
【目标检测】35、PISA: Prime Sample Attention in Object Detection

论文:Prime Sample Attention in Object Detection
代码:https://github.com/open-mmlab/mmdetection/tree/master/configs/pisa
出处:CVPR2020
贡献点:
- 提出了 PrIme Sample Attention (PISA),让网络更加关注 prime samples,prime samples 是指那些对检测效果很重要的样本(IoU 高的正样本和 Score 高的负样本),且证明了关注这些 prime 样本比单单关注 hard sample 更有效
- 提出了新的 samples 排序方法,在每个 batch 中,使用 IoU-HLR 来对 positive samples 排序,使用 Score-HLR 来对 negative sample 排序,这样的排序方法能够把 IoU 大的正样本(prime),和分类得分高的负样本(难样本,因为是负样本,但分类得分却高,所以需要重点关注)排到前面,指导网络更关注这些样本。
- 提出了一个 classification-aware 的回归 loss,来联合优化分类和回归分支,能够抑制回归 loss 高的样本,强化 prime 样本的贡献
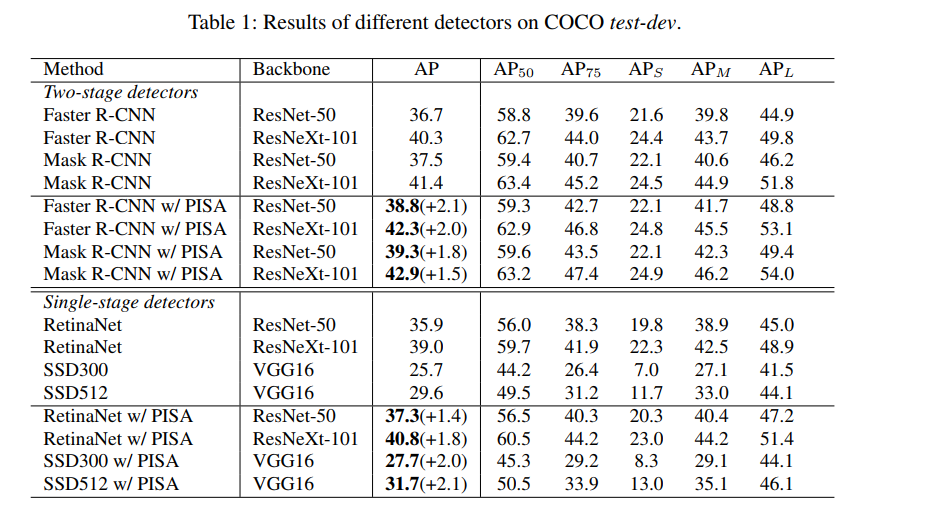
- 使用 COCO 数据集,在 Faster RCNN、Mask RCNN、RetinaNet 上分别提高 2.0%、1.5%、1.8% AP
一、背景
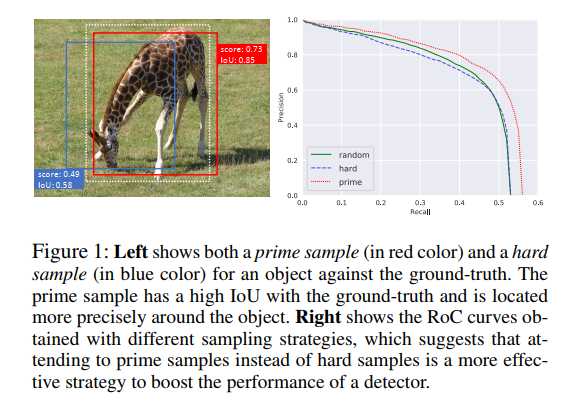
很多检测方法中,一般都是将所有 anchor 平等看待,对 loss 优化的贡献也相同,但我们可以直观想象到绝大部分的 anchor 其实是背景信息,所以就有一些方法来试图解决这些问题,如 OHEM 和 Focal loss。HOEM 挖掘了一些难样本,而Focal loss 是在 loss 函数中对样本进行了加强,让难样本对 loss 的贡献更大一些。
虽然这些方法能够对上述问题有所缓解,但没有从根本上回答这个问题:
到底那些样本对检测器来说是最重要的呢?
本文出发点:
-
所有的 sample 不应该被独立且同等地对待(它们既不独立也不平等,它们是竞争关系,且高 IoU 的样本应该是更重要的)
Region-based 目标检测方法其实是在一堆 sample 中选择极少数的几个 sample 来作为最终的检测结果,所以这些 sample 是竞争关系,不是完全独立的。
对于检测器来说,更可取的做法是在每个对象周围的一个边界框上获得高分,同时确保所有感兴趣的对象都被充分覆盖,而不是试图为所有正样本(即那些与对象大量重叠的)产生高分。即关注那些 high IoU 的正样本,而非所有正样本。
-
分类和定位的目标函数是相关的,而非独立的
那些精确定位在地面真实物体周围的样本特别重要,即分类的目的与定位的目的密切相关,也就是说,定位良好的样本需要以高置信度进行良好分类。
二、方法
2.1 Hierarchical Local Rank(HLR)
1、计算正样本的 IoU-HLR(如图 3):
- 首先,根据距离 gt 的距离,将所有的 samples 分成不同的 groups,也就是将 samples 分配到对应的 gt 上去,一个 gt 对应的一堆 samples 为一组,如图 3a 所示
- 接着,在每个 group 里边对 sample 进行排序,排序的依据是按 IoU 的降序排列,得到 IoU Local Rank(IoU-LR)
- 最后,将每个 group 的 top-1 中的值按 IoU 降序排列,后面跟着 top-2、top-3 … Samples
IoU-HLR 排序后,正样本是怎样的:
- 每个 gt 对应的 IoU 最大的 sample 排在了最前面的序列中,后面是所有 gt 对应的 top-2 的 sample,以此类推
IoU-HLR 排序后的序列如何使用:
- IoU-HLR 排序中越靠前的 sample,是越重要的 sample,对网络的贡献越大
- 越靠前的样本,网络的关注越高
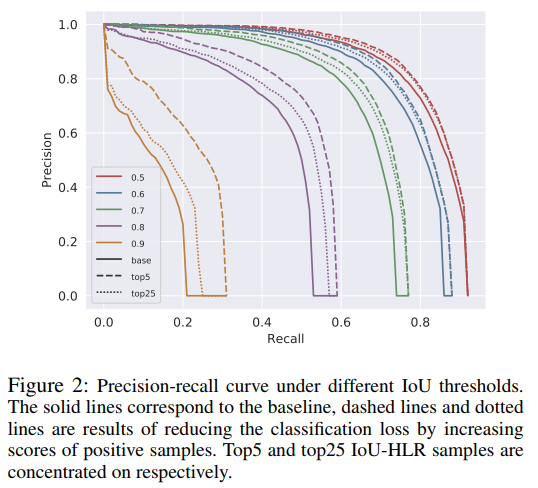
图 2 展示了 PR 曲线,不同颜色的实线是不同 IoU 阈值下的 PR 曲线,这些曲线说明,网络聚焦于那些 top samples,比平等的看待所有 samples 的效果好,因为 PR 曲线下面积越大,说明 mAP 越高。
2、计算负样本的 Score-HLR:
由于负样本一般出现在背景区域,也无法使用 gt 来对其进行聚类,所以:
- 首先,使用 NMS 来将他们分组到不同的组,也就是把距离近的聚到一个 group,如图 3b 所示
- 接着,在每个 group 内按照分类得分进行排序
- 最后,提取每个 group 的 top-1,将分类得分最大的排在第一个,依此排列,然后将 top-2 的按照相同的方法排到 top-1 的后面,以此类推,得到最终的 HLR 序列。
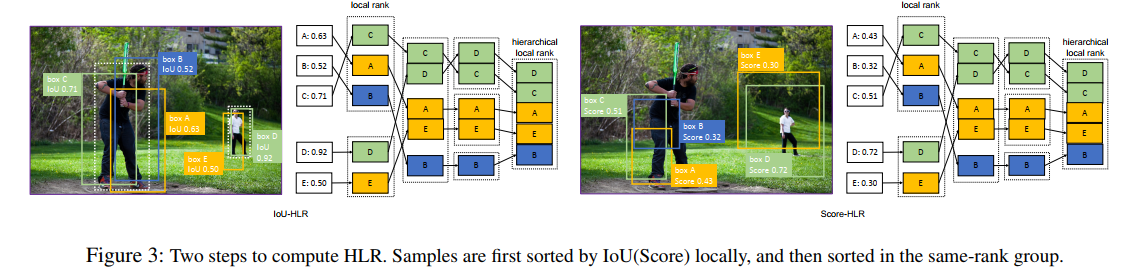
Score-HLR 排序号的序列是怎样的:
- 负样本中,分类得分越高的越靠前
- 得分越靠前的样本,网络训练过程更关注
Score-HLR 排序后的序列怎么使用:
- 排序后,那些得分高的负样本排在前面了,之后通过线性变换,会得到大的权重,排序越靠前权重越大,模型越关注这些假正的样本。
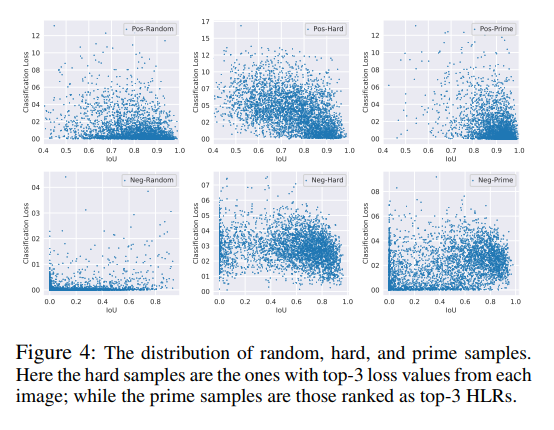
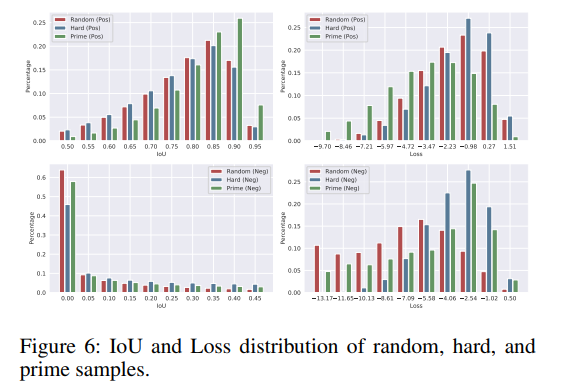
图 4 展示了 random、hard、prime samples 和 IoU vs. Classification score 的关系,第一行是 positive samples,第二行是 negative samples。
图 4 说明了什么?
- Hard positive 样本一般 classification loss 很高,并且在 IoU 轴上很分散
- Prime positive 样本一般有高 IoU 和 低 classification loss
- Hard negative 样本一般是有高 classification loss 和高 IoU
- Prime negative 样本分布很没有规律
不同 sampling method 的对比:
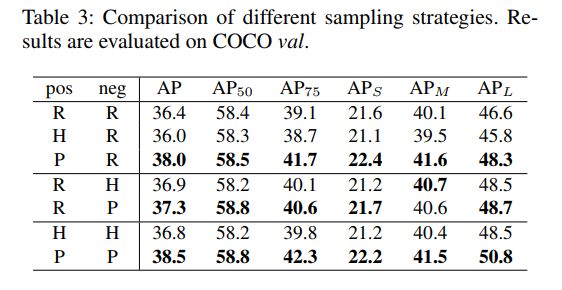
不同 sampling 的方法分别更喜欢哪种 sample?
- positive samples:hard samples 的 loss 高但 IoU 低,prime samples 的 loss 低但 IoU 高,说明 prime samples 更喜欢易于分类的样本
- negative saples:PISA 是在 random sampling 和 hard mining 中间,random sampling 区域喜欢低 IoU 的简单样本,hard mining 喜欢高 IoU 的难样本,PISA 会保留样本更多的多样性。
2.2 PISA
PISA 的主要目的是让网络更关注 prime samples,包含以下两个模块:
- Importance-based Sample Reweighting:在训练过程中偏向 prime samples,而非对所有 samples 同等对待,
- Classification-Aware Regression Loss:分类和回归使用联合目标函数训练,有助于提高 positive prime samples 的得分
先看看 PISA 每个模块的作用:
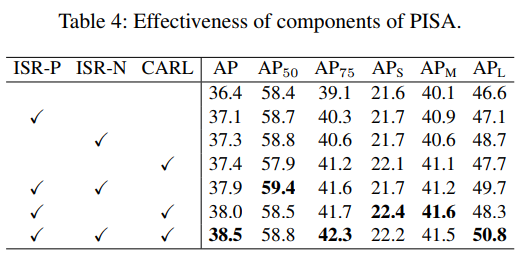
1、Importance-based Sample Reweighting
一个分类器的效果和 sample 的分布往往有很大的关系,如果某些样本频繁的出现在训练数据中,那么就会取得较好的效果,hard sampling 和 soft sampling 是两个改变训练数据分布的方法:
- Soft sampling 是给不同样本赋予不同的权重
- Hard sampling 从候选样本中选择一部分来参与模型训练,可以看做 soft sampling 的一个特例,权重给 0/1
本文提出的 Importance-based Sample Reweighting (ISR) 就是一个 soft sampling 的方法,根据样本的重要程度,来给其分配不同的 loss 权重。
ISR 包含两个部分:
- Positive sample reweighting:ISR-P,使用的“重要程度衡量标准”为 IoU-HLR
- Negative sample reweighting:ISR-N,使用的“重要程度衡量标准”为 Score-HLR
能够衡量重要程度之后,就需要解决如何将重要程度转化为 loss weight:
-
首先,使用线性方式来转换这些排序,由于 HLR 是根据不同的类别来分别计算的(N 个前景类,1 个背景类)。
对于类别 j j j,假设共有 n j n_j nj 个 samples 进行排序,得到 r 1 , r 2 , . . . , r n j {r_1, r_2, ..., r_{nj}} r1,r2,...,rnj,则使用公式 1 的方式来进行线性转换。
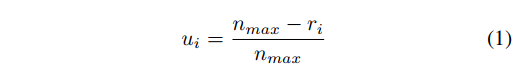
- u i u_i ui 是第 j 个类中的第 i 个sample 的重要程度
- n m a x n_{max} nmax 是所有类别中,最大的 n j n_j nj,该值能够保证不同类别中相同排序位置的 sample,都会被赋予相同的 u i u_i ui
-
然后,使用如公式 2 所示的一个单调递增的函数,来将 importance u i u_i ui 投射为 loss weight w i w_i wi:
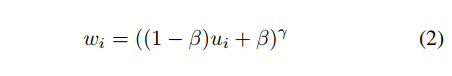
-
γ \gamma γ 决定了将给该 sample 多大的偏爱
-
β \beta β 是一个偏置,决定了最低 sample weight
-
最后,在 Reweighting 之后,交叉熵分类函数可以重写为公式 3。直接在 loss 函数上使用权重,会直接改变 loss 的值,也会改变 positive 和 negative sample 对 loss 的贡献比例,所以,作者使用将 w w w 规范化为 w ′ w' w′,来保持 loss 的值不被改变。
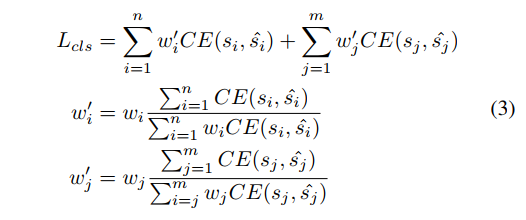
- n n n 是 positive sample 数量
- m m m 是 negative sample 的数量
- s s s 是预测分类得分, s ^ \hat{s} s^ 是类别真值
ISR 如何影响分类得分?
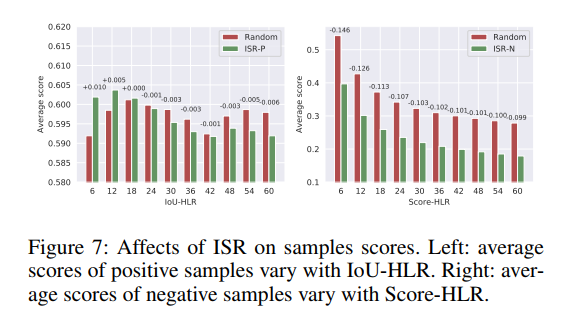
ISR 会给 prime samples 分配更大的权重,如图 7 展示了不同 HLR 对应的正负样本的分布情况。
- 对于正样本,top-ranked samples 的得分高于 baseline,lower-ranked samples 的得分很低,说明 ISR-P 能够提高 prime 样本的分类得分,降低其他的样本的分类得分
- 对于负样本,所有样本的分类得分都低于 baseline,尤其是 top-ranked samples,说明 ISR-N 能够很好的抑制假正
2、 Classification-Aware Regression Loss
对于一个分类器,期望的是其能够对重要的样本输出更高的得分,而回归器的输出又决定了一个样本是不是重要,所以,分类和回归是有一定的联系在里边的。
作者如何将分类和回归联合起来?
使用一个 classification-aware 回归函数,能够让回归分支的梯度传递到分类分支上去,具体公式如公式 4 所示:
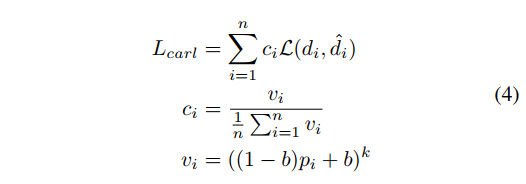
- p i p_i pi 是预测的类别置信度
- d i d_i di 是回归输出的 offset
- L L L 是 smooth L1 loss
- k = 1.0 , b = 0.2 k=1.0, b=0.2 k=1.0,b=0.2
分析:
- 回归 loss 越大,classification score 接收到的梯度越大,也就是会越抑制该分类得分
- 回归 loss 越小,classification score 接收到的梯度越小,也就是不会抑制该分类得分
- 有了 CARL,classification branch 就会被 regression loss 监督起来,不重要的样本的分类得分会被抑制,重要样本的分类得分会被增强。
超参数的验证:
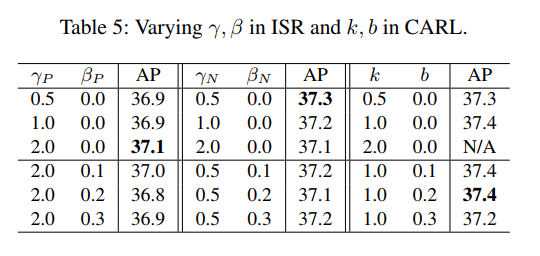
CARL 如何影响分类得分?
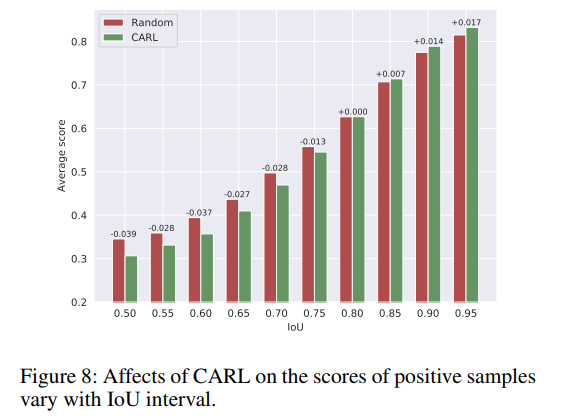
CARL 通过在回归 loss 中引入分类得分的方法,将分类得分和回归分支联合起来,回归质量低的样本的分类得分会被抑制,回归质量高的样本的分类得分会被增强,如图 8 所示,相比 FPN,CARL 能够增强 high IoU 样本的分类得分,抑制 low IoU 样本的分类得分。
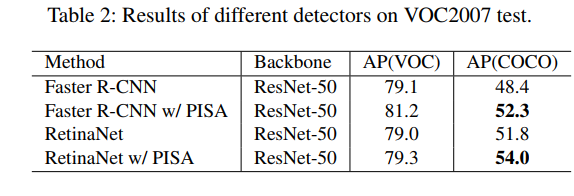
三、效果
相关文章
- istio-in-action - 08 VirtualService 使用 header 重写路由
- ORA-01218: logfile member is not from the same point-in-time ORACLE 报错 故障修复 远程处理
- ORA-19602: cannot backup or copy active file in NOARCHIVELOG mode ORACLE 报错 故障修复 远程处理
- ORA-26015: Array column string in table string is not supported by direct path ORACLE 报错 故障修复 远程处理
- ORA-30178: duplicate flag used in a format specification ORACLE 报错 故障修复 远程处理
- ORA-30490: Ambiguous expression in GROUP BY ROLLUP or CUBE list ORACLE 报错 故障修复 远程处理
- ORA-32485: element in cycle column list of CYCLE clause must appear in the column alias list of the WITH clause element ORACLE 报错 故障修复 远程处理
- ORA-38703: Type string in header is not a flashback database log file. ORACLE 报错 故障修复 远程处理
- ORA-00204: error in reading (block string, # blocks string) of control file ORACLE 报错 故障修复 远程处理
- ORA-01055: Object datatypes not supported for bind or define in this mode ORACLE 报错 故障修复 远程处理
- ORA-08446: syntax error in SYNCHRONIZED clause in mask options ORACLE 报错 故障修复 远程处理
- ORA-12725: unmatched parentheses in regular expression ORACLE 报错 故障修复 远程处理
- MySQL删除IN操作: 简易指南(mysql删除in)
- no main manifest attribute, in demo-1.0.jar详解编程语言
- MySQL中实现嵌套查询的IN关键字用法(mysql嵌套查询in)
- 搜索MySQL中IN搜索的应用(mysql包含in)
- MySQL中的IN函数详解(mysql中的in)
- 查询MySQL中使用IN语句实现多字段查询(mysql多字段in)
- Exploring File Sharing in Linux: The Benefits of Using SMB://(linuxsmb)
- MSSQL条件查询IN机制优化技巧(mssql条件查询in)
- MySQL中使用IN关键字时,字符串的长度有限制吗(mysql中in长度)
- MySQL中的IN查询的性能优化(mysql中in性能)
- MySQL中IN函数的使用及作用解析(mysql中in作用)
- 中利用IN语句检索Oracle数据库中的数据(in在oracle数据库)
- MySQL实现不在某个范围内的查询当字段不在给定值列表中时,使用NOT IN语法(mysql 不in)
- MySQL不支持IN运算符如何解决(mysql 不支持in)
- 利用Oracle中的IN子句改善查询效率(oracle中的in子句)
- javascript版的in_array函数(判断数组中是否存在特定值)