函数。返回0代表成功,其他非零值代表异常。quit() 函数等价于 exit(0)。线程退出后会发出 finished() 信号。
5. 操作运行中的线程
5.1 获取状态
(1)运行状态
线程的状态有很多种,而往往我们只关心一个线程是运行中还是已经结束。QThread 提供了 isRunning()、isFinished() 两个函数来判断当前线程的运行状态。
(2)线程标识
关于 currentThreadId() 函数,很多人将该函数用于输出线程ID,这是错误的用法。该函数主要用于 Qt 内部,不应该出现在我们的代码中。那为什么还要开放这个接口?这是因为我们有时候想和系统线程进行交互,而不同平台下的线程 ID 表示方式不同。因此调用该函数返回的 Qt::HANDLE 类型数据并转化成对应平台的线程 ID 号数据类型(例如 Windows 下是 DWORD 类型),利用这个转化后的 ID 号就可以与系统开放出来的线程进行交互了。当然,这就破坏了移植性了。
需要注意的是,这个 Qt::HANDLE 是 ID 号而不是句柄。句柄相当于对象指针,一个线程可以被多个对象所操控,而每个线程只有一个全局线程 ID 号。正确的获取线程 ID 做法是:调用操作系统的线程接口来获取。以下是不同平台下获取线程 ID 的代码:
#include <QCoreApplication>
#include <QDebug>
#ifdef Q_OS_LINUX
#include <pthread.h>
#endif
#ifdef Q_OS_WIN
#include <windows.h>
#endif
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
#ifdef Q_OS_LINUX
qDebug() << pthread_self();
#endif
#ifdef Q_OS_WIN
qDebug() << GetCurrentThreadId();
#endif
return a.exec();
}我们自己的程序内部可以调用 currentThread() 函数来获取 QThread 指针,有了线程指针就可以对线程进行一些操作了。
3)更为精细的事件处理
在《Qt 中的事件系统 - 有什么难的呢?》一文中我们提到事件的整个运行流程,文中所提及的 QCoreApplication::processEvents() 等传递事件方法其实是很简单的,但如果再深入下去就无能为力了。Qt 提供了 QAbstractEventDispatcher 类用于更为精细的事件处理,该类精细到可以管理 Qt 事件队列,即接收到事件(来自操作系统或者 Qt 写的程序)后负责发送到 QCoreApplication 或者 QApplication 实例以进行处理。而文中讲的是从 QCoreApplication 接收到事件开始,再往后的事情了。
线程既然可以开启事件循环,那么就可以调用 eventDispatcher()、setEventDispatcher() 函数来设置和获取事件调度对象,然后对事件进行更为精细的操作。
除此以外,loopLevel() 函数可以获取有多少个事件循环在线程中运行。正如下文所说,这个函数本来在 Qt 4 中被删除了,但是对于那些想知道有多少事件循环的人来说该函数还是有用的。所以在 Qt 5 中又加了进来。
This function used to reside in QEventLoop in Qt 3 and was deprecated in Qt 4. However this is useful for those who want to know how many event loops are running within the thread so we just make it possible to get at the already available variable.
5.2 操作线程
(1)安全退出线程必备函数:wait(unsigned long time = ULONG_MAX)
在上面已经提到“一般是在后面跟上 wait() 函数来保证线程已退出”,线程退出的时候不要那么暴力,告诉操作系统要退出的线程后,给点时间(即阻塞)让线程处理完。也可以设置超时时间 time,时间一到就强制退出线程。一般在类的析构函数中调用,正如本文开头「2.1 我们该把耗时代码放在哪里?」的示例代码那样:
Controller::~Controller()
{
m_workThread.quit();
m_workThread.wait();
}(2)线程间的礼让行为
这是个很有意思的话题,一般我们都希望每个线程都能最大限度的榨干系统资源,何来礼让之说呢?有时候我们采用多线程并不只是运行耗时代码,而是和主 GUI 线程分开,避免主界面卡死的情况发生。那么有些线程上跑的任务可能对实时性要求不高,这时候适当的缩短被 CPU 选中的机会可以节约出系统资源。
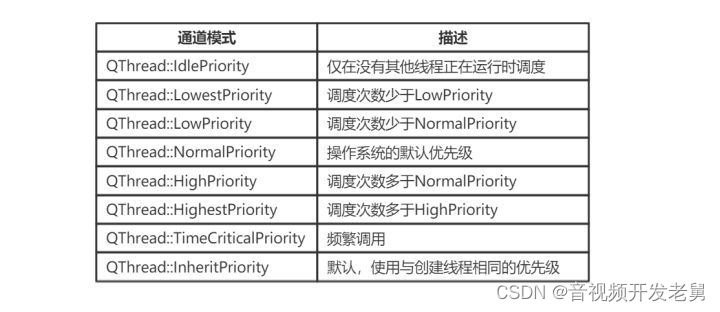
除了调用 setPriority()、priority() 优先级相关的函数以外,QThread 类还提供了 yieldCurrentThread() 静态函数,该函数是在通知操作系统“我这个线程不重要,优先处理其他线程吧”。当然,调用该函数后不会立马将 CPU 计算资源交出去,而是由操作系统决定。
QThread 类还提供了 sleep()、msleep()、usleep() 这三个函数,这三个函数也是在通知操作系统“在未来 time 时间内我不参与 CPU 计算”。从我们直观的角度看,就好像当前线程“沉睡”了一段时间。
(3)线程的中断标志位
Qt 为每一个线程都设置了一个布尔变量用来标记当前线程的终端状态,用 isInterruptionRequested() 函数来获取,用 requestInterruption() 函数来设置中断标记。这个标记不是给操作系统看的,而是给用户写的代码中进行判断。也就是说调用 requestInterruption() 函数并不能中断线程,需要我们自己的代码去判断。这有什么用处呢?
while (ture) {
if (!isInterruptionRequested()) {
// 耗时操作
......
}
}这种设计可以让我们自助的中断线程,而不是由操作系统强制中断。经常我们会在新线程上运行无限循环的代码,在代码中加上判断中断标志位可以让我们随时跳出循环。好处就是给了我们程序更大的灵活性。
6. 为每个线程提供独立数据
思考这样一个问题,如果线程本身存在全局变量,那么修改一处后另一个线程会不会受影响?我们以一段代码为例:
// main.cpp
#include <QCoreApplication>
#include "workthread.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
WorkThread thread1;
WorkThread thread2;
thread1.start();
thread2.start();
return a.exec();
}
// WorkThread.h
#ifndef WORKTHREAD_H
#define WORKTHREAD_H
#include <QThread>
class WorkThread : public QThread
{
public:
WorkThread();
protected:
virtual void run() override;
};
#endif
// WorkThread.cpp
#include "workthread.h"
#include <QDebug>
#include <QThreadStorage>
WorkThread::WorkThread()
{
}
quint64 g_value1 = 0;
void WorkThread::run()
{
g_value1 = quint64(currentThreadId());
qDebug() << g_value1;
}我们继承 QThread 类并重写 run() 函数,函数中的全局变量 g_value1 由线程 ID 赋值。实例化出两个线程对象并均启动。其结果输出如下:

可以看到两个输出的结果是一样的,线程 thr 对全局变量的修改影响了线程 thr1。造成这个现象的原因也很好理解。“线程隶属于某一个进程,与进程内的其他线程一起共享这片地址空间”。也就是说全局变量属于公共资源,被所有线程所共享,只要一个线程修改了这个全局变量自然就会影响其他线程对该全局变量的访问。
而 QThreadStorage 类为每个线程提供了独立的数据存储功能,即使在线程中用到全局变量,只要存在 QThreadStorage 中,也不会影响到其他线程。。如下图所示:
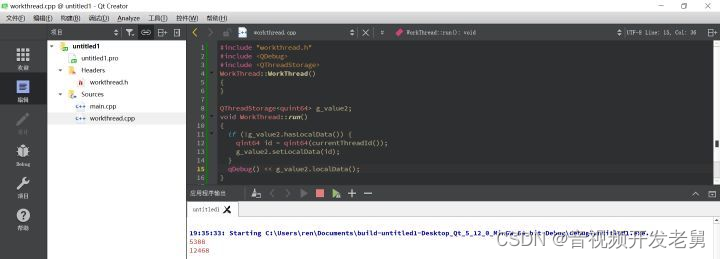
需要注意的是,QThreadStorage 的析构函数并不会删除所储存的数据,只有线程退出才会被删除。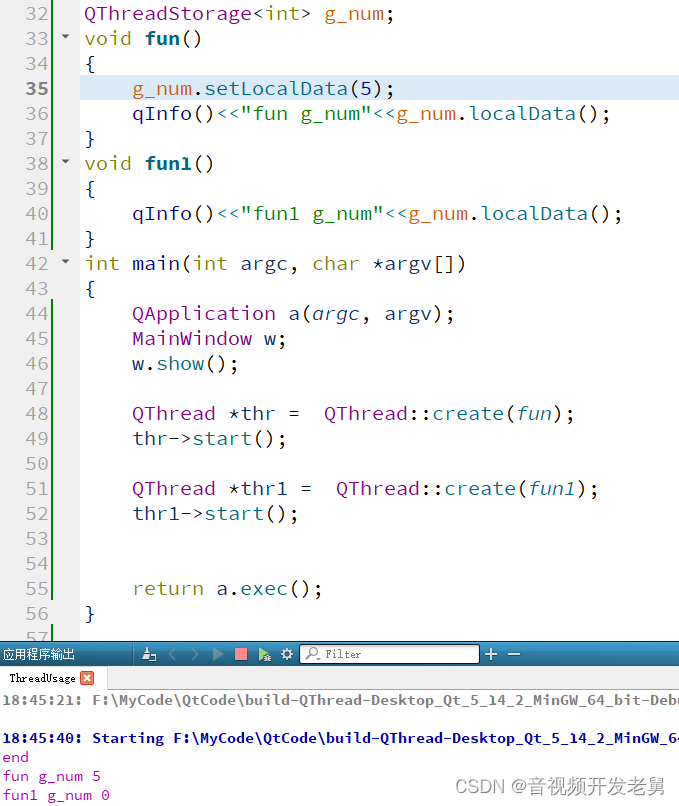
本文福利,莬费领取Qt开发学习资料包、技术视频,内容包括(C++语言基础,Qt编程入门,QT信号与槽机制,QT界面开发-图像绘制,QT网络,QT数据库编程,QT项目实战,QT嵌入式开发,Quick模块等等)↓↓↓↓↓↓见下面↓↓文章底部点击莬费领取↓↓
相关文章
- [C++]Qt文本操作(按行读写)
- 【C/C++学院】(19)QT版:记事本
- Qt编写自定义控件一开关按钮
- Qt-消息对话框的设计
- Qt-跨平台的C++图形用户界面应用程序框架(一)
- 使用Qt和C语言或者C++语言实现十、二、八、十六进制之间的转换(两种方法)
- Qt Plugin插件机制与实例
- Qt Quick 常用元素:RadioButton(单选框),CheckBox(复选框) 与 GroupBox(分组框)
- C++Qt中qmake的详解
- C++QT开发——布局管理器
- C++Qt开发——HTTP协议
- C++QT开发——TCP&UDP网络编程
- C++Qt开发——QSS样式表
- Qt实现控件的折叠收起和展开的功能
- C++ QT中文件的读写操作(UI界面)
- 【Qt】在ubuntu上安装qt的mqtt模块
- Qt QPropertyAnimation 几行代码快速制作流畅的动画效果
- QT-QXmlStreamReader解析,QXmlStreamWriter写入
- Qt官方示例-数字时钟
- QT-QPlainEdit 信号与槽
- Qt - 生产者和消费者模型示例
- C++(Qt)与Python混合编程(一)
- Qt中用QLabel显示OpenCV中Mat图像数据出现扭曲现象的解决
- Qt开发MQTT(一) 之Qt官方Qt MQTT
- Qt Quick 组件和动态创建的对象具体的解释
- C/C++、Qt开发,跨平台CMake判断当前平台是Linux还是Windows,操作系统判断
- QT 定时关机、共享内存、启动浏览器、浏览器前进后退刷新、进度条、设置浏览器标题、QML入门